Initial Exploration of Applying Python Crawler on FMZ — Crawling Binance Announcement Content
Author: Ninabadass, Created: 2022-04-08 15:47:43, Updated: 2022-04-13 10:07:13Initial Exploration of Applying Python Crawler on FMZ —— Crawling Binance Announcement Content
Recently, I looked through our Forums and Digest, and there is no relevant information about Python crawler. Based on the FMZ spirit of comprehensive development, I went to simply learn about the concepts and knowledge of crawler. After learning about it, I found that there is still more to learn about “crawler technique”. This article is only a preliminary exploration of “crawler technique”, and a simplest practice of crawler technique on FMZ Quant trading platform.
Demand
For traders who like IPO trading, they always want to get the platform listing information as soon as possible. It is obviously unrealistic to manually stare at a platform website all the time. Then you need to use the crawler script to monitor the announcement page of the platform, and detect new announcements in order to be notified and reminded at the first time.
Initial Exploration
Use a very simple program as a start (really powerful crawler scripts are far more complex, so take your time). The program logic is very simple, that is, let the program continuously visit the announcement page of a platform, parse the acquired HTML content, and detect whether the content of a specifed label is updated.
Code Implementation
You can use some useful crawler structures. Considering that the demand is very simple, you can also write directly.
The python libraries to be used:
```bs4```, which can be simply regarded as the library used to parse the HTML code of web pages.
Code:
from bs4 import BeautifulSoup import requests
urlBinanceAnnouncement = “https://www.binancezh.io/en/support/announcement/c-48?navId=48” # Binance announcement web page address
def openUrl(url): headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36’} r = requests.get(url, headers=headers) # use “requests” library to access url, namely the Binance announcement web page address
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def main(): preNews_href = “” lastNews = “” Log(“watching…”, urlBinanceAnnouncement, “#FF0000”) while True: ret = openUrl(urlBinanceAnnouncement) if ret: soup = BeautifulSoup(ret, ‘html.parser’) # parse the page text into objects lastNewshref = soup.find(‘a’, class=‘css-1ej4hfo’)[“href”] # find specified lables, to obtain href lastNews = soup.find(‘a’, class_=‘css-1ej4hfo’).get_text() # obtain the content in the label if preNews_href == “”: preNews_href = lastNews_href if preNews_href != lastNews_href: # the label change detected, namely the new announcement generated Log(“New Cryptocurrency Listing update!”) # print the prompt message preNews_href = lastNews_href LogStatus(_D(), “\n”, “preNews_href:”, preNews_href, “\n”, “news:”, lastNews) Sleep(1000 * 10)
”`
Operation
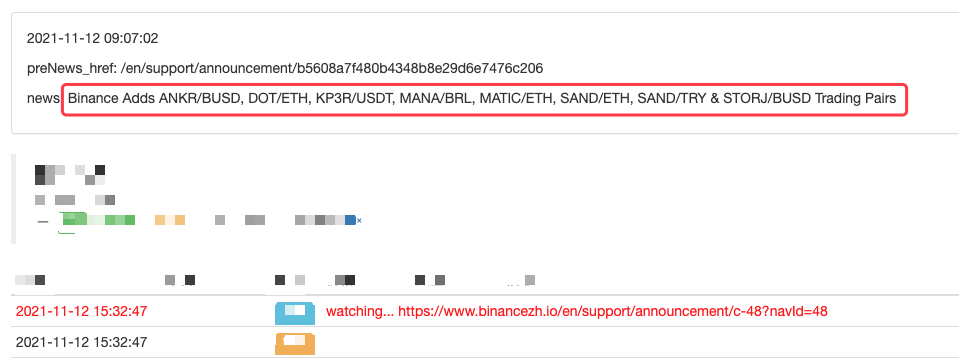
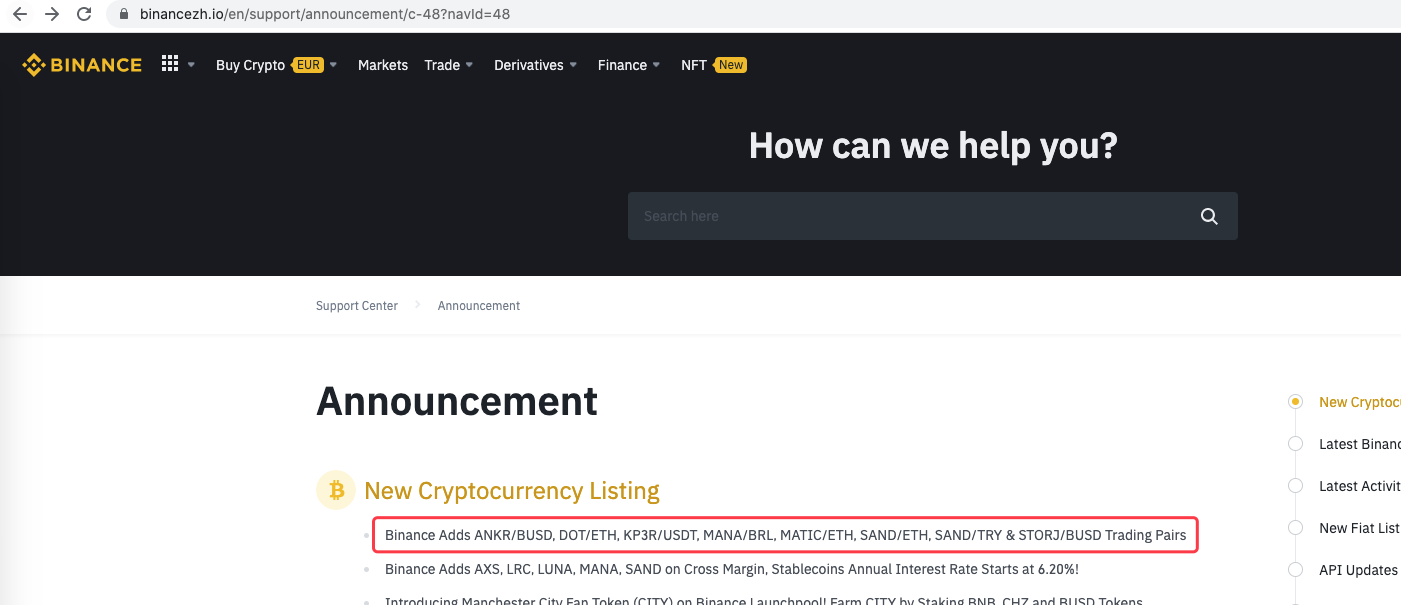
You can even extend it, such as the detection of new announcement, analysis of newly listed currency symbols, and automatic ordering of IPO trade.
- 取消打印某种日志
- 取消当前币种所有未完成订单
- Quick Start of FMZ Quant Trading Platform APP
- Realize a Simple Order Supervising Bot of Cryptocurrency Spot
- 基于FMZ做成跟单平台
- Cryptocurrency Contract Simple Order-Supervising Bot
- 在用getdepth时想获取对应时间戳
- 忽略,已解决
- 面值问题
- dYdX Strategy Design Example
- Hedge Strategy Design Research & Example of Pending Spot and Futures Orders
- Recent Situation and Recommended Operation of Funding Rate Strategy
- Dual Moving Average Breakpoint Strategy of Cryptocurrency Futures (Teaching)
- Cryptocurrency Spot Multi-Symbol Dual Moving Average Strategy (Teaching)
- Realization of Fisher Indicator in JavaScript & Plotting on FMZ
- 托管者
- 2021 Cryptocurrency TAQ Review & Simplest Missed Strategy of 10-Time Increase
- Cryptocurrency Futures Multi-Symbol ART Strategy (Teaching)
- Upgrade! Cryptocurrency Futures Martingale Strategy
- Getrecords函数无法获取以秒为单位的K线图