একটি বিটকয়েন ট্রেডিং বট তৈরি করুন যা অর্থ হারাবে না
 0
5331
0
5331

আসুন একটি ডিজিটাল কারেন্সি ট্রেডিং বট তৈরি করতে কৃত্রিম বুদ্ধিমত্তায় রিইনফোর্সমেন্ট লার্নিং ব্যবহার করি
এই নিবন্ধে, আমরা একটি রিইনফোর্সমেন্ট লার্নিং ফ্রেমওয়ার্ক তৈরি করব এবং প্রয়োগ করব এবং কীভাবে বিটকয়েন ট্রেডিং বট তৈরি করতে হয় তা শিখব। এই টিউটোরিয়ালে, আমরা স্থিতিশীল-বেসলাইন লাইব্রেরি থেকে OpenAI-এর জিম এবং PPO রোবট ব্যবহার করব, যা OpenAI বেসলাইন লাইব্রেরির একটি কাঁটা।
গত কয়েক বছরে গভীর শিক্ষার গবেষকদের ওপেন সোর্স সফ্টওয়্যার প্রদান করার জন্য OpenAI এবং DeepMind কে অনেক ধন্যবাদ। আপনি যদি আলফাগো, ওপেনএআই ফাইভ এবং আলফাস্টারের মতো প্রযুক্তির মাধ্যমে তারা যে আশ্চর্যজনক সাফল্যগুলি অর্জন করেছেন তা না দেখে থাকেন তবে আপনি সম্ভবত গত বছর ধরে বিচ্ছিন্নভাবে বসবাস করছেন, তবে আপনার সেগুলিও পরীক্ষা করা উচিত।
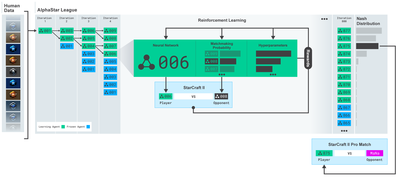
আলফাস্টার প্রশিক্ষণ https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
যদিও আমরা চিত্তাকর্ষক কিছু তৈরি করব না, প্রতিদিনের ভিত্তিতে একটি বিটকয়েন বট ট্রেড করা এখনও কোনও বুদ্ধিমানের কাজ নয়। যাইহোক, যেমন টেডি রুজভেল্ট একবার বলেছিলেন,
খুব সহজ জিনিসের কোন মূল্য নেই।
সুতরাং, আমাদের শুধু নিজেদেরই ট্রেড করতে শিখতে হবে না… কিন্তু আমাদের রোবটকেও আমাদের জন্য ট্রেড করতে দিতে হবে।
পরিকল্পনা

১. আমাদের রোবটের জন্য মেশিন লার্নিং করার জন্য একটি জিম পরিবেশ তৈরি করুন।
একটি সহজ এবং মার্জিত চাক্ষুষ পরিবেশ রেন্ডার করুন
একটি লাভজনক ট্রেডিং কৌশল শিখতে আমাদের রোবটকে প্রশিক্ষণ দিন
আপনি যদি এখনও স্ক্র্যাচ থেকে জিম পরিবেশ তৈরি করতে বা কীভাবে এই পরিবেশগুলির ভিজ্যুয়ালাইজেশন রেন্ডার করতে হয় তার সাথে পরিচিত না হন। এগিয়ে যাওয়ার আগে, এই মত একটি নিবন্ধ google নির্দ্বিধায়. এমনকি সবচেয়ে জুনিয়র প্রোগ্রামারও এই দুটি কাজকে কঠিন মনে করবেন না।
শুরু করা
এই টিউটোরিয়ালে, আমরা জিলাক দ্বারা তৈরি কাগল ডেটাসেট ব্যবহার করব। আপনি যদি সোর্স কোডটি ডাউনলোড করতে চান তবে এটি আমার গিথুব রিপোজিটরিতে, .csv ডেটা ফাইলগুলির সাথে উপলব্ধ। ঠিক আছে, শুরু করা যাক.
প্রথমে, আসুন সমস্ত প্রয়োজনীয় লাইব্রেরি আমদানি করি। আপনি পিপ দিয়ে অনুপস্থিত কোনো লাইব্রেরি ইনস্টল করতে ভুলবেন না।
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
এর পরে, পরিবেশের জন্য আমাদের ক্লাস তৈরি করা যাক। আমাদের অনেকগুলি পান্ডা ডেটা ফ্রেমে পাস করতে হবে, সেইসাথে একটি ঐচ্ছিক প্রাথমিক_ব্যালেন্স এবং একটি লুকব্যাক_উইন্ডো_সাইজ, যা প্রতিটি ধাপে রোবট দ্বারা পর্যবেক্ষণ করা বিগত সময়ের পদক্ষেপের সংখ্যা নির্দেশ করবে। আমরা প্রতি বাণিজ্যে কমিশনকে 0.075% ডিফল্ট করি, যা Bitmex-এর বর্তমান রেট, এবং সিরিয়াল প্যারামিটারটিকে মিথ্যাতে ডিফল্ট করি, যার অর্থ ডিফল্টরূপে আমাদের ডেটাফ্রেম নম্বর র্যান্ডম সেগমেন্টে অতিক্রম করা হবে।
আমরা ডেটাতে dropna() এবং reset_index() কেও কল করি, প্রথমে NaN মান সহ সারিগুলি মুছে ফেলি এবং তারপরে ফ্রেম নম্বরের জন্য সূচকটি পুনরায় সেট করি যেহেতু আমরা ডেটা ফেলে দিয়েছি।
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
আমাদের action_space এখানে 3টি বিকল্পের (ক্রয়, বিক্রয় বা ধরে রাখা) সেট এবং 10টি পরিমাণের (1⁄10, 2⁄10, 3⁄10 ইত্যাদি) আরেকটি সেট হিসাবে উপস্থাপন করা হয়েছে। বাই অ্যাকশন বেছে নেওয়ার সময়, আমরা * স্ব-ব্যালেন্স মূল্যের BTC কিনব। বিক্রির জন্য, আমরা * self.btc_held মূল্যের BTC বিক্রি করব। অবশ্যই, হোল্ড অ্যাকশন পরিমাণ উপেক্ষা করে এবং কিছুই করে না।
আমাদের অবজারভেশন_স্পেসকে 0 এবং 1 এর মধ্যে আকৃতি সহ ফ্লোটগুলির একটি সংলগ্ন সেট হিসাবে সংজ্ঞায়িত করা হয়েছে (10, lookback_window_size + 1)। + 1 বর্তমান সময়ের ধাপ গণনা করতে ব্যবহৃত হয়। উইন্ডোতে প্রতিবার পদক্ষেপের জন্য, আমরা OHCLV মান পর্যবেক্ষণ করব। আমাদের ইক্যুইটি BTC কেনা বা বিক্রি করা সংখ্যার সমান এবং সেই BTC-এ আমরা যে পরিমাণ USD খরচ করেছি বা পেয়েছি তার সমান।
এর পরে, পরিবেশ শুরু করার জন্য আমাদের রিসেট পদ্ধতি লিখতে হবে।
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
এখানে আমরা নিজেকে ব্যবহার করি।_রিসেট_সেশন এবং স্ব._পরবর্তী_পর্যবেক্ষণ, আমরা এখনও তাদের সংজ্ঞায়িত করিনি। আসুন প্রথমে তাদের সংজ্ঞায়িত করি।
ট্রেডিং সেশন
আমাদের পরিবেশের একটি গুরুত্বপূর্ণ অংশ হল ট্রেডিং সেশনের ধারণা। আমরা যদি এই বটটিকে বাজারের বাইরে মোতায়েন করি তবে আমরা সম্ভবত এটি একবারে কয়েক মাসের বেশি চালাতে পারব না। এই কারণে, আমরা self.df এ পরপর ফ্রেমের সংখ্যা সীমিত করব, অর্থাৎ, আমাদের রোবট পরপর কতগুলি ফ্রেম দেখতে পাবে।
আমাদের _reset_session পদ্ধতিতে, আমরা প্রথমে current_step 0 এ রিসেট করি। এর পরে, আমরা 1 এবং MAX_TRADING_SESSION এর মধ্যে একটি এলোমেলো সংখ্যায় steps_left সেট করব, যা আমরা প্রোগ্রামের শীর্ষে সংজ্ঞায়িত করব।
MAX_TRADING_SESSION = 100000 # ~2个月
এরপরে, যদি আমরা ফ্রেমের উপর ক্রমাগত পুনরাবৃত্তি করতে চাই, তাহলে আমাদের এটিকে পুরো ফ্রেম কাউন্টের উপর পুনরাবৃত্তি করার জন্য সেট আপ করতে হবে, অন্যথায় আমরা self.df-এ একটি এলোমেলো পয়েন্টে ফ্রেম_স্টার্ট সেট করি এবং সক্রিয়_ডিএফ নামে একটি নতুন ডেটা ফ্রেম তৈরি করি, যা শুধুমাত্র স্বয়ং। ফ্রেম_স্টার্ট থেকে ফ্রেম_স্টার্ট + স্টেপস_লেফট পর্যন্ত df এর একটি স্লাইস পাওয়া যায়।
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
স্লাইসে র্যান্ডম সংখ্যক ডেটার ফ্রেমের উপর পুনরাবৃত্তি করার একটি গুরুত্বপূর্ণ পার্শ্বপ্রতিক্রিয়া হল যে দীর্ঘ সময় ধরে প্রশিক্ষণের সময় আমাদের রোবট ব্যবহার করার জন্য আরও অনন্য ডেটা থাকবে। উদাহরণস্বরূপ, যদি আমরা সিরিয়াল ফ্যাশনে ডেটা ফ্রেমের সংখ্যার উপর পুনরাবৃত্তি করি (অর্থাৎ 0 থেকে লেন(ডিএফ) পর্যন্ত), তাহলে আমাদের কাছে কেবলমাত্র ডেটা ফ্রেমের সংখ্যার মতো অনেকগুলি অনন্য ডেটা পয়েন্ট থাকবে। আমাদের পর্যবেক্ষণ স্থান এমনকি প্রতিটি সময় ধাপে শুধুমাত্র একটি পৃথক সংখ্যক রাজ্য গ্রহণ করতে পারে।
যাইহোক, এলোমেলোভাবে ডেটাসেটের স্লাইসগুলিকে অতিক্রম করে, আমরা প্রারম্ভিক ডেটাসেটের প্রতিটি ধাপের জন্য ট্রেডিং ফলাফলের আরও অর্থপূর্ণ সেট তৈরি করতে পারি, অর্থাৎ, আরও অনন্য ডেটা সেট তৈরি করতে ট্রেডিং অ্যাকশন এবং পূর্বে দেখা মূল্য অ্যাকশনের সংমিশ্রণ। একটা উদাহরণ দিয়ে ব্যাখ্যা করি।
সিরিয়াল এনভায়রনমেন্ট রিসেট করার পর দশম ধাপে, আমাদের রোবট সবসময় ডেটাসেটের মধ্যে একযোগে চলবে এবং প্রতিটি ধাপের পর 3টি পছন্দ থাকবে: কেনা, বিক্রি বা ধরে রাখা। এই তিনটি বিকল্পের প্রতিটির জন্য, আরেকটি বিকল্প প্রয়োজন: 10%, 20%, … বা নির্দিষ্ট বাস্তবায়নের পরিমাণের 100%। এর মানে হল যে আমাদের রোবটটি 103টি থেকে 10টি রাজ্যের ক্ষমতার মধ্যে যেকোনো একটির মুখোমুখি হতে পারে, মোট 1030টি পরিস্থিতি।
এখন ফিরে আসি আমাদের এলোমেলোভাবে কাটা পরিবেশে। 10-এর একটি ধাপে, আমাদের রোবট ডেটা ফ্রেমের সংখ্যার মধ্যে যেকোনো len(df) সময় ধাপে থাকতে পারে। ধরে নিলাম প্রতিটি টাইম স্টেপের পরে একই পছন্দ করা হয়েছে, এর মানে হল রোবট একই 10 বার ধাপে পাওয়ার 30-এ উত্থাপিত len(df)-এ যেকোনো অনন্য অবস্থা অনুভব করতে পারে।
যদিও এটি বৃহৎ ডেটা সেটগুলিতে যথেষ্ট শব্দ প্রবর্তন করতে পারে, আমি বিশ্বাস করি রোবটগুলিকে আমাদের কাছে থাকা সীমিত পরিমাণ ডেটা থেকে আরও শিখতে দেওয়া উচিত। অ্যালগরিদমের কার্যকারিতা সম্পর্কে আরও সঠিক বোঝার জন্য আমরা এখনও নতুন, আপাতদৃষ্টিতে ‘লাইভ’ ডেটা পেতে সিরিয়াল ফ্যাশনে আমাদের পরীক্ষার ডেটা লুপ করি।
রোবটের চোখ দিয়ে দেখা
আমাদের রোবট কী ধরণের ফাংশন ব্যবহার করবে তা বোঝার জন্য পরিবেশের একটি ভালো চাক্ষুষ ধারণা থাকা প্রায়শই সহায়ক। উদাহরণস্বরূপ, এখানে OpenCV ব্যবহার করে রেন্ডার করা পর্যবেক্ষণযোগ্য স্থানের একটি ভিজ্যুয়ালাইজেশন রয়েছে।

OpenCV ভিজ্যুয়াল পরিবেশের পর্যবেক্ষণ
চিত্রের প্রতিটি সারি আমাদের পর্যবেক্ষণ_স্থানের একটি সারি প্রতিনিধিত্ব করে। অনুরূপ ফ্রিকোয়েন্সির লাল রেখার প্রথম 4টি সারি OHCL ডেটা উপস্থাপন করে, এবং সরাসরি নীচে কমলা এবং হলুদ বিন্দুগুলি ট্রেডিং ভলিউমকে উপস্থাপন করে। নীচের ওঠানামা করা নীল বারটি রোবটের ইক্যুইটি, যখন নীচের হালকা বারগুলি রোবটের ব্যবসার প্রতিনিধিত্ব করে৷
আপনি যদি মনোযোগ সহকারে দেখেন তবে আপনি নিজেই একটি ক্যান্ডেলস্টিক চার্ট তৈরি করতে পারেন। লেনদেন ভলিউম বারের নীচে মোর্স কোডের মতো একটি ইন্টারফেস রয়েছে, যা লেনদেনের ইতিহাস প্রদর্শন করে। দেখে মনে হচ্ছে আমাদের বট আমাদের পর্যবেক্ষণ_স্থানের ডেটা থেকে পর্যাপ্তভাবে শিখতে সক্ষম হবে, তাই চলুন চালিয়ে যাওয়া যাক। এখানে আমরা _next_observation পদ্ধতিটি সংজ্ঞায়িত করব যেখানে আমরা 0 থেকে 1 পর্যন্ত পর্যবেক্ষণ করা ডেটা স্কেল করব।
- সামনের দিকের পক্ষপাত রোধ করার জন্য রোবট এখন পর্যন্ত যে ডেটা পর্যবেক্ষণ করেছে তা কেবল প্রসারিত করা গুরুত্বপূর্ণ।
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
ব্যবস্থা নেওয়া
এখন যেহেতু আমাদের পর্যবেক্ষণ স্থানটি সেট আপ করা হয়েছে, এখন আমাদের স্টেপ ফাংশনটি লেখার এবং তারপরে রোবটটি যে পদক্ষেপগুলি নিতে চায় তা নেওয়ার সময়। যখনই আমাদের বর্তমান ট্রেডিং সেশনের জন্য self.steps_left == 0 হবে, আমরা আমাদের BTC হোল্ডিং বিক্রি করব এবং reset session() কল করব। অন্যথায়, আমরা বর্তমান ইকুইটিতে পুরষ্কার সেট করি, অথবা যদি আমাদের তহবিল শেষ হয়ে যায় তবে সম্পন্নকে True তে সেট করি।
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
ট্রেডিং অ্যাকশন নেওয়া বর্তমান_মূল্য পাওয়ার মতোই সহজ, যে অ্যাকশনটি সম্পাদন করতে হবে এবং কেনা বা বিক্রির পরিমাণ নির্ধারণ করা। আসুন দ্রুত _take_action লিখি যাতে আমরা আমাদের পরিবেশ পরীক্ষা করতে পারি।
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
অবশেষে, একই পদ্ধতিতে, আমরা ট্রেডগুলিকে self.trades-এ যুক্ত করব এবং আমাদের ইক্যুইটি এবং অ্যাকাউন্টের ইতিহাস আপডেট করব।
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
আমাদের বট এখন একটি নতুন পরিবেশ চালু করতে পারে, এর মধ্য দিয়ে যেতে পারে এবং পরিবেশকে প্রভাবিত করে এমন পদক্ষেপ নিতে পারে। এটা তাদের বাণিজ্য দেখার সময়.
আমাদের রোবটদের ব্যবসা দেখুন
আমাদের রেন্ডার পদ্ধতি প্রিন্ট (self.net_worth) কল করার মতো সহজ হতে পারে, তবে এটি যথেষ্ট আকর্ষণীয় হবে না। পরিবর্তে, আমরা একটি ভলিউম বার এবং আমাদের ইক্যুইটির একটি পৃথক চার্ট সহ একটি সাধারণ ক্যান্ডেলস্টিক চার্ট আঁকব।
আমরা আমার শেষ নিবন্ধ থেকে StockTradingGraph.py-এ কোডটি নেব এবং বিটকয়েন পরিবেশের সাথে মানানসই করার জন্য এটিকে পুনরায় ডিজাইন করব। আপনি আমার Github থেকে কোড পেতে পারেন.
আমরা প্রথম যে পরিবর্তনটি করতে যাচ্ছি তা হল self.df পরিবর্তন করা।[ ‘তারিখ’] self.df এ আপডেট করুন[‘টাইমস্ট্যাম্প’], এবং date2num-এ সমস্ত কল মুছে ফেলুন যেহেতু আমাদের তারিখগুলি ইতিমধ্যেই ইউনিক্স টাইমস্ট্যাম্প ফর্ম্যাটে রয়েছে। এর পরে, আমাদের রেন্ডার পদ্ধতিতে, আমরা একটি সংখ্যার পরিবর্তে একটি মানব-পাঠযোগ্য তারিখ প্রিন্ট করতে তারিখ লেবেলটি আপডেট করব।
from datetime import datetime
প্রথমে ডেটটাইম লাইব্রেরি ইম্পোর্ট করুন, তারপর আমরা প্রতিটি টাইমস্ট্যাম্প থেকে UTC স্ট্রিং পেতে utcfromtimestampmethod ব্যবহার করব এবং strftime এটিকে এভাবে ফরম্যাট করতে হবে: Y-m-d H:M ফর্ম্যাট করা স্ট্রিং।
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
অবশেষে, আমরা self.df করব[‘ভলিউম’] self.df এ পরিবর্তিত হয়েছে[‘ভলিউম_(বিটিসি)’] আমাদের ডেটাসেটের সাথে মেলে, এটি সম্পূর্ণ করুন এবং আমরা প্রস্তুত। আমাদের BitcoinTradingEnv-এ ফিরে, আমরা এখন গ্রাফ প্রদর্শনের জন্য রেন্ডারিং পদ্ধতি লিখতে পারি।
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
দেখো! আমরা এখন আমাদের রোবট ব্যবসা বিটকয়েন দেখতে পারি।

ম্যাটপ্লটলিবের সাথে আমাদের রোবটের ট্রেডিং কল্পনা করা
সবুজ ফ্যান্টম লেবেলগুলি BTC-এর কেনার প্রতিনিধিত্ব করে, এবং লাল ফ্যান্টম লেবেলগুলি বিক্রির প্রতিনিধিত্ব করে৷ উপরের ডানদিকের কোণায় থাকা সাদা লেবেলটি হল রোবটের বর্তমান নেট মূল্য এবং নীচের ডানদিকের কোণায় থাকা লেবেলটি হল বিটকয়েনের বর্তমান মূল্য৷ সহজ কিন্তু মার্জিত. এখন, আমাদের রোবটকে প্রশিক্ষণ দেওয়ার এবং আমরা কত টাকা উপার্জন করতে পারি তা দেখার সময়!
প্রশিক্ষণ সময়
আমার পূর্ববর্তী নিবন্ধে আমি একটি সমালোচনা পেয়েছি ক্রস-বৈধকরণের অভাব, প্রশিক্ষণ এবং পরীক্ষার সেটগুলিতে ডেটা বিভক্ত না করা। এর উদ্দেশ্য হল নতুন ডেটার উপর চূড়ান্ত মডেলের নির্ভুলতা পরীক্ষা করা যা আগে কখনও দেখা যায়নি। যদিও এটি সেই নিবন্ধের ফোকাস নয়, এটি অবশ্যই গুরুত্বপূর্ণ। যেহেতু আমরা টাইম সিরিজ ডেটা ব্যবহার করছি, তাই ক্রস-ভ্যালিডেশনের ক্ষেত্রে আমাদের কাছে খুব বেশি পছন্দ নেই।
উদাহরণ স্বরূপ, ক্রস-ভ্যালিডেশনের একটি সাধারণ ফর্মকে কে-ফোল্ড ভ্যালিডেশন বলা হয়, যেখানে আপনি ডেটাকে k সমান গ্রুপে বিভক্ত করেন, একবারে একটি গ্রুপকে টেস্ট গ্রুপ হিসেবে এবং অবশিষ্ট ডেটাকে ট্রেনিং গ্রুপ হিসেবে। যাইহোক, টাইম সিরিজ ডেটা সময়ের উপর অত্যন্ত নির্ভরশীল, যার মানে পরবর্তী ডেটাগুলি আগের ডেটার উপর অত্যন্ত নির্ভরশীল। সুতরাং k-fold কাজ করবে না কারণ আমাদের বট ট্রেড করার আগে ভবিষ্যতের ডেটা থেকে শিখবে, যা একটি অন্যায্য সুবিধা।
টাইম সিরিজ ডেটাতে প্রয়োগ করার সময় অন্যান্য ক্রস-ভ্যালিডেশন কৌশলগুলিতে একই সমস্যাগুলি প্রযোজ্য। তাই আমরা সম্পূর্ণ ডেটা ফ্রেম নম্বরের একটি অংশকে একটি প্রশিক্ষণ সেট হিসাবে ব্যবহার করি যা ফ্রেম নম্বর থেকে শুরু করে কিছু স্বেচ্ছাচারী সূচক পর্যন্ত, এবং বাকি ডেটা একটি পরীক্ষা সেট হিসাবে।
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
পরবর্তী, যেহেতু আমাদের পরিবেশ শুধুমাত্র একটি একক ডেটা ফ্রেম প্রক্রিয়া করার জন্য সেট আপ করা হয়েছে, আমরা দুটি পরিবেশ তৈরি করব, একটি প্রশিক্ষণ ডেটার জন্য এবং একটি পরীক্ষার ডেটার জন্য৷
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
এখন, আমাদের মডেলকে প্রশিক্ষণ দেওয়া আমাদের পরিবেশ ব্যবহার করে বট তৈরি করা এবং model.learn কল করার মতোই সহজ।
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
এখানে আমরা টেনসরবোর্ড ব্যবহার করি যাতে আমরা সহজেই আমাদের টেনসরফ্লো গ্রাফটি কল্পনা করতে পারি এবং আমাদের বট সম্পর্কে কিছু পরিমাণগত মেট্রিক্স দেখতে পারি। উদাহরণস্বরূপ, এখানে 200,000 টাইম ধাপে অনেক বটের জন্য ছাড় দেওয়া পুরস্কারের একটি গ্রাফ রয়েছে:
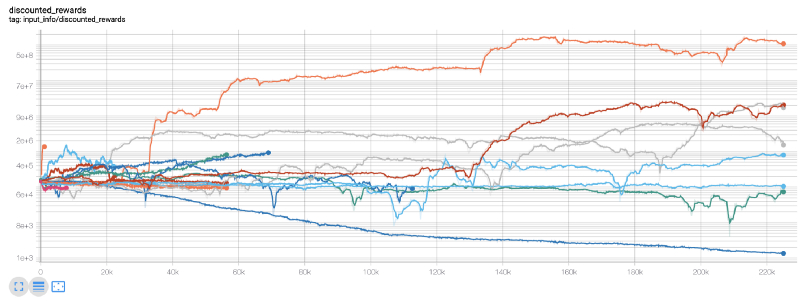
বাহ, মনে হচ্ছে আমাদের বট খুব লাভজনক! আমাদের সেরা রোবটটি এমনকি 200,000 ধাপে 1000x ব্যালেন্স অর্জন করতে সক্ষম হয়েছিল, বাকিদের গড় কমপক্ষে 30x বেশি!
ঠিক তখনই আমি বুঝতে পেরেছিলাম যে পরিবেশে একটি বাগ আছে… সেই বাগটি ঠিক করার পর, এখানে নতুন পুরস্কারের প্লট রয়েছে:
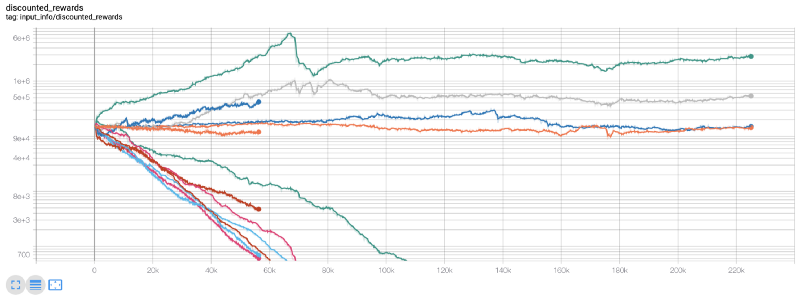
আপনি দেখতে পাচ্ছেন, আমাদের কিছু বট খুব ভাল করেছে এবং বাকিরা নিজেরাই দেউলিয়া হয়ে গেছে। যাইহোক, ভাল-পারফর্মিং বটগুলি তাদের প্রাথমিক ভারসাম্য 10x বা এমনকি 60x পর্যন্ত অর্জন করতে সক্ষম। আমাকে স্বীকার করতে হবে, সমস্ত লাভ বট ছেলেরা কমিশন ছাড়াই প্রশিক্ষিত এবং পরীক্ষিত হয়, তাই আমাদের বটদের জন্য প্রকৃত অর্থ উপার্জন করা অবাস্তব হবে। কিন্তু আমরা অন্তত দিক খুঁজে পেয়েছি!
আসুন আমাদের বটগুলিকে একটি পরীক্ষার পরিবেশে পরীক্ষা করি (নতুন ডেটা ব্যবহার করে যা তারা আগে কখনও দেখেনি) এবং তারা কীভাবে কাজ করে তা দেখুন।
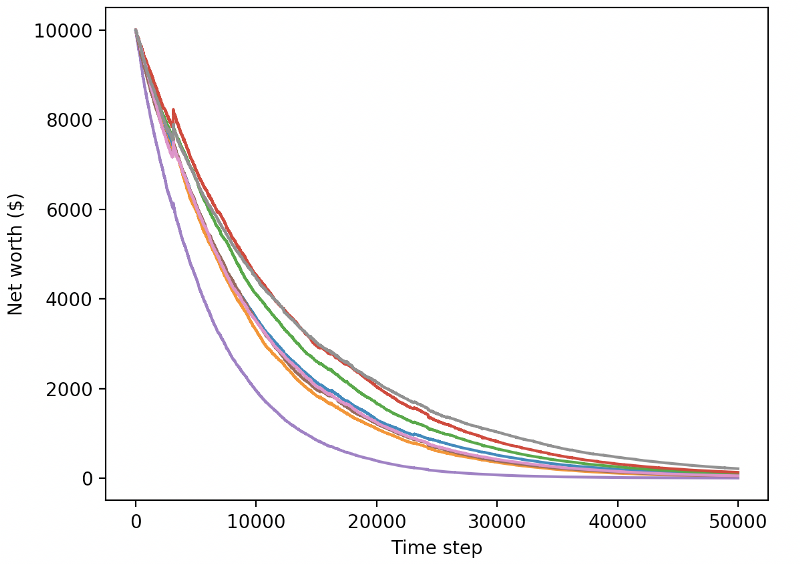
নতুন পরীক্ষার ডেটা ট্রেড করার সময় আমাদের প্রশিক্ষিত বট দেউলিয়া হয়ে যায়
স্পষ্টতই, আমাদের এখনও অনেক কাজ বাকি আছে। বর্তমান PPO2 বটের পরিবর্তে স্থিতিশীল বেসলাইন A2C ব্যবহার করার জন্য মডেলটি পরিবর্তন করে আমরা এই ডেটাসেটে আমাদের কর্মক্ষমতা উল্লেখযোগ্যভাবে উন্নত করতে পারি। অবশেষে, Sean O’Gorman-এর পরামর্শ অনুসরণ করে, আমরা আমাদের পুরষ্কার ফাংশনকে কিছুটা আপডেট করতে পারি যাতে আমরা শুধুমাত্র একটি উচ্চ সম্পদ অর্জন এবং সেখানে থাকার পরিবর্তে আমাদের নেট মূল্যে পুরষ্কার যোগ করতে পারি।
reward = self.net_worth - prev_net_worth
এই দুটি পরিবর্তন একাই পরীক্ষার ডেটাসেটের কার্যক্ষমতাকে উল্লেখযোগ্যভাবে উন্নত করেছে, এবং আপনি নীচে দেখতে পাচ্ছেন, আমরা অবশেষে নতুন ডেটাতে লাভজনকতা অর্জন করতে সক্ষম হয়েছি যা প্রশিক্ষণ সেটে ছিল না।
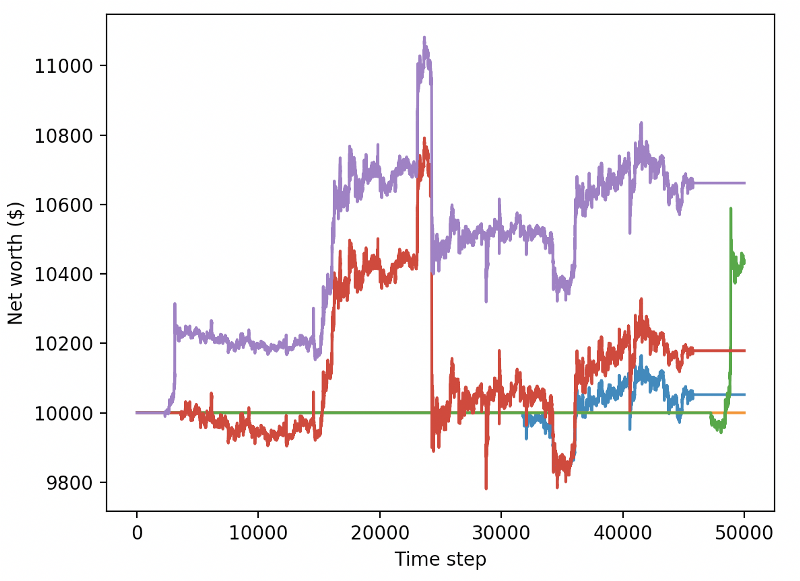
তবে আমরা আরও ভালো করতে পারি। আমাদের এই ফলাফলগুলি উন্নত করার জন্য, আমাদের হাইপারপ্যারামিটারগুলিকে অপ্টিমাইজ করতে হবে এবং আমাদের রোবটকে দীর্ঘ সময়ের জন্য প্রশিক্ষণ দিতে হবে। GPU-কে কাজে লাগানোর এবং এটি চালু করার সময় এসেছে!
এই মুহুর্তে, এই নিবন্ধটি ইতিমধ্যেই কিছুটা দীর্ঘ, এবং আমাদের এখনও অনেক বিশদ বিবেচনা করার আছে, তাই আমরা এখানে একটি বিরতি নিতে যাচ্ছি। পরবর্তী পোস্টে, আমরা আমাদের সমস্যার স্থানের জন্য সর্বোত্তম হাইপারপ্যারামিটারগুলিকে বিভাজন করতে Bayesian অপ্টিমাইজেশান ব্যবহার করব এবং CUDA ব্যবহার করে GPU-তে প্রশিক্ষণ/পরীক্ষার জন্য প্রস্তুত করব।
উপসংহারে
এই নিবন্ধে, আমরা শক্তিবৃদ্ধি শিক্ষা ব্যবহার করে স্ক্র্যাচ থেকে একটি লাভজনক বিটকয়েন ট্রেডিং বট তৈরি করার জন্য সেট করেছি। আমরা নিম্নলিখিত কাজগুলি সম্পন্ন করতে সক্ষম:
স্ক্র্যাচ থেকে বিটকয়েন ট্রেডিং পরিবেশ তৈরি করতে OpenAI-এর জিম ব্যবহার করুন।
এই পরিবেশের একটি ভিজ্যুয়ালাইজেশন তৈরি করতে Matplotlib ব্যবহার করুন।
সহজ ক্রস-ভ্যালিডেশন ব্যবহার করে আমাদের বটকে প্রশিক্ষণ দিন এবং পরীক্ষা করুন।
লাভজনক হতে আমাদের বটকে সামান্য পরিবর্তন করুন
যদিও আমাদের ট্রেডিং বট আমাদের পছন্দ মতো লাভজনক নয়, আমরা ইতিমধ্যেই সঠিক পথে চলেছি। পরের বার, আমরা নিশ্চিত করব যে আমাদের বট ধারাবাহিকভাবে বাজারকে হারাতে পারে এবং আমরা দেখব যে আমাদের ট্রেডিং বট রিয়েল-টাইম ডেটা দিয়ে কী করে। আমার পরবর্তী নিবন্ধের জন্য সাথে থাকুন, এবং দীর্ঘজীবী বিটকয়েন!