Aplicação da tecnologia de aprendizado de máquina na negociação
 3
3072
3
3072

Esta postagem foi inspirada por minhas observações de alguns avisos e armadilhas comuns após tentar aplicar técnicas de aprendizado de máquina a problemas de negociação durante minha pesquisa de dados na plataforma Inventor Quant.
Se você não leu meu artigo anterior, recomendamos que leia meu guia anterior sobre o ambiente de pesquisa de dados automatizado estabelecido na Plataforma Quantitativa Inventor e a abordagem sistemática para desenvolver estratégias de negociação antes deste artigo.
Os endereços estão aqui: https://www.fmz.com/digest-topic/4187 e https://www.fmz.com/digest-topic/4169.
Sobre o estabelecimento do ambiente de pesquisa
Este tutorial foi criado para entusiastas, engenheiros e cientistas de dados de todos os níveis de habilidade. Seja você um especialista da indústria ou um novato em programação, as únicas habilidades necessárias são um entendimento básico da linguagem de programação Python e conhecimento suficiente de operações de linha de comando. (Ser capaz de montar um projeto de ciência de dados é suficiente)
- Instalar Inventor Quant Hoster e configurar Anaconda
Além de fornecer fontes de dados de alta qualidade das principais bolsas tradicionais, a Plataforma Quantitativa Inventor FMZ.COM também fornece um rico conjunto de interfaces de API para nos ajudar a realizar transações automatizadas após concluir a análise de dados. Este conjunto de interfaces inclui ferramentas práticas, como consulta de informações de conta, consulta de preços altos, de abertura, baixos e de fechamento, volume de negociação, vários indicadores de análise técnica comumente usados em várias bolsas tradicionais, etc., especialmente para conexão com as principais bolsas tradicionais na prática. processos de negociação. A interface API pública fornece suporte técnico poderoso.
Todos os recursos mencionados acima são encapsulados em um sistema similar ao Docker. Tudo o que precisamos fazer é comprar ou alugar nosso próprio serviço de computação em nuvem e então implantar o sistema Docker.
No nome oficial da Inventor Quantitative Platform, esse sistema Docker é chamado de sistema host.
Para obter mais informações sobre como implantar hosts e robôs, consulte meu artigo anterior: https://www.fmz.com/bbs-topic/4140
Os leitores que desejam adquirir seu próprio host de implantação de servidor de computação em nuvem podem consultar este artigo: https://www.fmz.com/bbs-topic/2848
Após a implantação bem-sucedida do serviço de computação em nuvem e do sistema host, instalaremos a ferramenta Python mais poderosa: Anaconda
Para obter todos os ambientes de programa relevantes necessários para este artigo (bibliotecas dependentes, gerenciamento de versões, etc.), a maneira mais fácil é usar o Anaconda. É um ecossistema de ciência de dados Python empacotado e um gerenciador de dependências.
Como estamos instalando o Anaconda em um serviço de nuvem, recomendamos que você instale o sistema Linux mais a versão de linha de comando do Anaconda no servidor de nuvem.
Para o método de instalação do Anaconda, consulte o guia oficial do Anaconda: https://www.anaconda.com/distribution/
Se você é um programador Python experiente e não sente necessidade de usar o Anaconda, tudo bem. Presumo que você não precise de ajuda para instalar as dependências necessárias e pode pular esta seção.
Desenvolver uma estratégia de negociação
O resultado final de uma estratégia de negociação deve responder às seguintes perguntas:
Direção: Determine se um ativo é barato, caro ou razoavelmente valorizado.
Condições de abertura: se o preço do ativo estiver barato ou caro, você deve operar comprado ou vendido.
Fechar negociação: Se o preço do ativo for justo e tivermos uma posição naquele ativo (compra ou venda anterior), você deve fechar a posição?
Faixa de preço: O preço (ou faixa) no qual a negociação é aberta
Quantidade: A quantidade de fundos negociados (por exemplo, a quantidade de moeda digital ou o número de lotes de futuros de commodities)
O aprendizado de máquina pode ser usado para responder a cada uma dessas perguntas, mas, no restante deste artigo, nos concentraremos em responder à primeira pergunta, que é a direção do comércio.
Abordagem estratégica
Existem dois tipos de abordagens para a construção de estratégias: uma baseada em modelos e a outra baseada em mineração de dados. Essas duas são abordagens basicamente opostas.
Na construção de estratégias baseadas em modelos, começamos com um modelo de ineficiências de mercado, construímos expressões matemáticas (por exemplo, preços, retornos) e testamos sua eficácia em períodos de tempo mais longos. O modelo geralmente é uma versão simplificada de um modelo complexo real, e sua significância e estabilidade a longo prazo precisam ser verificadas. As estratégias usuais de acompanhamento de tendências, reversão à média e arbitragem se enquadram nessa categoria.
Por outro lado, primeiro procuramos padrões de preços e tentamos usar algoritmos em métodos de mineração de dados. O que causa esses padrões não é importante, pois o que é certo é que eles continuarão a se repetir no futuro. Este é um método de análise cega e precisamos de uma inspeção rigorosa para identificar os padrões reais dos padrões aleatórios. “Tentativa e erro”, “Padrões de gráfico de barras” e “Regressão de massa de recursos” pertencem a esta categoria.
Claramente, o aprendizado de máquina se presta facilmente a métodos de mineração de dados. Vamos ver como o aprendizado de máquina pode ser usado para criar sinais de negociação por meio da mineração de dados.
Os exemplos de código usam a ferramenta de backtesting e a interface de API de negociação automatizada com base na Plataforma Quantitativa do Inventor. Após implantar o hoster e instalar o Anaconda na seção acima, você só precisa instalar a biblioteca de análise de ciência de dados que precisamos e o famoso modelo de aprendizado de máquina scikit-learn. Não entraremos em detalhes sobre esta parte.
pip install -U scikit-learn
Usando aprendizado de máquina para criar sinais de estratégia de negociação
- Mineração de dados
Antes de começar, uma estrutura padrão de problema de aprendizado de máquina é mostrada abaixo:
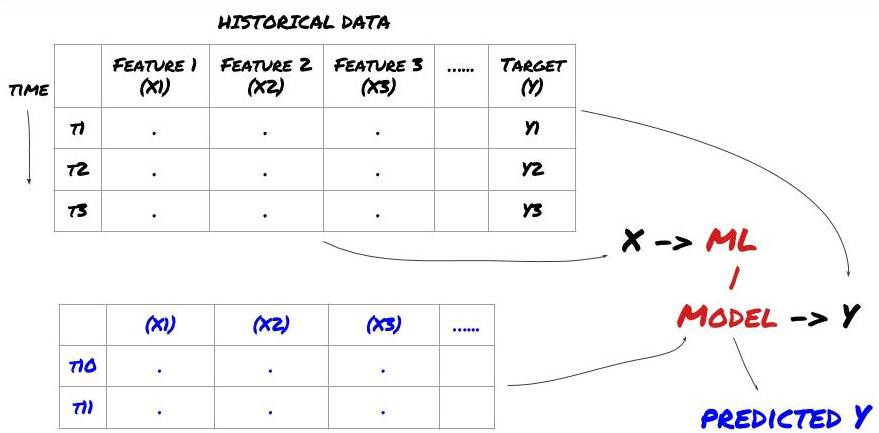
Estrutura de problemas de aprendizado de máquina
Os recursos que vamos criar devem ter algum poder preditivo (X), queremos prever a variável alvo (Y) e usar os dados históricos para treinar um modelo de ML que possa prever Y o mais próximo possível do valor real. Por fim, usamos esse modelo para fazer previsões sobre novos dados onde Y é desconhecido. Isso nos leva ao primeiro passo:
Etapa 1: configure seu problema
- O que você quer prever? O que é uma boa previsão? Como você avalia os resultados da previsão?
Ou seja, em nossa estrutura acima, o que é Y?
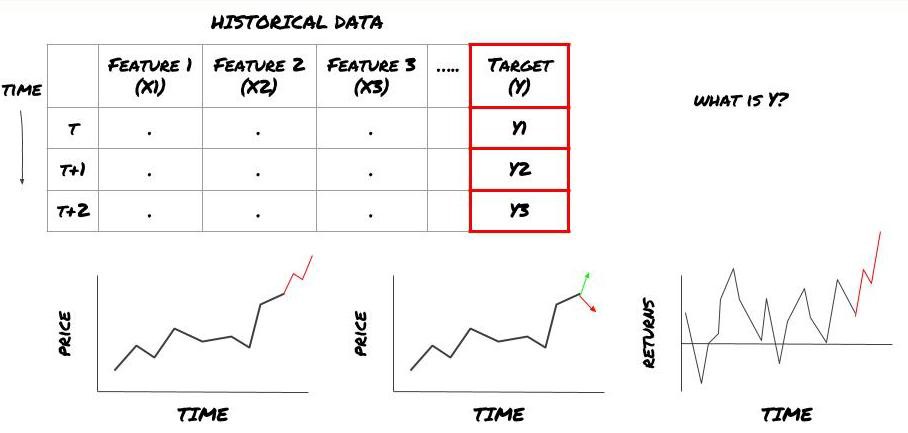
O que você quer prever?
Você quer prever preços futuros, retornos/PNL futuros, sinais de compra/venda, otimizar alocações de portfólio e tentar executar negociações de forma eficiente etc.?
Suponha que estamos tentando prever o preço no próximo registro de data e hora. Neste caso, Y(t) = Preço(t+1). Agora podemos completar nossa estrutura com dados históricos
Observe que Y(t) só é conhecido no backtest, mas quando usamos nosso modelo não saberemos o preço no momento t (t+1). Usamos nosso modelo para fazer uma previsão Y(previsto, t) e compará-la com o valor real apenas no tempo t+1. Isso significa que você não pode usar Y como um recurso em um modelo preditivo.
Depois de sabermos nosso alvo Y, também podemos decidir como avaliar nossas previsões. Isso é importante para distinguir os diferentes modelos que testaremos em nossos dados. Dependendo do problema que estamos resolvendo, escolha uma métrica para medir a eficiência do nosso modelo. Por exemplo, se estivermos prevendo preços, podemos usar o erro quadrático médio como métrica. Alguns indicadores comumente usados (média móvel, MACD e pontuação de variância, etc.) foram pré-codificados na caixa de ferramentas do Inventor Quant, e você pode chamar esses indicadores globalmente por meio da interface da API.
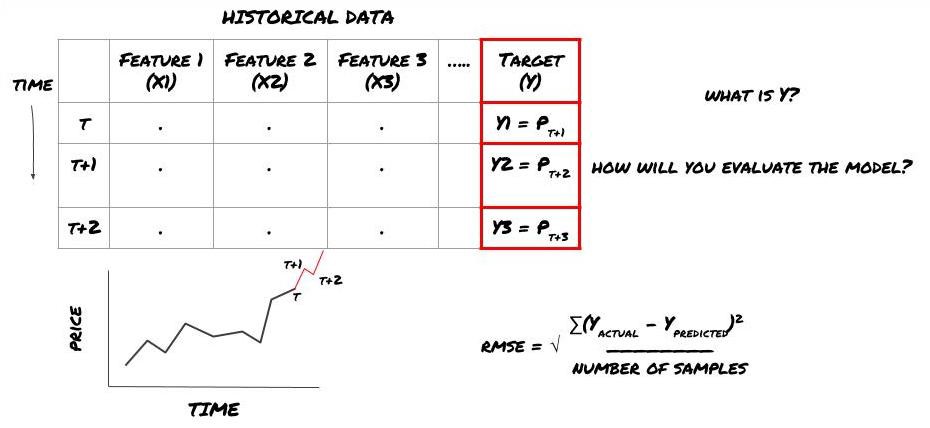
Estrutura de ML para prever preços futuros
Para demonstrar, criaremos um modelo de previsão para prever o valor base esperado futuro de uma meta de investimento hipotética, onde:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Como este é um problema de regressão, avaliaremos o modelo em RMSE (Erro Quadrático Médio). Também usaremos o PNL Total como critério de avaliação
Nota: Para conhecimento matemático relevante sobre RMSE, consulte o conteúdo relevante da Enciclopédia Baidu
- Nosso objetivo: criar um modelo que torne os valores previstos o mais próximo possível de Y.
Etapa 2: coletar dados confiáveis
Colete e limpe dados que podem ajudar você a resolver o problema em questão
Quais dados você precisa considerar para ter poder preditivo para a variável alvo Y? Se estivermos prevendo preços, você pode usar dados de preço-alvo, dados de volume de negociação-alvo, dados semelhantes para alvos relacionados, indicadores gerais de mercado, como níveis de índice-alvo, preços de outros ativos relacionados, etc.
Você precisará configurar permissões de acesso a esses dados, garantir que eles estejam precisos e resolver dados ausentes (um problema muito comum). Certifique-se também de que seus dados sejam imparciais e representem adequadamente todas as condições de mercado (por exemplo, o mesmo número de cenários de vitória/perda) para evitar viés em seu modelo. Talvez você também precise limpar os dados de dividendos, divisões de portfólio, continuações, etc.
Se você estiver usando a Inventor Quantitative Platform (FMZ.COM), podemos acessar dados globais gratuitos do Google, Yahoo, NSE e Quandl; dados detalhados de futuros de commodities nacionais, como CTP e Yisheng; Binance, OKEX, Huobi e BitMex A Plataforma Quantitativa do Inventor também pré-limpa e filtra esses dados, como divisões de metas de investimento e dados de mercado detalhados, e os apresenta aos desenvolvedores de estratégias em um formato que é fácil de entender para os trabalhadores quantitativos.
Para a conveniência deste artigo, usamos os seguintes dados como o alvo de investimento virtual ‘MQK’. Também usamos uma ferramenta quantitativa muito conveniente chamada Auquan’s Toolbox. Para mais informações, consulte: https://github.com/Auquan / caixa-de-ferramentas-auquan-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Com o código acima, o Auquan’s Toolbox baixou e carregou os dados no dicionário do quadro de dados. Agora precisamos preparar os dados em um formato que preferimos. A função ds.getBookDataByFeature() retorna um dicionário de quadros de dados, um quadro de dados por recurso. Criamos um novo dataframe para ações com todos os recursos.
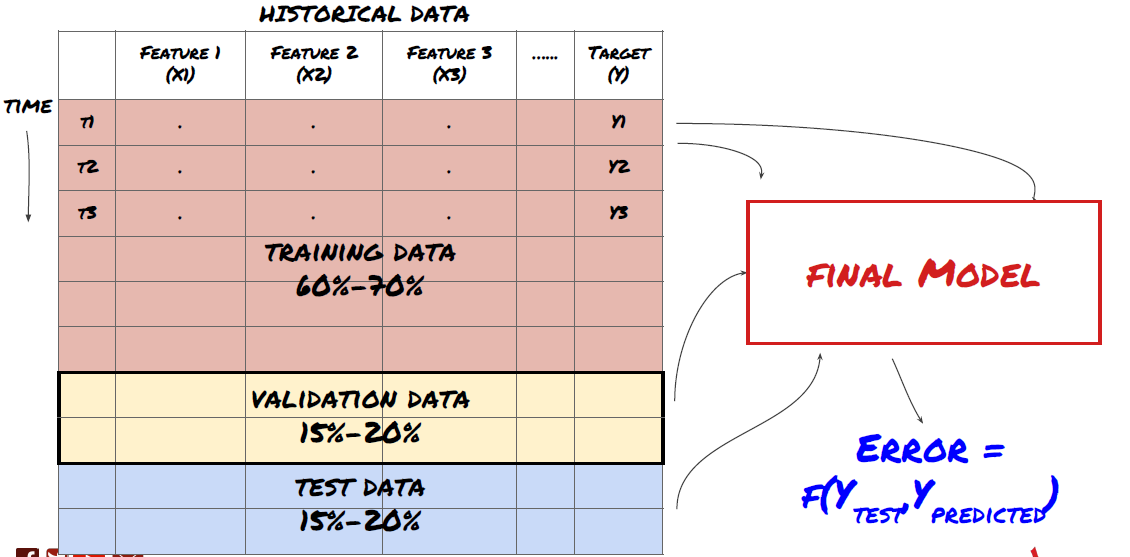
Etapa 3: Divida os dados
- Crie conjuntos de treinamento a partir de dados, faça a validação cruzada e teste esses conjuntos
Este é um passo muito importante! Antes de prosseguir, devemos dividir os dados em um conjunto de dados de treinamento, para treinar seu modelo, e um conjunto de dados de teste, para avaliar o desempenho do modelo. A divisão recomendada é: 60-70% conjunto de treinamento e 30-40% conjunto de teste
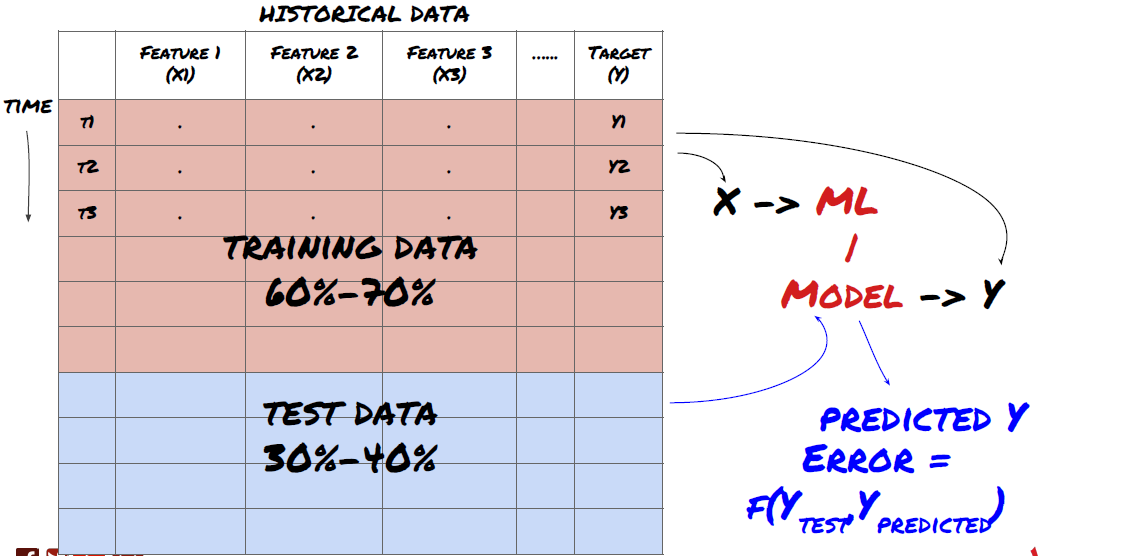
Divida os dados em conjuntos de treinamento e teste
Como os dados de treinamento são usados para avaliar os parâmetros do modelo, seu modelo pode se ajustar excessivamente a esses dados de treinamento e os dados de treinamento podem enganar o desempenho do modelo. Se você não mantiver nenhum dado de teste separado e usar todos os dados para treinamento, não saberá o quão bem ou mal seu modelo funcionará em dados novos e nunca vistos. Esse é um dos principais motivos pelos quais os modelos de ML treinados falham em dados ativos: as pessoas treinam com todos os dados disponíveis e ficam animadas com as métricas dos dados de treinamento, mas o modelo não consegue fazer nenhuma previsão significativa em dados ativos nos quais não foi treinado. .
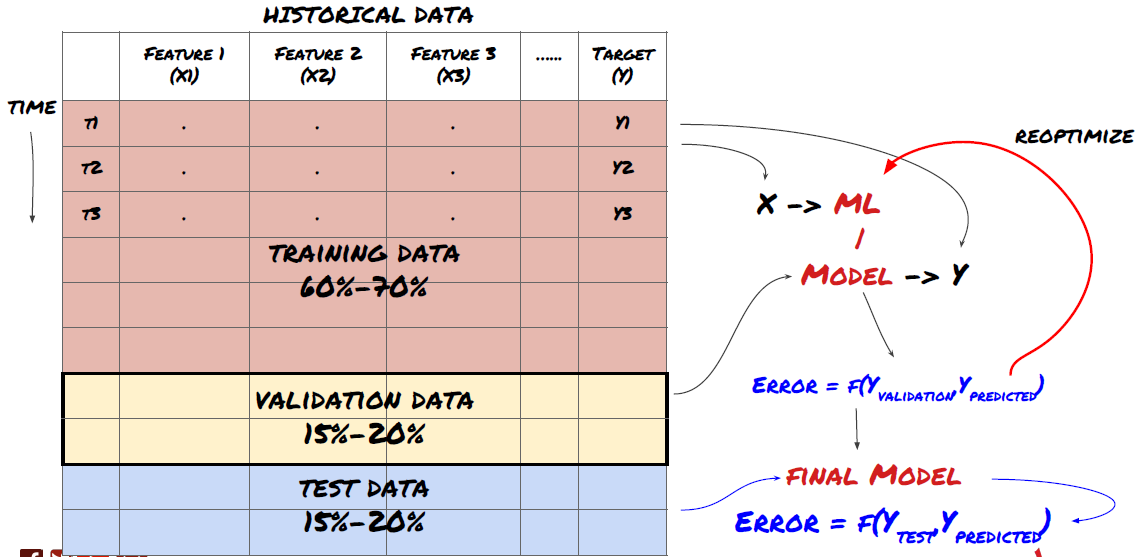
Divida os dados em conjuntos de treinamento, validação e teste
Há problemas com essa abordagem. Se treinarmos repetidamente com dados de treinamento, avaliarmos o desempenho com dados de teste e otimizarmos nosso modelo até ficarmos satisfeitos com o desempenho, incluiremos implicitamente os dados de teste como parte dos dados de treinamento. No final das contas, nosso modelo pode ter um bom desempenho nesse conjunto de dados de treinamento e teste, mas não há garantia de que ele será capaz de prever bem novos dados.
Para resolver esse problema, podemos criar um conjunto de dados de validação separado. Agora você pode treinar com os dados, avaliar o desempenho nos dados de validação, otimizar até ficar satisfeito com o desempenho e, finalmente, testar nos dados de teste. Dessa forma, os dados do teste não serão contaminados e não usaremos nenhuma informação dos dados do teste para melhorar nosso modelo.
Lembre-se, depois de verificar o desempenho dos dados de teste, não volte atrás e tente otimizar ainda mais o modelo. Se você perceber que seu modelo não está dando bons resultados, descarte-o completamente e comece de novo. A divisão sugerida poderia ser 60% de dados de treinamento, 20% de dados de validação e 20% de dados de teste.
Para o nosso problema, temos três conjuntos de dados disponíveis e usaremos um como conjunto de treinamento, o segundo como conjunto de validação e o terceiro como nosso conjunto de teste.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
A cada um deles, adicionamos a variável alvo Y, definida como a média dos próximos cinco valores base
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Etapa 4: Engenharia de recursos
Analisar o comportamento dos dados e criar recursos com poder preditivo
Agora começa a construção propriamente dita do projeto. A regra de ouro da seleção de recursos é que o poder preditivo vem principalmente dos recursos, não do modelo. Você descobrirá que a escolha dos recursos tem um impacto muito maior no desempenho do que a escolha do modelo. Algumas notas sobre a seleção de recursos:
Não selecione arbitrariamente um grande conjunto de recursos sem explorar seu relacionamento com a variável alvo.
Pouca ou nenhuma relação com a variável alvo pode levar ao overfitting
Os recursos que você escolher podem estar altamente correlacionados entre si, caso em que um número menor de recursos também pode explicar o alvo
Geralmente, crio alguns recursos que fazem sentido intuitivo e observo como a variável de destino está correlacionada com esses recursos, bem como como eles estão correlacionados entre si para decidir quais usar.
Você também pode tentar classificar os recursos candidatos com base no Coeficiente Máximo de Informação (MIC), realizar a Análise de Componentes Principais (ACP) e outros métodos.
Transformação/Normalização de Recursos:
Os modelos de ML tendem a ter bom desempenho com normalização. No entanto, a normalização é complicada ao lidar com dados de séries temporais porque o intervalo futuro dos dados é desconhecido. Seus dados podem estar fora do intervalo normalizado, fazendo com que o modelo esteja errado. Mas você ainda pode tentar forçar algum grau de estacionariedade:
Escala: Dividir recursos por desvio padrão ou intervalo interquartil
Centralização: Subtraia a média histórica do valor atual
Normalização: Dois períodos de retrospectiva do acima (x - média) / desvio padrão
Normalização convencional: normaliza os dados para um intervalo de -1 a +1 e centraliza novamente dentro do período de lookback (x-min)/(max-min)
Observe que, como usamos a média histórica, o desvio padrão, o valor máximo ou mínimo durante o período de análise, o valor normalizado do recurso representará diferentes valores reais em momentos diferentes. Por exemplo, se o valor atual de um recurso for 5 e a média móvel de 30 períodos for 4,5, ele será convertido para 0,5 após a centralização. Mais tarde, se a média móvel de 30 períodos se tornar 3, o valor 3,5 se tornará 0,5. Essa pode ser a razão pela qual o modelo está errado. Então, a regularização é complicada e você tem que descobrir o que realmente melhora o desempenho do modelo (se é que melhora alguma coisa).
Para a primeira iteração do nosso problema, criamos um grande número de recursos usando os parâmetros de mistura. Mais tarde tentaremos ver se podemos reduzir o número de recursos
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Etapa 5: Seleção do modelo
Escolha o modelo estatístico/ML apropriado para o problema escolhido
A escolha do modelo depende de como o problema é formulado. Você está resolvendo um problema de aprendizado supervisionado (cada ponto X na matriz de recursos é mapeado para uma variável alvo Y) ou não supervisionado (nenhum mapeamento é fornecido e o modelo tenta aprender padrões desconhecidos)? Você está resolvendo uma regressão (prevendo o preço real em um momento futuro) ou um problema de classificação (prevendo apenas a direção (aumento/diminuição) do preço em um momento futuro)?

Aprendizagem supervisionada ou não supervisionada

Regressão ou Classificação
Alguns algoritmos comuns de aprendizado supervisionado podem ajudar você a começar:
LinearRegression(parâmetros, regressão)
Regressão logística (parâmetros, classificação)
Algoritmo K-vizinho mais próximo (KNN) (baseado em instância, regressão)
SVM, SVR (parâmetros, classificação e regressão)
Árvore de decisão
Floresta de decisão
Recomendo começar com um modelo simples, como regressão linear ou logística, e construir modelos mais complexos a partir daí, conforme necessário. Também é recomendável que você leia a matemática por trás do modelo em vez de usá-lo cegamente como uma caixa-preta.
Etapa 6: Treinamento, validação e otimização (repita as etapas 4 a 6)
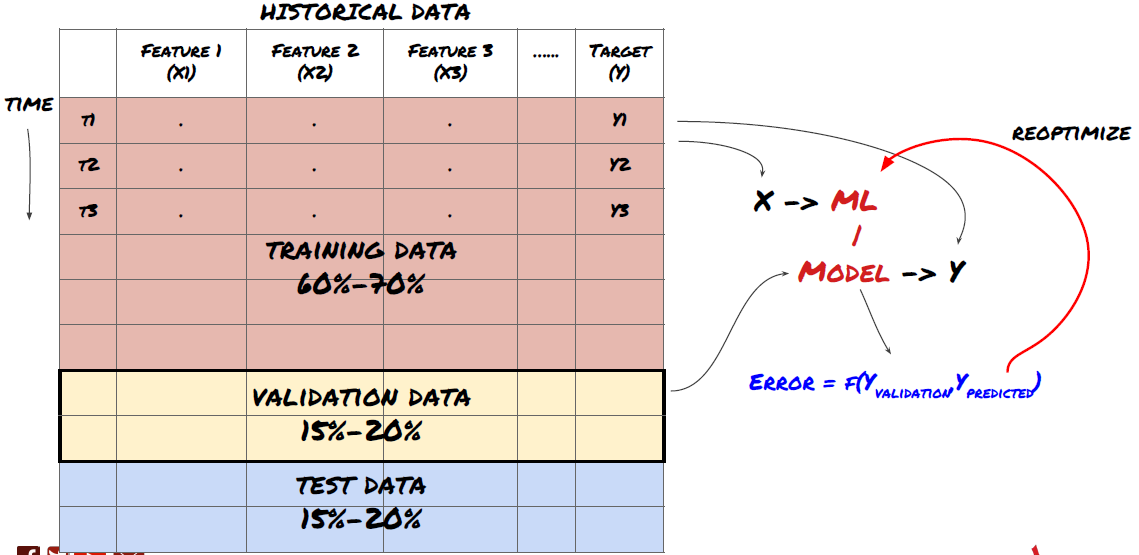
Treine e otimize seu modelo usando os conjuntos de dados de treinamento e validação
Agora você está pronto para finalmente construir seu modelo. Nesta fase, você está apenas iterando no modelo e nos parâmetros do modelo. Treine seu modelo nos dados de treinamento, meça seu desempenho nos dados de validação e depois volte, otimize, treine novamente e avalie. Se você não estiver satisfeito com o desempenho de um modelo, tente usar um modelo diferente. Você passa por essa fase várias vezes até finalmente ter um modelo com o qual esteja satisfeito.
Somente quando tiver um modelo que goste é que você poderá prosseguir para o próximo passo.
Para o nosso problema de demonstração, vamos começar com uma regressão linear simples
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
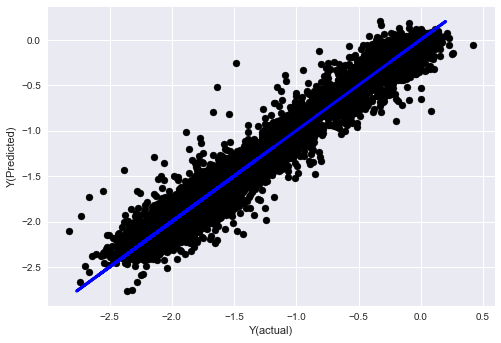
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
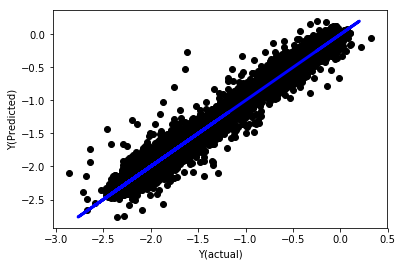
Regressão linear sem normalização
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Observe os coeficientes do modelo. Não podemos realmente compará-los ou dizer quais são importantes porque todos eles se enquadram em escalas diferentes. Vamos tentar normalizar para colocá-los na mesma escala e também impor alguma estacionariedade.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
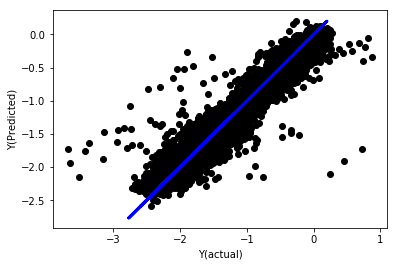
Regressão Linear Normalizada
Mean squared error: 0.05
Variance score: 0.90
Este modelo não é uma melhoria em relação ao anterior, mas também não é pior. Agora podemos comparar os coeficientes e ver quais são realmente significativos.
Vamos olhar para os coeficientes
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
O resultado é:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Podemos ver claramente que algumas características têm coeficientes mais altos em comparação a outras e provavelmente têm maior poder preditivo.
Vamos analisar a correlação entre diferentes características.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
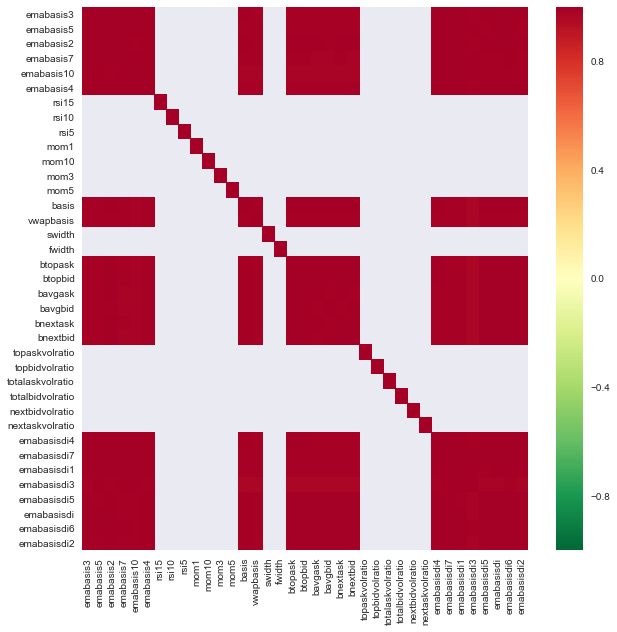
Correlação entre características
Áreas vermelho-escuras indicam variáveis altamente correlacionadas. Vamos criar/modificar alguns recursos novamente e tentar melhorar nosso modelo.
Por exemplo, posso facilmente descartar recursos como emabasisdi7, que são apenas combinações lineares de outros recursos.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
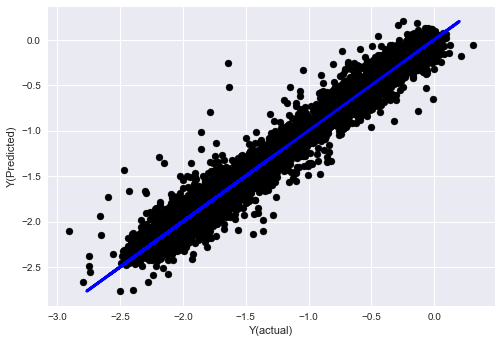
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Veja, não há nenhuma mudança no desempenho do nosso modelo, precisamos apenas de alguns recursos para explicar nossa variável alvo. Sugiro que você experimente mais dos recursos acima, experimente novas combinações etc. para ver o que pode melhorar nosso modelo.
Também podemos testar modelos mais complexos para ver se alterações no modelo podem melhorar o desempenho.
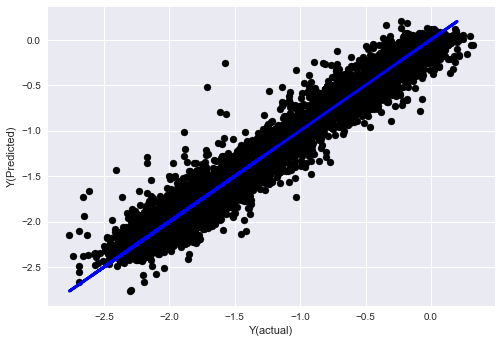
- Algoritmo K-vizinho mais próximo (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
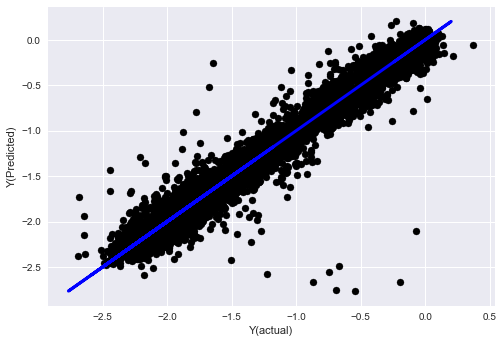
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Árvore de decisão
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Etapa 7: Faça o backtest dos dados de teste
Verifique o desempenho em dados de amostra reais
Desempenho de backtest no conjunto de dados de teste (intocado)
Este é um momento crítico. Começamos pelo último passo, executando nosso modelo final otimizado nos dados de teste que separamos no início e que não tocamos até agora.
Isso fornece expectativas realistas sobre o desempenho do seu modelo em dados novos e nunca vistos quando você começar a negociar ao vivo. Portanto, é necessário garantir que você tenha um conjunto de dados limpo que não tenha sido usado para treinar ou validar o modelo.
Se você não gostar dos resultados do backtest em seus dados de teste, descarte o modelo e comece de novo. Nunca volte e reotimize seu modelo, isso levará ao overfitting! (Também é recomendável criar um novo conjunto de dados de teste, pois esse conjunto de dados agora está contaminado; ao descartar o modelo, já sabemos implicitamente algo sobre o conjunto de dados).
Aqui ainda usaremos a caixa de ferramentas de Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
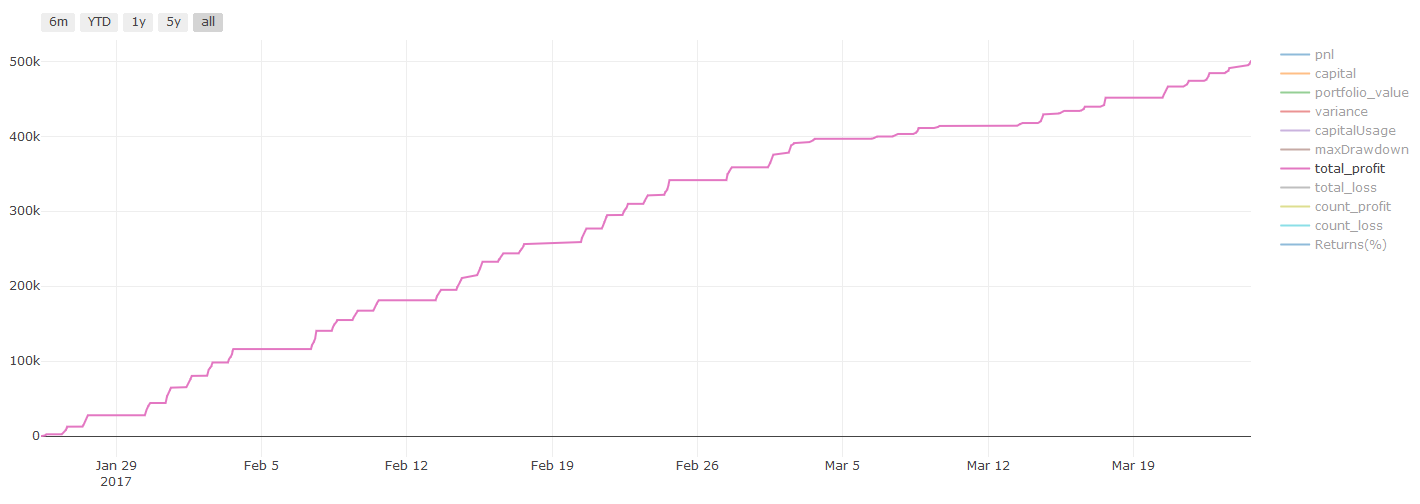
Resultados do backtest, o Pnl é calculado em dólares americanos (o Pnl não inclui custos de transação e outras taxas)
Etapa 8: Outras maneiras de melhorar o modelo
Validação contínua, aprendizagem em conjunto, ensacamento e reforço
Além de coletar mais dados, criar melhores recursos ou testar mais modelos, aqui estão algumas coisas que você pode tentar melhorar.
1. Verificação contínua
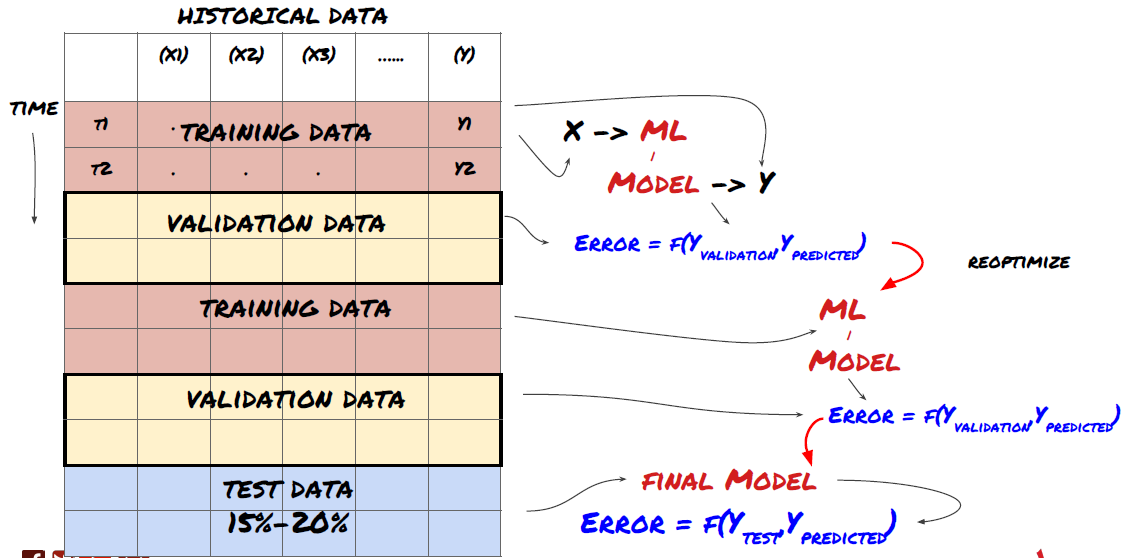
Validação Contínua
As condições de mercado raramente permanecem constantes. Digamos que você tenha um ano de dados e use dados de janeiro a agosto para treinamento e dados de setembro a dezembro para testar seu modelo. Você pode acabar treinando para um conjunto muito específico de condições de mercado. Talvez não tenha havido volatilidade de mercado no primeiro semestre do ano, e algumas notícias extremas fizeram o mercado subir bruscamente em setembro. Seu modelo não será capaz de aprender esse padrão e lhe dará resultados de previsão de lixo.
Pode ser melhor tentar avançar na validação, treinando em janeiro-fevereiro, validando em março, retreinando em abril-maio, validando em junho e assim por diante.
2. Aprendizagem em conjunto
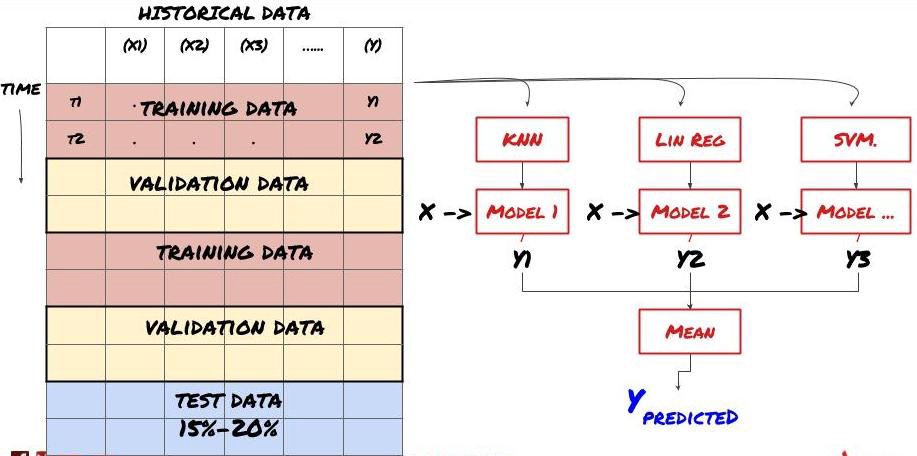
Aprendizagem em conjunto
Alguns modelos podem funcionar bem na previsão de certos cenários, mas podem apresentar sobreajuste significativo na previsão de outros cenários ou em certas situações. Uma maneira de reduzir erros e overfitting é usar um conjunto de modelos diferentes. Sua previsão será a média das previsões feitas por muitos modelos, e os erros de diferentes modelos podem ser compensados ou reduzidos. Alguns métodos comuns de conjunto são Bagging e Boosting.
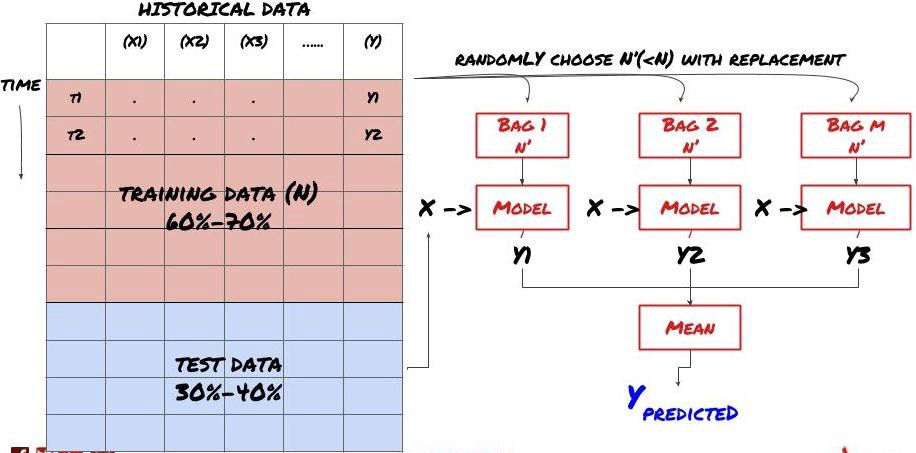
Bagging
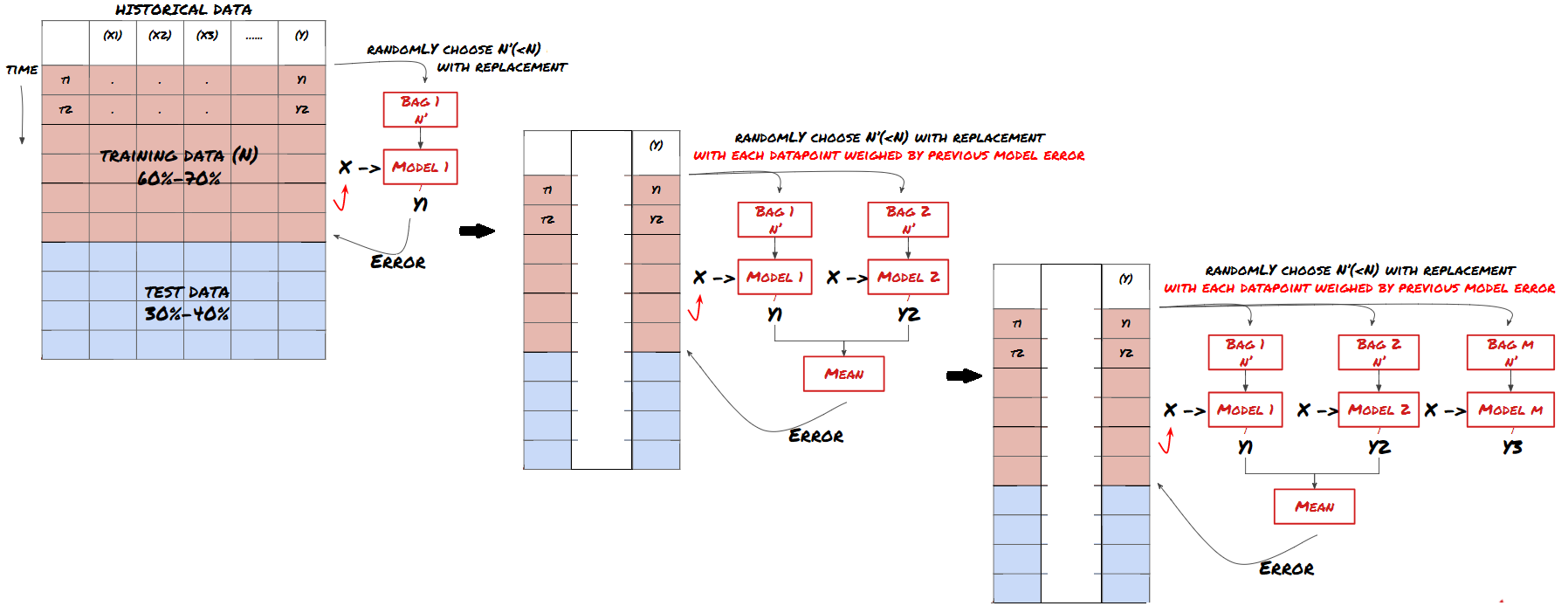
Boosting
Para ser breve, pularei esses métodos, mas você pode encontrar mais informações sobre eles online.
Vamos tentar um método de conjunto para o nosso problema
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Acumulamos muito conhecimento e informação até agora. Vamos rever rapidamente:
Resolva seu problema
Coletando dados confiáveis e limpando dados
Divida os dados em conjuntos de treinamento, validação e teste
Crie recursos e analise seu comportamento
Escolha o modelo de treinamento apropriado com base no comportamento
Use os dados de treinamento para treinar seu modelo e fazer previsões
Verifique o desempenho no conjunto de validação e otimize novamente
Verifique o desempenho final no conjunto de teste
Bem emocionante, certo? Mas ainda não acabou. Agora você só tem um modelo de previsão confiável. Lembra o que realmente queríamos em nossa estratégia? Então você não precisa ainda:
Desenvolver sinais baseados em modelos preditivos para identificar direções de negociação
Desenvolver uma estratégia específica para identificar posições de abertura e fechamento
Sistema de execução para identificação de posições e preços
Todos os itens acima exigem o uso da Inventor Quantitative Platform (FMZ.COM). Na Inventor Quantitative Platform, há uma interface de API altamente encapsulada e completa, bem como funções de ordem e transação globalmente chamáveis, então você não precisa para conectar e adicioná-los um por um. Interfaces de API de diferentes trocas, no Strategy Square da Inventor Quantitative Platform, há muitas estratégias alternativas maduras e completas. Com o método de aprendizado de máquina deste artigo, sua estratégia específica será mais poderosa . O Strategy Square está localizado em: https://www.fmz.com/square
Uma observação importante sobre os custos de transação: Seu modelo lhe dirá quando operar comprado ou vendido no ativo escolhido. No entanto, ele não leva em consideração taxas/custos de transação/volume disponível/stop losses etc. Os custos de transação muitas vezes podem transformar uma negociação lucrativa em prejuízo. Por exemplo, um ativo cujo preço deve aumentar em US\( 0,05 é uma compra, mas se você tiver que pagar US\) 0,10 para fazer essa negociação, você acabará com um prejuízo líquido de US$ 0,05. Nosso incrível gráfico de lucro acima na verdade fica assim depois de levarmos em conta comissões de corretoras, taxas de câmbio e spreads:
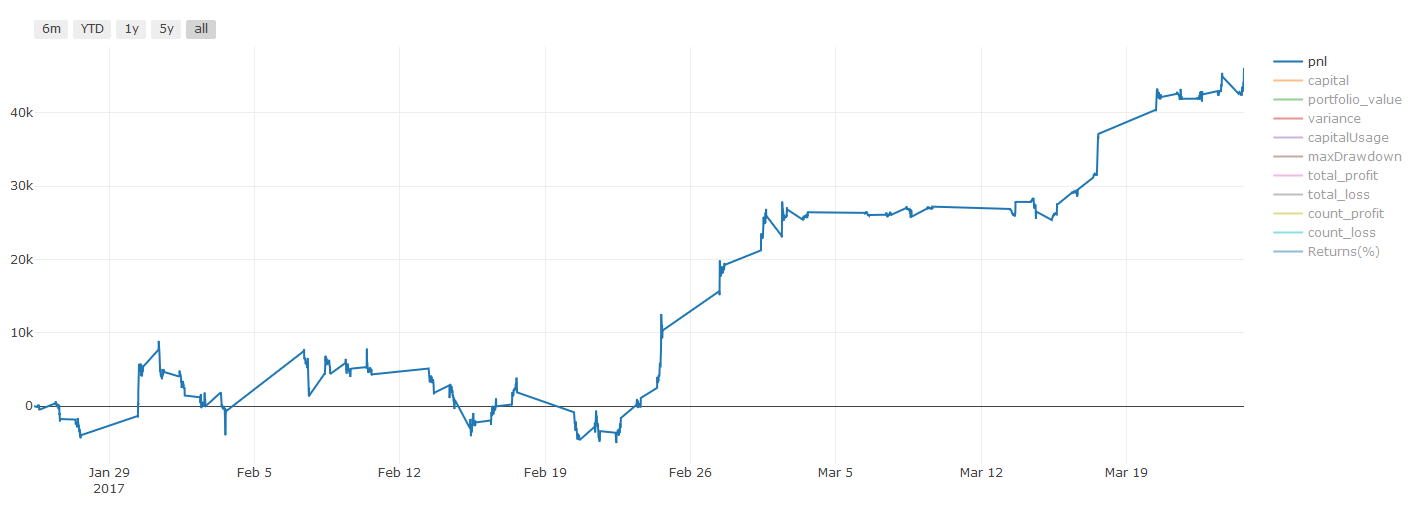
Resultados do backtest após taxas de transação e spreads, Pnl é USD
As taxas de transação e os spreads representam mais de 90% do nosso PNL! Discutiremos isso em detalhes em artigos subsequentes.
Por fim, vamos analisar algumas armadilhas comuns.
O que fazer e o que não fazer
Evite o overfitting com todas as suas forças!
Não treine novamente após cada ponto de dados: esse é um erro comum que as pessoas cometem no desenvolvimento de aprendizado de máquina. Se seu modelo precisa ser treinado novamente após cada ponto de dados, então provavelmente não é um modelo muito bom. Ou seja, ele precisa ser retreinado periodicamente, sempre que fizer sentido (por exemplo, no final de cada semana, se estiver fazendo previsões intradiárias).
Evite viés, especialmente viés de previsão: Esta é outra razão pela qual os modelos não funcionam. Certifique-se de que você não está usando nenhuma informação do futuro. Na maioria das vezes, isso significa não usar a variável de destino Y como um recurso no seu modelo. Você pode usá-lo durante o backtesting, mas ele não estará disponível quando seu modelo estiver sendo executado, o que o tornará inútil.
Cuidado com o viés da mineração de dados: como estamos tentando executar uma série de modelagens em nossos dados para determinar se eles se encaixam, se não houver uma razão específica para isso, certifique-se de executar testes rigorosos para separar padrões aleatórios de padrões reais que podem ocorrer. . Por exemplo, um padrão de tendência ascendente é bem explicado pela regressão linear, mas é provável que seja uma pequena parte de uma caminhada aleatória maior!
Evite overfitting
Isso é tão importante que sinto que precisa ser mencionado novamente.
O overfitting é a armadilha mais perigosa nas estratégias de negociação
Um algoritmo complexo pode ter um desempenho extremamente bom em backtesting, mas falhar miseravelmente em novos dados não vistos. O algoritmo não revela realmente nenhuma tendência nos dados e não tem poder preditivo real. É muito adequado aos dados que vê
Mantenha seu sistema o mais simples possível. Se você perceber que precisa de muitos recursos complexos para explicar seus dados, pode estar com overfitting
Divida seus dados disponíveis em dados de treinamento e teste e sempre verifique o desempenho em dados de amostra reais antes de usar o modelo para negociação ao vivo.