Neural network and digital currency quantitative trading series ((2)) Deep reinforcement learning training Bitcoin trading strategies
Author: The grass, Created: 2019-07-31 11:13:15, Updated: 2024-12-19 21:00:03
1.介绍
Previous articleHow to use LSTM network to predict Bitcoin pricehttps://www.fmz.com/digest-topic/4035As mentioned in the article, this is just a small project for practitioners to familiarize themselves with RNN and pytorch. This article will introduce methods of using reinforcement learning to directly train trading strategies. The reinforcement learning model is an OpenAI open source PPO, while the environment refers to gym styles. PPO, also known as Proximal Policy Optimization, is an optimization improvement to Policy Graident, a strategy gradient gym also released by OpenAI, which can interact with the strategy network, feedback on the current state of the environment and rewards, like the practice of reinforcement learning using the PPO model of LSTM to make buy, sell or do not operate instructions directly based on the market information of Bitcoin, feedback from the retesting environment, and achieve strategic profitability by training the model to continuously optimize. Reading this article requires a certain depth of knowledge of Python, pytorch, DRL. But it is not important, combined with the code given in this article, it is easy to learn the introduction.
2.数据和学习参考资料
Bitcoin price data is sourced from the inventor of FMZ's quantitative trading platform:https://www.quantinfo.com/Tools/View/4.htmlA post using DRL+gym to train trading strategies:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4Here are some examples of entrances to pytorch:https://github.com/yunjey/pytorch-tutorialThis article will use a short implementation of this LSTM-PPO model directly:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.pyThe article about PPO:https://zhuanlan.zhihu.com/p/38185553More articles about DRL:https://www.zhihu.com/people/flood-sung/postsThis article does not require installation, but reinforcement learning is common:https://gym.openai.com/
3.LSTM-PPO
In-depth explanation of the PPO can be learned from the previous reference material, here is just a simple introduction of the concept. The last phase of the LSTM network only predicted a price, how to buy and sell a transaction based on this predicted price is also implemented, it is natural to think that the direct output of the buy and sell action is not more direct?
Below is the source code of the LSTM-PPO, which can be understood in combination with the previous information:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4.比特币回测环境
The format is similar to the gym, with a reset initialization method, step input action, return result as ((next state, action gain, whether to end, additional information), the entire retrieval environment is also 60 lines, which can be modified on its own to a more complex version, specific code:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5.几个值得注意的细节
Why did the initial account have coins?
The formula for calculating the return of the retrospective environment is: current return = current account value - current value of the initial account. This means that if the price of Bitcoin falls, and the strategy makes a sell-coin operation, even if the total account value decreases, it should actually be rewarded with the strategy. If the retrospective period is long, the initial account may have little impact, but it still has a big impact at the beginning.
Why is it that people sample during training?
The total amount of data is more than ten thousand K-strings, which may be easier to overfit if the entire amount is run one cycle at a time, which takes a long time, and the strategy is the same in each situation. Extracting 500 pieces of data each time as a one-time retrieval, although it is still possible to overfit, the strategy faces more than ten thousand different possible starts.
What do you do when you have no money or no coins?
This is not taken into account in the retrospective environment, if the coin has been sold or does not reach the minimum trading volume, then executing the sell operation is actually equivalent to not executing the operation, if the price falls, according to the calculation of relative earnings, the strategy is still based on positive reward. The effect of this situation is that when the strategy judges the market decline and the account balance of the coin cannot be sold, it is impossible to distinguish between the selling action and the non-operating action, but the strategy itself has no effect on the judgment of the market situation.
Why do you want to return the account information to its original state?
The PPO model has a value network for evaluating the value of the current state, and obviously if the strategy judges that the price is going up, the entire state has a positive value only when the current account holds the bitcoin, and vice versa. So account information is an important basis for value network judgments. Note that it does not return past action information as a state, which the individual believes is useless for judging the value.
In what circumstances will it return to inactivity?
When the strategy judges that the profit from the buy-sell cannot cover the transaction fee, it should return to no action. Although the previous description repeatedly used the strategy to judge the price trend, for the sake of simplicity, the PPO model does not actually make a prediction of the market, but only produces the probability of three moves.
6.数据的获取和训练
As in the previous article, the way and format of data is as follows: Bitfinex exchange BTC_USD trades on the K line for one-hour cycles from 2018/5/7 to 2019/6/27:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Because of the long training time required to use the LSTM network, I changed the GPU version, which was about three times faster.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7.训练结果和分析
After a long wait:
First, look at the market for training data, and in general, the first half was a long decline and the second half was a strong rebound.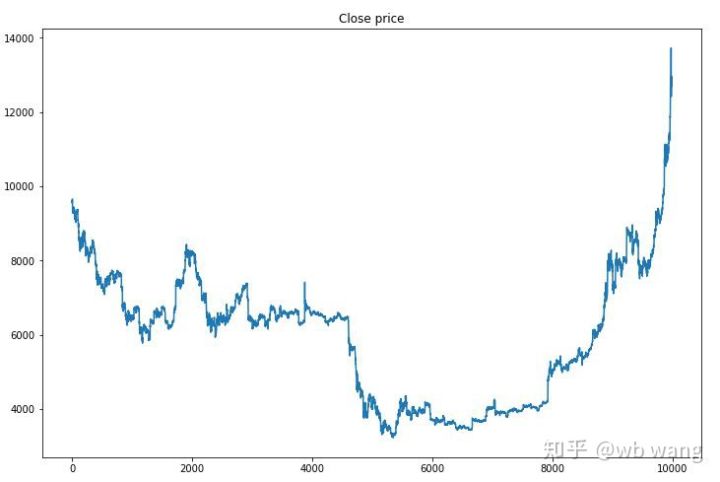
There are a lot of pre-training buy-in operations and basically no profitable round. By the middle of training, buy-in operations are gradually decreasing, and the probability of profit is also increasing, but there is still a large probability of loss.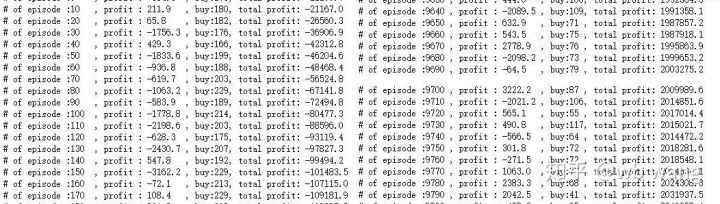
If you smooth out the earnings per round, the result is: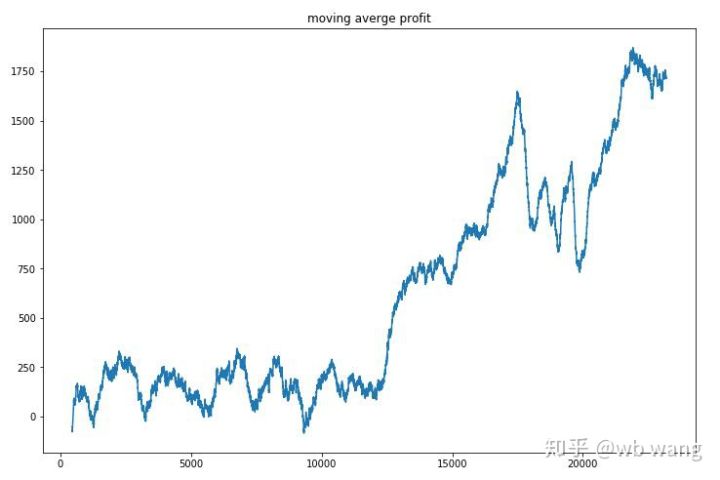
The strategy quickly recovered from the previous negative returns, but the fluctuations were large, and the returns did not grow rapidly until after 10,000 rounds, which was generally difficult to train the model.
After the final training, the model runs all the data once again to see how it performs, recording the total market value of the account, the number of bitcoins held, the percentage of bitcoin value, the total earnings during the period.
First, the total market value, the total earnings and the like, are not included: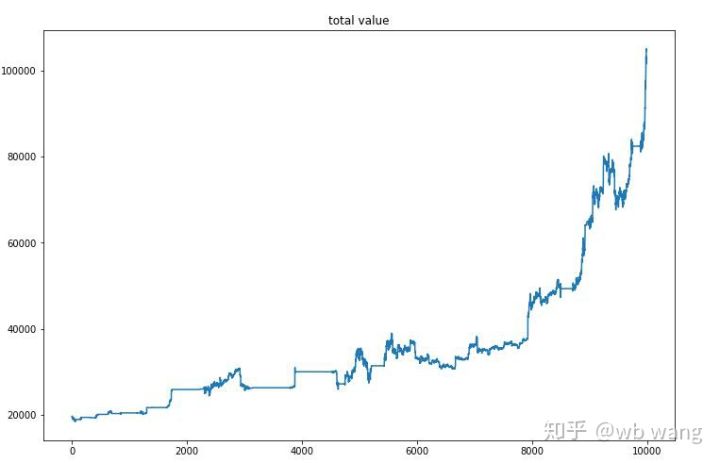
The total market value increased slowly during the early bear market, followed by an increase in the late bull market, but still showed a phased loss.
Finally, look at the holding ratio, the left axis of the graph is the holding ratio, the right axis is the market, you can initially judge that the model has appeared over-configured, the frequency of holding is low during the early bear market, the frequency of holding is high at the bottom of the market.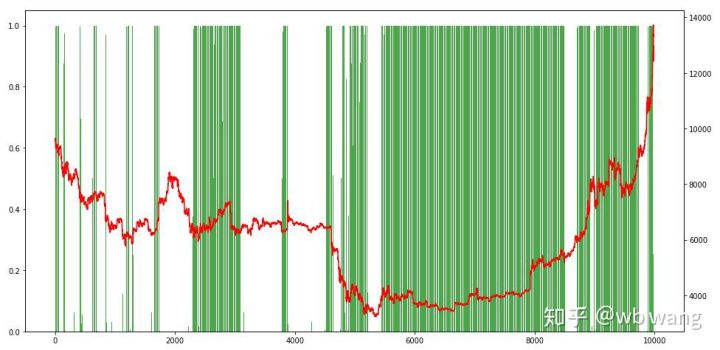
8.测试数据分析
The chart below shows the one-hour price of Bitcoin from $13,000 when the test data was obtained to $9,000 today, a big test for the model.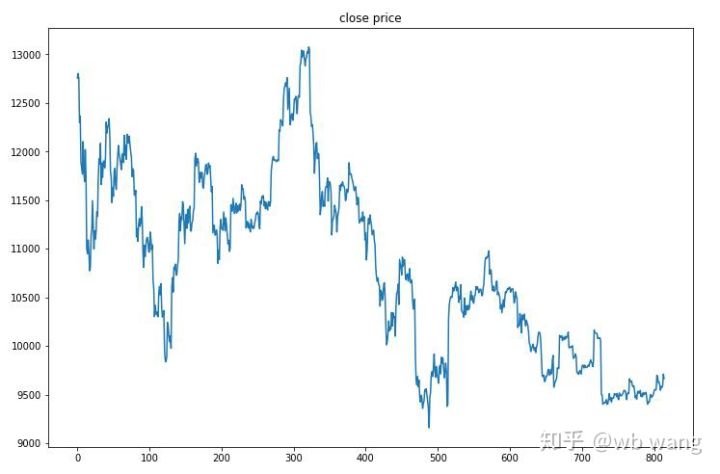
Firstly, in the long run, the relative gains were poor, but there were no losses.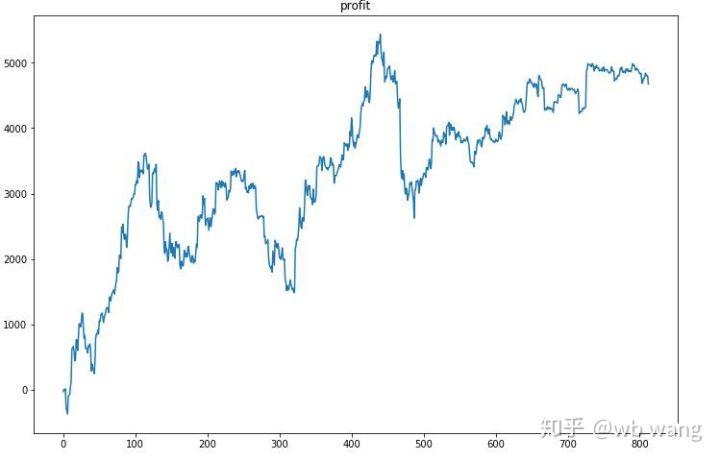
Looking back at the holdings, it can be assumed that the model tends to buy and sell rebounds after a sharp decline.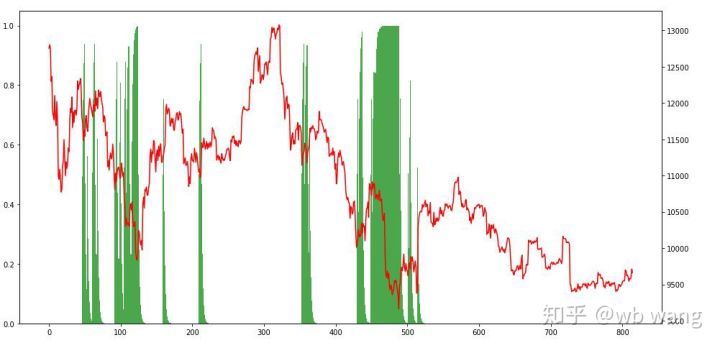
9.总结
This article trains a Bitcoin automated trading robot using the deep-learning method PPO, and some conclusions are made. Due to limited time, the model still has some areas for improvement, welcome to discuss. The biggest lesson is that the data is standardized, not scaled, or else the model will quickly remember the relationship between price and market, falling into a fit.
Previous articles: The inventors of FMZ share some of their public strategies on their quantification platform:https://zhuanlan.zhihu.com/p/64961672The course on quantitative digital currency trading at NetEase Cloud Classroom is only $20:https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076I'm going to show you a high-frequency strategy that used to be very profitable:https://www.fmz.com/bbs-topic/1211
- Quantitative Practice of DEX Exchanges (2) -- Hyperliquid User Guide
- DEX exchange quantitative practices ((2) -- Hyperliquid user guide
- Quantitative Practice of DEX Exchanges (1) -- dYdX v4 User Guide
- Introduction to Lead-Lag Arbitrage in Cryptocurrency (3)
- DEX exchange quantitative practice ((1) -- dYdX v4 user guide
- Introduction to the Lead-Lag suite in digital currency (3)
- Introduction to Lead-Lag Arbitrage in Cryptocurrency (2)
- Introduction to the Lead-Lag suite in the digital currency (2)
- Discussion on External Signal Reception of FMZ Platform: A Complete Solution for Receiving Signals with Built-in Http Service in Strategy
- Discussing FMZ platform external signal reception: a complete set of strategies for the reception of signals from built-in HTTP services
- Introduction to Lead-Lag Arbitrage in Cryptocurrency (1)
- A Dual Thrust digital currency quantified transaction strategy is implemented in Python
- K-line data processing in programmatic transactions is trivial
- Quantitative trading strategies for price dynamics analysis with Python
- Timeline data analysis with Tick data retrieval
- The experience of developing trading strategies
- Calculation and application of DMI indicators
- Detailed usage and practical skills of energy tide(OBV) indicator in quantitative trading
- The development of CTA strategies and the inventor quantification platform standard library
- The use of a combination strategy for the strength and weakness of the RSI versus the straight line
- Upgrade Edition of Keltner Channel trading Strategy
- Implementation and application of the inventor quantified platform in the fall line trading strategy
- Visualizing modules to build trading strategies - out
- KENTNA channel upgraded version of the KENTNA kingkeltner strategy
- Quantitative trading strategies with a trade index weighting
- Introducing the Aroon indicator
- The relative strengths and weaknesses of price-based quantitative trading strategies
- Introducing the adaptive moving average KAMA
- Implementation of Dual Thrust trading algorithms using My language on the inventor's quantification platform
- Introduction to RangeBreak Strategy
- Trading strategy based on box theory
lisa20231Why do you want to turn the pictures of the test results upside down? Why is it that when the dollar goes up, your earnings always go down?
jackmaprofit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) There is a bug It should be: profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
jackmaprofit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4]) There is a bug It should be: profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.start,4])
TimoshenkoIt's much stronger than the first edition.
xw2021I'm going to kill you.
EddieGod of the grass!
The grassGPU version What's up? device = torch.device (('cuda' if torch.cuda.is_available)) else 'cpu') class PPO ((nn.Module): def __init__ ((self): super ((PPO, self).__init__))) self.data = [] What do you think? self.fc1 = nn.Linear ((8,64) self.lstm = nn.LSTM ((64,32) self.fc_pi = nn.Linear ((32,3) self.fc_v = nn.Linear ((32,1) self.optimizer = optim.Adam ((self.parameters))) and lr = learning_rate def pi ((self, x, hidden): x = F.relu ((self.fc1))) x = x. view ((-1, 1, 64) x, lstm_hidden = self. lstm ((x, hidden)) x = self. fc_pi ((x)) prob = F.softmax ((x, dim = 2)) return prob, lstm_hidden is the return prob. What do you think? def v ((self, x, hidden): x = F.relu ((self.fc1))) x = x. view ((-1, 1, 64) x, lstm_hidden = self. lstm ((x, hidden)) v = self. fc_v ((x)) return v What do you think? def put_data ((self, transition): self.data.append (transition) is a file format used to store data. What do you think? def make_batch ((self): s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], For transition in self.data: s, a, r, s_prime, prob_a, hidden, done = transition What do you think? s_lst.append (s) a_lst.append (a) r_lst.append (r) s_prime_lst.append (s_prime) is the name of the I'm going to try to find a way to do this. Hidden_lst.append (HIDDEN) is the name of the app. done_mask = 0 if done else 1 This is done_lst.append What do you think? s,a,r,s_prime,done_mask,prob_a = torch.tensor ((s_lst,dtype=torch.float).to ((device),torch.tensor ((a_lst).to ((device).to ((device), \ Torch.tensor ((r_lst).to ((device), torch.tensor ((s_prime_lst, dtype=torch.float).to ((device), and \ Torch.tensor ((done_lst, dtype=torch.float).to ((device), torch.tensor ((prob_a_lst).to ((device) is a type of torch that is used to measure the speed of a torch. self.data = [] return s, a, r, s_prime, done_mask, prob_a, and hidden_lst[0] What do you think? def train_net ((self): s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch ()) first_hidden = (h1.to ((device).detach ((), h2.to ((device).detach (()) for i in range ((K_epoch): v_prime = self.v ((s_prime, first_hidden).squeeze))) td_target = r + gamma * v_prime * done_mask v_s = self.v ((s, first_hidden).squeeze ((1) delta = td_target - v_s and delta = delta.cpu (().detach (().numpy (()) advantage_lst = [] advantage = 0.0 for item in delta [::-1]: advantage = gamma * lmbda * advantage + item [0] This is a list of all the different ways advantage_lst.append is credited in the database. advantage_lst.reverse ()) advantage = torch.tensor ((advantage_lst, dtype=torch.float).to ((device)) pi, _ = self. pi ((s, first_hidden) pi_a = pi.squeeze ((1).gather ((1, a) ratio = torch.exp ((torch.log ((pi_a) - torch.log ((prob_a)) # a/b == log ((exp ((a) -exp ((b)) surr1 = ratio * advantage surr2 = torch.clamp ((ratio, 1-eps_clip, 1+eps_clip) * advantage loss = -torch.min ((surr1, surr2) + F.smooth_l1_loss ((v_s, td_target.detach)))) This is a self.optimizer.zero_grad. loss.mean (().backward ((retain_graph=True)) This is self.optimizer.step. What's up?