Red neuronal y transacción cuantitativa de monedas digitales serie ((1) LSTM predicción del precio de Bitcoin
El autor:Las hierbas, Creado: 2019-07-12 14:28:20, Actualizado: 2024-12-19 20:58:01
1.简单介绍
Las redes neurales profundas se han vuelto cada vez más populares en los últimos años, y muestran una gran capacidad para resolver problemas que en el pasado no podían resolverse en muchos campos. En la predicción de secuencias de tiempo, el precio de la red neural comúnmente utilizado es RNN, ya que la RNN tiene no solo la entrada de datos actuales, sino también la entrada de datos históricos. Por supuesto, cuando hablamos de la predicción de precios de RNN, a menudo hablamos de una especie de RNN: LSTM. Este tutorial es ofrecido por FMZ, el inventor de la plataforma de comercio de moneda digital cuantitativa.www.fmz.comEn la página de Facebook de la empresa, se puede leer:
2.数据和参考
Un ejemplo de un pronóstico de precios relacionado:https://yq.aliyun.com/articles/538484Para más información sobre el modelo RNN:https://zhuanlan.zhihu.com/p/27485750Comprender las entradas y salidas de RNN:https://www.zhihu.com/question/41949741/answer/318771336En cuanto a pytorch: Documento oficialhttps://pytorch.org/docsPara más información, busque por su cuenta. Además, para leer este artículo se requiere un conocimiento previo, como pandas / reptiles / procesamiento de datos, pero no importa.
3. Parámetros del modelo LSTM de pytorch
Los parámetros de LSTM:
La primera vez que vi estos parámetros en el documento, mi reacción fue: Si lo lees despacio, probablemente lo entiendas.
Si lo lees despacio, probablemente lo entiendas.

input_size: tamaño de la característica del vector de entrada x, si el precio de cierre se prevé en el precio de cierre, entonces input_size=1; si el precio de cierre se prevé en el precio de cierre, entonces input_size=4hidden_sizeTamaño de la capa implícita:num_layersNúmero de capas de RNN:batch_firstSi para True la primera dimensión que se ingresa es batch_size, este parámetro también puede ser confuso, y se explicará en detalle a continuación.
Los parámetros de entrada de datos son:
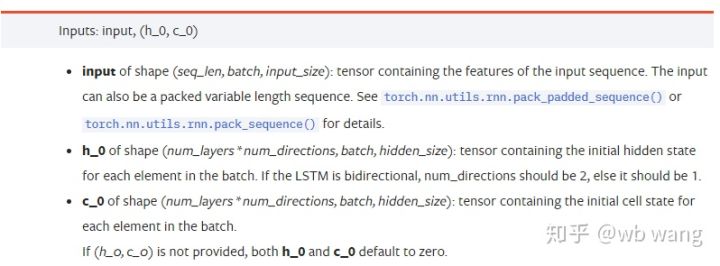
input: Los datos concretos de entrada son un tensor tridimensional, con la forma concreta de: ((seq_len, batch, input_size) ). Dentro de ellos, la longitud de la secuencia de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias de secuencias deh_0: estado oculto inicial, con la forma ((num_layers * num_directions, batch, hidden_size), si el número de direcciones de red bidireccional es = 2c_0: estado inicial de la célula, la misma forma, puede no ser especificado.
Los parámetros de salida:
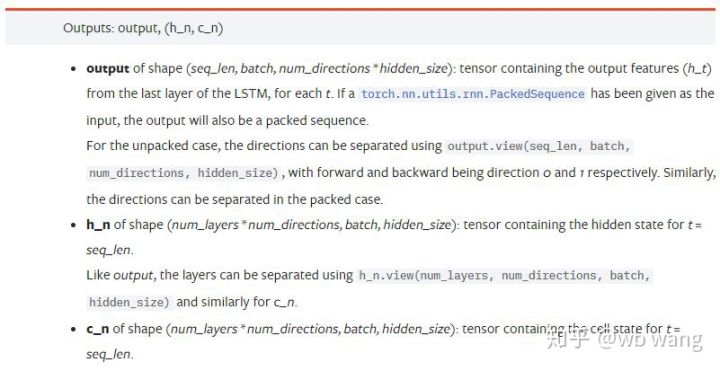
output: la forma de salida (seq_len, batch, num_directions * hidden_size), la atención está relacionada con el parámetro del modelo batch_firsth_n: t = estado h en el momento seq_len, con la misma forma que h_0c_n: t = estado c en el momento seq_len, con la misma forma que c_0
4.LSTM输入输出的简单例子
Primero importa los paquetes que necesitas.
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
Definición del modelo LSTM
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
Los datos están listos para ingresar
x = torch.randn(3,4,5)
# x的值为:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
Así que la forma de x es ((3,4,5)), como lo hemos definido antes.batch_first=TrueEl tamaño del batch_size es 3, el sqe_len es 4, el input_size es 5; x[0] representa el primer batch.
Si no se define batch_first, por defecto Falso, entonces la representación de los datos en este momento es completamente diferente, el tamaño del batch es de 4, sqe_len es de 3 y input_size es de 5; en este momento, x[0] representa todos los datos del batch cuando t=0, por lo tanto, la suposición. La persona siente que esta configuración no es intuitiva, por lo que se agregan parámetros.batch_first=True.
La conversión de datos entre los dos también es muy fácil:x.permute(1,0,2)
Input y output
La forma de las entradas y salidas de LSTM es fácilmente confusa, y la siguiente figura puede ayudar a comprender: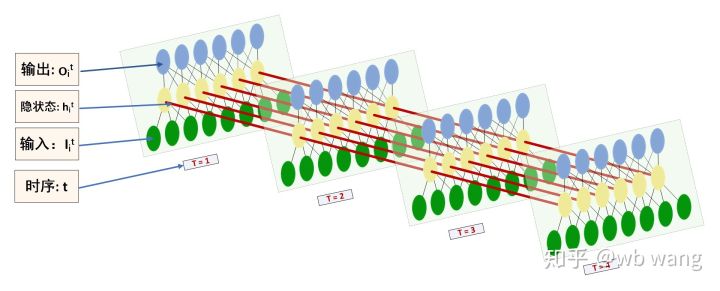
Fuente de información:https://www.zhihu.com/question/41949741/answer/318771336
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) #在这里思考一下,如果batch_first=False输出的大小会是多少?
print(hn.size())
print(cn.size())
#结果
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
Los resultados observados coinciden con la explicación de los parámetros anteriores. Nótese que el segundo valor dehn.size (()) es 3, y el tamaño de batch_size es consistente, lo que indica que no se guarda el estado intermedio en hn, sino solo el último paso. Dado que nuestra red LSTM tiene dos capas, en realidad, la última capa de output es el valor de la salida, la salida tiene la forma de [3, 4, 10], y guarda el resultado de t = 0, 1, 2, 3 en todos los momentos, por lo que:
hn[-1][0] == output[0][-1] #第一个batch在hn最后一层的输出等于第一个batch在t=3时output的结果
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5.准备比特币行情数据
Con todo lo dicho anteriormente, es una pavimentación, y es importante entender las entradas y salidas de LSTM, de lo contrario, extraer algo de código al azar de la web es fácilmente erróneo, ya que debido a la poderosa capacidad de LSTM en la secuencia de tiempo, incluso si el modelo está equivocado, puede obtener buenos resultados en el final.
Acceso a los datos
Los datos se utilizan en el mercado de Bitfinex para el intercambio BTC_USD.
import requests
import json
resp = requests.get('https://q.fmz.com/chart/history?symbol=bitfinex.btc_usd&resolution=15&from=0&to=0&from=1525622626&to=1562658565')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
Los formatos de datos son los siguientes: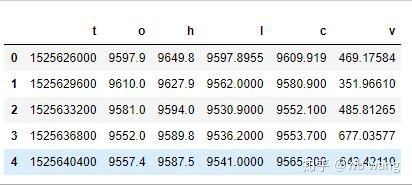
Preprocesamiento de datos
df.index = df['t'] # index设为时间戳
df = (df-df.mean())/df.std() # 数据的标准化,否则模型的Loss会非常大,不利于收敛
df['n'] = df['c'].shift(-1) # n为下一个周期的收盘价,是我们预测的目标
df = df.dropna()
df = df.astype(np.float32) # 改变下数据格式适应pytorch
El método de estandarización de los datos es muy rudo y puede tener algunos problemas, solo es una demostración, se puede usar estandarización de datos como el rendimiento.
Preparación de datos de entrenamiento
seq_len = 10 # 输入10个周期的数据
train_size = 800 # 训练集batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) #变化形状,-1代表的值会自动计算
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
Las formas de tren_x y tren_y son: torch.Size (([800, 10, 5]), torch.Size (([800, 10, 1]) ; puesto que nuestro modelo es un pronóstico del precio de cierre del próximo ciclo basado en datos de 10 ciclos, 800 lotes, en teoría, son suficientes para 800 precios de cierre previstos. Pero hay 10 datos en cada lote de tren_y, y en realidad el resultado intermedio del pronóstico de cada lote se conserva, no solo el último.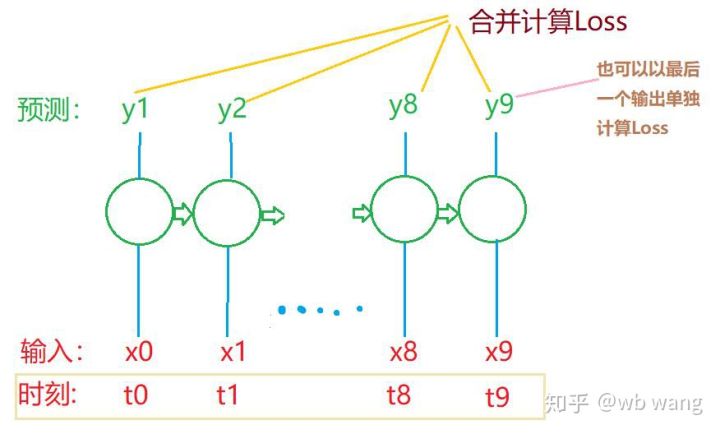
Tenga en cuenta que cuando se preparan los datos de entrenamiento, el movimiento de las ventanas es saltoso, los datos ya utilizados ya no se usan, y, por supuesto, las ventanas también se pueden mover individualmente, lo que da un gran número de reuniones de entrenamiento.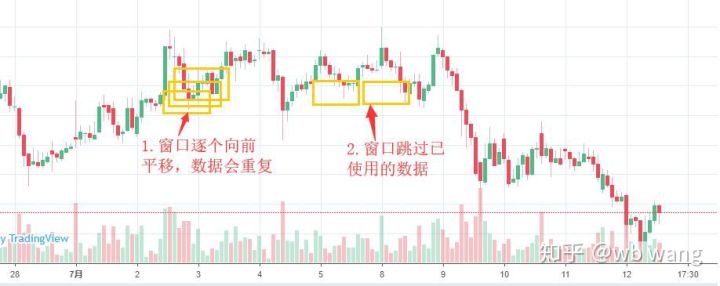
6.构造LSTM模型
El modelo final fue construido de la siguiente manera, con una capa LSTM de dos capas y una capa Linear.
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # 线性层,把LSTM的结果输出成一个值
def forward(self, x):
x, _ = self.rnn(x) # 如果不理解前向传播中数据维度的变化,可单独调试
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size为5,代表了高开低收和交易量. 隐含层为10.
7.开始训练模型
Finalmente comenzó el entrenamiento, el código es:
criterion = nn.MSELoss() # 使用了简单的均方差损失函数
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # 优化函数,lr可调
for epoch in range(600): # 由于速度很快,这里的epoch多一些
out = net(train_x) # 由于数据量很小, 直接拿全量数据计算
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # 反向传播损失
optimizer.step() # 更新参数
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
Los resultados de la capacitación son los siguientes: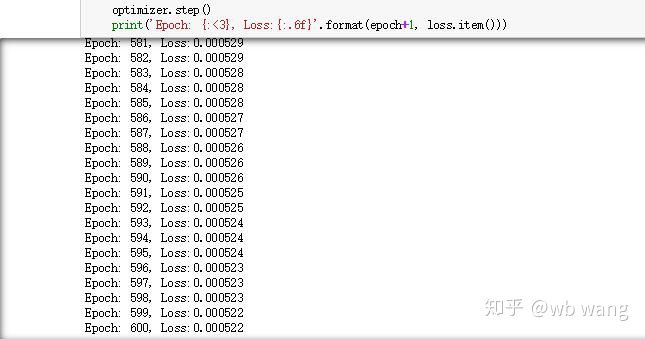
8.模型评价
El modelo predice:
p = net(torch.from_numpy(data_X))[:,-1,0] # 这里只取最后一个预测值作为比较
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
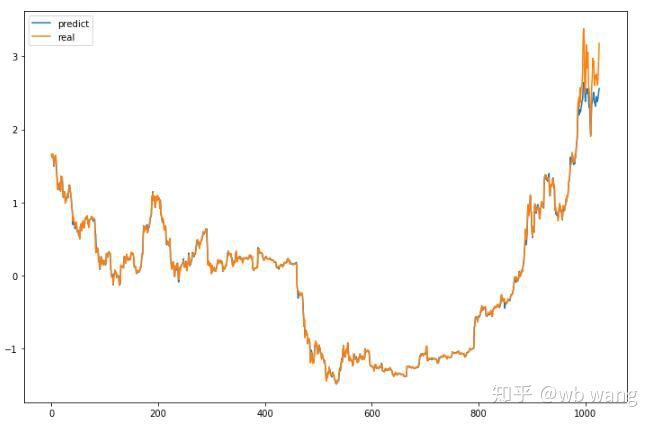
Como se puede ver en el gráfico, la coincidencia de los datos de entrenamiento (antes de 800) es muy alta, pero el precio de Bitcoin aumentó mucho más tarde, y el modelo no vio estos datos, por lo que los pronósticos no funcionaron. Esto también indica que hay problemas con la estandarización de los datos anteriores.
Si bien los precios no siempre son precisos, ¿cuál es la precisión para predecir una caída?
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
El resultado fue un 81.4% de precisión en la predicción de la caída, o más de lo que esperaba.
Por supuesto, este modelo no tiene ningún valor real, pero es sencillo y fácil de entender, por lo que se introducirá a más cursos de introducción a la aplicación de redes neuronales en la cuantificación de monedas digitales.
- Prácticas de cuantificación de las bolsas DEX ((1) -- dYdX v4 Guía de uso
- Introducción al conjunto de Lead-Lag en las monedas digitales (3)
- Introducción al arbitraje de lead-lag en criptomonedas (2)
- Introducción al conjunto de Lead-Lag en las monedas digitales (2)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: una solución completa para recibir señales con servicio HTTP incorporado en la estrategia
- Exploración de la recepción de señales externas de la plataforma FMZ: estrategias para una solución completa de recepción de señales de servicios HTTP integrados
- Introducción al arbitraje de lead-lag en criptomonedas (1)
- Introducción al conjunto de Lead-Lag en las monedas digitales (1)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: API extendida VS estrategia Servicio HTTP incorporado
- Exploración de la recepción de señales externas de la plataforma FMZ: API de expansión vs estrategia de servicio HTTP incorporado
- Discusión sobre el método de prueba de estrategias basado en el generador de tickers aleatorios
- Introducción a la estrategia RangeBreak
- Estrategia de negociación basada en la teoría de la caja
- Estrategias de negociación basadas en la teoría del cuadro que apoyan los futuros de productos y las monedas digitales
- Estrategias de termostato en las prácticas y aplicaciones de la plataforma de cuantificación de inventores
- Marco estratégico para los indicadores medios
- 6 estrategias y prácticas sencillas para principiantes en la transacción cuantitativa de monedas digitales
- Modulo de visualización para construir estrategias de transacción - progreso
- Sistema de operaciones diarias Pivot Point
- Los tres modelos de potencial en el comercio cuantitativo
- Aplicaciones de la estrategia RangeBreak en la vida real combinada con la volatilidad
- Principios y redacción de modelos de detención de daños
- Modulo de visualización para construir estrategias de transacción - Iniciación
- Sistema de negociación de divisas automático y software de negociación cuantitativa basado en el inventor de KAMA
- La plataforma de cuantificación de los inventores de FMZ
- Una simple demostración de la operación de la barra de la media móvil. (My language version)
- El edificio de la industria revela transacciones de algoritmos: los inventores cuantifican las plataformas como estrategias de mercado
- Cálculo y aplicación de los indicadores DMI
- Una estrategia de negociación intradía que utiliza la regresión de la media entre SPY e IWM
- Aplicación de los indicadores tecnológicos de Aroon en las transacciones cuantitativas
- Implementar políticas de cuantificación con JavaScript para ejecutar simultáneamente la función Go de envase de galón
- ¿ Qué haces?¿Los datos de entrenamiento son los mismos que los datos de pruebas?
a838899Lo que no está muy claro es si usas datos de 800 días para predecir los datos del día siguiente o los datos de los próximos 800 días.
Orión 1708¿Por qué decir que este modelo no tiene valor real?