বাজার কোট সংগ্রহকারী আবার আপগ্রেড
লেখক:ভাল, তৈরিঃ 2020-05-26 14:25:15, আপডেটঃ 2024-12-10 20:35:48
কাস্টম ডেটা উৎস প্রদানের জন্য CSV ফরম্যাটে ফাইল আমদানি সমর্থন
সাম্প্রতিককালে, একজন ব্যবসায়ীর FMZ প্ল্যাটফর্ম ব্যাকটেস্ট সিস্টেমের জন্য ডেটা উত্স হিসাবে তার নিজস্ব CSV ফর্ম্যাট ফাইল ব্যবহার করা দরকার। আমাদের প্ল্যাটফর্মের ব্যাকটেস্ট সিস্টেমের অনেকগুলি ফাংশন রয়েছে এবং এটি ব্যবহার করা সহজ এবং দক্ষ, যাতে যতক্ষণ ব্যবহারকারীদের নিজস্ব ডেটা থাকে ততক্ষণ তারা এই ডেটা অনুসারে ব্যাকটেস্টিং করতে পারে, যা এখন আমাদের প্ল্যাটফর্ম ডেটা সেন্টার দ্বারা সমর্থিত এক্সচেঞ্জ এবং জাতগুলিতে সীমাবদ্ধ নয়।
ডিজাইন আইডিয়া
নকশা ধারণা আসলে খুব সহজ. আমরা শুধুমাত্র পূর্ববর্তী বাজার সংগ্রাহক উপর ভিত্তি করে এটি সামান্য পরিবর্তন করতে হবে. আমরা একটি পরামিতি যোগisOnlySupportCSVব্যাকটেস্ট সিস্টেমের জন্য শুধুমাত্র সিএসভি ফাইলটি ডেটা উৎস হিসেবে ব্যবহার করা হয় কিনা তা নিয়ন্ত্রণ করার জন্য বাজারের সংগ্রহকারীকে।filePathForCSVএটি সার্ভারে স্থাপন করা CSV ডেটা ফাইলের পথ সেট করতে ব্যবহৃত হয় যেখানে মার্কেট কালেক্টর রোবট চালানো হয়।isOnlySupportCSVপ্যারামিটার সেট করা আছেTrueকোন ডাটা উৎস ব্যবহার করতে হবে তা নির্ধারণ করতে (আপনি নিজে সংগ্রহ করেছেন অথবা CSV ফাইলের ডাটা), এই পরিবর্তন প্রধানতdo_GETকার্যকারিতাProvider class.
সিএসভি ফাইল কি?
কমা-বিভক্ত মান, যা সিএসভি নামেও পরিচিত, কখনও কখনও অক্ষর-বিভক্ত মান হিসাবে উল্লেখ করা হয়, কারণ বিভাজক অক্ষরটিও একটি কমা হতে পারে না। এর ফাইলটি টেবিলের ডেটা (সংখ্যা এবং পাঠ্য) সরল পাঠ্যে সঞ্চয় করে। সরল পাঠ্যের অর্থ হল যে ফাইলটি অক্ষরের ক্রম এবং এতে বাইনারি সংখ্যার মতো ব্যাখ্যা করা দরকার এমন কোনও ডেটা নেই। সিএসভি ফাইলটিতে যে কোনও সংখ্যক রেকর্ড রয়েছে, কিছু নতুন লাইন অক্ষর দ্বারা পৃথক করা হয়েছে; প্রতিটি রেকর্ড ক্ষেত্রের সমন্বয়ে গঠিত, এবং ক্ষেত্রগুলির মধ্যে বিভাজক অন্যান্য অক্ষর বা স্ট্রিং, এবং সর্বাধিক সাধারণ কমা বা ট্যাব। সাধারণভাবে, সমস্ত রেকর্ডের ক্ষেত্রের সঠিক একই ক্রম রয়েছে। এগুলি সাধারণত সরল পাঠ্য ফাইল। এটি ব্যবহার করার পরামর্শ দেওয়া হয়WORDPADঅথবাExcelখুলতে।
সিএসভি ফাইল ফর্ম্যাটের সাধারণ মান বিদ্যমান নেই, তবে কিছু নিয়ম রয়েছে, সাধারণত প্রতি লাইনে একটি রেকর্ড, এবং প্রথম লাইনটি হেডার। প্রতিটি লাইনের ডেটা কমা দ্বারা পৃথক করা হয়।
উদাহরণস্বরূপ, আমরা পরীক্ষার জন্য যে CSV ফাইলটি ব্যবহার করেছি তা নোটপ্যাড দিয়ে এভাবে খোলা হয়ঃ
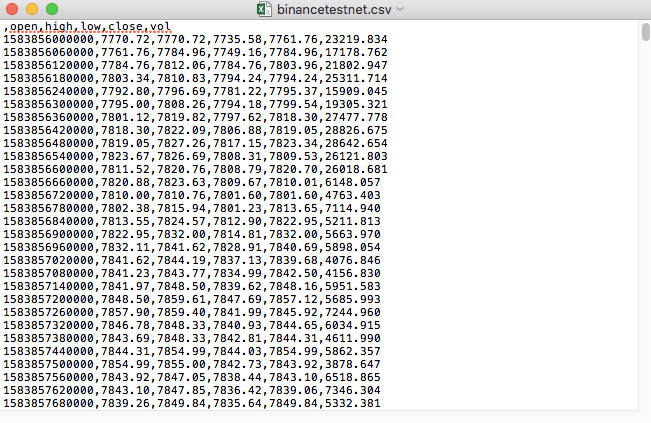
লক্ষ্য করুন যে CSV ফাইলের প্রথম লাইন হল টেবিল হেডার।
,open,high,low,close,vol
আমাদের শুধু এই ডেটা বিশ্লেষণ এবং সাজানোর প্রয়োজন, এবং তারপর ব্যাকটেস্ট সিস্টেমের কাস্টম ডেটা উত্স দ্বারা প্রয়োজনীয় ফরম্যাটে এটি তৈরি করুন। আমাদের পূর্ববর্তী নিবন্ধে এই কোডটি ইতিমধ্যে প্রক্রিয়া করা হয়েছে, এবং শুধুমাত্র সামান্য সংশোধন করা প্রয়োজন।
সংশোধিত কোড
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
রান টেস্ট
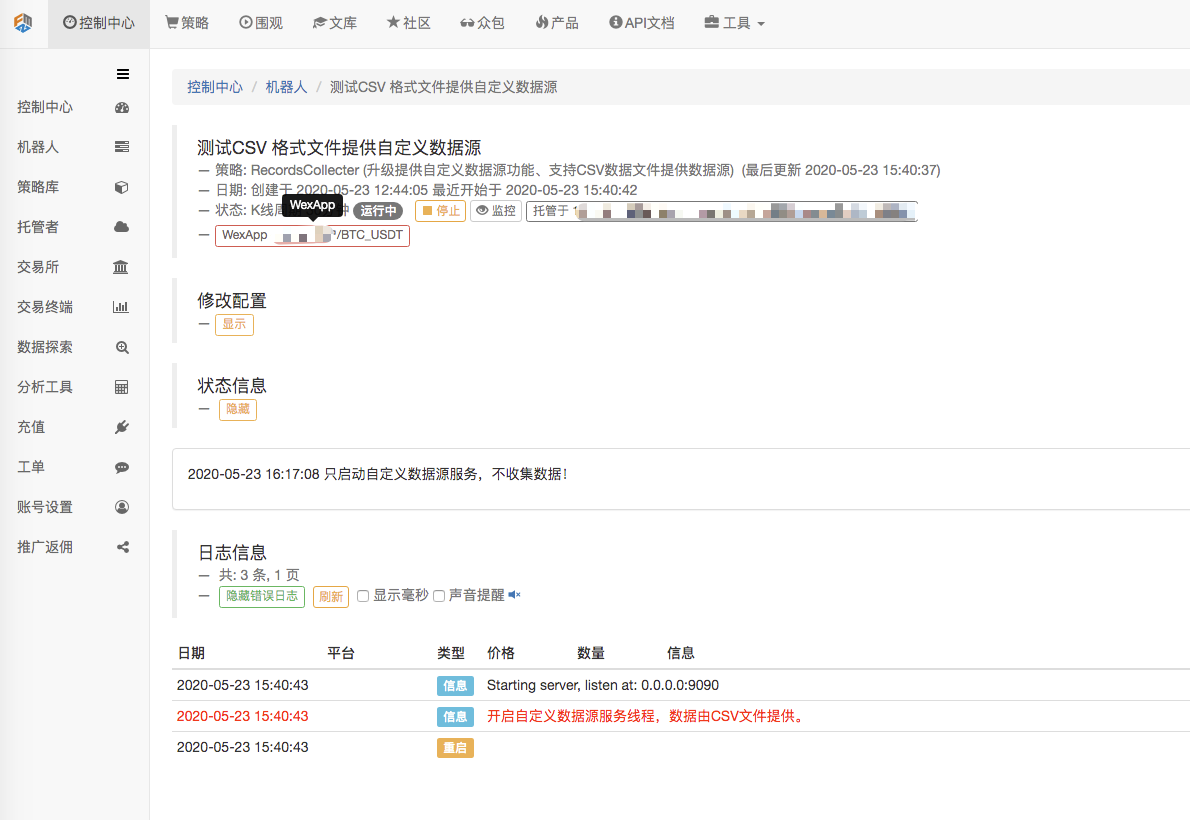
প্রথমে, আমরা মার্কেট কালেক্টর রোবট চালু করি। আমরা রোবটে একটি এক্সচেঞ্জ যোগ করি এবং রোবটকে চালাতে দিই।
প্যারামিটার কনফিগারেশনঃ

তারপর আমরা একটি টেস্ট কৌশল তৈরি করি:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
কৌশলটি খুবই সহজ, কেবলমাত্র তিনবার K-লাইন ডেটা সংগ্রহ এবং মুদ্রণ করুন।
ব্যাকটেস্ট পৃষ্ঠায়, ব্যাকটেস্ট সিস্টেমের ডেটা উত্সকে একটি কাস্টম ডেটা উত্স হিসাবে সেট করুন, এবং সার্ভারের ঠিকানা পূরণ করুন যেখানে মার্কেট কালেক্টর রোবট চালানো হয়। যেহেতু আমাদের সিএসভি ফাইলের ডেটা 1 মিনিটের কে লাইন। সুতরাং ব্যাকটেস্ট করার সময়, আমরা কে-লাইন সময়কাল 1 মিনিটে সেট করি।
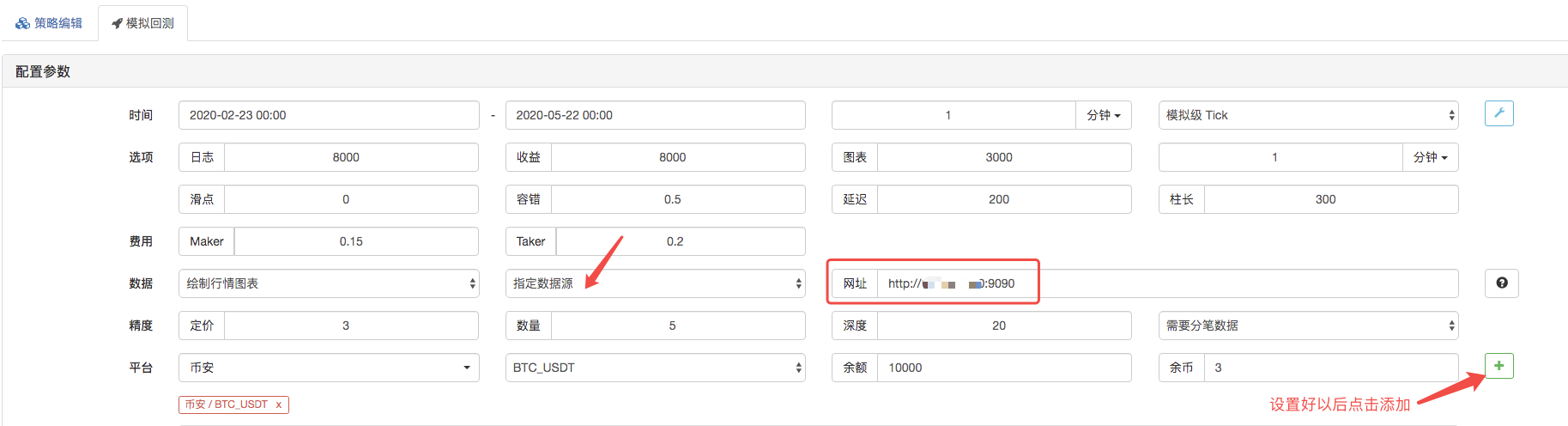
ব্যাকটেস্ট শুরু করতে ক্লিক করুন, এবং মার্কেট কালেক্টর রোবট ডাটা অনুরোধ গ্রহণ করেঃ

ব্যাকটেস্ট সিস্টেমের এক্সিকিউশন কৌশল সম্পন্ন হওয়ার পর, ডাটা সোর্সে K-লাইন ডেটার উপর ভিত্তি করে একটি K-লাইন চার্ট তৈরি করা হয়।
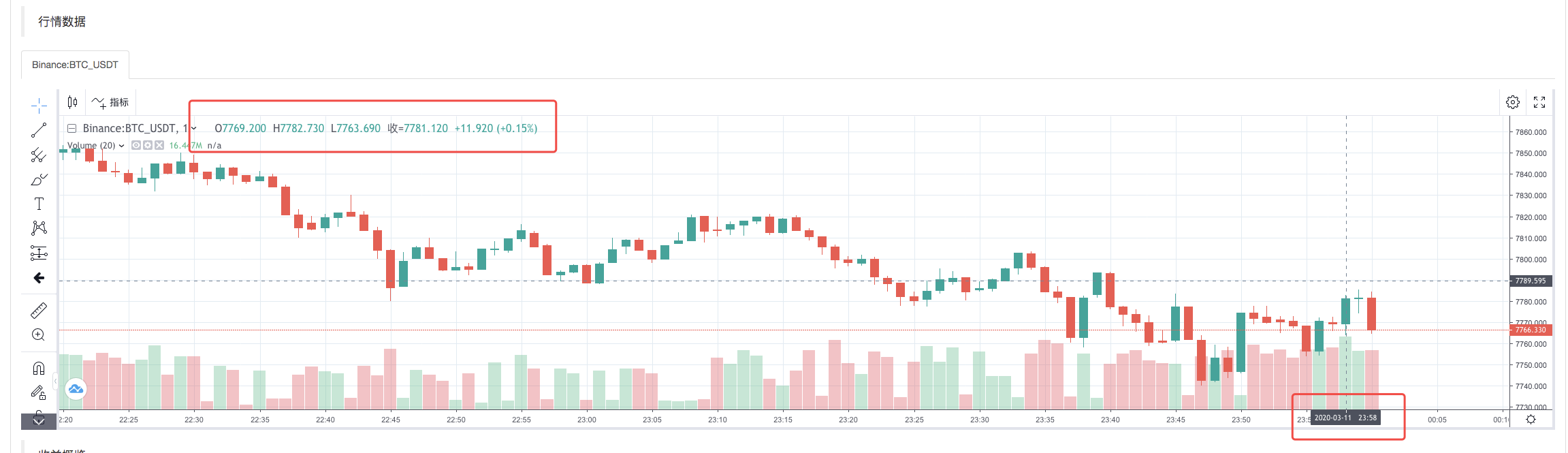
ফাইলের ডাটা তুলনা করুনঃ

- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (3)
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (2)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (২)
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণ নিয়ে আলোচনাঃ কৌশলগতভাবে অন্তর্নির্মিত এইচটিটিপি পরিষেবা সহ সংকেত গ্রহণের জন্য একটি সম্পূর্ণ সমাধান
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ কৌশলগুলি অন্তর্নির্মিত এইচটিটিপি পরিষেবাগুলির সংকেত গ্রহণের সম্পূর্ণ সমাধান
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (1)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণের বিষয়ে আলোচনাঃ বর্ধিত এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ এক্সটেনশান এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- র্যান্ডম টিকার জেনারেটরের উপর ভিত্তি করে কৌশল পরীক্ষার পদ্ধতি নিয়ে আলোচনা
- র্যান্ডম মার্কেট জেনারেটরের উপর ভিত্তি করে কৌশলগত পরীক্ষার পদ্ধতিগুলি অনুসন্ধান করুন
- ক্রিপ্টোকারেন্সি ফিউচার ট্রেডিং এর যুক্তি সম্পর্কে কিছু চিন্তাভাবনা
- আলফা১০১ ব্যাকরণ বিকাশের উপর ভিত্তি করে উন্নত বিশ্লেষণ সরঞ্জাম
- আপনি বাজার সংগ্রাহক আপগ্রেড শেখান ব্যাকটেস্ট কাস্টম তথ্য উৎস
- উচ্চ-ফ্রিকোয়েন্সি পুনরাবৃত্তি সিস্টেম এবং কে-লাইন পুনরাবৃত্তির ত্রুটিগুলি
- এফএমজেড সিমুলেশন স্তরের ব্যাকটেস্ট প্রক্রিয়া ব্যাখ্যা
- লিনাক্স ভিপিএসে এফএমজেড ডকার ইনস্টল এবং আপগ্রেড করার সর্বোত্তম উপায়
- কমোডিটি ফিউচার R-Breaker কৌশল
- ডিজিটাল মুদ্রার ফিউচার ট্রেডিংয়ের যুক্তি সম্পর্কে একটু চিন্তা করুন
- আপনাকে শেখান কিভাবে একটি বাজার কোট সংগ্রহকারী বাস্তবায়ন
- পাইথন সংস্করণ কমোডিটি ফিউচার মুভিং গড় কৌশল
- ঘটনা সংগ্রাহক পুনরায় আপগ্রেড - কাস্টম ডেটা উত্স সরবরাহ করতে CSV ফর্ম্যাট ফাইল আমদানি সমর্থন
- কমোডিটি ফিউচার হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল C++ দ্বারা লিখিত
- ল্যারি কনরস আরএসআই ২-এর অর্থ বিপরীতমুখী কৌশল
- ওক হ্যান্ডশেক আপনাকে JS এর সাথে FMZ এক্সটেনশন এপিআই জুড়তে শেখায়
- ইনট্রা ডে কৌশলগুলিতে একটি নতুন আপেক্ষিক শক্তি সূচক ব্যবহারের ভিত্তিতে
- বাইনারেন্স ফিউচার মাল্টি-ভারেন্সি হেজিং স্ট্র্যাটেজি পার্ট 4 এর উপর গবেষণা
- ল্যারি Connors ল্যারি Connors RSI2 গড় মূল্য প্রত্যাবর্তন কৌশল
- বাইনারেন্স ফিউচার মাল্টি-কার্উয়েন্সি হেজিং স্ট্র্যাটেজি পার্ট ৩ নিয়ে গবেষণা
- বাইনারেন্স ফিউচার মাল্টি-কার্উয়েন্সি হেজিং স্ট্র্যাটেজি পার্ট ২ নিয়ে গবেষণা
- বাইনারেন্স ফিউচার মাল্টি-ভারেন্সি হেজিং স্ট্র্যাটেজি পার্ট 1 এর উপর গবেষণা