Exploration initiale de l'application de Python Crawler sur FMZ Crawling Contenu de l'annonce de Binance
Auteur:Je suis désolée., Créé à: 2022-04-08 15:47:43, Mis à jour à: 2022-04-13 10:07:13Exploration initiale de l'application de Python Crawler sur FMZ Crawling Contenu de l'annonce de Binance
Récemment, j'ai parcouru nos forums et Digest, et il n'y a pas d'informations pertinentes sur le robot d'exploration Python. Basé sur l'esprit de développement complet de FMZ, je suis allé simplement apprendre les concepts et les connaissances du robot d'exploration. Après avoir appris à ce sujet, j'ai constaté qu'il y a encore plus à apprendre sur la technique du robot d'exploration. Cet article n'est qu'une exploration préliminaire de la technique du robot d'exploration, et une pratique la plus simple de la technique du robot d'exploration sur la plateforme de trading FMZ Quant.
La demande
Pour les traders qui aiment le trading d'introduction en bourse, ils veulent toujours obtenir l'information de la plate-forme dès que possible. Il est évidemment irréaliste de regarder manuellement un site Web de plate-forme tout le temps.
Les premières explorations
Utilisez un programme très simple pour commencer (les scripts de robot d'exploration vraiment puissants sont beaucoup plus complexes, alors prenez votre temps). La logique du programme est très simple, c'est-à-dire que le programme visite en permanence la page d'annonce d'une plateforme, analyse le contenu HTML acquis et détecte si le contenu d'une étiquette spécifiée est mis à jour.
Mise en œuvre du code
Vous pouvez utiliser des structures d'explorateurs utiles.
Les bibliothèques python à utiliser:requests, qui peut être simplement considérée comme la bibliothèque utilisée pour accéder aux pages Web.bs4, qui peut simplement être considérée comme la bibliothèque utilisée pour analyser le code HTML des pages Web.
Le code:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # Binance announcement web page address
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # use "requests" library to access url, namely the Binance announcement web page address
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # parse the page text into objects
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # find specified lables, to obtain href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # obtain the content in the label
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # the label change detected, namely the new announcement generated
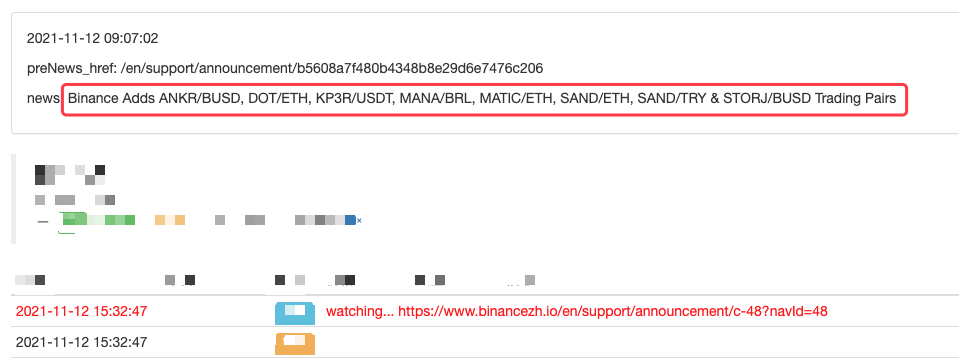
Log("New Cryptocurrency Listing update!") # print the prompt message
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
Opération
Vous pouvez même l'étendre, comme la détection de nouvelles annonces, l'analyse de nouveaux symboles de devises cotés et l'ordre automatique des transactions d'introduction en bourse.
- Désactiver l'impression d'un journal
- Annuler toutes les commandes en cours
- Début rapide de l'application de la plateforme de négociation quantique FMZ
- Réaliser un robot de supervision d'ordre simple de Cryptocurrency Spot
- Une plateforme de paiement basée sur FMZ
- Contrats de crypto-monnaie Robot simple de supervision des ordres
- Vous voulez obtenir le temps correspondant lorsque vous utilisez getdepth
- Ignoré, résolu
- Le problème de la valeur
- Exemple de conception de stratégie dYdX
- Définition de la stratégie de couverture Recherche et exemple d'ordres en attente au comptant et à terme
- Situation récente et fonctionnement recommandé de la stratégie de taux de financement
- Stratégie de point de rupture à moyenne mobile double des contrats à terme sur crypto-monnaie (enseignement)
- Stratégie des moyennes mobiles doubles multi-symbole de crypto-monnaie (enseignement)
- Réalisation de l'indicateur Fisher en JavaScript et de la planification sur FMZ
- Le gérant
- 2021 Cryptocurrency TAQ Review & Stratégie manquée la plus simple d'augmentation de 10 fois
- Stratégie ART multi-symbole sur les contrats à terme de crypto-monnaie (enseignement)
- Mise à niveau! Stratégie de Martingale sur les contrats à terme de crypto-monnaie
- La fonction Getrecords n'arrive pas à récupérer le schéma de K en secondes