Chiến lược giao dịch tần suất cao theo sổ lệnh dựa trên máy học
 1
7230
1
7230
Chiến lược giao dịch tần suất cao theo sổ lệnh dựa trên máy học
- ### Ý tưởng
Các cơ chế giao dịch trên thị trường chứng khoán có thể được chia thành hai loại: thị trường theo định giá và thị trường theo định giá. Đầu tiên là thị trường dựa vào các nhà đầu tư cung cấp thanh khoản, sau đó là thông qua đơn giá giới hạn, giao dịch được hình thành thông qua giá thầu ủy quyền mua và bán của nhà đầu tư. Thị trường chứng khoán của Trung Quốc thuộc loại thị trường theo định giá, bao gồm thị trường chứng khoán và thị trường tương lai.
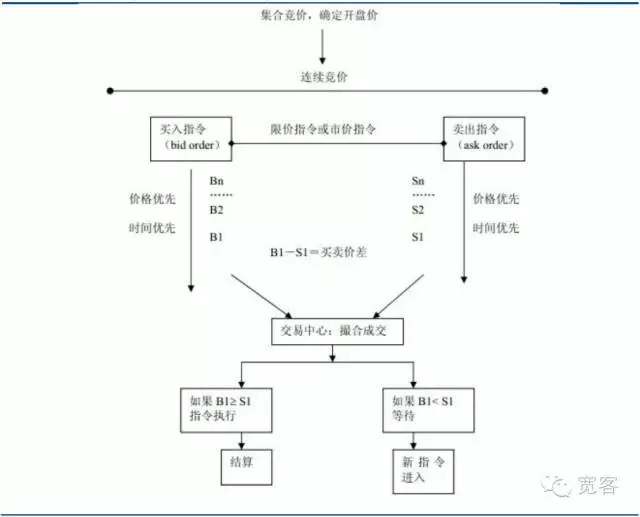 Hình 1: Hình thị trường theo lệnh
Hình 1: Hình thị trường theo lệnh
-
(I) Hồ sơ đơn đặt hàng giá giới hạn
Nghiên cứu của sổ đơn đặt hàng thuộc lĩnh vực nghiên cứu cấu trúc vi mô thị trường, lý thuyết cấu trúc vi mô thị trường lấy lý thuyết giá cả và lý thuyết nhà cung cấp trong kinh tế học vi mô làm nguồn gốc tư tưởng của nó, trong khi phân tích các vấn đề cốt lõi của nó về quá trình và lý do hình thành giá của giao dịch tài sản tài chính, nó sử dụng nhiều lý thuyết và phương pháp như cân bằng chung, cân bằng địa phương, thu nhập biên, chi phí biên, liên tục thị trường, lý thuyết kho, lý thuyết trò chơi, kinh tế học thông tin.
Theo tiến bộ nghiên cứu của nước ngoài, O’Hara đại diện cho lĩnh vực cấu trúc vi mô thị trường, hầu hết các lý thuyết đều dựa trên thị trường làm thị trường thương mại (tức là thị trường được thúc đẩy bởi giá cả), chẳng hạn như mô hình tồn kho và mô hình thông tin. Trong năm nay, trong thị trường giao dịch thực tế, lệnh đã dần chiếm ưu thế, nhưng nghiên cứu chuyên biệt về thị trường được thúc đẩy bởi lệnh vẫn còn ít hơn.
Các thị trường chứng khoán trong nước và thị trường tương lai đều thuộc thị trường được điều khiển theo đơn đặt hàng, dưới đây là ảnh chụp sổ đơn đặt hàng Level_1 của hợp đồng tương lai chỉ số chứng khoán IF1312. Không có nhiều thông tin được lấy trực tiếp từ trên, thông tin cơ bản bao gồm mua một giá, bán một giá, mua một số lượng và bán một số lượng. Trong một số bài báo học thuật ở nước ngoài, có sổ thông tin tương ứng với sổ đơn đặt hàng, bao gồm dữ liệu thu thập đơn đặt hàng chi tiết nhất, mỗi đơn đặt hàng bao gồm thông tin về số lượng đặt hàng, giá giao dịch, loại đơn đặt hàng, vì thông tin trong sổ thông tin của thị trường trong nước không được công khai, vì vậy giao dịch tần số cao chúng ta chỉ có thể dựa vào sổ đơn đặt hàng
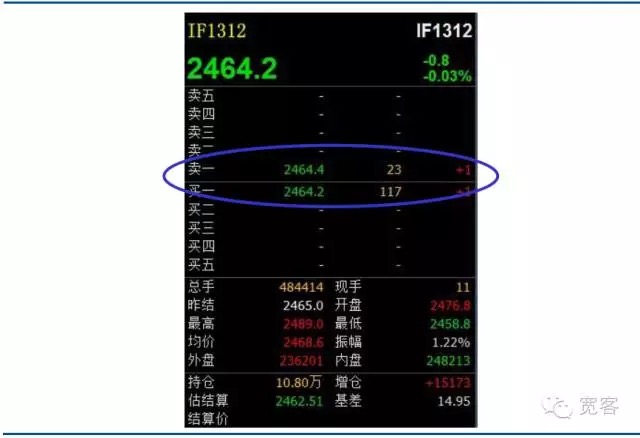 Hình 2 Sổ phiếu chỉ số tương lai hợp đồng chủ lực Level-1 Sổ đơn đặt hàng
Hình 2 Sổ phiếu chỉ số tương lai hợp đồng chủ lực Level-1 Sổ đơn đặt hàng -
(ii) Tiến triển nghiên cứu giao dịch tần số cao trong sổ đơn đặt hàng
Mô hình hóa động của sổ đơn đặt hàng, có hai phương pháp chính, một là phương pháp kinh tế học đo lường cổ điển, phương pháp học máy khác. Phương pháp kinh tế học đo lường là một phương pháp nghiên cứu chính thống cổ điển, chẳng hạn như phân tích MRR phân tích phân tích chênh lệch giá, phân tích Huang và Stoll, nghiên cứu mô hình ACD về thời gian tồn tại của đơn đặt hàng, nghiên cứu mô hình Logistic dự đoán giá cả.
Nghiên cứu học thuật về học máy trong lĩnh vực tài chính cũng rất tích cực, ví dụ như năm 2012 Forecasting trends of high_frequency KOSPI200 index data using learning classifiers Một cách suy nghĩ nghiên cứu phổ biến, sử dụng các chỉ số phân tích kỹ thuật phổ biến (MA, EMA, RSI, v.v.) để đưa ra phương pháp phân loại học máy để dự báo thị trường. Nhưng phương pháp này không khai thác thông tin động của sổ đơn đặt hàng, nghĩa là nghiên cứu về giao dịch giá cao sử dụng thông tin động của sổ đơn đặt hàng vẫn còn ít hơn cả trong và ngoài nước, đây là lĩnh vực đáng nghiên cứu sâu hơn.
-
2. ứng dụng học máy trong giao dịch tần số cao trong sổ đặt hàng
- #### (I) Bản đồ cấu trúc hệ thống
Hình dưới đây là sơ đồ cấu trúc hệ thống của chiến lược giao dịch học máy điển hình, bao gồm dữ liệu sổ đặt hàng, phát hiện tính năng, xây dựng mô hình và xác minh và các mô-đun chính của cơ hội giao dịch. Đáng chú ý là quá trình giao dịch được kích hoạt bởi các sự kiện thị trường, và sự xuất hiện của một tick là một trong những sự kiện này.
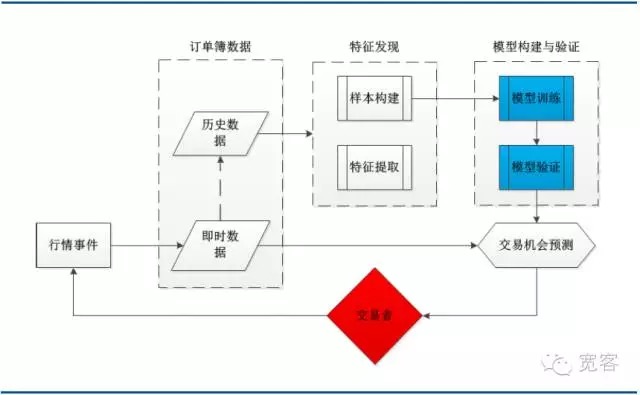 Hình 3: Bản đồ kiến trúc hệ thống dựa trên mô hình sổ đặt hàng dựa trên học máy
Hình 3: Bản đồ kiến trúc hệ thống dựa trên mô hình sổ đặt hàng dựa trên học máy- #### (ii) Hướng dẫn về máy vector hỗ trợ
Trong những năm 1970, Vapnik và những người khác bắt đầu xây dựng một hệ thống lý thuyết tốt hơn về lý thuyết học tập thống kê (SLT), được sử dụng để nghiên cứu các quy luật thống kê và tính chất của phương pháp học tập trong tình huống mẫu giới hạn, tạo ra một khuôn khổ lý thuyết tốt cho các vấn đề học tập máy có mẫu giới hạn, giải quyết tốt hơn các vấn đề thực tế như mẫu nhỏ, phi tuyến tính, chiều cao và cực nhỏ địa phương. Năm 1995, Vapnik và những người khác đã đưa ra một phương pháp học tập phổ biến mới để hỗ trợ Vector Machine Support (SVM), sau khi lý thuyết này được chú ý rộng rãi và được áp dụng cho các lĩnh vực khác nhau, nó đã ban đầu thể hiện nhiều hiệu suất tốt hơn các phương pháp của riêng mình.
SVM được phát triển từ siêu phẳng phân loại tối ưu trong trường hợp có thể phân chia tuyến tính. Đối với câu hỏi phân loại hai loại, hãy đặt tập hợp mẫu đào tạo là ((xi,yi), i = 1,2…l, l là số của mẫu đào tạo, xi là mẫu đào tạo, yi thuộc {-1 + 1} là ký hiệu lớp của mẫu nhập x ((kết quả mong đợi) 。 Điểm khởi đầu của thuật toán SVM là tìm siêu phẳng phân loại tối ưu.
Bảng phân loại siêu phẳng tối ưu không chỉ có thể phân tách tất cả các mẫu một cách chính xác (số điểm lỗi đào tạo là 0), mà còn có thể làm cho biên giới giữa hai loại (đường biên) lớn nhất, biên giới được định nghĩa là tổng khoảng cách nhỏ nhất của tập dữ liệu đào tạo đến bảng phân loại siêu phẳng đó. Bảng phân loại siêu phẳng tối ưu có nghĩa là lỗi phân loại trung bình đối với dữ liệu thử nghiệm là nhỏ nhất.
Nếu có một siêu phẳng trong không gian vectơ d:
F(x)=w*x+b=0
Nếu có thể tách hai loại dữ liệu trên, thì siêu mặt phẳng này được gọi là giao diện phân chia.*x là tích nội của hai vector w và x trong không gian vector chiều d.
Nếu giao diện:
w*x+b=0
Giao diện này được gọi là giao diện tối ưu khi có khoảng cách lớn nhất giữa hai mẫu gần nhất của giao diện đó.
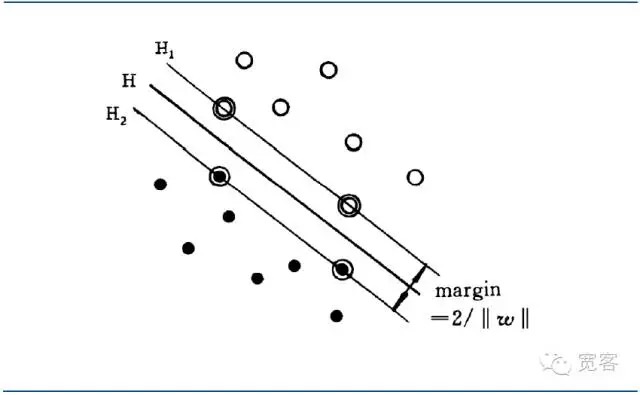 Hình 4 Đồ họa giao diện tối ưu phân loại SVM
Hình 4 Đồ họa giao diện tối ưu phân loại SVMPhân tích các phương trình giao diện tối ưu có thể làm cho khoảng cách giữa hai mẫu
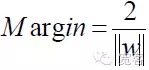
Vì vậy, đối với bất kỳ mẫu nào, có
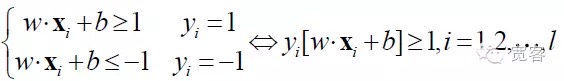
Để có được giao diện tối ưu, ngoài việc đáp ứng các biểu thức trên, bạn cũng cần giảm thiểu.
Mô hình toán học của câu hỏi SVM là:
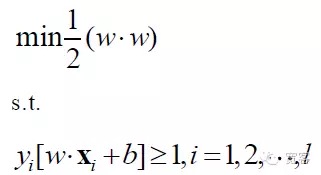
SVM cuối cùng đã trở thành một vấn đề lập kế hoạch tối ưu hóa, các nghiên cứu nóng trong giới học thuật chủ yếu tập trung vào giải pháp nhanh, phổ biến cho các ứng dụng đa lớp, các vấn đề thực tế.
SVM ban đầu được đề xuất cho các vấn đề phân loại thứ hai, theo yêu cầu ứng dụng thực tế hiện tại, nó được mở rộng sang các vấn đề phân loại đa lớp. Các thuật toán phân loại đa lớp đã có bao gồm nhiều cặp, một đối một, mã hóa sửa lỗi, DAG-SVM và bộ phân loại SVM đa lớp.
- #### (III) Lưu trữ chỉ số sổ đơn hàng
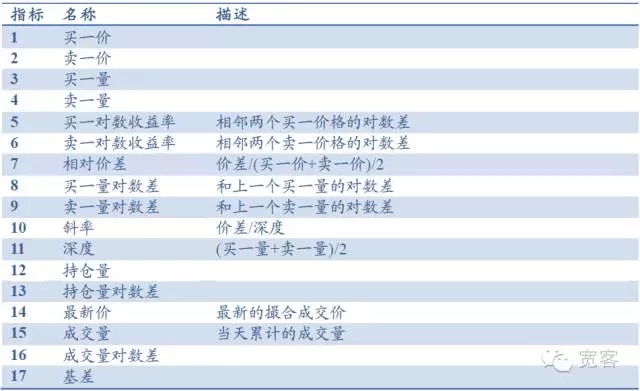
Ví dụ, trong trường hợp chỉ số chứng khoán tương lai cấp 1, sổ đơn đặt hàng bao gồm các chỉ số cơ bản như giá mua, giá bán, giá mua, giá bán, và có thể dẫn ra các chỉ số như độ sâu, độ lệch, chênh lệch giá tương đối, các chỉ số khác bao gồm khối lượng nắm giữ, khối lượng giao dịch, chênh lệch cơ sở, tổng cộng 17 chỉ số, như trong bảng dưới đây. Cũng có thể đưa ra các chỉ số phân tích kỹ thuật phổ biến như RSI, KDJMA, EMA, v.v.
Bảng 1 Thư viện chỉ số dựa trên sổ đơn đặt hàng Level
- #### (iv) Hình vẽ tính năng động của sổ đơn đặt hàng và cơ hội giao dịch
Trong thị trường vi mô, có hai cách để đo động lực giá trong một thời gian ngắn, một là động lực giá trung bình, và một là giá chênh lệch chéo. Trong bài viết này, chúng tôi chọn động lực giá trung bình đơn giản hơn và trực quan hơn.
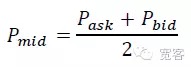
Đường trung bình của giá trị trung bình ΔP trong danh mục đặt hàng trong Δt được chia thành ba loại.
Hình dưới đây là sự phân bố động lực giá trung bình của hợp đồng IF1311 vào ngày 29 tháng 10, với 32400 tick mỗi ngày.
Trong trường hợp Δt = 1tick, giá trung bình thay đổi tuyệt đối 0.2 khoảng 6000 lần, giá tuyệt đối thay đổi 0.4 khoảng 1500 lần, giá tuyệt đối thay đổi 0.6 khoảng 150 lần, giá tuyệt đối thay đổi 0.8 lớn hơn 50 lần, giá tuyệt đối thay đổi lớn hơn bằng 1 khoảng 10 lần.
Trong trường hợp Δt = 2tick, giá trung bình thay đổi tuyệt đối 0.2 khoảng 7000 lần, giá tuyệt đối thay đổi 0.4 khoảng 3000 lần, giá tuyệt đối thay đổi 0.6 khoảng 550 lần, giá tuyệt đối thay đổi 0.8 khoảng 205 lần, giá tuyệt đối thay đổi lớn hơn bằng 1 khoảng 10 lần.
Chúng tôi coi sự thay đổi giá trị tuyệt đối lớn hơn hoặc bằng 0,4 là cơ hội giao dịch tiềm năng. Trong trường hợp Δt = 1 tick, có khoảng 1700 cơ hội mỗi ngày; Trong trường hợp Δt = 2 tick, có khoảng 4000 cơ hội mỗi ngày.
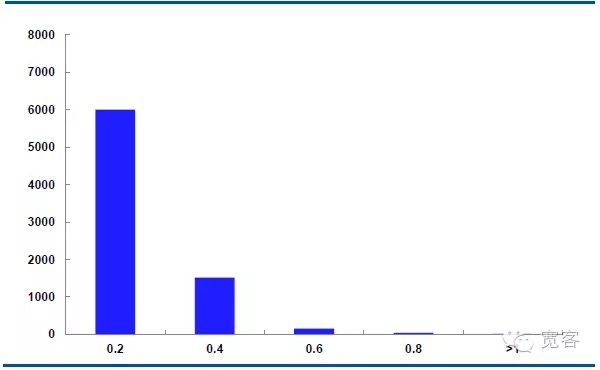
Hình 5 IF1311 Phân bố biến đổi giá trung bình vào ngày 29 tháng 10
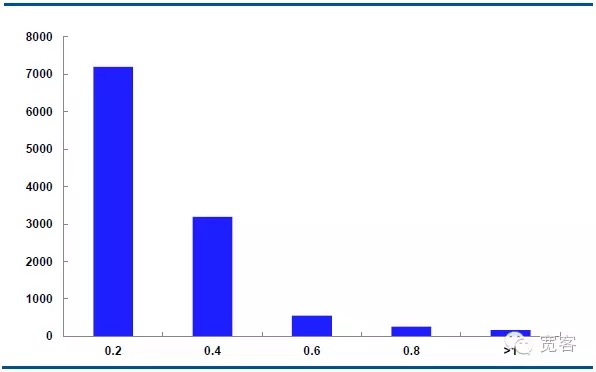
Hình 6 IF1311 Phân bố biến đổi giá trung bình vào ngày 29 tháng 10
-
Ba, chiến lược thực tế.
Do mô hình SVM có độ phức tạp đào tạo cao trong trường hợp mẫu lớn và thời gian đào tạo dài, chúng tôi đã chọn dữ liệu thực tế lịch sử có khoảng thời gian tương đối ngắn, lấy dữ liệu thực tế IF1311 Contract Level_1 vào tháng 10 làm ví dụ để xác minh tính hiệu quả của mô hình.
-
(I) Kiểm tra hiệu quả mô hình
Chu kỳ dữ liệu: dữ liệu về IF1311 trong tháng 10;
Đánh giá Δt: Đánh giá Δt càng nhỏ, yêu cầu về chi tiết giao dịch càng cao, khi Δt = 1 tick, rất khó để có được lợi nhuận trong giao dịch thực tế, để so sánh hiệu quả của mô hình, đây là 1 tick, 2 tick, 3 tick;
Các chỉ số đánh giá mô hình: độ chính xác mẫu, độ chính xác kiểm tra, thời gian dự đoán.
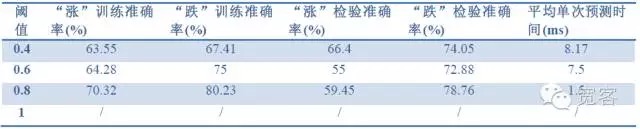 Bảng 2 Dự đoán hiệu quả của 1 tick với dữ liệu 1 tick
Bảng 2 Dự đoán hiệu quả của 1 tick với dữ liệu 1 tick Bảng 3 Dự đoán hiệu quả của tick 2 bằng dữ liệu tick 1
Bảng 3 Dự đoán hiệu quả của tick 2 bằng dữ liệu tick 1 Bảng 4 Dự đoán hiệu quả của 2tick với dữ liệu 2tick
Bảng 4 Dự đoán hiệu quả của 2tick với dữ liệu 2tickTừ những dữ liệu trên ba bảng, chúng ta có thể rút ra một số kết luận: Tính chính xác cao nhất là khoảng 70%, và ở mức độ chính xác là 60%, có thể chuyển thành chiến lược giao dịch.
-
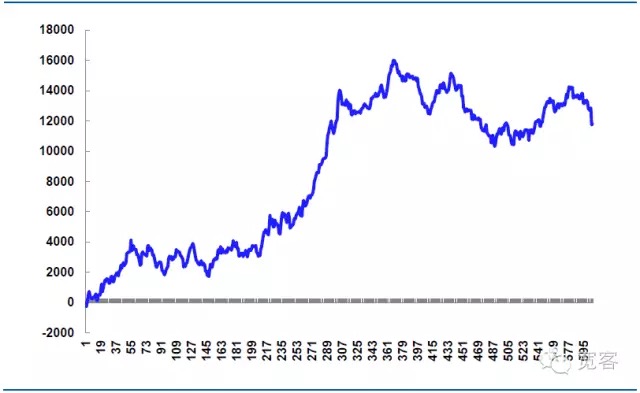
(ii) Chiến lược mô phỏng thu nhập
Ví dụ như vào ngày 31 tháng 10, chúng tôi thực hiện giao dịch mô phỏng, phí giao dịch tương lai chỉ số cổ phiếu của tổ chức thường là phí giao dịch tương lai chỉ số cổ phiếu của tổ chức thường là 0.26⁄10000, chúng tôi giả định số lần giao dịch không có giới hạn thu nhập, giả sử mỗi lần giao dịch giá trượt một chiều là 0,2 điểm, mỗi lần đặt hàng là 1 tay.
Bảng 5 Chiến lược mô phỏng giao dịch vào ngày 31 tháng 10

Số lần giao dịch trong ngày là 605, bao gồm các trường hợp thủ tục, số lần lợi nhuận là 339, tỷ lệ thắng là 56%, lợi nhuận ròng là 11814,99 đô la.
Giá giảm theo lý thuyết là 14.520 USD, đây là một phần của chiến lược chiến đấu thực tế, nếu chi tiết đặt hàng được kiểm soát tinh tế hơn, thì có thể giảm giá giảm, tăng lợi nhuận ròng, nếu chi tiết đặt hàng không được kiểm soát đúng cách, hoặc thị trường biến động bất thường, giá giảm sẽ lớn hơn, và lợi nhuận ròng sẽ giảm, do đó, thành công và thất bại của giao dịch tần số cao thường phụ thuộc vào việc thực hiện chi tiết.
Hình 7 Lợi nhuận của chiến lược mô phỏng vào ngày 31 tháng 10
Tác giả của bài viết này là Nguyễn Quân, được đăng tải bởi Xin ghi rõ nguồn gốc.