Experiência visualmente intuitiva de 7 algoritmos de classificação comumente usados (comumente usados para estratégias de escrita)
 2
1610
2
1610
Sete algoritmos de classificação usados em Visual Intuition
Quando se escreve uma estratégia, o código do programa inevitavelmente encontrará situações que requerem a ordenação de dados, então como podemos projetar um programa científico com o menor gasto do sistema (tempo e recursos do sistema)?
- ### 1. Classificação rápida
O que aconteceu?
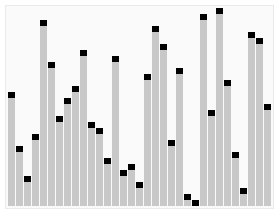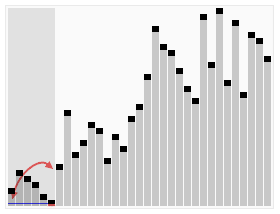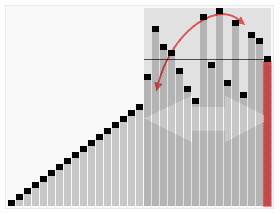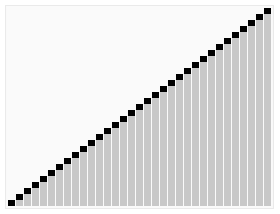
A classificação rápida é um tipo de algoritmo de classificação desenvolvido por Tony Hall. Em condições médias, a classificação de n itens requer O (n log n) comparações. Em condições piores, a classificação precisa de O (n log n) comparações, mas isso não é comum. Na verdade, a classificação rápida é geralmente significativamente mais rápida do que outros algoritmos de O (n log n) porque seu loop interno pode ser implementado com muita eficiência na maioria das arquiteturas e, na maioria dos dados do mundo real, pode decidir sobre as opções de design, reduzindo a possibilidade de duplicação do tempo necessário.
Passos:
Escolha um elemento da matriz, denominado pivô de referência (pivot)
Reorganize a matriz, colocando todos os elementos menores do que o valor de referência na frente da matriz e todos os elementos maiores do que o valor de referência atrás da matriz (o mesmo número pode ir para qualquer lado). Após a saída desta divisão, a matriz está no meio da matriz. Isso é chamado de operação de divisão.
Recursivo () ordena um subconjunto menor que o elemento de referência e um subconjunto maior que o elemento de referência.
Efeito de ordenação:
- ### 2. Reincidência e ordenação
O que aconteceu?
Merge sort é um algoritmo de classificação eficaz baseado na operação de fusão. O algoritmo é uma aplicação muito típica do método Divide and Conquer.
Passos:
Espaço de solicitação, que tem o tamanho da soma de duas sequências previamente ordenadas, que é usado para armazenar a sequência depois da fusão
Configure dois ponteiros com a posição inicial de duas sequências ordenadas
Comparar os elementos que os dois ponteiros apontam, escolher um elemento relativamente pequeno para colocar no espaço de fusão e mover o ponteiro para a próxima posição
Repetir o passo 3 até que um dos ponteiros chegue ao fim da sequência
Copiar todos os elementos restantes de outra sequência diretamente para o final da sequência de fusão
Efeito de ordenação:

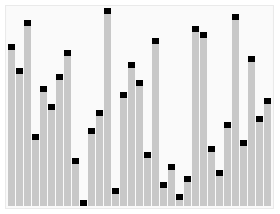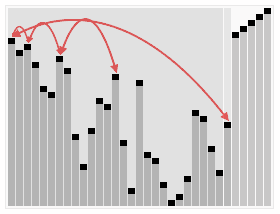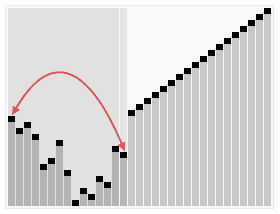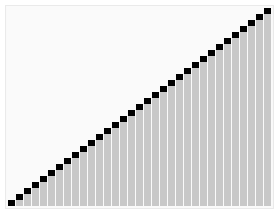
- ### 3. Sequenciamento de pilhas
O que aconteceu?
O Heapsort é um algoritmo de classificação projetado para usar esta estrutura de dados. O Heapsort é uma estrutura de árvore binária quase perfeita, e ao mesmo tempo satisfaz a propriedade do Heapsort: o valor-chave ou índice de um sub-nó sempre é menor que (ou maior que) seu pai.
Passos:
(É mais complicado, procure na internet)
Efeito de ordenação:
- ### 4. Selecionar a ordem
O que aconteceu?
Selection sort é um algoritmo de ordenação simples e intuitivo que funciona da seguinte forma: primeiro, localiza o menor elemento na sequência não-ordenada, armazena-o na posição inicial da sequência de ordenação, em seguida, continua a procurar o menor elemento dos restantes elementos não-ordenados, e depois coloca-o no final da sequência de ordenação. E assim por diante até que todos os elementos estejam classificados.
Efeito de ordenação:

- ### 5. Sequência de borbulhas
O que aconteceu?
Bubble Sort é um algoritmo de classificação simples que visita repetidamente os números que você quer classificar, comparando dois elementos de uma vez e trocando-os se eles estiverem em ordem errada. O trabalho de visitar as colunas é repetidamente até que não seja mais necessário trocar, ou seja, a classificação está concluída. O nome do algoritmo vem do fato de que os elementos mais pequenos flutuam lentamente até o topo da coluna através da troca.
Passos:
Compare elementos adjacentes. Se o primeiro for maior que o segundo, troque-os por dois.
Faça o mesmo com cada par de elementos adjacentes, desde o primeiro par até o último. Neste ponto, o último elemento deve ser o maior.
Repita os passos acima para todos os elementos, exceto o último.
Repetindo os passos acima para cada cada vez menos elementos, até que nenhum dos pares de números seja comparado.
Efeito de ordenação:

- ### Sequência de inserção 6.
O que aconteceu? O algoritmo de classificação por inserção (Insertion Sort) é um algoritmo de classificação simples e intuitivo. O seu princípio de trabalho é o de construir uma sequência de dados em que os dados não classificados são escaneados de trás para a frente na sequência ordenada, para encontrar a posição correspondente e inserir. A classificação por inserção, em sua implementação, geralmente usa classificação in-place, ou seja, classificação com espaço adicional de apenas O (1), pois o processo de varredura de trás para a frente requer a repetição de elementos classificados para trás, fornecendo espaço para inserção de novos elementos. Passos: Começando pelo primeiro elemento, este elemento pode ser considerado como já ordenado Pegue um elemento e vá de trás para a frente na sequência de elementos já ordenados Se o elemento é maior do que o novo elemento, move-o para a próxima posição Repita o passo 3 até encontrar um elemento ordenado menor ou igual ao novo elemento Inserir um novo elemento na posição Repetir o passo 2 Efeito de ordenação: (Não disponível)
- ### Sequência Hill
O que aconteceu?
A ordenação de Hill, também conhecida como algoritmo de ordenação decrescente-incremental, é uma versão rápida e estável de ordenação de inserção.
A classificação de Hill propõe uma melhor abordagem baseada nas seguintes duas propriedades da inserção de classificação:
1, inserção de ordenação é altamente eficiente para a operação de dados que já estão quase ordenados, ou seja, pode atingir a eficiência de uma ordenação linear
Mas inserção de ordenação é geralmente ineficiente, porque a inserção de ordenação só pode mover dados de uma pessoa para outra.
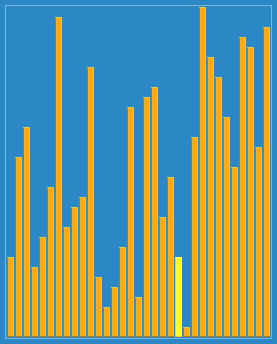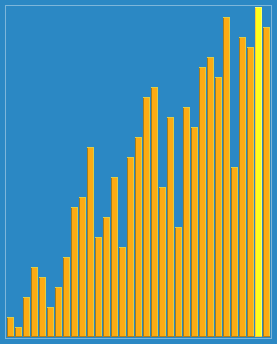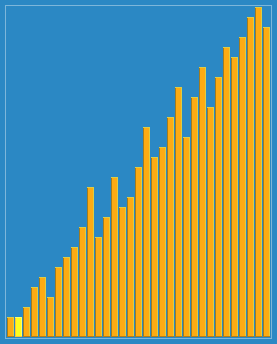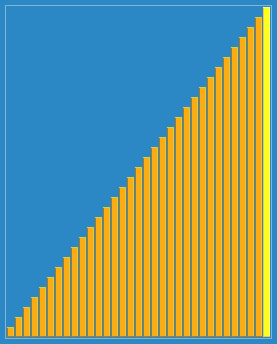
Eu uso mais o método de borbulhar (o mais simples), e você?