Erste Erforschung der Anwendung von Python Crawler auf FMZ Crawling Binance Ankündigungsinhalt
Schriftsteller:- Ich bin ein Idiot., Erstellt: 2022-04-08 15:47:43, Aktualisiert: 2022-04-13 10:07:13Erste Erforschung der Anwendung von Python Crawler auf FMZ Crawling Binance Ankündigungsinhalt
Vor kurzem habe ich durch unsere Foren und Digest gesucht, und es gibt keine relevanten Informationen über Python-Crawler. Basierend auf dem FMZ-Geist der umfassenden Entwicklung ging ich einfach, um über die Konzepte und das Wissen von Crawler zu lernen. Nachdem ich darüber gelernt hatte, fand ich heraus, dass es noch mehr über
Nachfrage
Für Händler, die den Börsengang mögen, möchten sie immer so schnell wie möglich die Plattform-Listing-Informationen erhalten. Es ist offensichtlich unrealistisch, die ganze Zeit manuell auf eine Plattform-Website zu starren. Dann müssen Sie das Crawler-Skript verwenden, um die Ankündigungsseite der Plattform zu überwachen und neue Ankündigungen zu erkennen, um beim ersten Mal benachrichtigt und erinnert zu werden.
Erste Erkundungen
Verwenden Sie ein sehr einfaches Programm als Start (wirklich leistungsstarke Crawler-Skripte sind viel komplexer, also nehmen Sie sich Zeit). Die Programmlogik ist sehr einfach, das heißt, lassen Sie das Programm kontinuierlich die Ankündigungsseite einer Plattform besuchen, den erworbenen HTML-Inhalt analysieren und erkennen, ob der Inhalt eines angegebenen Labels aktualisiert wird.
Umsetzung des Codes
Da die Anforderung sehr einfach ist, können Sie auch direkt schreiben.
Die zu verwendenden Python-Bibliotheken:
```bs4```, which can be simply regarded as the library used to parse the HTML code of web pages.
Code:
aus bs4 importieren BeautifulSoup Einfuhranträge
UrlBinanceAnkündigung =
Definition von offen Url:
Überschriften = {
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
Definition der Haupt*:
PreNews_href =
”`
Betrieb
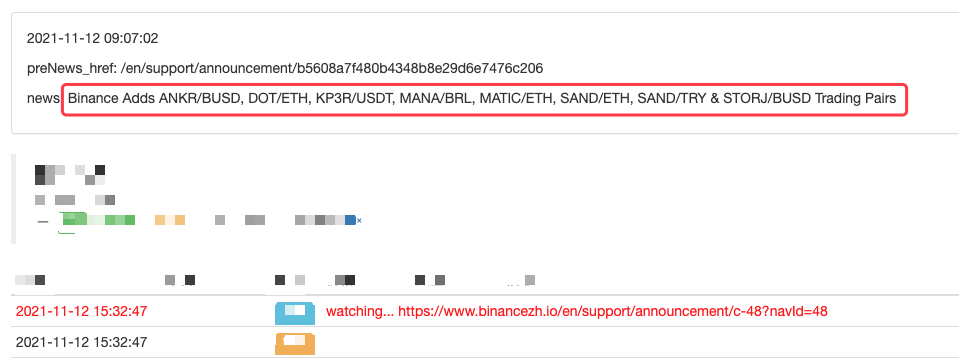
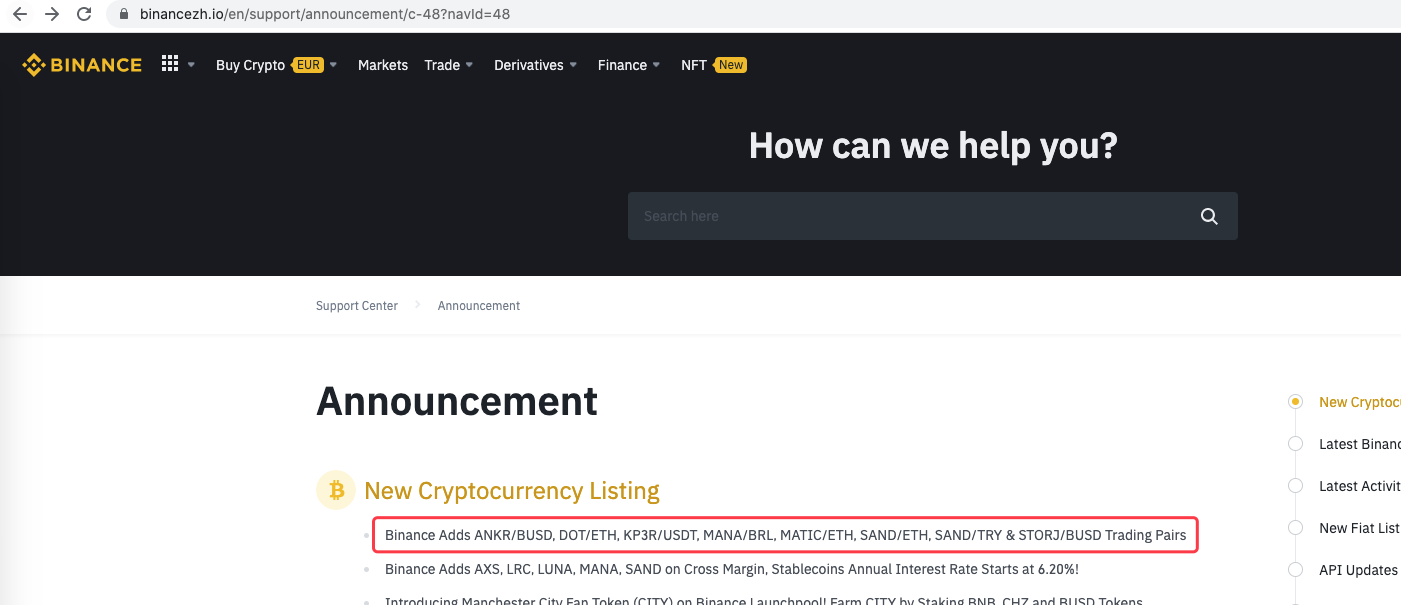
Sie können es sogar erweitern, wie zum Beispiel die Erkennung neuer Ankündigungen, die Analyse von neu gelisteten Währungssymbolen und die automatische Bestellung von Börsengängen.
- Verzichten Sie auf das Drucken eines Logs
- Löschen Sie alle noch ausstehenden Bestellungen in aktuellen Währungen
- Schnelle Einführung der FMZ Quant Trading Platform APP
- Realisieren Sie einen einfachen Auftragsüberwachungsbot von Cryptocurrency Spot
- Eine Plattform, die auf FMZ basiert.
- Kryptowährungs-Kontrakt einfacher Auftragsüberwachungsbot
- Wenn Sie mit getdepth die entsprechende Zeitschrift erhalten möchten
- Ignoriert, gelöst
- Die Frage nach dem Gesichtswert
- dYdX-Strategie-Entwurfsbeispiel
- Hedge-Strategie-Design-Forschung & Beispiel für offene Spot- und Futures-Orders
- Aktuelle Situation und empfohlene Anwendung der Finanzierungsrate-Strategie
- Strategie für einen doppelten gleitenden Durchschnitts-Brechpunkt von Kryptowährungs-Futures (Teaching)
- Strategie für einen doppelten gleitenden Durchschnitt mit mehreren Symbolen (Teaching)
- Realisierung von Fisher Indicator in JavaScript und Plotting auf FMZ
- Treuhänder
- 2021 Kryptowährungs-TAQ-Überprüfung & Einfachste verpasste Strategie der 10-fachen Erhöhung
- Kryptowährungs-Futures Multi-Symbol ART-Strategie (Lehre)
- Aktualisieren! Kryptowährungs Futures Martingale Strategie
- Die Getrecords-Funktion kann keine K-Stringkarte in Sekunden erhalten