নিউরাল নেটওয়ার্ক এবং ডিজিটাল কারেন্সি কোয়ান্টিটেটিভ ট্রেডিং সিরিজ (2) - ডিপ রিইনফোর্সমেন্ট লার্নিং ট্রেনিং বিটকয়েন ট্রেডিং কৌশল
 7
5787
7
5787

1. ভূমিকা
পূর্ববর্তী নিবন্ধে বিটকয়েনের দামের পূর্বাভাস দেওয়ার জন্য LSTM নেটওয়ার্ক ব্যবহার করা হয়েছিল https://www.fmz.com/digest-topic/4035 নিবন্ধে উল্লেখ করা হয়েছে, এটি RNN এবং pytorch এর সাথে পরিচিত হওয়ার জন্য একটি ছোট প্রকল্প। এই নিবন্ধটি ট্রেডিং কৌশলগুলিকে সরাসরি প্রশিক্ষণের জন্য শক্তিবৃদ্ধি শেখার ব্যবহার করার পদ্ধতি চালু করবে। রিইনফোর্সমেন্ট লার্নিং মডেল হল OpenAI এর ওপেন সোর্স PPO, এবং পরিবেশ জিম শৈলীকে বোঝায়। বোঝার এবং পরীক্ষা করার সুবিধার্থে, LSTM PPO মডেল এবং ব্যাকটেস্টিংয়ের জন্য জিমের পরিবেশ রেডিমেড প্যাকেজ ব্যবহার না করে সরাসরি লেখা হয়েছে। PPO, প্রক্সিমাল পলিসি অপ্টিমাইজেশানের পুরো নাম, হল পলিসি গ্রেডেন্টের অপ্টিমাইজেশান এবং উন্নতি, অর্থাৎ পলিসি গ্রেডিয়েন্ট। জিমটি ওপেনএআই দ্বারা প্রকাশ করা হয়েছে এবং এটি বর্তমান পরিবেশের অবস্থা এবং পুরষ্কার সম্পর্কে প্রতিক্রিয়া জানাতে পারে, ঠিক যেমন LSTM ব্যবহার করে PPO মডেলটি সরাসরি ক্রয়, বিক্রয় বা কোন অপারেশন করতে পারে না। বিটকয়েনের বাজার তথ্য ব্যাকটেস্ট পরিবেশ দ্বারা দেওয়া হয়, এবং কৌশলগত লাভজনকতা অর্জনের জন্য মডেলটি ক্রমাগতভাবে অপ্টিমাইজ করা হয়। এই নিবন্ধটি পড়ার জন্য Python, pytorch এবং DRL-এ গভীর শক্তিবৃদ্ধি শিক্ষার একটি নির্দিষ্ট ভিত্তি প্রয়োজন। তবে আপনি যদি এটি না জানেন তবে এটি কোন ব্যাপার না, এই নিবন্ধে দেওয়া কোডটি একত্রিত করা, এটি শিখতে এবং শুরু করা সহজ। এই নিবন্ধটি FMZ দ্বারা উত্পাদিত হয়েছে, যা ডিজিটাল মুদ্রার পরিমাণগত ট্রেডিং প্ল্যাটফর্মের (www.fmz.com) উদ্ভাবক, যোগাযোগের জন্য QQ গ্রুপে যোগ দিতে স্বাগতম।
2. ডেটা এবং শেখার রেফারেন্স উপকরণ
বিটকয়েন মূল্যের ডেটা FMZ উদ্ভাবক পরিমাণগত ট্রেডিং প্ল্যাটফর্ম থেকে আসে: https://www.quantinfo.com/Tools/View/4.html ট্রেডিং কৌশলগুলি প্রশিক্ষণের জন্য DRL+gym ব্যবহার করে একটি নিবন্ধ: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4 পাইটর্চ দিয়ে শুরু করার কিছু উদাহরণ: https://github.com/yunjey/pytorch-tutorial এই নিবন্ধটি সরাসরি এই LSTM-PPO মডেলের সংক্ষিপ্ত বাস্তবায়ন ব্যবহার করবে: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py PPO সম্পর্কে প্রবন্ধ: https://zhuanlan.zhihu.com/p/38185553 ডিআরএল সম্পর্কে আরও নিবন্ধ: https://www.zhihu.com/people/flood-sung/posts জিম সম্পর্কে, এই নিবন্ধটির ইনস্টলেশনের প্রয়োজন নেই, তবে শক্তিবৃদ্ধি শেখার খুব সাধারণভাবে ব্যবহৃত হয়: https://gym.openai.com/
3.LSTM-PPO
PPO এর গভীর ব্যাখ্যার জন্য, আপনি পূর্ববর্তী রেফারেন্স সামগ্রীগুলি অধ্যয়ন করতে পারেন এটি কেবলমাত্র সাধারণ ধারণাগুলির একটি ভূমিকা। LSTM নেটওয়ার্কের শেষ সংখ্যাটি কেবলমাত্র এই পূর্বাভাসিত মূল্যের উপর ভিত্তি করে ক্রয়-বিক্রয় লেনদেনের পূর্বাভাস দিয়েছে, এটি কি সরাসরি ক্রয়-বিক্রয় ক্রিয়াকলাপের আউটপুট হবে না? এটি পলিসি গ্রেডেন্টের ক্ষেত্রে, যা ইনপুট পরিবেশগত তথ্যের উপর ভিত্তি করে বিভিন্ন কর্মের সম্ভাব্যতা দিতে পারে। LSTM-এর ক্ষতি হল পূর্বাভাসিত মূল্য এবং প্রকৃত মূল্যের মধ্যে পার্থক্য, যখন PG-এর ক্ষতি হল -log(p)*Q, যেখানে p হল একটি আউটপুট অ্যাকশনের সম্ভাব্যতা, এবং Q হল অ্যাকশনের মান (যেমন পুরস্কার স্কোর) স্বজ্ঞাত ব্যাখ্যা হল যে যদি কোনও অ্যাকশনের মান বেশি হয়, তাহলে নেটওয়ার্কটি কমানোর জন্য উচ্চতর সম্ভাবনা তৈরি করবে। ক্ষতি যদিও পিপিও অনেক বেশি জটিল, তবে মূল বিষয় হল প্রতিটি কাজের মানকে কীভাবে আরও ভালভাবে মূল্যায়ন করা যায় এবং কীভাবে পরামিতিগুলিকে আরও ভালভাবে আপডেট করা যায়।
LSTM-PPO-এর সোর্স কোড নীচে দেওয়া হবে, যা পূর্ববর্তী তথ্যের সাথে একত্রে বোঝা যাবে:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. বিটকয়েন ব্যাকটেস্ট পরিবেশ
জিমের বিন্যাস অনুকরণ করে, একটি রিসেট প্রারম্ভিক পদ্ধতি আছে, ধাপে ইনপুট অ্যাকশন, এবং প্রত্যাবর্তিত ফলাফল হল (পরবর্তী অবস্থা, অ্যাকশন আয়, শেষ হবে কিনা, অতিরিক্ত তথ্য), সম্পূর্ণ ব্যাকটেস্ট পরিবেশে শুধুমাত্র 60 লাইন রয়েছে এবং পরিবর্তন করা যেতে পারে নিজের দ্বারা জটিল সংস্করণ, নির্দিষ্ট কোড:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. বেশ কিছু উল্লেখযোগ্য বিবরণ
প্রাথমিক খাতায় কয়েন থাকে কেন?
ব্যাকটেস্ট পরিবেশে আয় গণনার সূত্র হল: বর্তমান আয় = বর্তমান অ্যাকাউন্টের মান - প্রাথমিক অ্যাকাউন্টের বর্তমান মূল্য। এর মানে হল যে যদি বিটকয়েনের দাম কমে যায় এবং কৌশলটি কয়েন বিক্রি করে, মোট অ্যাকাউন্টের মান কমে গেলেও কৌশলটি আসলে পুরস্কৃত করা উচিত। ব্যাকটেস্টে যদি দীর্ঘ সময় লাগে, প্রাথমিক অ্যাকাউন্টে বড় প্রভাব নাও থাকতে পারে, তবে এটি এখনও শুরুতে একটি বড় প্রভাব ফেলবে। আপেক্ষিক রিটার্ন গণনা করা নিশ্চিত করে যে প্রতিটি সঠিক অপারেশনের জন্য ইতিবাচক পুরস্কার পাওয়া যায়।
প্রশিক্ষণের সময় বাজারের নমুনা কেন?
ডেটার মোট পরিমাণ 10,000 কে-লাইনগুলির বেশি হলে, যদি একটি সম্পূর্ণ চক্র প্রতিবার চালানো হয়, তবে এটি অনেক সময় নেবে এবং কৌশলটি প্রতিবার ঠিক একই পরিস্থিতির মুখোমুখি হবে, যা এটিকে ওভারফিট করা সহজ করে তুলতে পারে৷ ব্যাকটেস্ট ডেটা হিসাবে প্রতিবার 500টি শিকড় বের করা হয় যদিও এটি এখনও ওভারফিট করা সম্ভব, কৌশলটি 10,000টিরও বেশি বিভিন্ন সম্ভাব্য শুরুর মুখোমুখি হয়।
আমার কোন মুদ্রা বা টাকা না থাকলে আমার কি করা উচিত?
যদি কারেন্সি বিক্রি হয়ে যায় বা ন্যূনতম লেনদেন ভলিউম না পৌঁছানো যায়, তাহলে এই সময়ে মূল্য না কমলে কোনো অপারেশন করার সমতুল্য আপেক্ষিক আয়ের পদ্ধতি, এটি এখনও কৌশলের উপর ভিত্তি করে ইতিবাচক পুরস্কার। এই পরিস্থিতির প্রভাব হল যে যখন কৌশল নির্ধারণ করে যে বাজার পতন হচ্ছে এবং অ্যাকাউন্টে অবশিষ্ট মুদ্রা বিক্রি করা যাবে না, তখন এটি বিক্রয় কর্ম এবং অ-পরিচালন ক্রিয়াগুলির মধ্যে পার্থক্য করতে পারে না, তবে কৌশলটির নিজস্ব রায়ের উপর এটির কোন প্রভাব নেই। বাজার
কেন অ্যাকাউন্টের তথ্য স্ট্যাটাস হিসাবে ফেরত দেওয়া উচিত?
PPO মডেলের একটি মান নেটওয়ার্ক রয়েছে যা বর্তমান অবস্থার মূল্যায়নের জন্য ব্যবহার করা হয়, যদি কৌশল নির্ধারণ করে যে দাম বাড়তে চলেছে, সমগ্র রাজ্যের একটি ইতিবাচক মান তখনই থাকবে যখন বর্তমান অ্যাকাউন্টে বিটকয়েন থাকবে এবং এর বিপরীতে। . অতএব, অ্যাকাউন্ট তথ্য মান নেটওয়ার্ক বিচারের জন্য একটি গুরুত্বপূর্ণ ভিত্তি। মনে রাখবেন যে অতীত কর্মের তথ্য স্ট্যাটাস হিসাবে ফেরত দেওয়া হয় না, এবং আমি ব্যক্তিগতভাবে মনে করি মূল্য বিচার করার জন্য এটি অকেজো।
কোন পরিস্থিতিতে এটি কোন অপারেশন ফিরে আসবে?
যখন কৌশল নির্ধারণ করে যে ক্রয়-বিক্রয় থেকে আয় হ্যান্ডলিং ফিগুলিকে কভার করতে পারে না, তখন এটি কোনও অপারেশনে ফিরে আসা উচিত নয়। যদিও পূর্ববর্তী বর্ণনা বারবার মূল্য প্রবণতা নির্ধারণের জন্য কৌশল ব্যবহার করে, এটি শুধুমাত্র বোঝার সুবিধার জন্য, এই PPO মডেলটি বাজারের পূর্বাভাস দেয় না, তবে শুধুমাত্র তিনটি ক্রিয়াকলাপের সম্ভাব্যতা প্রকাশ করে।
6. ডেটা অধিগ্রহণ এবং প্রশিক্ষণ
আগের নিবন্ধের মতো, ডেটা অধিগ্রহণের পদ্ধতি এবং বিন্যাস নিম্নরূপ, 2018/5/7 থেকে 2019/6/27 পর্যন্ত বিটফাইনেক্স এক্সচেঞ্জে BTC_USD ট্রেডিং পেয়ারের এক-ঘণ্টার সময়ের কে-লাইন:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
LSTM নেটওয়ার্ক ব্যবহারের কারণে, প্রশিক্ষণের সময়টি খুব দীর্ঘ, তাই আমি এটিকে একটি GPU সংস্করণে পরিবর্তন করেছি, যা প্রায় 3 গুণ দ্রুত।
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. প্রশিক্ষণের ফলাফল এবং বিশ্লেষণ
দীর্ঘ অপেক্ষার পর:

প্রথমে, প্রশিক্ষণ তথ্যের বাজারের প্রবণতাগুলি একবার দেখে নেওয়া যাক। সাধারণভাবে বলতে গেলে, প্রথমার্ধে দীর্ঘ পতন ছিল এবং দ্বিতীয়ার্ধে একটি শক্তিশালী প্রত্যাবর্তন ছিল।
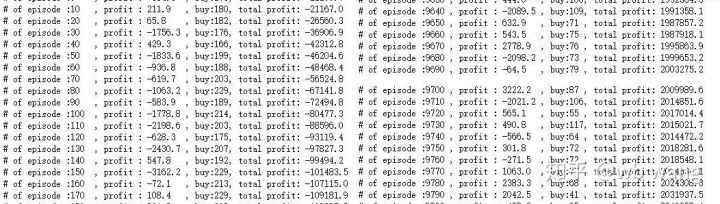
প্রশিক্ষণের প্রাথমিক পর্যায়ে অনেক ক্রয় অপারেশন আছে, এবং মূলত কোন লাভজনক রাউন্ড নেই। প্রশিক্ষণের মাঝামাঝি সময়ে, ক্রয় কার্যক্রম ধীরে ধীরে হ্রাস পায়, এবং লাভের সম্ভাবনা বৃহত্তর এবং বৃহত্তর হয়ে ওঠে, তবে এখনও ক্ষতির উচ্চ সম্ভাবনা রয়েছে।
প্রতি রাউন্ড আয় মসৃণ করা, ফলাফল নিম্নরূপ:
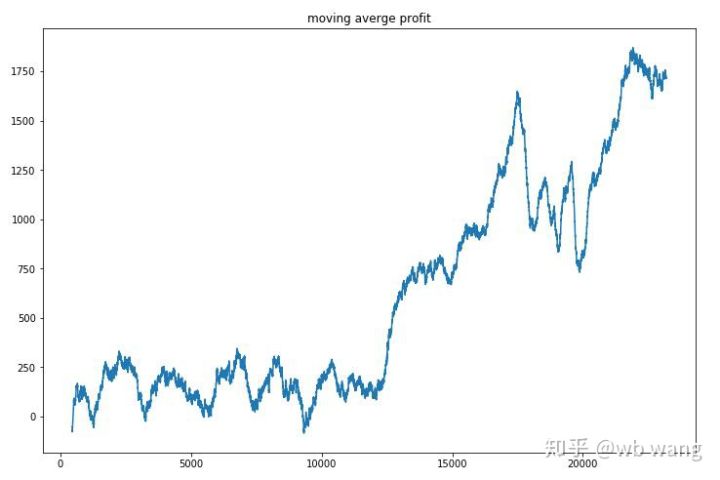
কৌশলটি দ্রুত নেতিবাচক প্রত্যাবর্তন থেকে মুক্তি পেয়েছিল, তবে এটি 10,000 রাউন্ডের মধ্যে খুব দ্রুতগতিতে বৃদ্ধি পায়নি, মডেল প্রশিক্ষণটি খুব কঠিন ছিল।
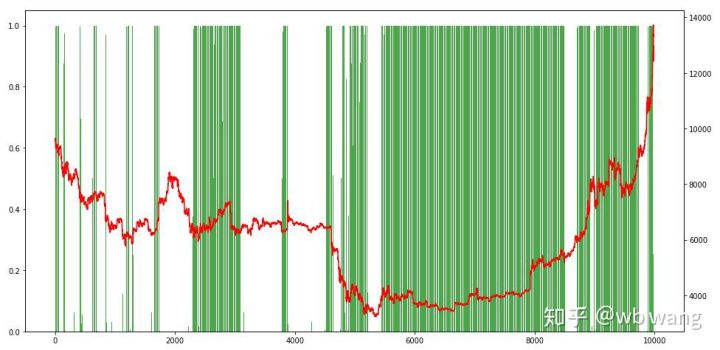
চূড়ান্ত প্রশিক্ষণের পরে, এই সময়ের মধ্যে এটি কীভাবে কাজ করেছে তা দেখতে মডেলটিকে আবার দেখতে দিন, অ্যাকাউন্টের মোট বাজার মূল্য, বিটকয়েনের সংখ্যা, বিটকয়েনের মূল্যের অনুপাত এবং মোট আয় রেকর্ড করা হয়েছে। .
প্রথমটি হল মোট বাজার মূল্য এর সাথে সমান, তাই আমি এটি এখানে পোস্ট করব না:
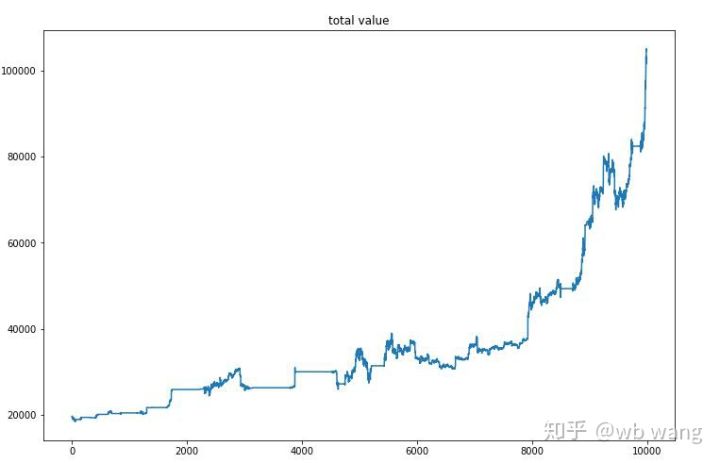
মোট বাজার মূলধন প্রাথমিক বিয়ার বাজারের সময় ধীরে ধীরে বৃদ্ধি পায় এবং পরবর্তী ষাঁড়ের বাজারের সময় বৃদ্ধির সাথে তা বজায় থাকে, কিন্তু পর্যায়ক্রমিক ক্ষতি এখনও ঘটে।
পরিশেষে, গ্রাফের বাম অক্ষ হল অবস্থানের অনুপাত, এবং এটি প্রাথমিকভাবে বিচার করা যেতে পারে যে মডেলটি প্রারম্ভিক বিয়ার মার্কেটে ওভারফিট করা হয়েছে পজিশন কম ছিল, এবং মার্কেটের নীচে, পজিশনের ফ্রিকোয়েন্সি বেশি ছিল। আপনি আরও দেখতে পারেন যে মডেলটি দীর্ঘ সময়ের জন্য অবস্থান ধরে রাখতে শেখেনি এবং সর্বদা দ্রুত বিক্রি হয়।
8. পরীক্ষা তথ্য বিশ্লেষণ
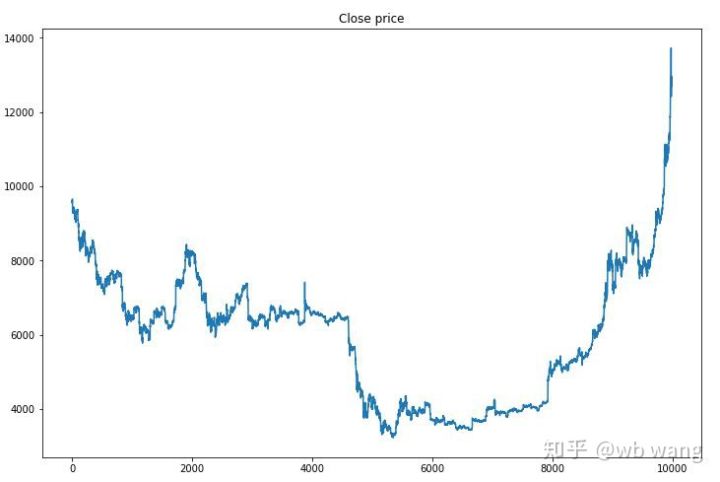
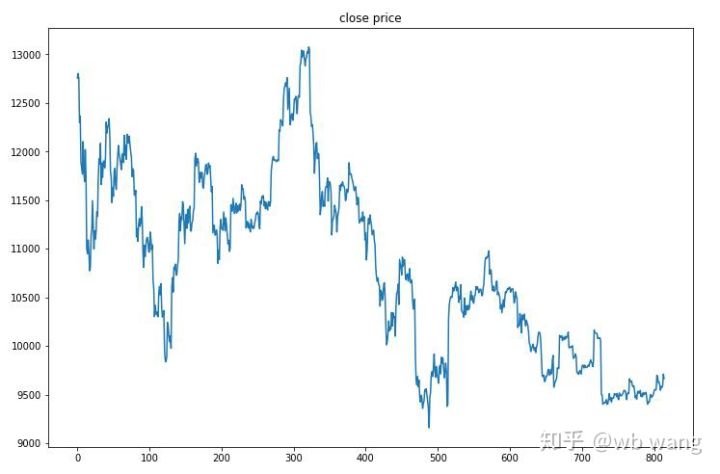
পরীক্ষার ডেটা 2019/6/27 থেকে বর্তমান পর্যন্ত এক ঘন্টার বিটকয়েনের বাজার মূল্য থেকে প্রাপ্ত করা হয়েছে। ছবিতে দেখা যায়, দামটি প্রাথমিক US\(13,000 থেকে নেমে US\)9,000-এর বেশি হয়েছে, যা মডেলটির জন্য একটি দুর্দান্ত পরীক্ষা বলা যেতে পারে।
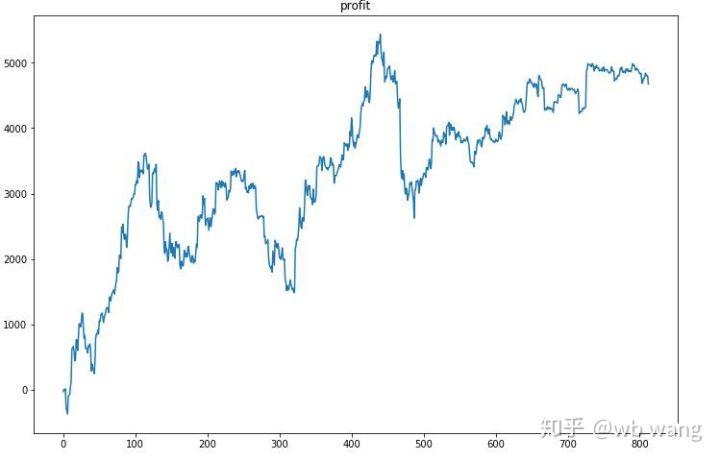
প্রথমত, চূড়ান্ত আপেক্ষিক আয় কর্মক্ষমতা অসন্তোষজনক ছিল, কিন্তু কোন ক্ষতি ছিল না.
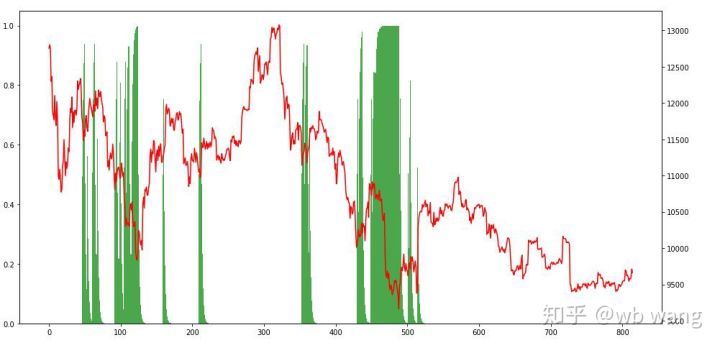
অবস্থানের অবস্থা দেখে, আমরা অনুমান করতে পারি যে মডেলটি একটি তীক্ষ্ণ পতনের পরে কেনার এবং তারপরে বিক্রি করার প্রবণতা সাম্প্রতিক সময়ে, বিটকয়েন বাজারটি খুব অস্থির হয়েছে এবং মডেলটি একটি সংক্ষিপ্ত অবস্থানে রয়েছে।
9. সারাংশ
এই নিবন্ধটি একটি বিটকয়েন স্বয়ংক্রিয় ট্রেডিং রোবট প্রশিক্ষণের জন্য গভীর শক্তিবৃদ্ধি শেখার পদ্ধতি PPO ব্যবহার করেছে এবং কিছু সিদ্ধান্তে এসেছে। সীমিত সময়ের কারণে, মডেলের উন্নতির জন্য এখনও কিছু ক্ষেত্র রয়েছে এবং প্রত্যেককে এটি আলোচনা করার জন্য স্বাগত জানাই। সবচেয়ে বড় শিক্ষা হল ডাটা স্ট্যান্ডার্ডাইজেশন হল সর্বোত্তম পদ্ধতি যেমন স্কেলিং ব্যবহার করবেন না, অন্যথায় মডেলটি দ্রুত মূল্য এবং বাজারের অবস্থার মধ্যে সম্পর্ক মনে রাখবে এবং ওভারফিটিংয়ে পড়বে। স্বাভাবিক পরিবর্তনের হার হল আপেক্ষিক ডেটা, যা মডেলের জন্য বাজারের সাথে সম্পর্ক মনে রাখা কঠিন করে তোলে এবং পরিবর্তনের হার এবং উত্থান-পতনের মধ্যে সংযোগ খুঁজে পেতে বাধ্য হয়।
পূর্ববর্তী নিবন্ধগুলির ভূমিকা: FMZ উদ্ভাবক পরিমাণগত প্ল্যাটফর্মে কিছু পাবলিক কৌশল ভাগ করা: https://zhuanlan.zhihu.com/p/64961672 NetEase ক্লাউড ক্লাসরুমের ডিজিটাল মুদ্রা পরিমাণগত ট্রেডিং কোর্সের জন্য শুধুমাত্র 20 ইউয়ান খরচ হয়: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000606027 আমি একটি উচ্চ-ফ্রিকোয়েন্সি কৌশল প্রকাশ করেছি যা খুব লাভজনক ছিল: https://www.fmz.com/bbs-topic/1211