Erstellen Sie einen Bitcoin-Handelsbot, der niemals Geld verliert
 0
5331
0
5331

Lassen Sie uns Verstärkungslernen in der künstlichen Intelligenz nutzen, um einen Kryptowährungs-Handelsroboter zu erstellen
In diesem Artikel erstellen und wenden wir ein Framework für bestärkendes Lernen an, um zu lernen, wie man einen Bitcoin-Handelsbot erstellt. In diesem Tutorial verwenden wir das Gym von OpenAI und den PPO-Roboter aus der Stable-Baselines-Bibliothek, die ein Fork der OpenAI-Baselines-Bibliothek ist.
Vielen Dank an OpenAI und DeepMind für die Bereitstellung von Open-Source-Software für Deep-Learning-Forscher in den letzten Jahren. Wenn Sie die erstaunlichen Erfolge, die sie mit Technologien wie AlphaGo, OpenAI Five und AlphaStar erzielt haben, noch nicht gesehen haben, haben Sie das letzte Jahr möglicherweise isoliert gelebt. Aber Sie sollten einen Blick darauf werfen.
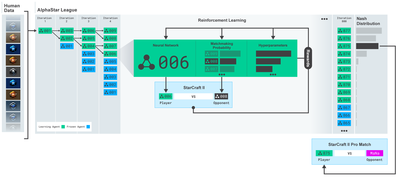
AlphaStar-Training https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Auch wenn wir nichts Beeindruckendes erschaffen, ist der Bitcoin-Roboterhandel im alltäglichen Handel dennoch keine leichte Aufgabe. Doch wie Teddy Roosevelt einmal sagte:
Dinge, die zu leicht kommen, sind wertlos.
Lernen Sie also nicht nur, selbst zu handeln, sondern lassen Sie auch die Roboter für uns handeln.
planen

Erstellen Sie eine Fitnessumgebung für unseren Roboter, um maschinelles Lernen durchzuführen
Rendern Sie eine einfache und elegante Visualisierungsumgebung
Trainieren Sie unseren Roboter, um eine profitable Handelsstrategie zu erlernen
Wenn Sie noch nicht wissen, wie Sie Fitnessstudioumgebungen von Grund auf erstellen oder wie Sie einfach Visualisierungen dieser Umgebungen rendern. Sie können gerne nach einem solchen Artikel googeln, bevor Sie fortfahren. Diese beiden Aktionen werden selbst für die unerfahrensten Programmierer kein Problem sein.
Erste Schritte
In diesem Tutorial verwenden wir den von Zielak generierten Kaggle-Datensatz. Wenn Sie den Quellcode herunterladen möchten, ist er zusammen mit der CSV-Datendatei in meinem Github-Repository verfügbar. Okay, fangen wir an.
Importieren wir zunächst alle erforderlichen Bibliotheken. Stellen Sie sicher, dass Sie alle fehlenden Bibliotheken mit pip installieren.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Als nächstes erstellen wir unsere Klasse für die Umgebung. Wir müssen einen Pandas-Datenrahmen sowie einen optionalen Initial_Balance- und Lookback_Window_Size-Wert übergeben, der bestimmt, wie viele vergangene Zeitschritte der Roboter bei jedem Schritt beobachtet. Wir setzen die Provision pro Handel standardmäßig auf 0,075 %, den aktuellen Satz bei Bitmex, und den Serienparameter standardmäßig auf „false“, was bedeutet, dass unser Datenrahmen standardmäßig in zufälligen Teilen durchlaufen wird.
Wir rufen auch dropna() und reset_index() für die Daten auf, um zuerst die Zeilen mit NaN-Werten zu entfernen und dann den Index für die Frame-Nummer zurückzusetzen, da wir Daten gelöscht haben.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Unser Aktionsbereich wird hier als ein Satz von 3 Optionen (Kaufen, Verkaufen oder Halten) und ein weiterer Satz von 10 Beträgen (1⁄10, 2⁄10, 3⁄10 usw.) dargestellt. Wenn wir uns für die Kaufaktion entscheiden, kaufen wir den Betrag * den Eigenbestand an BTC. Zum Verkauf verkaufen wir den Betrag * den Wert von self.btc_held in BTC. Natürlich ignoriert die Hold-Aktion den Betrag und bewirkt nichts.
Unser Beobachtungsraum wird als eine Menge kontinuierlicher Gleitkommazahlen zwischen 0 und 1 mit der Form (10, Größe des Rückblickfensters + 1) definiert. + 1 wird verwendet, um den aktuellen Zeitschritt zu berechnen. Für jeden Zeitschritt im Fenster beobachten wir den OHCLV-Wert. Unser Nettovermögen entspricht der Menge der gekauften oder verkauften BTC und der Gesamtsumme an USD, die wir für diese BTC ausgegeben oder erhalten haben.
Als Nächstes müssen wir die Reset-Methode schreiben, um die Umgebung zu initialisieren.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Hier verwenden wir self._reset_session und selbst._next_observation, wir haben sie noch nicht definiert. Lassen Sie uns sie zunächst definieren.
Handelssitzung
Ein wichtiger Teil unserer Umgebung ist das Konzept einer Handelssitzung. Wenn wir diesen Bot außerhalb des Marktes einsetzen würden, würden wir ihn wahrscheinlich nie länger als ein paar Monate am Stück laufen lassen. Aus diesem Grund begrenzen wir die Anzahl aufeinanderfolgender Frames in self.df, d. h. die Anzahl der Frames, die unser Roboter gleichzeitig sehen kann.
In unserer Methode _reset_session setzen wir zuerst den current_step auf 0 zurück. Als nächstes setzen wir steps_left auf eine Zufallszahl zwischen 1 und MAX_TRADING_SESSION, die wir oben im Programm definieren.
MAX_TRADING_SESSION = 100000 # ~2个月
Wenn wir als nächstes kontinuierlich über die Frames iterieren möchten, müssen wir es so einstellen, dass es über den gesamten Frame iteriert, andernfalls setzen wir frame_start auf einen zufälligen Punkt in self.df und erstellen einen neuen Datenrahmen namens active_df, der einfach self ist. Ein Slice von df von Frame_Start bis Frame_Start + Schritte_links.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Ein wichtiger Nebeneffekt der Iteration über die Anzahl der Datenrahmen beim zufälligen Aufteilen besteht darin, dass unserem Roboter beim Training über einen längeren Zeitraum mehr einzigartige Daten zur Verfügung stehen. Wenn wir beispielsweise einfach die Anzahl der Datenrahmen seriell durchlaufen würden (d. h. in der Reihenfolge von 0 bis len(df)), hätten wir nur so viele eindeutige Datenpunkte, wie in der Anzahl der Datenrahmen enthalten sind. Unser Beobachtungsraum kann sogar zu jedem Zeitpunkt nur eine diskrete Anzahl von Zuständen annehmen.
Durch zufälliges Iterieren über Ausschnitte des Datensatzes können wir jedoch einen aussagekräftigeren Satz an Handelsergebnissen für jeden Zeitschritt im ursprünglichen Datensatz erstellen, d. h. eine Kombination aus Handelsaktionen und zuvor beobachteten Preisaktionen, um einen einzigartigeren Datensatz zu erstellen. Lassen Sie mich dies anhand eines Beispiels erklären.
Bei einem Zeitschritt von 10 nach dem Zurücksetzen der seriellen Umgebung wird unser Roboter immer gleichzeitig innerhalb des Datensatzes ausgeführt und hat nach jedem Zeitschritt 3 Auswahlmöglichkeiten: Kaufen, Verkaufen oder Halten. Zu jeder dieser drei Möglichkeiten gibt es noch eine weitere Option: 10%, 20%, … oder 100% des konkreten Umsetzungsbetrages. Dies bedeutet, dass unser Roboter in eine der Situationen 103 hoch 10 geraten könnte, also insgesamt 1030.
Nun zurück zu unserer Umgebung für zufälliges Slicen. Bei einem Zeitschritt von 10 kann sich unser Roboter in jedem beliebigen len(df)-Zeitschritt innerhalb der Anzahl der Datenrahmen befinden. Unter der Annahme, dass nach jedem Zeitschritt die gleiche Wahl getroffen wird, bedeutet dies, dass der Roboter in denselben 10 Zeitschritten jeden einzelnen Zustand von len(df)30 durchlaufen kann.
Dies kann zwar bei großen Datensätzen zu erheblichem Rauschen führen, ich bin jedoch der Meinung, dass Roboter dadurch aus der begrenzten Datenmenge, die uns zur Verfügung steht, mehr lernen können. Wir werden unsere Testdaten weiterhin seriell durchgehen, um die aktuellsten, scheinbar „Echtzeit“-Daten zu erhalten und so ein genaueres Verständnis der Wirksamkeit des Algorithmus zu erlangen.
Durch die Augen eines Roboters
Um die Art der Funktionen zu verstehen, die unser Roboter verwenden wird, ist es oft hilfreich, einen guten visuellen Überblick über die Umgebung zu haben. Hier sehen Sie beispielsweise eine Visualisierung des mit OpenCV gerenderten sichtbaren Raums.

Beobachtung der OpenCV-Visualisierungsumgebung
Jede Zeile im Bild stellt eine Zeile in unserem Beobachtungsraum dar. Die ersten vier Zeilen mit ähnlicher Häufigkeit (rote Linien) stellen OHCL-Daten dar, und die orangefarbenen und gelben Punkte direkt darunter stellen das Volumen dar. Der schwankende blaue Balken unten ist das Eigenkapital des Bots, während die helleren Balken darunter die Trades des Bots darstellen.
Wenn Sie genau hinschauen, können Sie sogar Ihr eigenes Candlestick-Chart erstellen. Unter der Lautstärkeleiste befindet sich eine Morsecode-ähnliche Schnittstelle, die den Handelsverlauf anzeigt. Es sieht so aus, als ob unser Bot in der Lage sein sollte, ausreichend aus den Daten in unserem Beobachtungsraum zu lernen, also machen wir weiter. Hier definieren wir die Methode _next_observation, mit der wir die beobachteten Daten von 0 bis 1 skalieren.
- Es ist wichtig, nur die Daten zu erweitern, die der Roboter bisher beobachtet hat, um einen Lookahead-Bias zu vermeiden.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Werde aktiv
Nachdem wir nun unseren Beobachtungsraum eingerichtet haben, ist es an der Zeit, unsere Schrittfunktion zu schreiben und dann die Aktionen auszuführen, die der Roboter ausführen soll. Immer wenn self.steps_left == 0 für unsere aktuelle Handelssitzung ist, werden wir unsere BTC-Bestände verkaufen und reset session() aufrufen. Andernfalls setzen wir die Belohnung auf das aktuelle Eigenkapital oder setzen „Done“ auf „True“, wenn wir kein Geld mehr haben.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Um eine Handelsaktion durchzuführen, müssen Sie lediglich den aktuellen Preis ermitteln, die auszuführende Aktion und den Kauf- oder Verkaufsbetrag festlegen. Schreiben wir schnell _take_action, damit wir unsere Umgebung testen können.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Abschließend fügen wir mit derselben Methode den Handel an self.trades an und aktualisieren unser Eigenkapital und unseren Kontoverlauf.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Unser Roboter kann jetzt eine neue Umgebung starten, diese durchlaufen und Aktionen ausführen, die sich auf die Umgebung auswirken. Es ist Zeit, ihnen beim Handel zuzusehen.
Beobachten Sie unsere Roboter beim Handeln
Unsere Rendermethode könnte so einfach sein wie der Aufruf von print(self.net_worth), aber das wäre nicht interessant genug. Stattdessen zeichnen wir ein einfaches Candlestick-Chart mit einer Volumenleiste und einem separaten Chart für unser Eigenkapital.
Wir werden den Code in StockTradingGraph.py aus meinem vorherigen Artikel nehmen und ihn überarbeiten, damit er zur Bitcoin-Umgebung passt. Sie können den Code von meinem Github erhalten.
Die erste Änderung, die wir vornehmen werden, ist die Änderung von self.df[ ‘Datum’] Update auf self.df[„Zeitstempel“] und entfernen Sie alle Aufrufe von date2num, da unsere Daten bereits im Unix-Zeitstempelformat vorliegen. Als Nächstes aktualisieren wir in unserer Rendermethode die Datumsbeschriftung, um anstelle einer Zahl ein für Menschen lesbares Datum zu drucken.
from datetime import datetime
Zuerst importieren wir die Datetime-Bibliothek, dann verwenden wir die Methode utcfromtimestamp, um die UTC-Zeichenfolge aus jedem Zeitstempel abzurufen, und strftime, um daraus eine Zeichenfolge im Format Y-m-d H:M umzuwandeln.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Schließlich verwenden wir self.df[‘Volume’] wird in self.df geändert[‘Volume_(BTC)’], um es mit unserem Datensatz abzugleichen, und damit können wir loslegen. Zurück zu unserem BitcoinTradingEnv können wir jetzt die Rendermethode zum Anzeigen des Diagramms schreiben.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Sehen! Wir können jetzt zusehen, wie unser Roboter mit Bitcoins handelt.

Visualisierung der Trades unseres Roboters mit Matplotlib
Grüne Phantombeschriftungen stehen für den Kauf von BTC und rote Phantombeschriftungen für den Verkauf. Das weiße Etikett in der oberen rechten Ecke ist das aktuelle Nettovermögen des Roboters und das Etikett in der unteren rechten Ecke ist der aktuelle Preis von Bitcoin. Einfach und elegant. Jetzt ist es Zeit, unseren Bot zu trainieren und zu sehen, wie viel Geld wir verdienen können!
Trainingszeit
Zu meinem vorherigen Artikel wurde mir unter anderem die fehlende Kreuzvalidierung und die fehlende Aufteilung der Daten in Trainings- und Testsätze vorgeworfen. Der Zweck besteht darin, die Genauigkeit des endgültigen Modells anhand neuer, noch nie dagewesener Daten zu testen. Dies ist zwar nicht der Schwerpunkt dieses Artikels, aber es ist sicherlich wichtig. Da wir mit Zeitreihendaten arbeiten, haben wir bei der Kreuzvalidierung keine große Auswahl.
Eine gängige Form der Kreuzvalidierung wird beispielsweise als k-fach-Validierung bezeichnet. Dabei teilen Sie die Daten in k gleiche Gruppen auf, trennen eine der Gruppen als Testgruppe ab und verwenden die restlichen Daten als Trainingsgruppe. . Allerdings sind Zeitreihendaten stark zeitabhängig, was bedeutet, dass spätere Daten stark von früheren Daten abhängen. Daher wird K-Fold nicht funktionieren, da unser Roboter vor dem Handel aus zukünftigen Daten lernt, was ein unfairer Vorteil ist.
Die gleichen Mängel gelten auch für die meisten anderen Kreuzvalidierungsstrategien, wenn sie auf Zeitreihendaten angewendet werden. Daher müssen wir nur einen Teil der Gesamtzahl der Datenrahmen als Trainingssatz verwenden, beginnend vom Anfang der Rahmennummer bis zu einem beliebigen Index, und den Rest der Daten als Testsatz nutzen.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Da unsere Umgebung nur für die Verarbeitung eines einzelnen Datensatzes eingerichtet ist, erstellen wir als Nächstes zwei Umgebungen, eine für die Trainingsdaten und eine für die Testdaten.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Jetzt ist das Trainieren unseres Modells so einfach wie das Erstellen eines Roboters mit unserer Umgebung und das Aufrufen von model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Hier verwenden wir Tensorboard, damit wir unser Tensorflow-Diagramm einfach visualisieren und einige quantitative Messwerte zu unserem Roboter sehen können. Hier ist beispielsweise eine Darstellung der reduzierten Belohnungen für viele Roboter über 200.000 Zeitschritte:
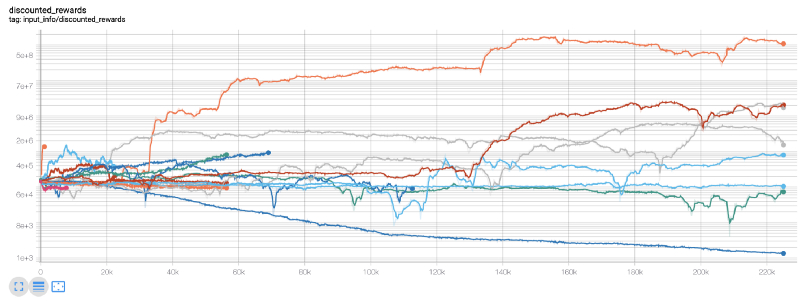
Wow, es sieht so aus, als wäre unser Bot ziemlich profitabel! Unser bester Roboter konnte im Laufe von 200.000 Schritten sogar ein 1000-mal besseres Gleichgewicht erreichen, und bei den anderen war die Verbesserung im Durchschnitt mindestens 30-mal so hoch!
An diesem Punkt ist mir aufgefallen, dass es einen Fehler in der Umgebung gab … Nachdem ich ihn behoben hatte, ist hier die neue Belohnungskarte:
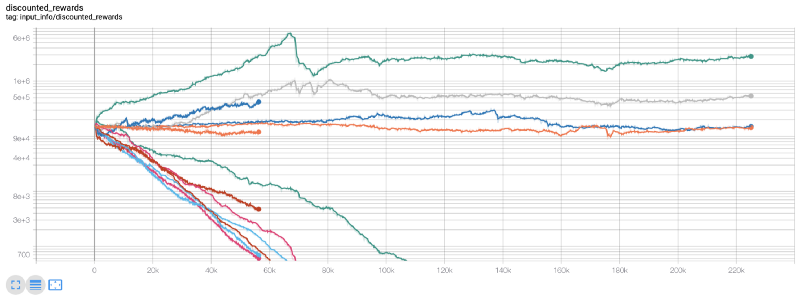
Wie Sie sehen, haben einige unserer Roboter großartige Arbeit geleistet, der Rest ist von selbst bankrott gegangen. Ein Bot mit guter Leistung kann jedoch das 10- oder sogar 60-fache des ursprünglichen Guthabens erreichen. Ich muss zugeben, dass alle profitablen Bots ohne Provisionen trainiert und getestet werden, daher ist es unrealistisch, dass unsere Bots echtes Geld verdienen. Aber zumindest haben wir die Richtung gefunden!
Lassen Sie uns unsere Bots in einer Testumgebung testen (mit neuen Daten, die sie noch nie zuvor gesehen haben) und sehen, wie sie funktionieren.
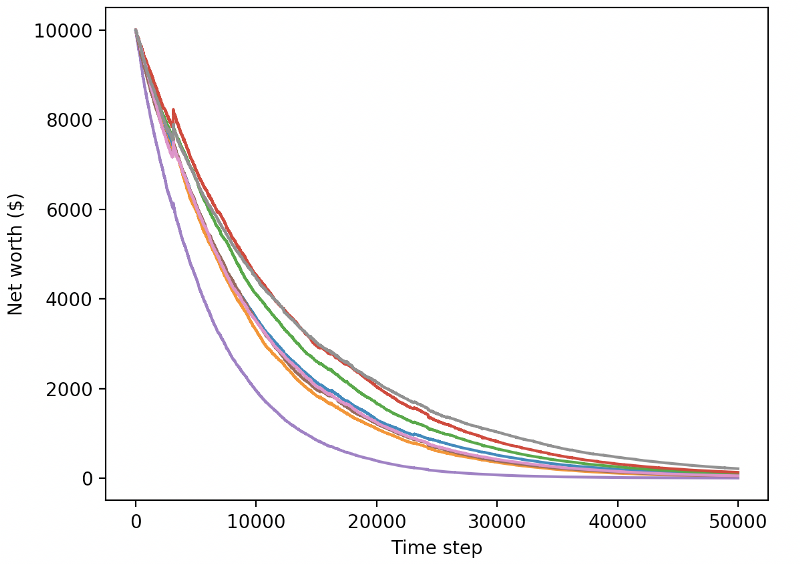
Unser trainierter Bot geht beim Handel mit neuen Testdaten pleite
Es ist klar, dass noch viel Arbeit vor uns liegt. Indem wir das Modell einfach so umstellen, dass es einen stabilen A2C-Basiswert anstelle des aktuellen PPO2-Roboters verwendet, können wir unsere Leistung in diesem Datensatz erheblich verbessern. Und schließlich können wir, dem Vorschlag von Sean O’Gorman folgend, unsere Belohnungsfunktion leicht aktualisieren, sodass wir Belohnungen zum Nettovermögen hinzufügen, statt nur ein hohes Nettovermögen zu erreichen und es dabei zu belassen.
reward = self.net_worth - prev_net_worth
Allein diese beiden Änderungen verbessern die Leistung des Testdatensatzes erheblich und wie Sie unten sehen können, sind wir endlich in der Lage, mit neuen Daten, die nicht im Trainingssatz enthalten waren, Rentabilität zu erzielen.
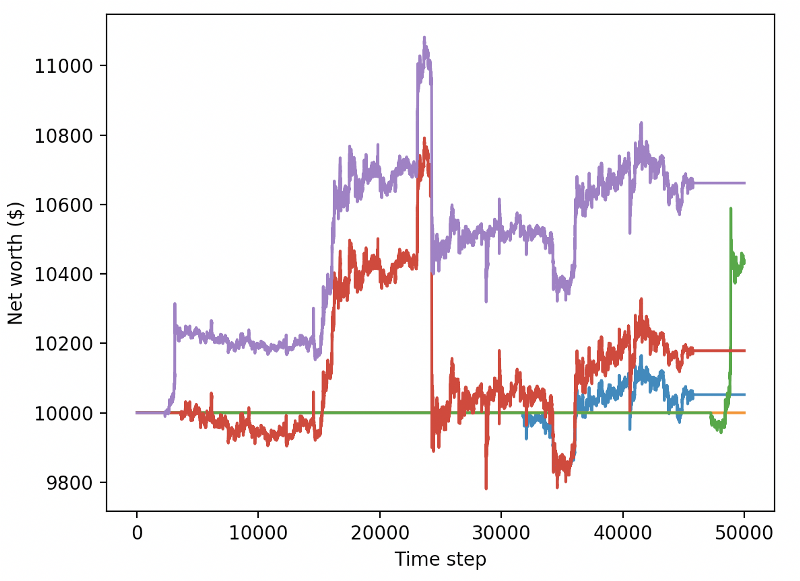
Aber wir können es besser machen. Damit wir diese Ergebnisse verbessern können, müssen wir unsere Hyperparameter optimieren und unseren Bot länger trainieren. Es ist Zeit, Ihre GPU zum Laufen zu bringen und auf Hochtouren laufen zu lassen!
Da dieser Beitrag mittlerweile etwas lang geworden ist und wir noch viele Einzelheiten berücksichtigen müssen, machen wir hier eine Pause. Im nächsten Beitrag werden wir die Bayessche Optimierung verwenden, um die besten Hyperparameter für unseren Problembereich zu partitionieren und uns auf das Training/Testen auf GPUs mit CUDA vorzubereiten.
abschließend
In diesem Artikel haben wir uns vorgenommen, mithilfe von bestärkendem Lernen einen profitablen Bitcoin-Handelsbot von Grund auf zu erstellen. Folgende Aufgaben können wir übernehmen:
Erstellen Sie mithilfe des Gym von OpenAI eine Bitcoin-Handelsumgebung von Grund auf.
Verwenden Sie Matplotlib, um eine Visualisierung der Umgebung zu erstellen.
Trainieren und testen Sie unseren Bot mithilfe einer einfachen Kreuzvalidierung.
Optimieren Sie unseren Roboter leicht, um Rentabilität zu erzielen
Obwohl unser Handelsroboter nicht so profitabel ist, wie wir es gerne hätten, sind wir auf dem richtigen Weg. Das nächste Mal werden wir sicherstellen, dass unser Bot den Markt konstant schlagen kann, und wir werden sehen, wie unser Trading-Bot anhand von Live-Daten abschneidet. Seien Sie gespannt auf meinen nächsten Artikel und: Lang lebe Bitcoin!