ٹریڈنگ میں مشین لرننگ ٹیکنالوجی کا اطلاق
 3
3072
3
3072

یہ پوسٹ انوینٹر کوانٹ پلیٹ فارم پر میرے ڈیٹا ریسرچ کے دوران ٹریڈنگ کے مسائل پر مشین لرننگ تکنیک کو لاگو کرنے کی کوشش کرنے کے بعد کچھ عام انتباہات اور نقصانات کے میرے مشاہدات سے متاثر ہوئی تھی۔
اگر آپ نے میرا پچھلا مضمون نہیں پڑھا ہے، تو ہم تجویز کرتے ہیں کہ آپ موجد مقداری پلیٹ فارم پر قائم کردہ خودکار ڈیٹا ریسرچ ماحول کے لیے میری پچھلی گائیڈ اور اس مضمون سے پہلے تجارتی حکمت عملیوں کو تیار کرنے کے لیے منظم طریقہ کو پڑھیں۔
پتے یہاں ہیں: https://www.fmz.com/digest-topic/4187 اور https://www.fmz.com/digest-topic/4169۔
تحقیقی ماحول کے قیام کے بارے میں
یہ ٹیوٹوریل تمام مہارتوں کے شوقینوں، انجینئرز، اور ڈیٹا سائنسدانوں کے لیے ڈیزائن کیا گیا ہے چاہے آپ انڈسٹری کے ماہر ہوں یا پروگرامنگ کے نوآموز، آپ کو صرف ایک ہی مہارت کی ضرورت ہے جو Python پروگرامنگ زبان کی بنیادی سمجھ اور کمانڈ لائن آپریشنز کا کافی علم ہے۔ (ڈیٹا سائنس پروجیکٹ ترتیب دینے کی اہلیت کافی ہے)
- انوینٹر کوانٹ ہوسٹر انسٹال کرنا اور ایناکونڈا سیٹ کرنا
اہم مرکزی دھارے کے تبادلے سے اعلیٰ معیار کے ڈیٹا کے ذرائع فراہم کرنے کے علاوہ، موجد مقداری پلیٹ فارم FMZ.COM ڈیٹا کے تجزیہ کو مکمل کرنے کے بعد خودکار لین دین کرنے میں ہماری مدد کرنے کے لیے API انٹرفیس کا ایک بھرپور سیٹ بھی فراہم کرتا ہے۔ انٹرفیس کے اس سیٹ میں عملی ٹولز شامل ہیں جیسے اکاؤنٹ کی معلومات کے بارے میں استفسار کرنا، اعلیٰ، کھولنے، کم، بند ہونے والی قیمتوں، تجارتی حجم، مختلف مرکزی دھارے کے تبادلے کے مختلف عام طور پر استعمال ہونے والے تکنیکی تجزیہ اشارے، وغیرہ، خاص طور پر اصل میں بڑے مرکزی دھارے کے تبادلے سے جڑنے کے لیے۔ تجارتی عمل عوامی API انٹرفیس طاقتور تکنیکی مدد فراہم کرتا ہے۔
مندرجہ بالا تمام خصوصیات ڈوکر کی طرح ایک سسٹم میں شامل ہیں ہمیں اپنی کلاؤڈ کمپیوٹنگ سروس کو خریدنا یا کرایہ پر لینا ہے اور پھر ڈوکر سسٹم کو تعینات کرنا ہے۔
موجد کوانٹیٹیو پلیٹ فارم کے آفیشل نام پر، اس ڈوکر سسٹم کو میزبان سسٹم کہا جاتا ہے۔
میزبانوں اور روبوٹس کو تعینات کرنے کے طریقے کے بارے میں مزید معلومات کے لیے، براہ کرم میرا سابقہ مضمون دیکھیں: https://www.fmz.com/bbs-topic/4140
وہ قارئین جو اپنا کلاؤڈ کمپیوٹنگ سرور تعیناتی میزبان خریدنا چاہتے ہیں اس مضمون کا حوالہ دے سکتے ہیں: https://www.fmz.com/bbs-topic/2848
کلاؤڈ کمپیوٹنگ سروس اور ہوسٹ سسٹم کو کامیابی کے ساتھ تعینات کرنے کے بعد، ہم سب سے طاقتور Python ٹول انسٹال کریں گے: ایناکونڈا
اس مضمون کے لیے درکار تمام متعلقہ پروگرام ماحول کو حاصل کرنے کے لیے (انحصار لائبریریاں، ورژن کا انتظام، وغیرہ)، سب سے آسان طریقہ ایناکونڈا کا استعمال ہے۔ یہ ایک پیکڈ Python ڈیٹا سائنس ایکو سسٹم اور انحصار مینیجر ہے۔
چونکہ ہم کلاؤڈ سروس پر ایناکونڈا انسٹال کر رہے ہیں، اس لیے ہم تجویز کرتے ہیں کہ آپ لینکس سسٹم کے علاوہ ایناکونڈا کا کمانڈ لائن ورژن کلاؤڈ سرور پر انسٹال کریں۔
ایناکونڈا کی تنصیب کے طریقہ کار کے لیے، براہ کرم ایناکونڈا کے آفیشل گائیڈ سے رجوع کریں: https://www.anaconda.com/distribution/
اگر آپ ایک تجربہ کار Python پروگرامر ہیں اور Anaconda استعمال کرنے کی ضرورت محسوس نہیں کرتے ہیں تو یہ بالکل ٹھیک ہے۔ میں فرض کروں گا کہ آپ کو مطلوبہ انحصار کو انسٹال کرنے میں مدد کی ضرورت نہیں ہے اور آپ اس سیکشن کو چھوڑ سکتے ہیں۔
تجارتی حکمت عملی تیار کریں۔
تجارتی حکمت عملی کی حتمی پیداوار کو درج ذیل سوالات کا جواب دینا چاہیے:
سمت: اس بات کا تعین کریں کہ آیا کوئی اثاثہ سستا ہے، مہنگا ہے یا کافی قیمتی ہے۔
کھلنے کی شرائط: اگر اثاثہ کی قیمت سستی یا مہنگی ہے، تو آپ کو طویل یا مختصر جانا چاہیے۔
تجارت بند کریں: اگر اثاثہ کی قیمت مناسب ہے اور اس اثاثہ میں ہماری پوزیشن ہے (پچھلی خرید و فروخت)، کیا آپ کو پوزیشن بند کرنی چاہئے؟
قیمت کی حد: قیمت (یا حد) جس پر تجارت کھولی جاتی ہے۔
مقدار: تجارت کی جانے والی رقوم کی رقم (جیسے ڈیجیٹل کرنسی کی رقم یا کموڈٹی فیوچرز کی بہت سی تعداد)
ان میں سے ہر ایک سوال کا جواب دینے کے لیے مشین لرننگ کا استعمال کیا جا سکتا ہے، لیکن اس مضمون کے باقی حصے کے لیے، ہم پہلے سوال کے جواب پر توجہ مرکوز کریں گے، جو کہ تجارت کی سمت ہے۔
اسٹریٹجک اپروچ
حکمت عملی بنانے کے لیے دو طرح کے طریقے ہیں، ایک ماڈل پر مبنی ہے اور دوسرا ڈیٹا مائننگ پر مبنی ہے۔ یہ دونوں بنیادی طور پر مخالف نقطہ نظر ہیں۔
ماڈل پر مبنی حکمت عملی کی تعمیر میں، ہم مارکیٹ کی ناکارہیوں کے ماڈل کے ساتھ شروعات کرتے ہیں، ریاضی کے تاثرات (جیسے قیمتیں، واپسی) بناتے ہیں اور طویل مدت میں ان کی تاثیر کو جانچتے ہیں۔ ماڈل عام طور پر ایک حقیقی پیچیدہ ماڈل کا ایک آسان ورژن ہوتا ہے، اور اس کی اہمیت اور طویل مدتی استحکام کی تصدیق کرنے کی ضرورت ہے۔ مندرجہ ذیل معمول کا رجحان، مطلب کی تبدیلی اور ثالثی کی حکمت عملی اس زمرے میں آتی ہے۔
دوسری طرف، ہم سب سے پہلے قیمت کے نمونے تلاش کرتے ہیں اور ڈیٹا مائننگ کے طریقوں میں الگورتھم استعمال کرنے کی کوشش کرتے ہیں۔ ان نمونوں کی وجہ کیا ہے یہ اہم نہیں ہے، کیونکہ یہ صرف یقینی ہے کہ پیٹرن مستقبل میں دہراتے رہیں گے۔ یہ ایک اندھا تجزیہ طریقہ ہے اور ہمیں بے ترتیب نمونوں سے حقیقی نمونوں کی شناخت کے لیے سخت معائنہ کی ضرورت ہے۔ “آزمائش اور غلطی”، “بار چارٹ پیٹرن” اور “فیچر ماس ریگریشن” اس زمرے سے تعلق رکھتے ہیں۔
واضح طور پر، مشین لرننگ خود کو ڈیٹا مائننگ کے طریقوں پر آسانی سے قرض دیتی ہے۔ آئیے دیکھتے ہیں کہ کس طرح مشین لرننگ کو ڈیٹا مائننگ کے ذریعے تجارتی سگنل بنانے کے لیے استعمال کیا جا سکتا ہے۔
کوڈ کی مثالیں موجد مقداری پلیٹ فارم پر مبنی بیک ٹیسٹنگ ٹول اور خودکار ٹریڈنگ API انٹرفیس کا استعمال کرتی ہیں۔ مندرجہ بالا سیکشن میں ہوسٹر کو تعینات کرنے اور ایناکونڈا کو انسٹال کرنے کے بعد، آپ کو صرف ڈیٹا سائنس انالیسس لائبریری کو انسٹال کرنے کی ضرورت ہے جس کی ہمیں ضرورت ہے اور ہم اس حصے کے بارے میں تفصیلات میں نہیں جائیں گے۔
pip install -U scikit-learn
تجارتی حکمت عملی کے سگنل بنانے کے لیے مشین لرننگ کا استعمال
- ڈیٹا مائننگ
اس سے پہلے کہ ہم شروع کریں، مشین سیکھنے کا ایک معیاری مسئلہ اس طرح نظر آتا ہے:
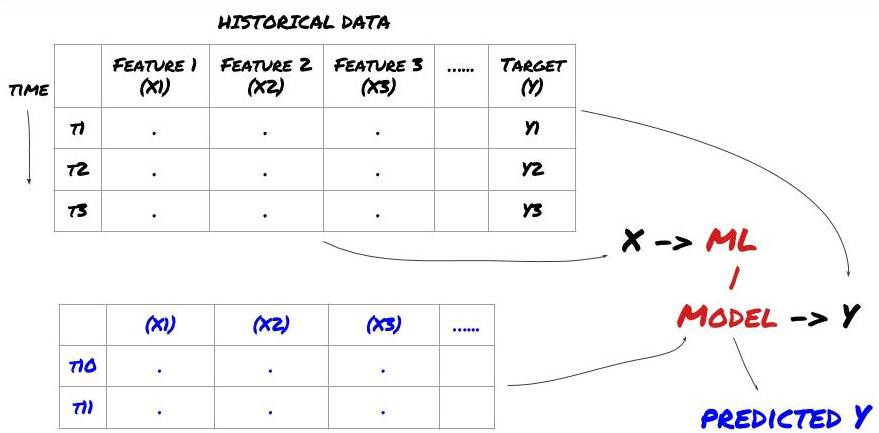
مشین لرننگ پرابلم فریم ورک
ہم جو خصوصیات بنانے جا رہے ہیں ان میں کچھ پیشین گوئی کرنے والی طاقت (X) ہونی چاہیے، ہم ہدف متغیر (Y) کی پیشین گوئی کرنا چاہتے ہیں، اور تاریخی ڈیٹا کا استعمال ایک ML ماڈل کو تربیت دینے کے لیے کرنا چاہتے ہیں جو Y کی اصل قدر کے جتنا قریب ہو سکے پیشین گوئی کر سکے۔ آخر میں، ہم اس ماڈل کو نئے ڈیٹا پر پیشین گوئی کرنے کے لیے استعمال کرتے ہیں جہاں Y نامعلوم ہے۔ یہ ہمیں پہلے مرحلے کی طرف لے جاتا ہے:
مرحلہ 1: اپنا مسئلہ ترتیب دیں۔
- آپ کیا پیشین گوئی کرنا چاہتے ہیں؟ اچھی پیشن گوئی کیا ہے؟ آپ پیشن گوئی کے نتائج کا اندازہ کیسے لگاتے ہیں؟
یعنی، اوپر ہمارے فریم ورک میں، Y کیا ہے؟
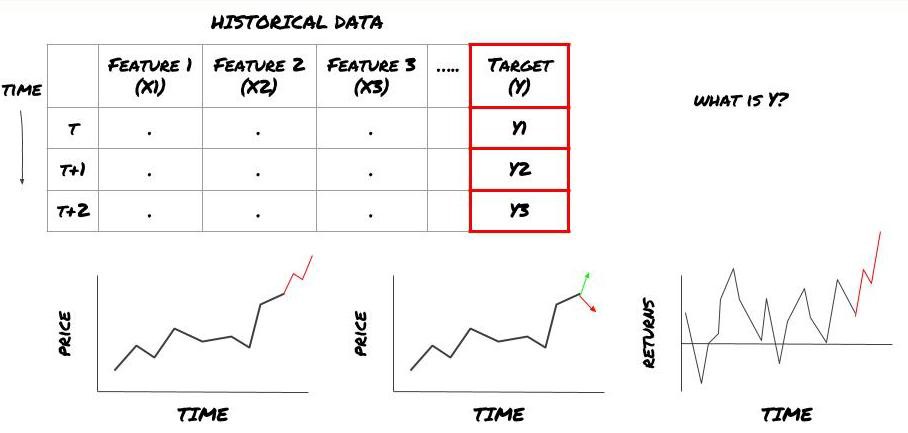
آپ کیا پیشین گوئی کرنا چاہتے ہیں؟
کیا آپ مستقبل کی قیمتوں، مستقبل کے ریٹرن/Pnl، خرید/فروخت کے سگنل، پورٹ فولیو مختص کو بہتر بنانا اور تجارت کو مؤثر طریقے سے انجام دینے کی کوشش کرنا چاہتے ہیں وغیرہ؟
فرض کریں کہ ہم اگلی ٹائم اسٹیمپ پر قیمت کا اندازہ لگانے کی کوشش کر رہے ہیں۔ اس صورت میں، Y(t) = قیمت(t+1)۔ اب ہم تاریخی ڈیٹا کے ساتھ اپنا فریم ورک مکمل کر سکتے ہیں۔
نوٹ کریں کہ Y(t) صرف بیک ٹیسٹ میں جانا جاتا ہے، لیکن جب ہم اپنا ماڈل استعمال کرتے ہیں تو ہمیں t (t+1) کے وقت قیمت معلوم نہیں ہوگی۔ ہم اپنے ماڈل کا استعمال ایک پیشین گوئی Y(پیش گوئی، t) کرنے کے لیے کرتے ہیں اور اس کا موازنہ صرف t+1 کے وقت اصل قدر سے کرتے ہیں۔ اس کا مطلب ہے کہ آپ پیش گوئی کرنے والے ماڈل میں Y کو بطور خصوصیت استعمال نہیں کر سکتے۔
ایک بار جب ہم اپنے ہدف Y کو جان لیتے ہیں، تو ہم یہ بھی فیصلہ کر سکتے ہیں کہ اپنی پیشین گوئیوں کا اندازہ کیسے لگایا جائے۔ یہ مختلف ماڈلز کو الگ کرنے کے لیے اہم ہے جو ہم اپنے ڈیٹا پر آزمائیں گے۔ ہم جس مسئلے کو حل کر رہے ہیں اس پر منحصر ہے، ہمارے ماڈل کی کارکردگی کی پیمائش کے لیے ایک میٹرک کا انتخاب کریں۔ مثال کے طور پر، اگر ہم قیمتوں کی پیشن گوئی کر رہے ہیں، تو ہم روٹ مطلب مربع غلطی کو بطور میٹرک استعمال کر سکتے ہیں۔ کچھ عام طور پر استعمال ہونے والے اشارے (موونگ ایوریج، MACD اور ویرینس سکور وغیرہ) کو Inventor Quant ٹول باکس میں پہلے سے کوڈ کیا گیا ہے، اور آپ API انٹرفیس کے ذریعے عالمی سطح پر ان اشاریوں کو کال کر سکتے ہیں۔
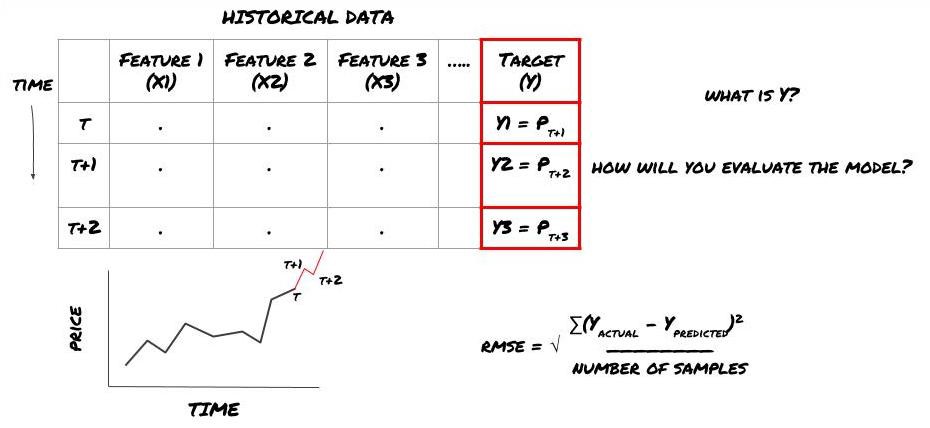
مستقبل کی قیمتوں کی پیشن گوئی کے لیے ML فریم ورک
ظاہر کرنے کے لیے، ہم فرضی سرمایہ کاری کے ہدف کی مستقبل کی متوقع بنیاد کی قیمت کی پیشین گوئی کرنے کے لیے ایک پیشن گوئی کا ماڈل بنائیں گے، جہاں:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
چونکہ یہ رجعت کا مسئلہ ہے، اس لیے ہم RMSE (Rot Mean Squared Error) پر ماڈل کا جائزہ لیں گے۔ ہم کل Pnl کو بھی تشخیص کے معیار کے طور پر استعمال کریں گے۔
نوٹ: RMSE کے متعلق ریاضی کے متعلقہ علم کے لیے، براہ کرم Baidu انسائیکلوپیڈیا کے متعلقہ مواد سے رجوع کریں۔
- ہمارا مقصد: ایک ایسا ماڈل بنائیں جو پیش گوئی کی گئی اقدار کو Y کے زیادہ سے زیادہ قریب بنائے۔
مرحلہ 2: قابل اعتماد ڈیٹا اکٹھا کریں۔
ڈیٹا اکٹھا کریں اور صاف کریں جو آپ کو ہاتھ میں موجود مسئلے کو حل کرنے میں مدد دے سکتا ہے۔
ہدف متغیر Y کے لیے پیشین گوئی کی طاقت رکھنے کے لیے آپ کو کس ڈیٹا پر غور کرنے کی ضرورت ہے؟ اگر ہم قیمتوں کی پیشن گوئی کر رہے ہیں، تو آپ ٹارگٹ پرائس ڈیٹا، ٹارگٹ ٹریڈنگ والیوم ڈیٹا، متعلقہ اہداف کے لیے ملتے جلتے ڈیٹا، مجموعی مارکیٹ انڈیکیٹرز جیسے ٹارگٹ انڈیکس لیولز، دیگر متعلقہ اثاثوں کی قیمتیں وغیرہ استعمال کر سکتے ہیں۔
آپ کو اس ڈیٹا کے لیے ڈیٹا تک رسائی کی اجازتیں مرتب کرنے کی ضرورت ہوگی اور یہ یقینی بنانا ہوگا کہ آپ کا ڈیٹا درست ہے اور گمشدہ ڈیٹا (ایک بہت عام مسئلہ) کو حل کرنا ہوگا۔ یہ بھی یقینی بنائیں کہ آپ کا ڈیٹا غیرجانبدار ہے اور آپ کے ماڈل میں تعصب سے بچنے کے لیے مارکیٹ کے تمام حالات (مثلاً جیت/نقصان کی ایک ہی تعداد) کی مناسب نمائندگی کرتا ہے۔ آپ کو ڈیویڈنڈ، پورٹ فولیو کی تقسیم، تسلسل وغیرہ کے لیے ڈیٹا کو صاف کرنے کی بھی ضرورت پڑ سکتی ہے۔
اگر آپ انوینٹر کوانٹیٹیو پلیٹ فارم (FMZ.COM) استعمال کر رہے ہیں، تو ہم Google، Yahoo، NSE اور Quandl سے مفت عالمی ڈیٹا تک رسائی حاصل کر سکتے ہیں جیسے کہ CTP اور Yisheng، OKEX، Huobi اور BitMex؛ Inventor Quantitative Platform اس ڈیٹا کو پہلے سے صاف اور فلٹر بھی کرتا ہے، جیسے کہ سرمایہ کاری کے ہدف کی تقسیم اور مارکیٹ کے گہرائی سے ڈیٹا، اور اسے حکمت عملی کے ڈویلپرز کو ایک ایسی شکل میں پیش کرتا ہے جسے مقداری کارکنوں کے لیے سمجھنا آسان ہو۔
اس مضمون کی سہولت کے لیے، ہم مندرجہ ذیل ڈیٹا کو بطور مجازی سرمایہ کاری کے ہدف ‘MQK’ کا استعمال کرتے ہیں۔ / auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
مندرجہ بالا کوڈ کے ساتھ، Auquan’s Toolbox نے ڈیٹا کو ڈیٹا فریم ڈکشنری میں ڈاؤن لوڈ اور لوڈ کر دیا ہے۔ اب ہمیں اپنی پسند کے فارمیٹ میں ڈیٹا تیار کرنے کی ضرورت ہے۔ فنکشن ds.getBookDataByFeature() ڈیٹا فریموں کی لغت واپس کرتا ہے، فی فیچر ایک ڈیٹا فریم۔ ہم تمام خصوصیات کے ساتھ اسٹاک کے لیے نیا ڈیٹا فریم بناتے ہیں۔
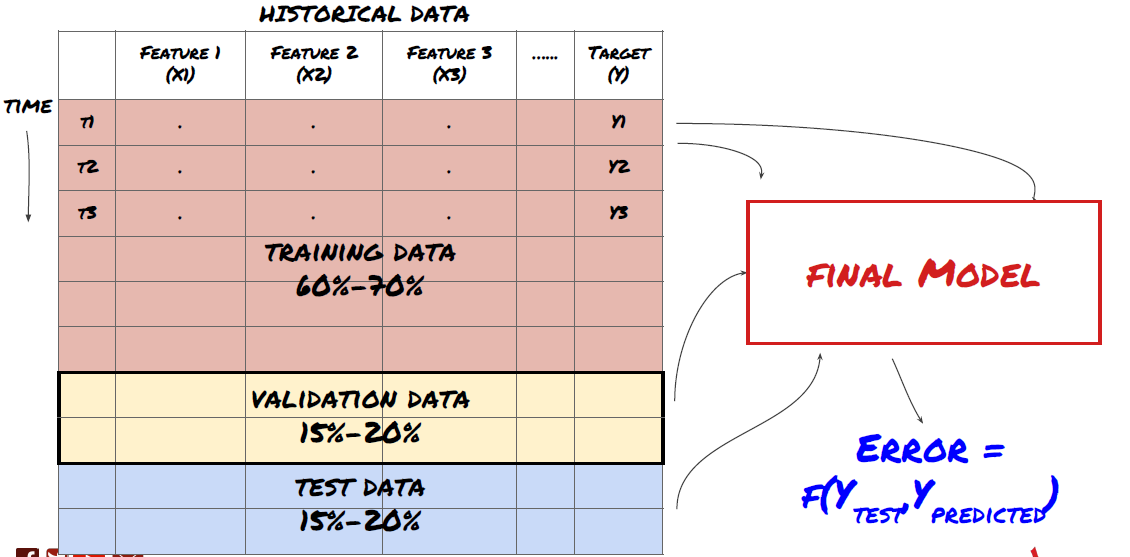
مرحلہ 3: ڈیٹا تقسیم کریں۔
- اعداد و شمار سے تربیتی سیٹ بنائیں، ان سیٹوں کی تصدیق اور جانچ کریں۔
یہ ایک بہت اہم قدم ہے! اس سے پہلے کہ ہم آگے بڑھیں، ہمیں ڈیٹا کو ٹریننگ ڈیٹاسیٹ میں تقسیم کرنا چاہیے، آپ کے ماڈل کو تربیت دینے کے لیے، اور ایک ٹیسٹ ڈیٹاسیٹ، ماڈل کی کارکردگی کا جائزہ لینے کے لیے۔ تجویز کردہ تقسیم یہ ہے: 60-70% ٹریننگ سیٹ اور 30-40% ٹیسٹ سیٹ
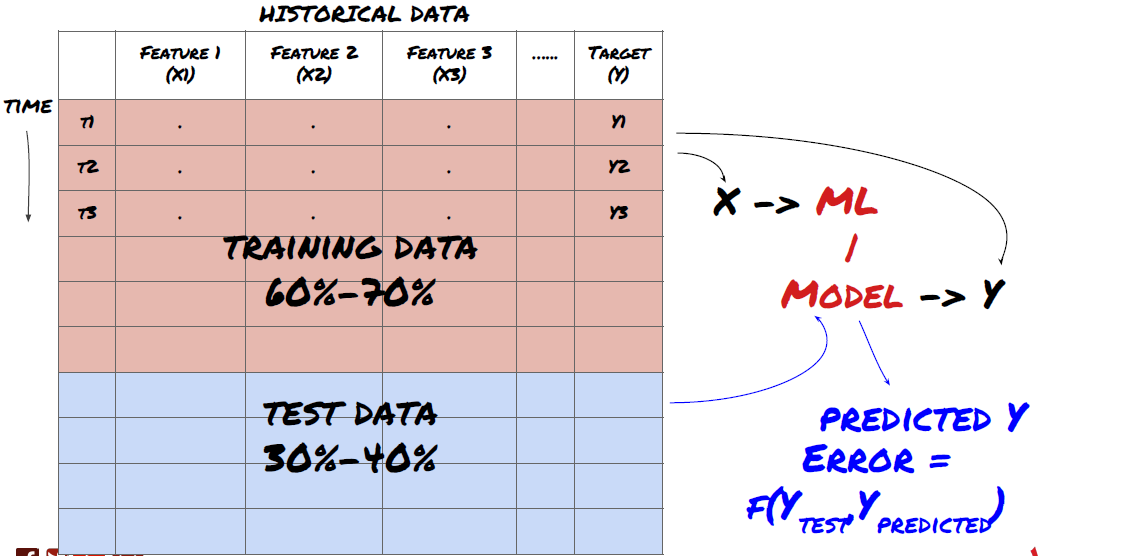
ڈیٹا کو ٹریننگ اور ٹیسٹنگ سیٹس میں تقسیم کریں۔
چونکہ ٹریننگ ڈیٹا کا استعمال ماڈل کے پیرامیٹرز کا جائزہ لینے کے لیے کیا جاتا ہے، اس لیے آپ کا ماڈل اس ٹریننگ ڈیٹا سے زیادہ فٹ ہو سکتا ہے اور ٹریننگ ڈیٹا ماڈل کی کارکردگی کو گمراہ کر سکتا ہے۔ اگر آپ کوئی الگ ٹیسٹ ڈیٹا نہیں رکھتے اور تمام ڈیٹا کو ٹریننگ کے لیے استعمال کرتے ہیں، تو آپ نہیں جان پائیں گے کہ آپ کا ماڈل نئے، غیر دیکھے ڈیٹا پر کتنی اچھی یا بری کارکردگی دکھائے گا۔ تربیت یافتہ ایم ایل ماڈلز لائیو ڈیٹا پر ناکام ہونے کی ایک اہم وجہ یہ ہے: لوگ تمام دستیاب ڈیٹا پر تربیت حاصل کرتے ہیں اور ٹریننگ ڈیٹا میٹرکس سے پرجوش ہو جاتے ہیں، لیکن ماڈل لائیو ڈیٹا پر کوئی بامعنی پیشین گوئی کرنے میں ناکام رہتا ہے جس پر اسے تربیت نہیں دی گئی تھی۔ .
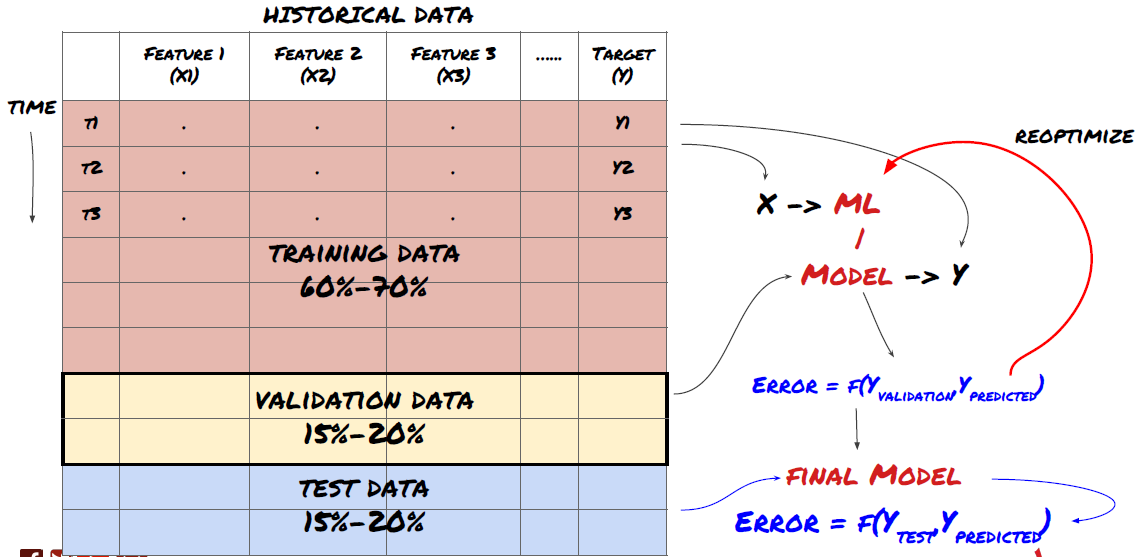
ڈیٹا کو تربیت، توثیق اور ٹیسٹ سیٹ میں تقسیم کریں۔
اس نقطہ نظر کے ساتھ مسائل ہیں. اگر ہم بار بار ٹریننگ ڈیٹا پر ٹریننگ کرتے ہیں، ٹیسٹ ڈیٹا پر کارکردگی کا جائزہ لیتے ہیں اور اپنے ماڈل کو بہتر بناتے ہیں جب تک کہ ہم کارکردگی سے مطمئن نہ ہو جائیں، تو ہم واضح طور پر ٹیسٹ ڈیٹا کو تربیتی ڈیٹا کے حصے کے طور پر شامل کرتے ہیں۔ بالآخر، ہمارا ماڈل ٹریننگ اور ٹیسٹ ڈیٹا کے اس سیٹ پر اچھی کارکردگی کا مظاہرہ کر سکتا ہے، لیکن اس بات کی کوئی گارنٹی نہیں ہے کہ یہ نئے ڈیٹا کی اچھی طرح سے پیش گوئی کر سکے گا۔
اس مسئلے کو حل کرنے کے لیے، ہم ایک علیحدہ توثیق ڈیٹاسیٹ بنا سکتے ہیں۔ اب آپ ڈیٹا پر تربیت حاصل کر سکتے ہیں، توثیق کے ڈیٹا پر کارکردگی کا جائزہ لے سکتے ہیں، جب تک آپ کارکردگی سے مطمئن نہیں ہو جاتے تب تک آپٹمائز کر سکتے ہیں، اور آخر میں ٹیسٹ ڈیٹا پر ٹیسٹ کر سکتے ہیں۔ اس طرح، ٹیسٹ کا ڈیٹا آلودہ نہیں ہو گا اور ہم اپنے ماڈل کو بہتر بنانے کے لیے ٹیسٹ ڈیٹا سے کوئی بھی معلومات استعمال نہیں کریں گے۔
یاد رکھیں، ایک بار جب آپ ٹیسٹ ڈیٹا پر کارکردگی کو چیک کر لیں، تو پیچھے نہ جائیں اور ماڈل کو مزید بہتر بنانے کی کوشش کریں۔ اگر آپ کو معلوم ہوتا ہے کہ آپ کا ماڈل اچھے نتائج نہیں دے رہا ہے، تو ماڈل کو مکمل طور پر چھوڑ دیں اور دوبارہ شروع کریں۔ تجویز کردہ تقسیم 60% تربیتی ڈیٹا، 20% توثیق ڈیٹا، اور 20% ٹیسٹ ڈیٹا ہو سکتی ہے۔
ہمارے مسئلے کے لیے، ہمارے پاس تین ڈیٹا سیٹس دستیاب ہیں اور ہم ایک کو تربیتی سیٹ کے طور پر، دوسرے کو توثیق کے سیٹ کے طور پر، اور تیسرا کو اپنے ٹیسٹ سیٹ کے طور پر استعمال کریں گے۔
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
ان میں سے ہر ایک میں، ہم ہدف متغیر Y کو شامل کرتے ہیں، جس کی وضاحت اگلے پانچ بنیادی اقدار کے وسط کے طور پر کی گئی ہے۔
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
مرحلہ 4: فیچر انجینئرنگ
ڈیٹا کے رویے کا تجزیہ کریں اور پیشین گوئی کی طاقت کے ساتھ خصوصیات بنائیں
اب اس منصوبے کی اصل تعمیر شروع ہوتی ہے۔ فیچر کے انتخاب کا سنہری اصول یہ ہے کہ پیشین گوئی کی طاقت بنیادی طور پر خصوصیات سے آتی ہے، ماڈل سے نہیں۔ آپ دیکھیں گے کہ خصوصیات کے انتخاب کا کارکردگی پر ماڈل کے انتخاب کے مقابلے میں بہت زیادہ اثر پڑتا ہے۔ خصوصیت کے انتخاب پر کچھ نوٹ:
ٹارگٹ متغیر کے ساتھ ان کے تعلقات کو دریافت کیے بغیر من مانی طور پر خصوصیات کا ایک بڑا مجموعہ منتخب نہ کریں۔
ہدف متغیر کے ساتھ بہت کم یا کوئی تعلق زیادہ فٹنگ کا باعث بن سکتا ہے۔
آپ کی منتخب کردہ خصوصیات ایک دوسرے کے ساتھ بہت زیادہ منسلک ہو سکتی ہیں، ایسی صورت میں خصوصیات کی ایک چھوٹی تعداد بھی ہدف کی وضاحت کر سکتی ہے۔
میں عام طور پر کچھ خصوصیات تخلیق کرتا ہوں جو بدیہی سمجھ میں آتی ہیں اور یہ دیکھتے ہیں کہ ہدف کے متغیر کو ان خصوصیات کے ساتھ کس طرح منسلک کیا جاتا ہے، اور ساتھ ہی یہ فیصلہ کرنے کے لیے کہ کون سا استعمال کرنا ہے۔
آپ زیادہ سے زیادہ انفارمیشن کوفیشینٹ (MIC) کی بنیاد پر امیدوار کی خصوصیات کی درجہ بندی کرنے کی کوشش بھی کر سکتے ہیں، پرنسپل کمپوننٹ اینالیسس (PCA) اور دیگر طریقوں کو انجام دے سکتے ہیں۔
فیچر ٹرانسفارمیشن/ نارملائزیشن:
ML ماڈل معمول کے ساتھ اچھی کارکردگی کا مظاہرہ کرتے ہیں۔ تاہم، ٹائم سیریز کے ڈیٹا سے نمٹتے وقت نارملائزیشن مشکل ہے کیونکہ ڈیٹا کی مستقبل کی حد نامعلوم ہے۔ آپ کا ڈیٹا معمول کی حد سے باہر ہو سکتا ہے، جس کی وجہ سے ماڈل غلط ہے۔ لیکن آپ پھر بھی کچھ حد تک اسٹیشنریٹی کو مجبور کرنے کی کوشش کر سکتے ہیں:
اسکیلنگ: معیاری انحراف یا انٹرکوارٹائل رینج کے لحاظ سے خصوصیات کو تقسیم کریں۔
سینٹرنگ: موجودہ قدر سے تاریخی اوسط کو گھٹائیں۔
نارملائزیشن: اوپر کے دو لُک بیک پیریڈز (x - اوسط) / stdev
روایتی نارملائزیشن: ڈیٹا کو -1 سے +1 کی حد تک معمول پر لائیں اور لک بیک پیریڈ (x-min)/(زیادہ سے زیادہ منٹ) کے اندر دوبارہ سینٹر کریں۔
نوٹ کریں کہ چونکہ ہم تاریخی رننگ وسط، معیاری انحراف، زیادہ سے زیادہ یا کم از کم قدر کو دیکھنے کی مدت میں استعمال کرتے ہیں، اس لیے خصوصیت کی معمول کی قیمت مختلف اوقات میں مختلف حقیقی اقدار کی نمائندگی کرے گی۔ مثال کے طور پر، اگر کسی خصوصیت کی موجودہ قیمت 5 ہے اور 30-پیریڈ کی اوسط 4.5 ہے، تو اسے سینٹرنگ کے بعد 0.5 میں تبدیل کر دیا جائے گا۔ بعد میں، اگر 30 مدت کی اوسط 3 ہو جاتی ہے، تو قدر 3.5 0.5 ہو جائے گی۔ یہ ماڈل کے غلط ہونے کی وجہ ہو سکتی ہے لہذا، ریگولرائزیشن مشکل ہے اور آپ کو یہ معلوم کرنا ہوگا کہ اصل میں ماڈل کی کارکردگی کو کیا بہتر بناتا ہے (اگر کچھ بھی ہے)۔
اپنے مسئلے میں پہلی بار تکرار کے لیے، ہم نے اختلاط کے پیرامیٹرز کا استعمال کرتے ہوئے بڑی تعداد میں خصوصیات تخلیق کیں۔ بعد میں ہم یہ دیکھنے کی کوشش کریں گے کہ آیا ہم خصوصیات کی تعداد کو کم کر سکتے ہیں۔
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
مرحلہ 5: ماڈل کا انتخاب
منتخب کردہ مسئلہ کے لیے مناسب شماریاتی/ML ماڈل کا انتخاب کریں۔
ماڈل کا انتخاب اس بات پر منحصر ہے کہ مسئلہ کس طرح تیار کیا گیا ہے۔ کیا آپ ایک زیر نگرانی حل کر رہے ہیں (فیچر میٹرکس میں ہر پوائنٹ X کو ٹارگٹ متغیر Y کے ساتھ میپ کیا جاتا ہے) یا غیر زیر نگرانی سیکھنے کا مسئلہ (کوئی میپنگ نہیں دی جاتی ہے اور ماڈل نامعلوم پیٹرن سیکھنے کی کوشش کرتا ہے)؟ کیا آپ رجعت (مستقبل کے وقت میں اصل قیمت کی پیشن گوئی) یا درجہ بندی کا مسئلہ حل کر رہے ہیں (مستقبل کے وقت قیمت کی صرف سمت (اضافہ/کمی) کی پیش گوئی کر رہے ہیں)۔

زیر نگرانی یا غیر زیر نگرانی تعلیم

رجعت یا درجہ بندی
کچھ عام زیر نگرانی سیکھنے کے الگورتھم شروع کرنے میں آپ کی مدد کر سکتے ہیں:
لکیری ریگریشن (پیرامیٹر، رجعت)
لاجسٹک ریگریشن (پیرامیٹر، درجہ بندی)
K-قریب ترین پڑوسی (KNN) الگورتھم (مثال پر مبنی، رجعت)
SVM، SVR (پیرامیٹر، درجہ بندی اور رجعت)
فیصلہ کن درخت
فیصلہ جنگل
میں ایک سادہ ماڈل سے شروع کرنے کی تجویز کرتا ہوں، جیسے لکیری یا لاجسٹک ریگریشن، اور ضرورت کے مطابق وہاں سے مزید پیچیدہ ماڈلز بنانا۔ یہ بھی تجویز کیا جاتا ہے کہ آپ ماڈل کے پیچھے کی ریاضی کو بلیک باکس کے طور پر استعمال کرنے کے بجائے اسے پڑھیں۔
مرحلہ 6: تربیت، توثیق اور اصلاح (مرحلہ 4-6 کو دہرائیں)
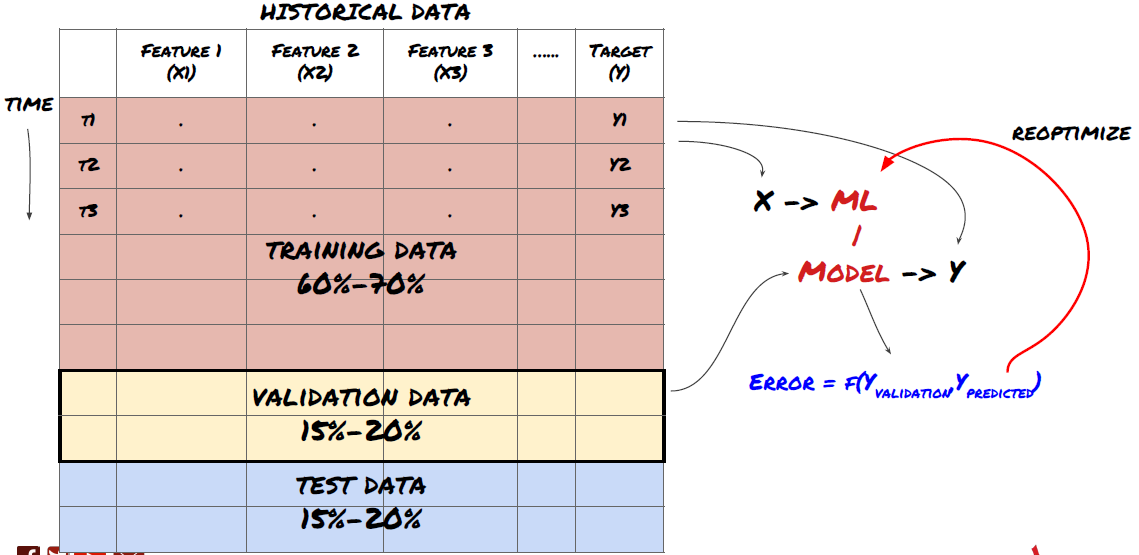
تربیت اور توثیق کے ڈیٹا سیٹس کا استعمال کرتے ہوئے اپنے ماڈل کو تربیت دیں اور بہتر بنائیں
اب آپ آخر کار اپنا ماڈل بنانے کے لیے تیار ہیں۔ اس مرحلے پر، آپ واقعی صرف ماڈل اور ماڈل پیرامیٹرز پر تکرار کر رہے ہیں۔ اپنے ماڈل کو تربیتی ڈیٹا پر تربیت دیں، توثیق کے ڈیٹا پر اس کی کارکردگی کی پیمائش کریں، پھر واپس جائیں، بہتر بنائیں، دوبارہ تربیت دیں، اور تشخیص کریں۔ اگر آپ کسی ماڈل کی کارکردگی سے مطمئن نہیں ہیں، تو کوئی دوسرا ماڈل استعمال کرنے کی کوشش کریں۔ آپ اس مرحلے کے ذریعے کئی بار سائیکل چلاتے ہیں جب تک کہ آپ کے پاس آخر کار ایسا ماڈل نہ ہو جس سے آپ خوش ہوں۔
صرف ایک بار جب آپ کے پاس اپنی پسند کا ماڈل ہو، پھر اگلے مرحلے پر جائیں۔
ہمارے مظاہرے کے مسئلے کے لیے، آئیے ایک سادہ لکیری رجعت کے ساتھ شروع کرتے ہیں۔
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
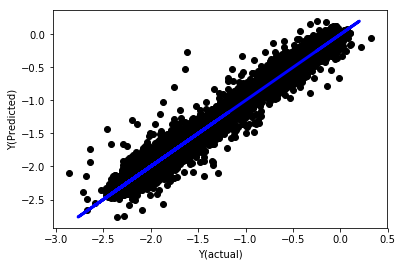
معمول کے بغیر لکیری رجعت
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
ماڈل گتانک کو دیکھیں۔ ہم واقعی ان کا موازنہ نہیں کر سکتے یا یہ نہیں کہہ سکتے کہ کون سے اہم ہیں کیونکہ وہ سب مختلف پیمانے پر آتے ہیں۔ آئیے انہیں ایک ہی پیمانے پر لانے کے لیے نارمل کرنے کی کوشش کریں اور کچھ سٹیشناریٹی کو بھی نافذ کریں۔
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
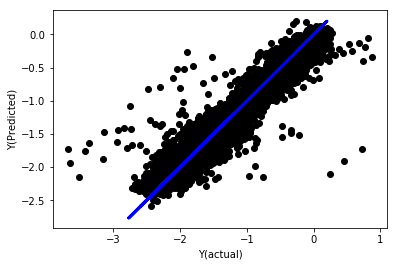
معمول کے مطابق لکیری رجعت
Mean squared error: 0.05
Variance score: 0.90
یہ ماڈل پچھلے ماڈل کے مقابلے میں بہتری نہیں ہے، لیکن یہ بدتر بھی نہیں ہے۔ اب ہم اصل میں گتانکوں کا موازنہ کر سکتے ہیں اور دیکھ سکتے ہیں کہ اصل میں کون سے اہم ہیں۔
آئیے گتانکوں کو دیکھتے ہیں۔
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
نتیجہ یہ ہے:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
ہم واضح طور پر دیکھ سکتے ہیں کہ کچھ خصوصیات میں دیگر خصوصیات کے مقابلے زیادہ گتانک ہوتے ہیں اور ان میں مضبوط پیشن گوئی کی طاقت کا امکان ہوتا ہے۔
آئیے مختلف خصوصیات کے مابین ارتباط کو دیکھیں۔
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
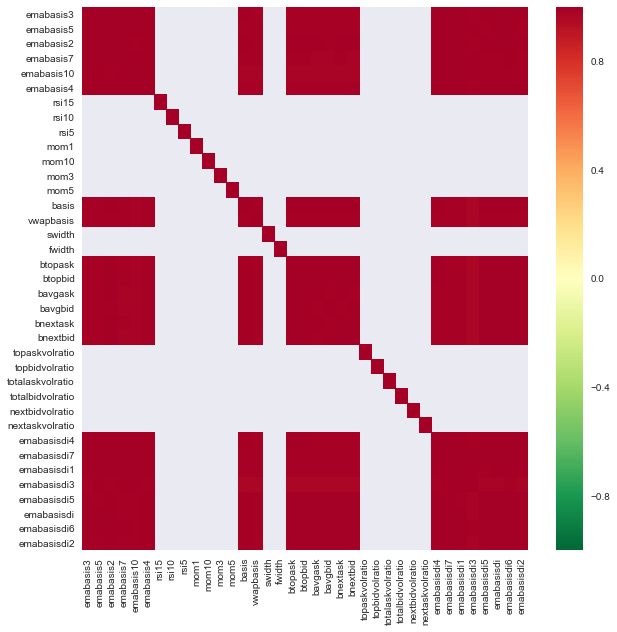
خصوصیات کے درمیان ارتباط
گہرے سرخ علاقے انتہائی باہم مربوط متغیرات کی نشاندہی کرتے ہیں۔ آئیے دوبارہ کچھ خصوصیات بنائیں/ترمیم کریں اور اپنے ماڈل کو بہتر بنانے کی کوشش کریں۔
مثال کے طور پر، میں آسانی سے emabasisdi7 جیسی خصوصیات کو رد کر سکتا ہوں جو کہ دوسری خصوصیات کے صرف لکیری امتزاج ہیں۔
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
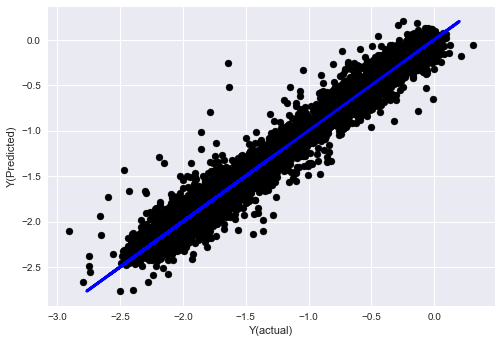
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
دیکھیں، ہمارے ماڈل کی کارکردگی میں کوئی تبدیلی نہیں آئی، ہمیں اپنے ہدف کے متغیر کی وضاحت کے لیے صرف چند خصوصیات کی ضرورت ہے۔ میرا مشورہ ہے کہ آپ مندرجہ بالا خصوصیات میں سے مزید کو آزمائیں، نئے امتزاجات وغیرہ کو آزمائیں کہ ہمارے ماڈل کو کیا بہتر بنا سکتا ہے۔
ہم یہ دیکھنے کے لیے مزید پیچیدہ ماڈلز بھی آزما سکتے ہیں کہ آیا ماڈل میں تبدیلیاں کارکردگی کو بہتر بنا سکتی ہیں۔
- K-قریب ترین پڑوسی (KNN) الگورتھم
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- فیصلہ کن درخت
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
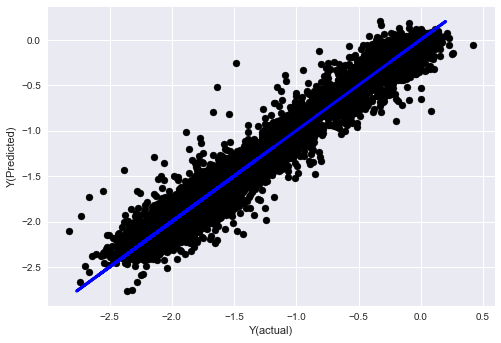
مرحلہ 7: ٹیسٹ ڈیٹا کا بیک ٹیسٹ کریں۔
اصل نمونہ ڈیٹا پر کارکردگی چیک کریں۔
(اچھوا) ٹیسٹ ڈیٹاسیٹ پر بہترین کارکردگی
یہ ایک نازک لمحہ ہے۔ ہم آخری مرحلے سے اپنے حتمی اصلاح شدہ ماڈل کو ٹیسٹ ڈیٹا پر چلا کر شروع کرتے ہیں جسے ہم نے شروع میں ایک طرف رکھا تھا اور اب تک اسے چھوا نہیں ہے۔
یہ آپ کو حقیقت پسندانہ توقعات فراہم کرتا ہے کہ جب آپ لائیو ٹریڈنگ شروع کرتے ہیں تو آپ کا ماڈل نئے اور ان دیکھے ڈیٹا پر کیسے کام کرے گا۔ لہذا، یہ یقینی بنانا ضروری ہے کہ آپ کے پاس ایک صاف ڈیٹاسیٹ ہے جو ماڈل کو تربیت دینے یا اس کی تصدیق کے لیے استعمال نہیں کیا گیا ہے۔
اگر آپ کو اپنے ٹیسٹ ڈیٹا پر بیک ٹیسٹ کے نتائج پسند نہیں ہیں، تو ماڈل کو پھینک دیں اور دوبارہ شروع کریں۔ کبھی واپس نہ جائیں اور اپنے ماڈل کو دوبارہ بہتر بنائیں، یہ اوور فٹنگ کا باعث بنے گا! (ایک نیا ٹیسٹ ڈیٹاسیٹ بنانے کی بھی سفارش کی جاتی ہے، کیونکہ یہ ڈیٹاسیٹ اب آلودہ ہے؛ ماڈل کو رد کرتے وقت، ہم ڈیٹاسیٹ کے بارے میں واضح طور پر کچھ جانتے ہیں)۔
یہاں ہم اب بھی Auquan’s Toolbox استعمال کریں گے۔
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
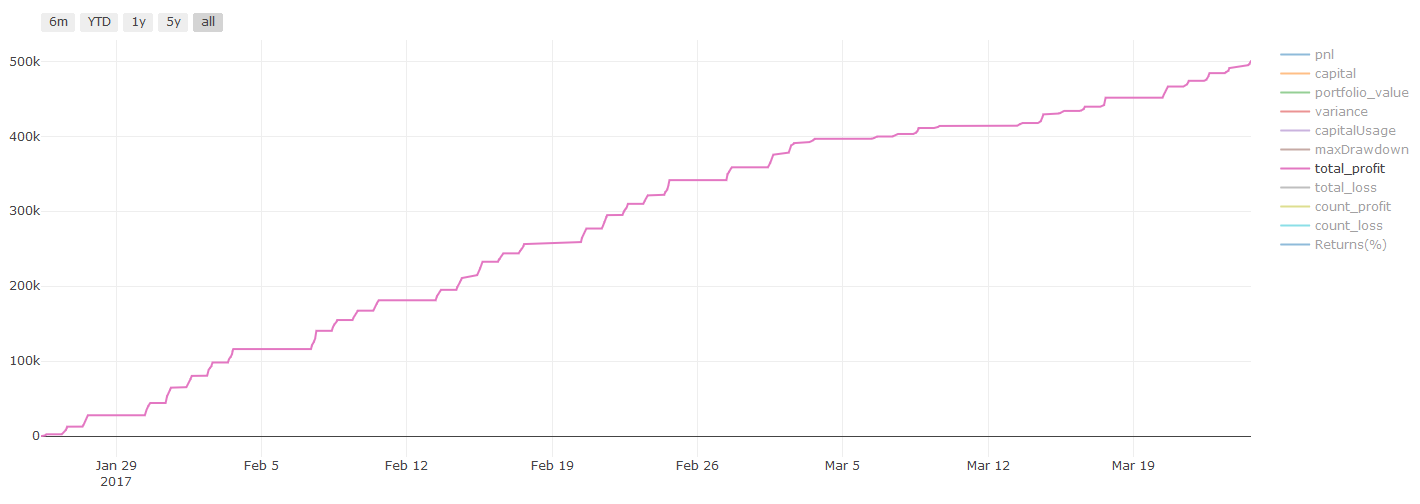
بیک ٹیسٹ کے نتائج، Pnl کا حساب امریکی ڈالر میں کیا جاتا ہے (Pnl میں لین دین کے اخراجات اور دیگر فیسیں شامل نہیں ہیں)
مرحلہ 8: ماڈل کو بہتر بنانے کے دوسرے طریقے
رولنگ کی توثیق، جوڑا سیکھنا، بیگنگ اور بوسٹنگ
مزید ڈیٹا اکٹھا کرنے، بہتر خصوصیات بنانے، یا مزید ماڈلز آزمانے کے علاوہ، یہاں کچھ چیزیں ہیں جن کو آپ بہتر کرنے کی کوشش کر سکتے ہیں۔
1. رولنگ تصدیق
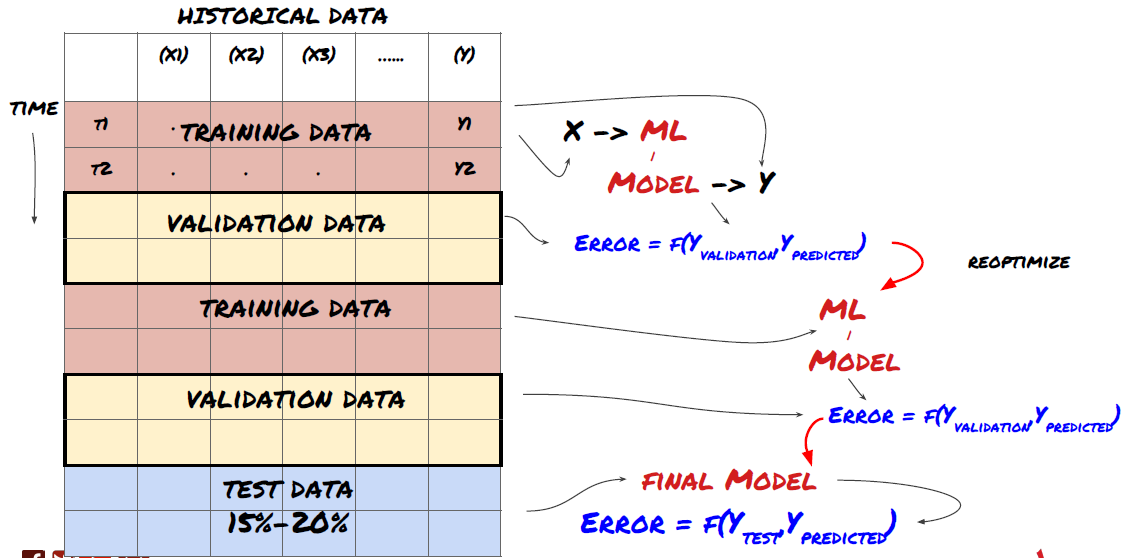
رولنگ کی توثیق
مارکیٹ کے حالات شاذ و نادر ہی مستقل رہتے ہیں۔ فرض کریں کہ آپ کے پاس ایک سال کا ڈیٹا ہے، اور آپ جنوری سے اگست تک کا ڈیٹا ٹریننگ کے لیے استعمال کرتے ہیں، اور اپنے ماڈل کی جانچ کے لیے ستمبر سے دسمبر تک کا ڈیٹا استعمال کرتے ہیں، ہو سکتا ہے کہ آپ مارکیٹ کے حالات کے ایک خاص سیٹ کے لیے ٹریننگ ختم کریں۔ ہو سکتا ہے کہ سال کی پہلی ششماہی میں مارکیٹ میں اتار چڑھاؤ نہ ہو، اور کچھ انتہائی خبروں کی وجہ سے ستمبر میں مارکیٹ میں تیزی سے اضافہ ہوا، آپ کا ماڈل اس طرز کو نہیں سیکھ سکے گا اور آپ کو ردی کی پیشن گوئی کے نتائج دے گا۔
بہتر ہو گا کہ توثیق کو آگے بڑھانے کی کوشش کریں، جنوری-فروری میں تربیت، مارچ میں توثیق، اپریل-مئی میں دوبارہ تربیت، جون میں توثیق، وغیرہ۔
2. جوڑا سیکھنا
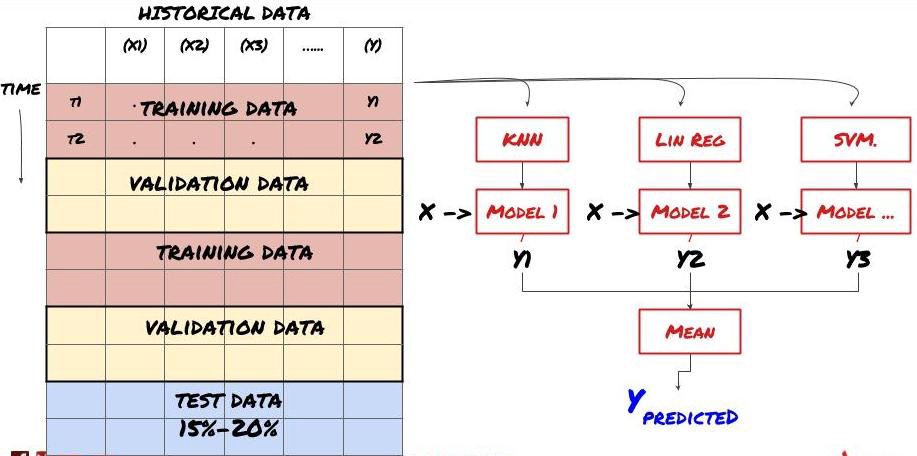
Ensemble لرننگ
کچھ ماڈلز بعض منظرناموں کی پیشین گوئی کرنے میں اچھی طرح سے کام کر سکتے ہیں، لیکن دوسرے منظرناموں یا بعض حالات میں پیشین گوئی کرنے میں کافی حد سے زیادہ ہو سکتے ہیں۔ غلطی اور اوور فٹنگ کو کم کرنے کا ایک طریقہ مختلف ماڈلز کا جوڑا استعمال کرنا ہے۔ آپ کی پیشین گوئی بہت سے ماڈلز کی طرف سے کی گئی پیشین گوئیوں کی اوسط ہوگی، اور مختلف ماڈلز کی غلطیاں دور یا کم ہو سکتی ہیں۔ جوڑنے کے کچھ عام طریقے بیگنگ اور بوسٹنگ ہیں۔
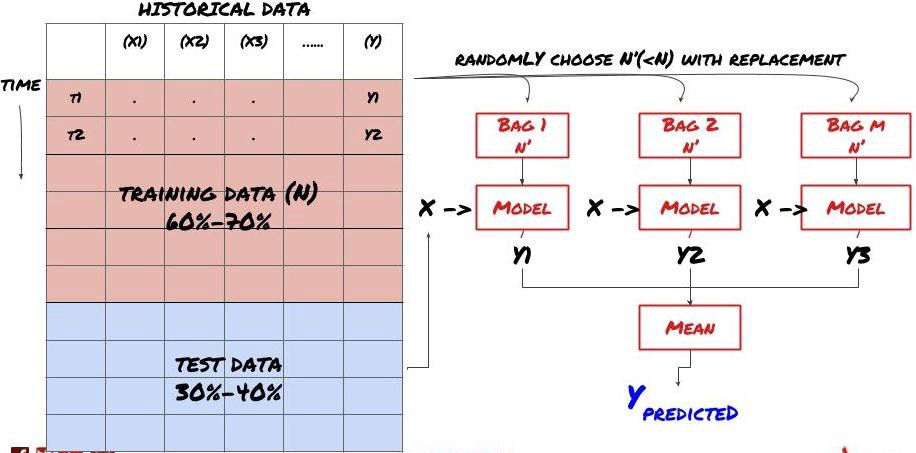
Bagging
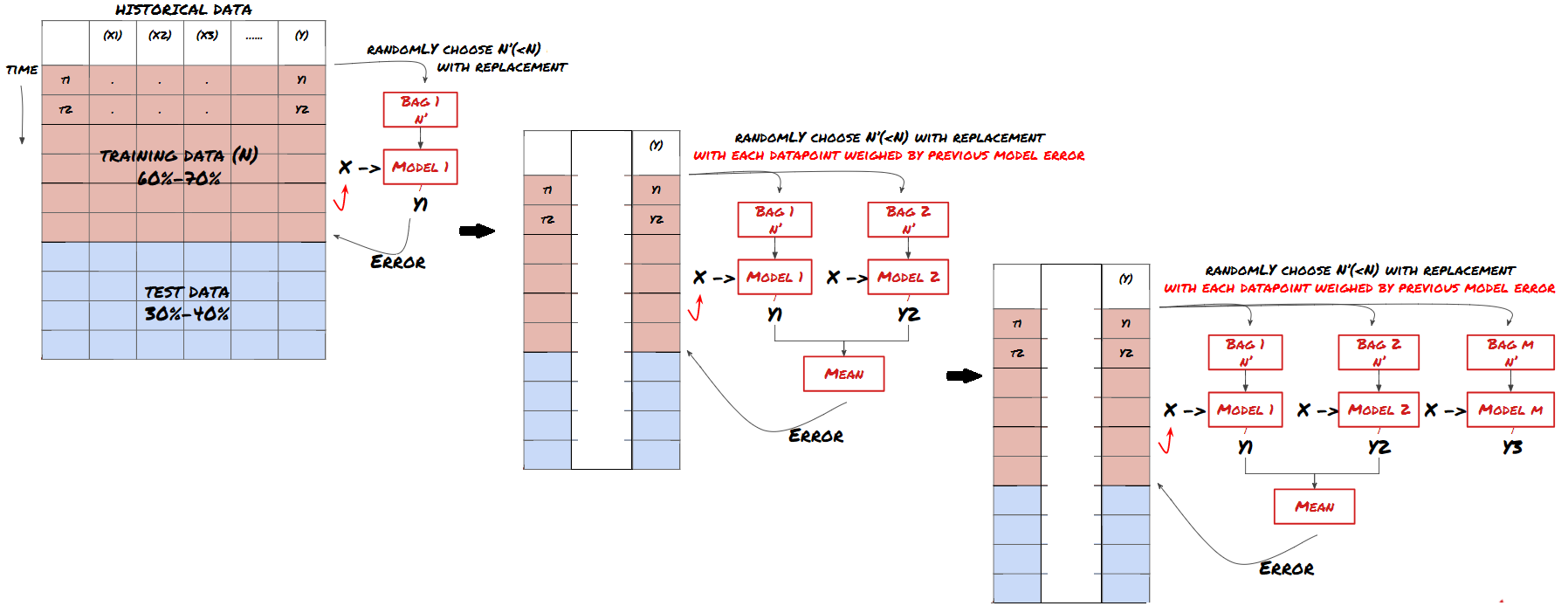
Boosting
اختصار کی خاطر، میں ان طریقوں کو چھوڑ دوں گا، لیکن آپ ان کے بارے میں مزید معلومات آن لائن حاصل کر سکتے ہیں۔
آئیے اپنے مسئلے کے لیے ایک جوڑ کا طریقہ آزماتے ہیں۔
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
ہم نے اب تک بہت زیادہ علم اور معلومات جمع کی ہیں آئیے فوری جائزہ لیں:
اپنا مسئلہ حل کریں۔
قابل اعتماد ڈیٹا اکٹھا کرنا اور ڈیٹا کو صاف کرنا
ڈیٹا کو تربیت، توثیق اور ٹیسٹ سیٹ میں تقسیم کریں۔
خصوصیات بنائیں اور ان کے طرز عمل کا تجزیہ کریں۔
رویے کی بنیاد پر مناسب تربیتی ماڈل کا انتخاب کریں۔
اپنے ماڈل کو تربیت دینے اور پیشین گوئیاں کرنے کے لیے تربیتی ڈیٹا کا استعمال کریں۔
توثیق سیٹ پر کارکردگی کو چیک کریں اور دوبارہ اصلاح کریں۔
ٹیسٹ سیٹ پر حتمی کارکردگی کی توثیق کریں۔
بہت دلچسپ، ٹھیک ہے لیکن یہ ابھی