Применение технологии машинного обучения в торговле
 3
3072
3
3072

На эту публикацию меня вдохновили наблюдения за некоторыми распространенными предупреждениями и подводными камнями, которые я сделал после попытки применить методы машинного обучения к решению торговых задач во время исследования данных на платформе Inventor Quant.
Если вы не читали мою предыдущую статью, рекомендуем вам прочитать мое предыдущее руководство по автоматизированной среде исследования данных, созданной на платформе Inventor Quantitative Platform, и системному подходу к разработке торговых стратегий до этой статьи.
Адреса здесь: https://www.fmz.com/digest-topic/4187 и https://www.fmz.com/digest-topic/4169.
О создании исследовательской среды
Это руководство предназначено для энтузиастов, инженеров и специалистов по данным всех уровней квалификации. Независимо от того, являетесь ли вы экспертом в отрасли или новичком в программировании, единственные навыки, которые вам нужны, — это базовое понимание языка программирования Python и достаточные знания операций командной строки. (Достаточно уметь организовать проект по науке о данных)
- Установка Inventor Quant Hoster и настройка Anaconda
Помимо предоставления высококачественных источников данных с крупнейших бирж, количественная платформа Inventor FMZ.COM также предоставляет богатый набор интерфейсов API, которые помогают нам выполнять автоматизированные транзакции после завершения анализа данных. Этот набор интерфейсов включает в себя практические инструменты, такие как запрос информации о счете, запрос максимальной, минимальной, цены открытия, закрытия, объема торгов, различных часто используемых индикаторов технического анализа различных основных бирж и т. д., особенно для подключения к основным основным биржам в реальном времени. Торговые процессы. Открытый интерфейс API обеспечивает мощную техническую поддержку.
Все упомянутые выше функции инкапсулированы в систему, похожую на Docker. Все, что нам нужно сделать, это купить или арендовать собственную службу облачных вычислений, а затем развернуть систему Docker.
В официальном названии Inventor Quantitative Platform эта система Docker называется хост-системой.
Более подробную информацию о том, как развертывать хосты и роботов, можно найти в моей предыдущей статье: https://www.fmz.com/bbs-topic/4140
Читатели, желающие приобрести собственный хост для развертывания сервера облачных вычислений, могут обратиться к этой статье: https://www.fmz.com/bbs-topic/2848
После успешного развертывания сервиса облачных вычислений и хост-системы мы установим самый мощный инструмент Python: Anaconda.
Чтобы реализовать все необходимые для этой статьи программные среды (зависимые библиотеки, управление версиями и т. д.), проще всего использовать Anaconda. Это пакетная экосистема Python для обработки и анализа данных, а также менеджер зависимостей.
Поскольку мы устанавливаем Anaconda на облачный сервис, мы рекомендуем вам установить систему Linux и версию Anaconda для командной строки на облачном сервере.
Информацию о способе установки Anaconda см. в официальном руководстве Anaconda: https://www.anaconda.com/distribution/
Если вы опытный программист на Python и не чувствуете необходимости использовать Anaconda, это совершенно нормально. Я предполагаю, что вам не нужна помощь в установке необходимых зависимостей, и вы можете пропустить этот раздел.
Разработать торговую стратегию
Окончательный результат торговой стратегии должен отвечать на следующие вопросы:
Направление: Определить, является ли актив дешевым, дорогим или справедливо оцененным.
Условия открытия: если цена актива низкая или высокая, вам следует открывать длинную или короткую позицию.
Закрытие сделки: если цена актива справедлива и у нас есть позиция по этому активу (предыдущая покупка или продажа), следует ли закрыть позицию?
Диапазон цен: цена (или диапазон), по которой открывается сделка.
Количество: объем торгуемых средств (например, объем цифровой валюты или количество лотов товарных фьючерсов)
Для ответа на каждый из этих вопросов можно использовать машинное обучение, но в оставшейся части статьи мы сосредоточимся на ответе на первый вопрос — о направлении торговли.
Стратегический подход
Существует два типа подходов к построению стратегий: один основан на моделировании, а другой — на интеллектуальном анализе данных. Это два принципиально противоположных подхода.
При построении стратегии на основе модели мы начинаем с модели неэффективности рынка, строим математические выражения (например, цены, доходность) и тестируем их эффективность в течение более длительных периодов времени. Модель обычно представляет собой упрощенную версию реальной сложной модели, и ее значимость и устойчивость в долгосрочной перспективе требуют проверки. К этой категории относятся обычные стратегии следования за трендом, возврата к среднему значению и арбитражные стратегии.
С другой стороны, мы сначала ищем ценовые закономерности и пытаемся использовать алгоритмы в методах интеллектуального анализа данных. Причины возникновения этих закономерностей не важны, поскольку достоверно лишь то, что они будут повторяться в будущем. Это слепой метод анализа, и нам нужна тщательная проверка, чтобы отличить реальные закономерности от случайных. К этой категории относятся «Метод проб и ошибок», «Шаблоны столбчатых диаграмм» и «Регрессия массы признаков».
Очевидно, что машинное обучение легко поддается методам интеллектуального анализа данных. Давайте рассмотрим, как машинное обучение можно использовать для создания торговых сигналов посредством интеллектуального анализа данных.
В примерах кода используется инструмент бэктестинга и API-интерфейс автоматизированной торговли на базе количественной платформы Inventor. После развертывания хостера и установки Anaconda в разделе выше, вам нужно только установить нужную нам библиотеку анализа науки о данных и известную модель машинного обучения scikit-learn. Мы не будем вдаваться в подробности этой части.
pip install -U scikit-learn
Использование машинного обучения для создания сигналов торговой стратегии
- Интеллектуальный анализ данных
Прежде чем мы начнем, стандартная задача машинного обучения выглядит так:
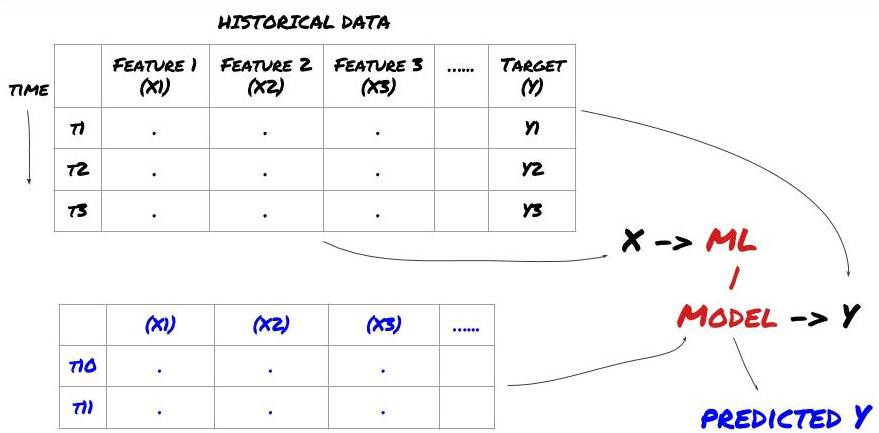
Рамки проблем машинного обучения
Создаваемые нами признаки должны обладать некоторой предсказательной силой (X), мы хотим предсказать целевую переменную (Y) и использовать исторические данные для обучения модели МО, которая может предсказать Y как можно ближе к фактическому значению. Наконец, мы используем эту модель для прогнозирования новых данных, где Y неизвестен. Это подводит нас к первому шагу:
Шаг 1: Определите проблему
- Что вы хотите предсказать? Какой прогноз можно считать хорошим? Как вы оцениваете результаты прогноза?
То есть, в нашей вышеизложенной схеме, что такое Y?
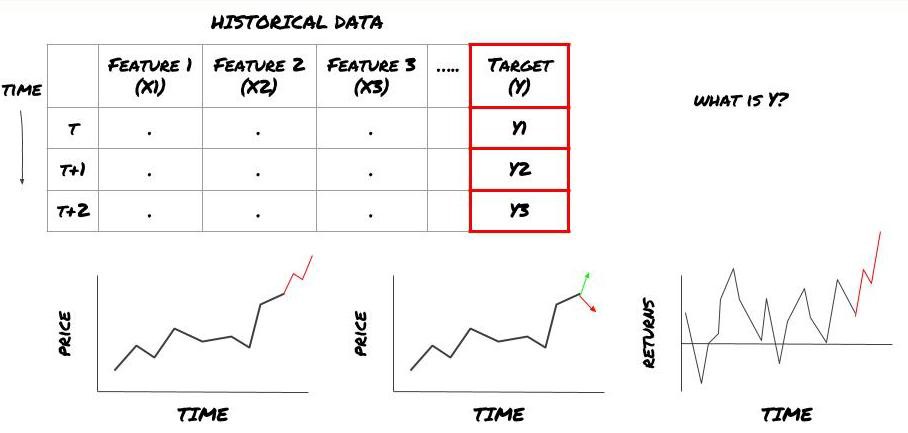
Что вы хотите предсказать?
Хотите ли вы прогнозировать будущие цены, будущую доходность/PNL, сигналы покупки/продажи, оптимизировать распределение портфеля и попытаться эффективно совершать сделки и т. д.?
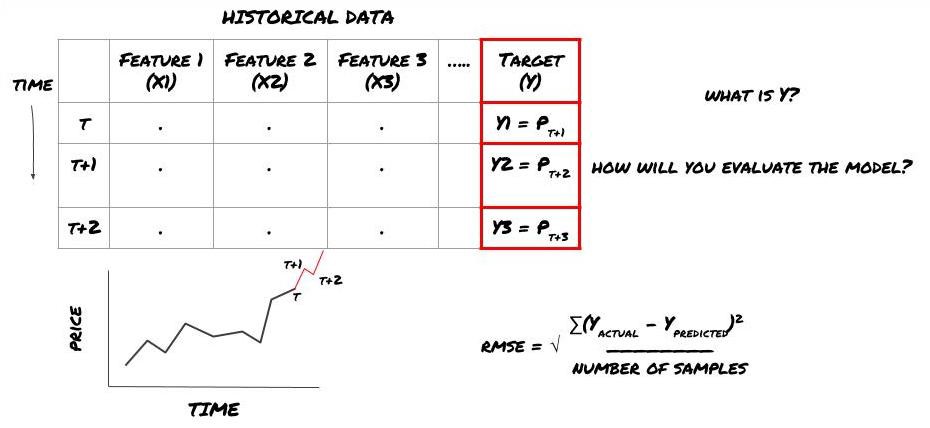
Предположим, мы пытаемся предсказать цену на следующую временную метку. В этом случае Y(t) = Цена(t+1). Теперь мы можем дополнить нашу структуру историческими данными.
Обратите внимание, что Y(t) известно только при бэктестинге, но при использовании нашей модели мы не будем знать цену в момент времени t (t+1). Мы используем нашу модель для прогнозирования Y(прогноз, t) и сравниваем его с фактическим значением только в момент времени t+1. Это означает, что вы не можете использовать Y в качестве признака в прогностической модели.
Узнав нашу цель Y, мы также можем решить, как оценивать наши прогнозы. Это важно для различения различных моделей, которые мы будем пробовать на наших данных. В зависимости от решаемой задачи выберите метрику для измерения эффективности нашей модели. Например, если мы прогнозируем цены, мы можем использовать в качестве метрики среднеквадратичную ошибку. Некоторые часто используемые индикаторы (скользящая средняя, MACD, показатель дисперсии и т. д.) предварительно закодированы в наборе инструментов Inventor Quant, и вы можете вызывать эти индикаторы глобально через интерфейс API.
Структура машинного обучения для прогнозирования будущих цен
Для демонстрации мы создадим модель прогнозирования для прогнозирования будущей ожидаемой базовой стоимости гипотетической инвестиционной цели, где:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Поскольку это задача регрессии, мы оценим модель по RMSE (среднеквадратичная ошибка). Мы также будем использовать общий Pnl в качестве критерия оценки.
Примечание: для получения соответствующих математических знаний о RMSE обратитесь к соответствующему контенту энциклопедии Baidu.
- Наша цель: создать модель, которая сделает прогнозируемые значения максимально близкими к Y.
Шаг 2: Соберите достоверные данные
Собирайте и очищайте данные, которые могут помочь вам решить имеющуюся проблему.
Какие данные необходимо учитывать, чтобы иметь предсказательную силу для целевой переменной Y? Если мы прогнозируем цены, можно использовать данные о целевых ценах, данные о целевых объемах торгов, аналогичные данные для связанных целей, общие рыночные показатели, такие как целевые уровни индексов, цены других связанных активов и т. д.
Вам необходимо будет настроить разрешения на доступ к этим данным, убедиться в точности ваших данных и устранить недостающие данные (очень распространенная проблема). Также убедитесь, что ваши данные непредвзяты и адекватно отражают все рыночные условия (например, одинаковое количество сценариев выигрыша/проигрыша), чтобы избежать предвзятости в вашей модели. Вам также может потребоваться очистить данные по дивидендам, дроблению портфеля, продолжениям и т. д.
Если вы используете платформу Inventor Quantitative Platform (FMZ.COM), мы можем получить доступ к бесплатным глобальным данным от Google, Yahoo, NSE и Quandl; подробным данным по внутренним товарным фьючерсам, таким как CTP и Yisheng; Binance, OKEX, Huobi и BitMex. Количественная платформа Inventor также предварительно очищает и фильтрует эти данные, такие как дробление инвестиционных целей и подробные рыночные данные, и представляет их разработчикам стратегии в формате, который легко понять специалистам по количественному анализу.
Для удобства этой статьи мы используем следующие данные в качестве виртуальной инвестиционной цели «MQK». Мы также используем очень удобный количественный инструмент под названием Auquan’s Toolbox. Для получения дополнительной информации, пожалуйста, перейдите по ссылке: https://github.com/Auquan / auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
С помощью приведенного выше кода Auquan Toolbox загрузил и загрузил данные в словарь фрейма данных. Теперь нам нужно подготовить данные в удобном для нас формате. Функция ds.getBookDataByFeature() возвращает словарь фреймов данных, по одному фрейму данных на каждый признак. Мы создаем новый фреймворк данных для акций со всеми функциями.
Шаг 3: Разделение данных
- Создавайте обучающие наборы из данных, проводите перекрестную проверку и тестирование этих наборов.
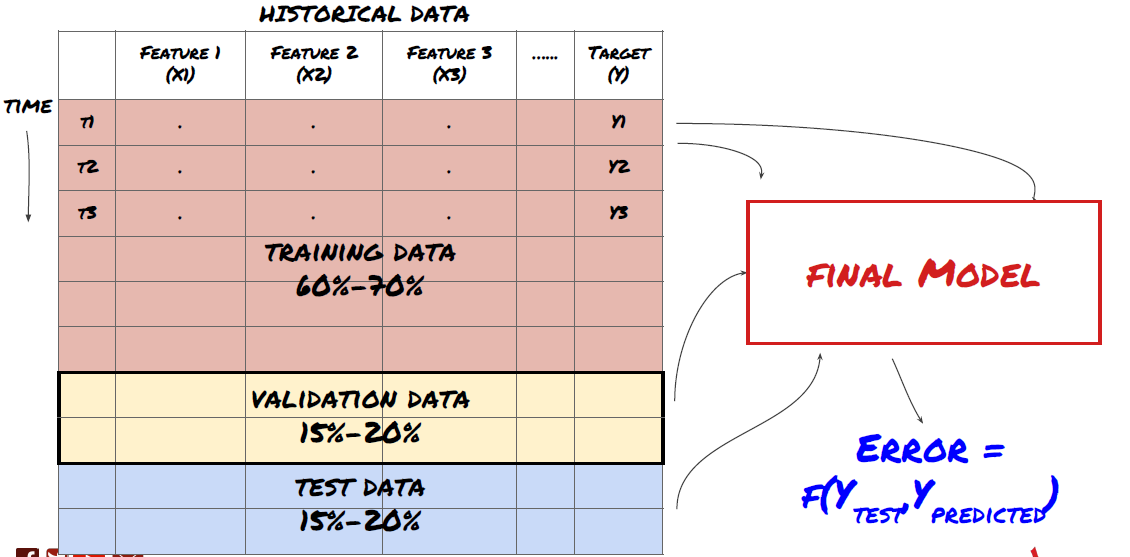
Это очень важный шаг! Прежде чем продолжить, нам следует разделить данные на обучающий набор данных для обучения модели и тестовый набор данных для оценки эффективности модели. Рекомендуемое разделение: 60–70 % обучающего набора и 30–40 % тестового набора.
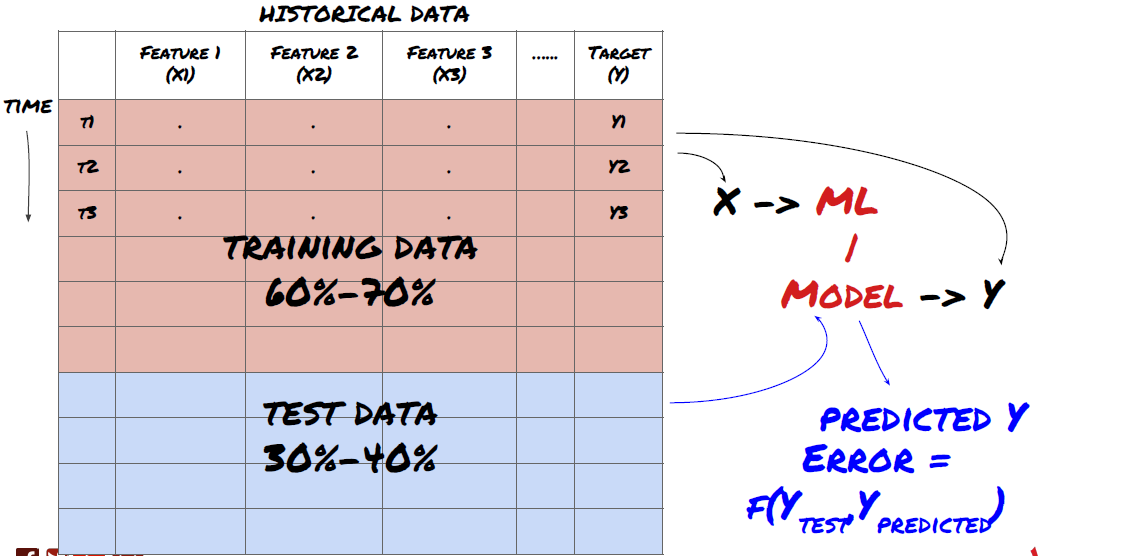
Разделите данные на обучающие и тестовые наборы.
Поскольку обучающие данные используются для оценки параметров модели, ваша модель может переобучиться этим обучающим данным, а обучающие данные могут исказить эффективность модели. Если вы не храните отдельные тестовые данные и используете все данные для обучения, вы не узнаете, насколько хорошо или плохо ваша модель будет работать на новых, невиданных данных. Это одна из основных причин, по которой обученные модели МО терпят неудачу на реальных данных: люди обучаются на всех доступных данных и приходят в восторг от показателей обучающих данных, но модель не может сделать никаких значимых прогнозов на реальных данных, на которых она не обучалась. .
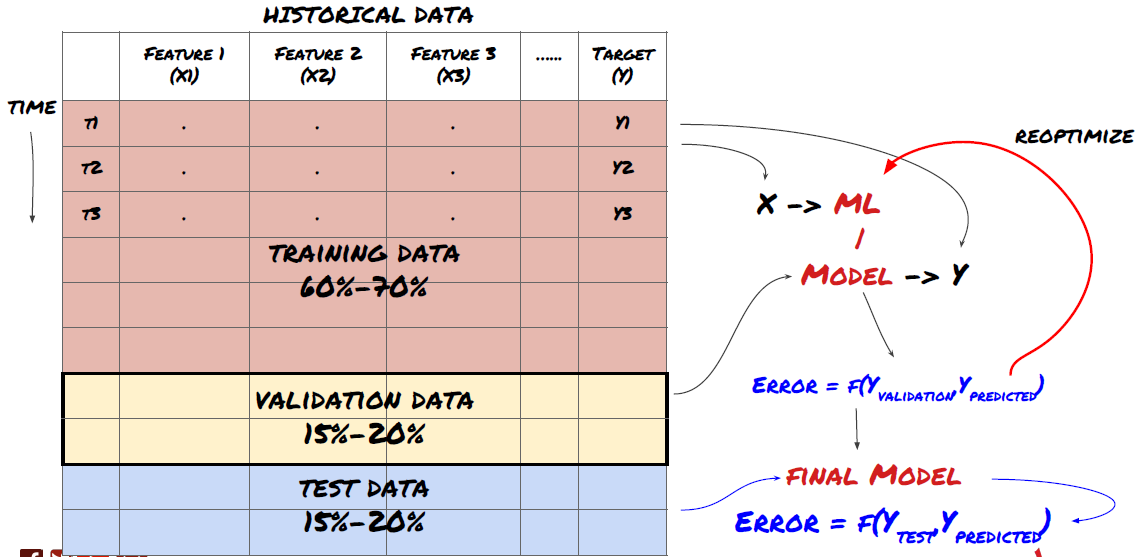
Разделите данные на обучающие, проверочные и тестовые наборы.
Такой подход имеет свои недостатки. Если мы многократно обучаем модель на обучающих данных, оцениваем ее эффективность на тестовых данных и оптимизируем ее до тех пор, пока не будем удовлетворены ее эффективностью, мы неявно включаем тестовые данные в обучающие данные. В конечном итоге наша модель может хорошо работать на этом наборе обучающих и тестовых данных, но нет никакой гарантии, что она сможет хорошо предсказывать новые данные.
Чтобы решить эту проблему, мы можем создать отдельный набор проверочных данных. Теперь вы можете обучиться на данных, оценить производительность на проверочных данных, оптимизировать систему до тех пор, пока не будете удовлетворены ее производительностью, и, наконец, провести тестирование на тестовых данных. Таким образом, тестовые данные не будут искажены, и мы не будем использовать какую-либо информацию из тестовых данных для улучшения нашей модели.
Помните, что после проверки производительности на тестовых данных не следует возвращаться к предыдущей версии и пытаться оптимизировать модель дальше. Если вы обнаружите, что ваша модель не дает хороших результатов, полностью откажитесь от нее и начните заново. Предлагаемое разделение может быть следующим: 60% обучающих данных, 20% проверочных данных и 20% тестовых данных.
Для решения нашей задачи у нас есть три набора данных, один из которых мы будем использовать в качестве обучающего, второй — в качестве проверочного, а третий — в качестве тестового.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
К каждому из них мы добавляем целевую переменную Y, определяемую как среднее значение следующих пяти базисных значений.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Шаг 4: Разработка функций
Анализируйте поведение данных и создавайте признаки с предсказательной силой
Теперь начинается фактическое строительство проекта. Золотое правило выбора признаков заключается в том, что предсказательная сила исходит в первую очередь от признаков, а не от модели. Вы обнаружите, что выбор функций оказывает гораздо большее влияние на производительность, чем выбор модели. Некоторые замечания по выбору функций:
Не выбирайте произвольно большой набор признаков, не изучив их связь с целевой переменной.
Небольшая или отсутствующая связь с целевой переменной может привести к переобучению.
Выбранные вами признаки могут быть тесно связаны друг с другом, и в этом случае меньшее количество признаков также может объяснить цель.
Обычно я создаю некоторые интуитивно понятные признаки и смотрю, как целевая переменная коррелирует с этими признаками, а также как они коррелируют друг с другом, чтобы решить, какие из них использовать.
Вы также можете попытаться ранжировать потенциальные признаки на основе максимального информационного коэффициента (MIC), выполнить анализ главных компонент (PCA) и другие методы.
Преобразование/нормализация признаков:
Модели МО, как правило, хорошо работают при нормализации. Однако при работе с данными временных рядов нормализация представляет собой сложную задачу, поскольку будущий диапазон данных неизвестен. Ваши данные могут выходить за пределы нормализованного диапазона, что приведет к неверной модели. Но вы все равно можете попытаться добиться некоторой степени стационарности:
Масштабирование: разделение признаков по стандартному отклонению или межквартильному размаху.
Центрирование: вычтите историческое среднее значение из текущего значения.
Нормализация: два периода ретроспективного анализа вышеприведенных данных (x - среднее) / стандартное отклонение
Обычная нормализация: нормализовать данные до диапазона от -1 до +1 и повторно центрировать в пределах периода ретроспективного анализа (x-мин)/(макс-мин)
Обратите внимание, что поскольку мы используем историческое скользящее среднее, стандартное отклонение, максимальное или минимальное значение за рассматриваемый период, нормализованное значение признака будет представлять собой различные фактические значения в разное время. Например, если текущее значение признака равно 5, а скользящее 30-периодное среднее равно 4,5, то после центрирования оно будет преобразовано в 0,5. Позже, если 30-периодная скользящая средняя станет равна 3, значение 3,5 станет 0,5. Это может быть причиной того, что модель неверна. Поэтому регуляризация — сложная задача, и вам нужно выяснить, что на самом деле улучшает производительность модели (если вообще улучшает).
Для первой итерации нашей задачи мы создали большое количество признаков, используя параметры смешивания. Позже мы попробуем посмотреть, сможем ли мы уменьшить количество функций.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Шаг 5: Выбор модели
Выберите подходящую статистическую/ML-модель для выбранной проблемы
Выбор модели зависит от формулировки проблемы. Решаете ли вы задачу контролируемого (каждая точка X в матрице признаков сопоставляется с целевой переменной Y) или неконтролируемого обучения (сопоставление не задано, и модель пытается изучить неизвестные закономерности)? Решаете ли вы задачу регрессии (прогнозирование фактической цены в будущем) или задачу классификации (прогнозирование только направления (увеличение/уменьшение) цены в будущем)?

Контролируемое или неконтролируемое обучение

Регрессия или классификация
Некоторые распространенные алгоритмы контролируемого обучения могут помочь вам начать:
ЛинейнаяРегрессия(параметры, регрессия)
Логистическая регрессия (параметры, классификация)
Алгоритм K-ближайшего соседа (KNN) (регрессионный, основанный на экземплярах)
SVM, SVR (параметры, классификация и регрессия)
Дерево решений
Лес решений
Я рекомендую начать с простой модели, например, линейной или логистической регрессии, и строить на ее основе более сложные модели по мере необходимости. Также рекомендуется ознакомиться с математическими выкладками, лежащими в основе модели, а не слепо использовать ее как черный ящик.
Шаг 6: Обучение, проверка и оптимизация (повторите шаги 4–6)
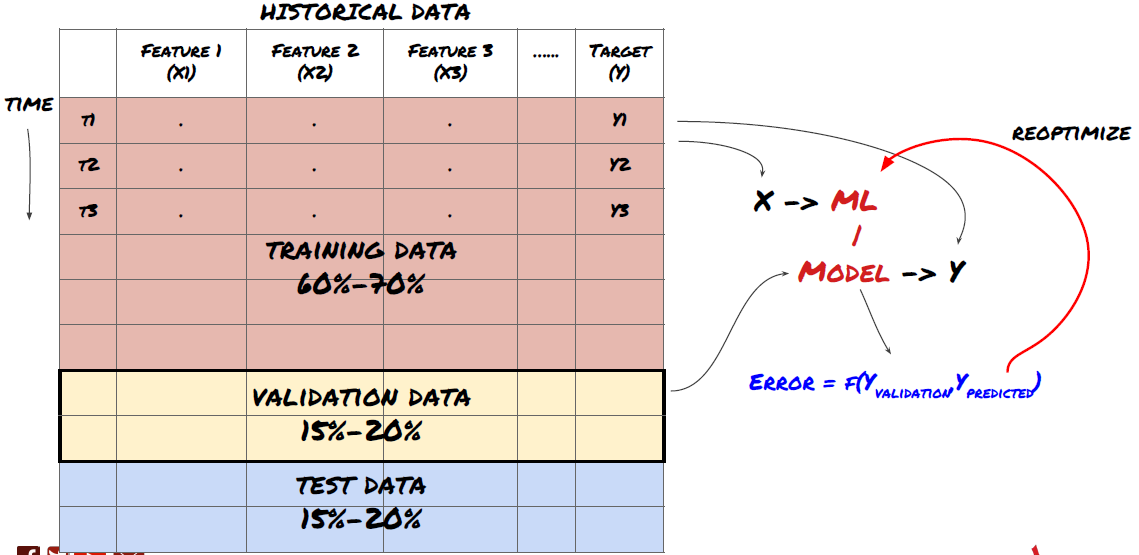
Обучайте и оптимизируйте свою модель, используя обучающие и проверочные наборы данных.
Теперь вы наконец готовы построить свою модель. На этом этапе вы фактически просто повторяете модель и ее параметры. Обучите свою модель на обучающих данных, измерьте ее эффективность на проверочных данных, затем вернитесь, оптимизируйте, повторно обучите и оцените. Если вы не удовлетворены работой модели, попробуйте использовать другую модель. Вы проходите этот этап несколько раз, пока не получите модель, которая вас устроит.
Только после того, как вы найдете понравившуюся модель, переходите к следующему шагу.
Для нашей демонстрационной задачи начнем с простой линейной регрессии.
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
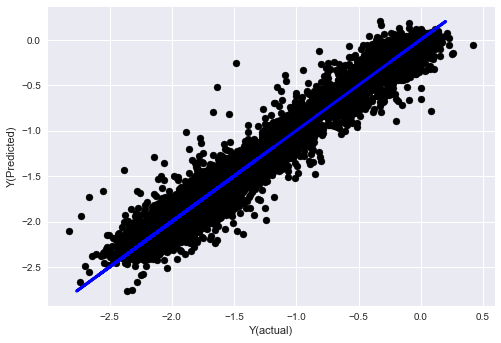
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
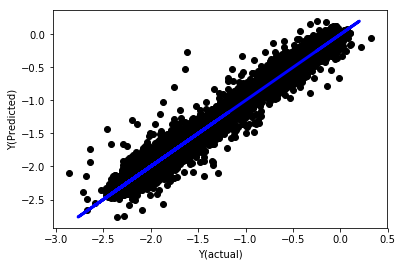
Линейная регрессия без нормализации
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Посмотрите на коэффициенты модели. Мы не можем по-настоящему сравнить их или сказать, какие из них важнее, поскольку все они находятся на разных масштабах. Давайте попробуем нормализовать их, чтобы привести к одному масштабу, а также обеспечить некоторую стационарность.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
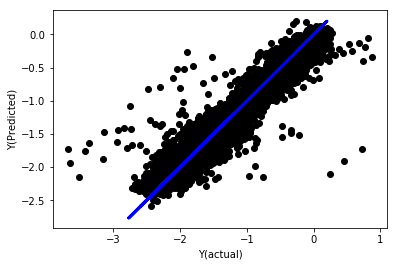
Нормализованная линейная регрессия
Mean squared error: 0.05
Variance score: 0.90
Эта модель не является улучшением предыдущей, но и не хуже. Теперь мы можем сравнить коэффициенты и увидеть, какие из них действительно значимы.
Давайте посмотрим на коэффициенты.
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Результат:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Мы ясно видим, что некоторые признаки имеют более высокие коэффициенты по сравнению с другими признаками и, вероятно, обладают более высокой предсказательной силой.
Давайте рассмотрим корреляцию между различными признаками.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
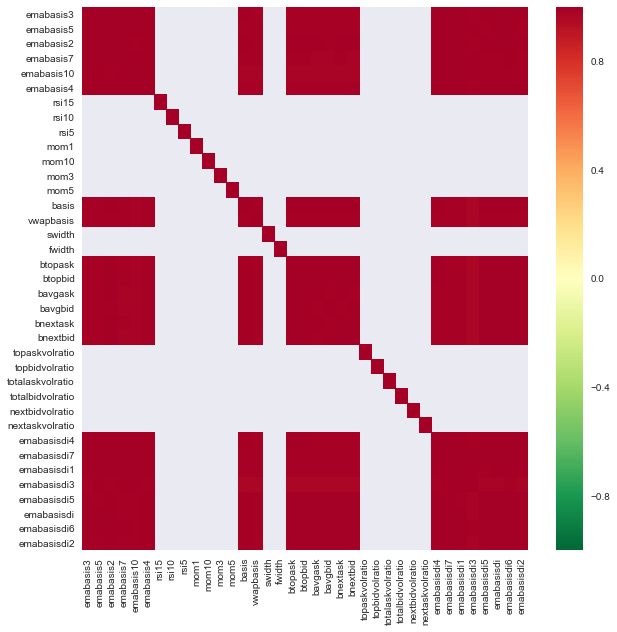
Корреляция между признаками
Темно-красные области обозначают сильно коррелированные переменные. Давайте снова создадим/изменим некоторые функции и попробуем улучшить нашу модель.
Например, я могу легко отбросить такие признаки, как emabasisdi7, которые представляют собой просто линейные комбинации других признаков.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
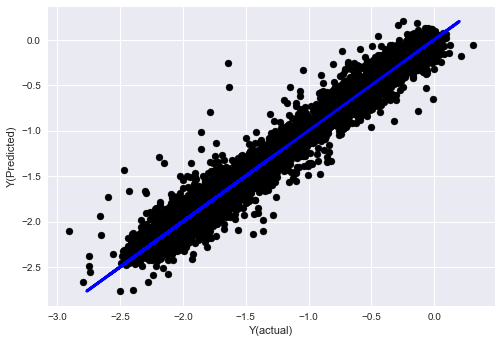
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Видите ли, эффективность нашей модели не изменилась, нам просто нужно несколько признаков, чтобы объяснить нашу целевую переменную. Я предлагаю вам попробовать больше из вышеперечисленных функций, попробовать новые комбинации и т. д., чтобы увидеть, что может улучшить нашу модель.
Мы также можем попробовать более сложные модели, чтобы посмотреть, могут ли изменения в модели улучшить производительность.
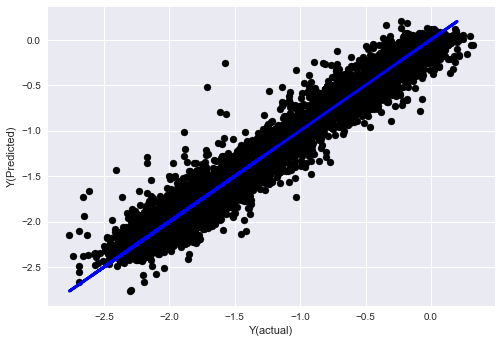
- Алгоритм K-ближайшего соседа (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
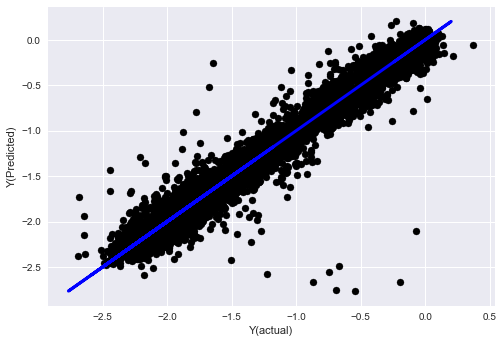
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Дерево решений
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Шаг 7: Проведите бэктест тестовых данных
Проверьте производительность на реальных выборочных данных
Результаты бэктестинга на (нетронутом) тестовом наборе данных
Это критический момент. Начнем с последнего шага, запустив нашу окончательную оптимизированную модель на тестовых данных, которые мы отложили в начале и до сих пор не трогали.
Это дает вам реалистичные ожидания относительно того, как ваша модель будет работать на новых и невиданных данных, когда вы начнете торговать в реальном времени. Поэтому необходимо убедиться, что у вас чистый набор данных, который не использовался для обучения или проверки модели.
Если вам не нравятся результаты бэктестинга на ваших тестовых данных, выбросьте модель и начните заново. Никогда не возвращайтесь и не оптимизируйте модель повторно, это приведет к переобучению! (Также рекомендуется создать новый тестовый набор данных, поскольку этот набор данных теперь загрязнен; при отбрасывании модели мы уже неявно знаем что-то о наборе данных).
Здесь мы по-прежнему будем использовать набор инструментов Auquan.
”` import backtester from backtester.features.feature import Feature from backtester.trading_system import TradingSystem from backtester.sample_scripts.fair_value_params import FairValueTradingParams class Problem1Solver(): def getTrainingDataSet(self): return “trainingData1” def getSymbolsToTrade(self): return [‘MQK’] def getCustomFeatures(self): return {‘my_custom_feature’: MyCustomFeature} def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\