全解机器学习3大分类6大算法的优势和劣势
 0
2918
0
2918
全解机器学习3大分类6大算法的优势和劣势
在机器学习中,目标要么是预测(prediction),要么是聚类(clustering)。本文重点关注的是预测。预测是从一组输入变量来预估输出变量的值的过程。例如,得到有关房子的一组特征,我们可以预测它的销售价格。预测问题可以分为两大类:1、回归问题:其中要预测的变量是数字的(如房屋的价格);2、分类问题:其中要预测的变量是“是/否”的答案(如预测某个设备是否会故障) 了解了这点,接下来让我们看看机器学习中最突出、最常用的算法。我们将这些算法分为3类:线性模型、基于树的模型、神经网络,重点介绍6大常用算法:
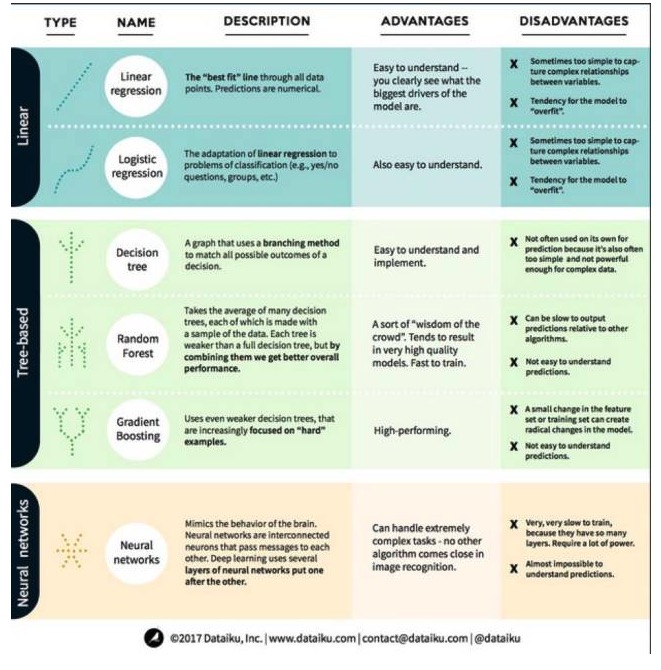
一、线性模型算法:线性模型使用简单的公式,通过一组数据点找到“最佳拟合”的行。这一方法可以追溯到200多年前,在统计学和机器学习领域都得到广泛应用。由于它的简单性,它对统计学很有用。你想要预测的变量(因变量)被表示为你已经知道的变量(自变量)的方程,因此预测只是一个输入自变量,然后算出方程的答案的问题。
- #### 1.线性回归
线性回归,或更准确的说法“最小二乘回归”,是线性模型的最标准形式。对于回归问题,线性回归是最简单的线性模型。其缺点是模型容易过拟合,也就是说,模型完全适应已进行训练的数据,而牺牲了推广到新数据的能力。因此,机器学习中的线性回归(以及我们接下来将谈到的逻辑回归)通常是“正则化”的,这意味着模型有一定的惩罚来防止过拟合。
线性模型的另一个缺点是,由于它们非常简单,所以当输入变量不独立时,他们不容易预测更复杂些的行为。
- #### 2.逻辑回归
逻辑回归是线性回归对分类问题的适应。逻辑回归的缺点与线性回归相同。逻辑函数对分类问题非常好,因为它引入了阈值效应。
二、树模型算法
- #### 1、决策树
决策树是使用分支方法显示决策的每一个可能的结果的图示。比如说,你决定要点一份沙拉,你的第一个决策是可能是生菜的种类,然后是配菜,然后是沙拉酱的种类。我们可以在一个决策树中表示所有可能的结果。
为了训练决策树,我们需要使用训练数据集并找出那个属性对目标最有用。例如,在欺诈检测用例中,我们可能发现对预测欺诈风险影响最大的属性是国家。在以第一个属性进行分支后,我们得到两个子集,这是假如我们只知道第一个属性时最能够准确预测的。接着,我们再找出可以对这两个子集进行分支的第二好的属性,再次进行分割,如此往复,直到使用足够多的属性后能满足目标的需求。
- #### 2、随机森林
随机森林是许多决策树的平均,其中每个决策树都用随机的数据样本进行训练。随机森林中的每个树都比一个完整的决策树弱,但是将所有树放在一起,由于多样性的优势,我们可以获得更好的整体性能。
随机森林是当今机器学习中非常流行的算法。随机森林的训练很容易,而且表现相当好。它的缺点是相对于其他算法,随机森林输出预测可能会很慢,所以在需要快速预测时,可能不会选择随机森林。
- #### 3、梯度提升
梯度提升(GradientBoosting),像随机森林那样,也是由“弱”决策树组成的。梯度提升与随机森林最大的区别是,在梯度提升中,树是一个接一个被训练的。每个后面的树主要由前面的树识别错误的数据来训练。这令梯度提升较少关注易于预测的情况,而更多地关注困难的情况。
梯度提升的训练也很快,表现也非常好。但是,训练数据集的小小变化可以令模型发生根本性的变化,因此它产生的结果可能不是最可行的。
三、神经网络算法:神经网络是指大脑中彼此交换信息的相互联系的神经元组成的生物学现象。这个想法现在被适用到机器学习领域,被 称为 ANN(人工神经网络)。深度学习是叠在一起的多层的神经网络。ANN 是一系列通过学习获取类似人类大脑的认知能力的模型。在处理非常复杂的的任务,例如图像识别时,神经网络表现很好。但是,正如人类大脑一样,训练模型非常耗时,而且需要非常多的能量。
转载自 大数据地盘
- 发明者量化 支持huobi和OKEX的币币交易以及USDT交易吗?
- 公开一个提现函数, 已集成到数字货币交易类库
- 如何通过一个量化策略的回测收益、波动等数据,计算该策略的最大资金容量?
- Shannon’s Demon
- 复杂的绝不是技术,只是人心!交易能力一定要和交易系统相匹配
- bitfinex的接口访问好慢啊,大家有什么关于服务器放置的推荐?
- bitfinex运行出错,帮忙分析,谢谢!
- 请问回测时调用API获取的数据是基于哪个时间点的?
- 求 币安提币的代码 。
- bitfinex的交易对里面为什么只有BCH_USD,BTC_USD,ETH_USD,LTC_USD四种
- 爆赚5000每币:做多BTC,做空okex1229合约,1个月,每币赚5000元!(转)
- 最后观望机制
- 提交Bug:创建策略时无默认参数值的交互按钮导致保存失败
- 请问回测系统不能选择其他币种吗?
- Please translate the buy plan page
- bitfinex有3个市场,如何让机器人选择?谢谢
- 动态视角下的期权共赢
- bitfinex上回测和实测货币单位不一致
- 如何看待背离和金叉死叉的有效性?
- Bithumb获得账户信息错误