Systematically learn regular expressions (a): basic essay
Author: Inventors quantify - small dreams, Created: 2017-03-29 10:52:47, Updated: 2020-11-18 12:39:53Systematically learn regular expressions (a): basic essay
What is a regular expression? A regular expression is a set of pre-defined characters, and a combination of these characters, that forms a string string string that is used to express a filter logic for the string.
Regular expressions can be used to achieve the following:
给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”); 可以通过正则表达式,从字符串中获取我们想要的特定部分。To make it easier for you to learn, I recommend Regextor, a software that verifies regular expressions.
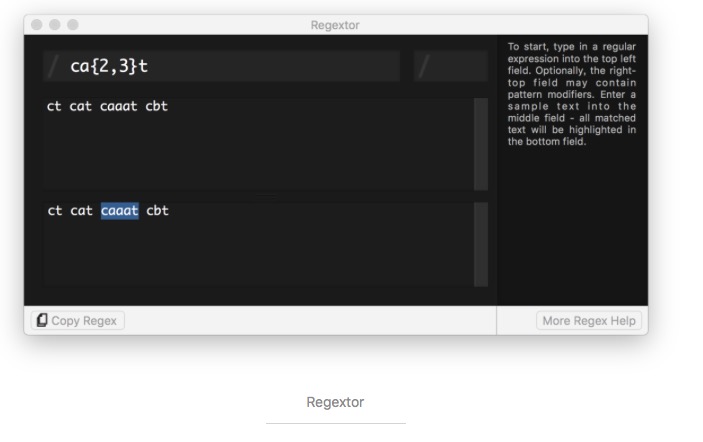
The following is an introduction to the rules of regular expressions:
-
Matching common text characters
Regular expressions can contain only plain text, representing a precise matching of that text; for example:
The formal expression is:
songThis is a list of characters who have appeared in the anime series Xiao Songge. Matching results: xiaosongGe, xiao songge By default, the regular expression is capitalized, so the song will not match theSong . However, most regular expression implementations provide an option to indicate the non-capitalization.
-
Match any character
. is used to match an arbitrary character, such as:
The regular expression is: c.t. Cat cet caaat dog is a game of cat-and-mouse. Matching results:
catcetCaat dog Analysis: c.t matches a string that starts with a syllable c, ends with a syllable t, and has an arbitrary character in the middle.同理,多个连续的.可以匹配多个连续的任意字符:
The regular expression: c..t Cat cet caat dog Matched results: cat cet
caatdog
-
Matching special characters
. is a special character in regular expressions with a special meaning.. is also a special character that can be used to translate special characters. If you want to match it, it is a real consonant.
The regular expression is: c.t. Cat c.t. dog is the name of the game. Matched results: cat
c.tThe dog Note: Because \ is also a special character, two inverse slopes are required to match a real \\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\:The regular expression: c\t Cat c \ t dog Matched results: cat
c\tdog
-
Use the character set
As mentioned above. I can match any character, but what if I want to match a few specific characters?
The regular expression is: c[ab]t I'm waiting for the match text: cat cbt cet Matching results:
catcbtThat's it. Analysis: [ab] matches aor a b . So c[ab]t matches a cat and a cbt without matching a cet .
-
Use character spaces
In the example above, what if I want to match cet and I add one more in [?], and if I want to match any lowercase letters, do I put dozens in?
The regular expression: c[a-z]t Cat cbt czt c2t Matching results:
catcbtcztc2t Analysis: c[a-z]t denotes a letter beginning withc , ending with t , and any letter in the middle of a - z . There are also similar areas:
[0-9] is the same function as [0123456789]. Matches all numbers. [A-F] Matches A to F capital characters. [A-Z] Matches all capital letters from A to Z. [a-z] matches all lowercase characters from a to z. [A-z] matches all characters in ASCII from A to ASCII z ((not only matches all characters, but also matches characters in the ASCII table from A to z, such as [ and ^ etc.)). [A-Za-z0-9] Matches all uppercase letters and numbers.
-
Matching of non-characters
Character sets are generally used to specify a set of characters that need to be matched. However, sometimes you want to exclude a set of characters that you don't want to match. This can be done by denying the character set.
The regular expression is: c[^a-z]t Cat cbt czt c2t cAt Matching results: cat cbt czt
c2tcAtAnalysis: This is the complete opposite of the previous example. │[a-z] matches all lowercase characters, while [^a-z] matches all non-lowercase characters.Note that the ^ character is a de-match of all characters in the character set.
-
Primary characters
Metatarsals have special meanings in regular expressions, and we have already said several metatarsals, such as., [and]. These characters cannot express their own meanings directly, for example, they cannot directly use [to match.........................................
All meta-characters can be preceded by an inverse-square transformation, after which the transformation will match the character itself rather than its special meaning. For example, [will match the [
: Regular expression: a[b] Text to match: a[b ab a[[b Matching results:
a[bAb a [[b]] Note: \ is used to convert a metric character, which also means \ is also a metric character. So if you need to match a real \\, you can use \: The regular expressions are: a\b Text to match: a\b a\b a[[b Matching results: a\b
a\ba[[b
-
Blank characters
Sometimes you may need to match blank characters that cannot be printed in the text. For example, you want to be able to find all tab characters, or all swap characters. You can use the special sub-characters in the table below:
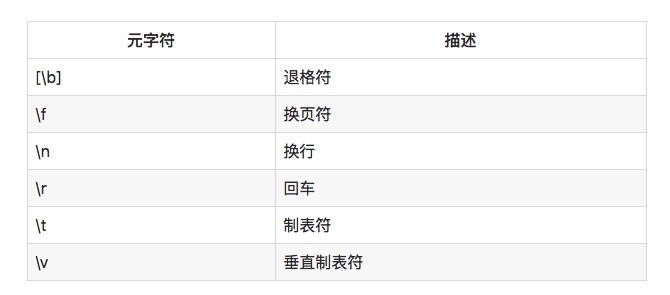
For example, \r\n will match a back-and-forth switching combination, which in Windows represents a file switching line. In Linux and Unix systems, only \n can be used.
-
Match specific character types
There are some special metatarsals that can be used to match commonly used character sets. These metatarsals are called matching character classes. You will find them very convenient to use.
Matching numbers or non-digits As mentioned above,[0-9] can match all numbers. If you don't want to match any numbers, you can use [^0-9]。 The following table lists numeric and non-numeric class elements:

The regular expression is: c\dt Cat c2t czt c9t Matching results: cat
c2tcztc9tThe regular expression is: c\Dt Cat c2t czt c9t Matching results:
catc2tcztc9t Matching alphabetic and non-alphabetic characters Another common class metadata is \w and \W: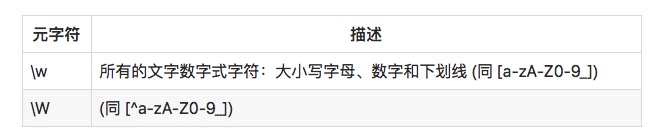
The regular expression is: c\wt Text to match: cat c2t czt c-t c\t Matching results:
catc2tc-t c\tThe regular expression is: c\Wt Text to match: cat c2t c-t c\t Matching results: cat c2t
c-tc\tMatching blank and non-blank The last matching class you will encounter is the blank class:
The regular expression: c\st Text to match: cat c t c2t c\t Matching results: cat
c tc2t c\tThe regular expression is: c\St Text to match: cat c t c2t c\t Matching results:
catc tc2tc\t
-
Match one or more characters
The + metric indicates matching one or more characters. For example, a will match a
a , and a+ will match one or more a . The regular expression is:cat I'm waiting for matching text: ct cat caat caaat Matched results: ct
catcaat caaatThe regular expression: ca+t I'm waiting for the matching text:ct cat caat caaat Matched results: ct
catcaatcaaatWhen using + in a character set, the + symbol needs to be placed outside the set:The regular expression is: c[0-9]+t Text to match: ct c0t cat c123t Matched results: ct
c0tcatc123tAnalysis: c[0-9]+t denotes a string that begins with the letter c and ends with the letter t, with one or more digits in the middle.Of course, [0-9+] is also a valid regular expression, but it represents a character set containing the symbols
0 - 9 and + . Generally, meta-characters such as. and + are used as literal meanings when used in a character set, so there is no need to translate them. However, it is okay to translate them, so the functions of [0-9+] and [0-9+] are the same.
Note: + is a meta-character, and matching
+ requires the use of the transitive +。
-
Match zero or more characters
If you want to match zero or more characters, you can use the * meta character.
The regular expression is: ca*t We are waiting for matching text: ct cat caat cbt Matching results:
ctcatcaatcbt Note:* The symbols are metadata. * * * * * * * * * * * * * *
-
Match zero or one character.
? matches a zero or a character. ▲ So,? is very suitable for matching an optional character in text. ▲
The regular expression is: ca?t We are waiting for matching text: ct cat caat cbt Matching results:
ctcatCaat cbt Note:? symbols are meta-characters.? to be able to match??
-
Use the number of matches
A regular expression allows the number of times a match can be specified. The number can be specified between the {\\displaystyle {\\displaystyle {\\displaystyle {\\displaystyle {\\displaystyle {\\vec {\\vec {}} } } Note: {and} is also a meta-character, which needs to be transliterated when using a literal meaning.
Exact number of matches To specify the number of matches, you can enter a number between {and}. For example, {3} will match the characters or sets that appear 3 times before:
The regular expression is: ca{3}t We are waiting for matching text: ct cat caaat cbt Matching results: ct cat
caaatcbt At least the number of matches We can also specify only the minimum value for matching. For example, {2,} means matching 2 or more times:The regular expression is: ca{1,}t We are waiting for matching text: ct cat caaat cbt Matched results: ct
catcaaatcbt Matching between fractions We can also use the minimum and maximum values to determine the number of matches. For example, {2,3} means a minimum of 2 matches and a maximum of 3 matches.The normal expression is ca{2,3}t We are waiting for matching text: ct cat caaat cbt Matching results: ct cat
caaatcbt So? and {0,1} have the same function + and {1,} have the same function.
-
Non-greedy matching
Let's look at the following examples:
The regular expression is: s.*g I'm waiting for the match text: xiao song xiao song The matching results: xiao song xiao song Analysis: s.*g does not match two s*ngs, as expected, but matches all text between the first s*ng and the last s*ng.
This is because * and + are greedy matches. That is, the regular expression always looks for the largest match, not the smallest, which is deliberately designed.
But if you don't want greedy matching, use these measure words for non-greedy matching (matching as few characters as possible):

*? YesIt's a non-greedy version, so you can use it.To modify the example above:
正则表达式:s.What? I'm waiting for the match text: xiao song xiao song Matched results: xiao
songxiaosong分析:可以看到s.?g matches two song titles.
-
Define the boundary of the string
The meta-character matching the string boundary is ^ and $, which are used at the beginning and end of the string, respectively.
^ Use the following terms:
The formal expression is:^xiao
This is the first time I've seen this video. Matching results:
xiaosongAxiosong is a song written and performed by the Japanese singer-songwriter Axiosong. The results of the matches: axiaosong Analysis: ^xiao matches a string that starts with
xiao . $ is used as follows:
The official expression is song$.
This is the first time I've seen this video. Matched results: xiao
songThis is the first time I've seen this video. The results of the matches: Xiaosonga Analysis: song $ matches a string ending in
song . Shared use:
The normal expression is:^[0-9a-zA-Z]{4,}$
Text to be matched: a1b234ABC Matching results:
a1b234ABCText to match: + a1b23 = 4ABC The result after matching: + a1b23 = 4ABC Analysis: ^[0-9a-zA-Z]{4,}$ matched with a number or letter, and the number of digits is greater than or equal to the four-digit string.
Note: ^ is negative if it is at the beginning of the set; if it is outside of the set, the starting position of the string will be matched.
-
Use the multi-line mode
However, a multi-line mode can be enabled. In multi-line mode, the regular expression engine will use a comma as the separator of the string, ^ will match the beginning of the text or the beginning of a line, and $ will match the end of the text or the end of a line.
Modify the previous example:
The formula is: ((?m) ^ [0-9a-zA-Z]{4,}$
Text to be matched: a1b234ABC + a1b23 is 4ABC ABC123456 This is the last one.
Matching results:
a1b234ABC+a1b23=4ABCABC123456Analysis: ((?m) ^[0-9a-zA-Z]{4,}$ will match the number or letter composition of each line, and the number of digits is greater than the four-digit string.Note: If a multi-line pattern is used, the m must be placed at the beginning of the regular expression. (?m) is not supported in most regular expression implementations. Some regular expression implementations also support the use of \A to match the beginning of the string and \Z to match the end of the string. If supported, these metadata have the same function as ^, $.
This article is about the basics of learning regular expressions systematically.
Translated from the booklet by iOS_Chosunoko
- Subjective and quantitative, synthetic and comparative
- Swing trading and swing trading
- How to use a template for drawing two Y-axes
- 7 issues to consider when dealing in virtual currency
- We hope to support the Bitmex platform
- Support for Coinbase and itbit
- MacD, please look at this.
- Indicator of the performance of trading algorithms -- Sharpe ratio
- A new kind of grid trading law
- I feel like you guys cut the cabbage, and I'm still holding the coin.
- Python and the Simple Bayes Application
- Analysis of the application of screw steel, iron ore ratio trading strategies
- How to analyze the volatility of options?
- Programmatic application of options
- Time and Cycle
- Support vector machines in the brain
- Talk about being a marketer and a mother.
- The deepest road in the world is your path: dig deep into the pits of the Sutlej River
- Read the probability statistics over the threshold and the simplest probability theories you never thought of.
- This is the third installment of the Money Management Trilogy: Format First.