Exploración inicial de la aplicación de Python Crawler en FMZ Crawling Contenido del anuncio de Binance
El autor:No lo sé., Creado: 2022-04-08 15:47:43, Actualizado: 2022-04-13 10:07:13Exploración inicial de la aplicación de Python Crawler en FMZ Crawling Contenido del anuncio de Binance
Recientemente, miré a través de nuestros Foros y Digest, y no hay información relevante sobre el rastreador de Python. Basado en el espíritu de desarrollo integral de FMZ, simplemente fui a aprender sobre los conceptos y el conocimiento del rastreador. Después de aprender al respecto, descubrí que todavía hay más por aprender sobre la técnica del rastreador. Este artículo es solo una exploración preliminar de la técnica del rastreador, y una práctica más simple de la técnica del rastreador en la plataforma comercial FMZ Quant.
Demandas
Para los comerciantes que les gusta el comercio de IPO, siempre quieren obtener la información de lista de la plataforma tan pronto como sea posible. Obviamente no es realista mirar manualmente un sitio web de la plataforma todo el tiempo.
La exploración inicial
Utilice un programa muy simple como comienzo (los scripts de rastreador realmente potentes son mucho más complejos, así que tómese su tiempo). La lógica del programa es muy simple, es decir, deje que el programa visite continuamente la página de anuncio de una plataforma, analice el contenido HTML adquirido y detecte si el contenido de una etiqueta especificada se actualiza.
Implementación del código
Puedes usar algunas estructuras de rastreador útiles.
Las bibliotecas de Python que se utilizarán:requests, que puede considerarse simplemente como la biblioteca utilizada para acceder a páginas web.bs4, que puede considerarse simplemente como la biblioteca utilizada para analizar el código HTML de las páginas web.
Código:
from bs4 import BeautifulSoup
import requests
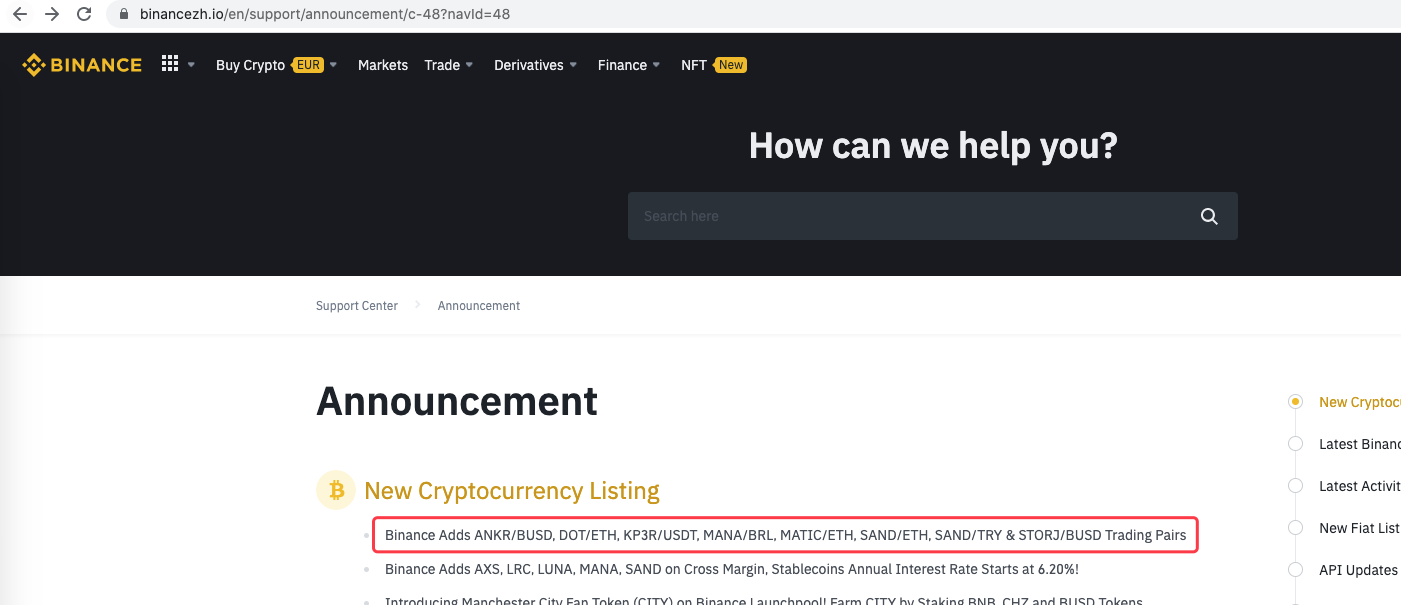
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # Binance announcement web page address
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # use "requests" library to access url, namely the Binance announcement web page address
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # parse the page text into objects
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # find specified lables, to obtain href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # obtain the content in the label
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # the label change detected, namely the new announcement generated
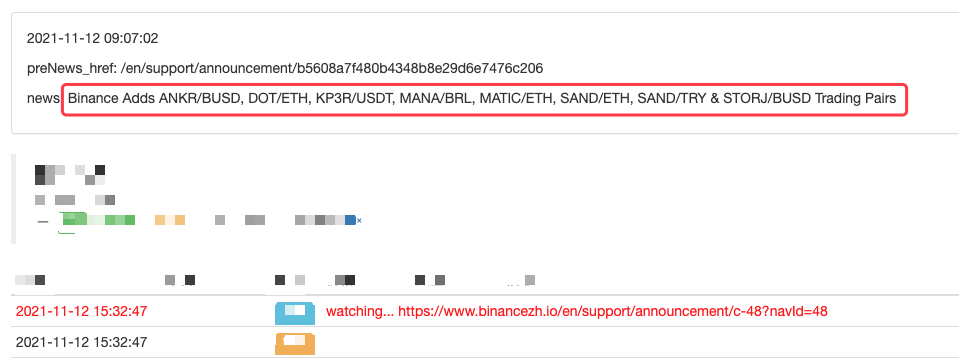
Log("New Cryptocurrency Listing update!") # print the prompt message
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
Operación
Incluso puede extenderlo, como la detección de nuevos anuncios, análisis de símbolos de divisas recién listados y orden automático de operaciones de IPO.
- No imprimir un registro
- Cancelar todos los pedidos pendientes en monedas actuales
- Inicio rápido de la plataforma de comercio cuántico FMZ
- Realizar un bot de supervisión de órdenes sencillo de Cryptocurrency Spot
- Una plataforma de pago basada en FMZ
- Contrato de criptomonedas bot de supervisión de órdenes sencillo
- Cuando se quiere obtener el tiempo de entrada correspondiente con getdepth
- Ignorado, resuelto
- El problema del valor facial
- Ejemplo de diseño de estrategia dYdX
- Investigación de diseño de estrategias de cobertura y ejemplo de órdenes de spot y futuros pendientes
- Situación reciente y funcionamiento recomendado de la estrategia de tasas de financiación
- Estrategia de punto de quiebre de promedio móvil doble de futuros de criptomonedas (Teaching)
- Estrategia de media móvil doble de símbolos múltiples de criptomoneda al contado (Teaching)
- Realización del indicador de Fisher en JavaScript y trazado en FMZ
- El administrador
- Revisión del TAQ de criptomonedas 2021 y estrategia perdida más simple de aumento de 10 veces
- Estrategia ART de futuros de criptomonedas de símbolos múltiples (Enseñanza)
- ¡Actualice! Estrategia de futuros de criptomonedas Martingale
- La función Getrecords no puede obtener el gráfico de K en segundos