Série sur le trading quantitatif des réseaux neuronaux et des devises numériques (2) - Apprentissage par renforcement profond pour former les stratégies de trading Bitcoin
 7
5787
7
5787

1. Introduction
L’article précédent présentait l’utilisation du réseau LSTM pour prédire les prix du Bitcoin https://www.fmz.com/digest-topic/4035. Comme mentionné dans l’article, il s’agit simplement d’un petit projet pour s’entraîner et se familiariser avec RNN et pytorch . Cet article présentera l’utilisation de méthodes d’apprentissage par renforcement pour former directement des stratégies de trading. Le modèle d’apprentissage par renforcement est le PPO open source d’OpenAI, et l’environnement est basé sur le style de salle de sport. Pour faciliter la compréhension et les tests, le modèle LSTM PPO et l’environnement de backtesting gym sont directement écrits sans utiliser de packages prêts à l’emploi. PPO, nom complet de Proximal Policy Optimization, est une amélioration de l’optimisation de Policy Gradient, c’est-à-dire du gradient de politique. Gym est également publié par OpenAI. Il peut interagir avec le réseau de politiques et renvoyer l’état actuel et la récompense de l’environnement. Il s’agit d’un exercice d’apprentissage par renforcement qui utilise le modèle LSTM PPO pour effectuer directement des achats, des ventes ou aucune opération en fonction de l’environnement. Informations sur le marché du Bitcoin. Les instructions sont données par l’environnement de backtesting et le modèle est continuellement optimisé par la formation pour atteindre l’objectif de rentabilité de la stratégie. La lecture de cet article nécessite certaines bases en Python, Pytorch et DRL Deep Strength Learning. Mais ce n’est pas grave si vous ne savez pas comment faire. Il est facile d’apprendre et de commencer avec le code donné dans cet article. Cet article est produit par FMZ, l’inventeur de la plateforme de trading quantitatif de devises numériques (www.fmz.com). Bienvenue dans le groupe QQ : 863946592 pour communiquer.
2. Données et références d’apprentissage
Les données sur le prix du Bitcoin proviennent de la plateforme de trading quantitative FMZ Inventor : https://www.quantinfo.com/Tools/View/4.html Un article sur l’utilisation de DRL+gym pour entraîner des stratégies de trading : https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4 Quelques exemples de démarrage avec Pytorch : https://github.com/yunjey/pytorch-tutorial Cet article utilisera directement cette courte implémentation du modèle LSTM-PPO : https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py Articles sur PPO : https://zhuanlan.zhihu.com/p/38185553 Plus d’articles sur DRL : https://www.zhihu.com/people/flood-sung/posts Concernant la salle de sport, cet article ne nécessite pas d’installation, mais l’apprentissage par renforcement est très courant : https://gym.openai.com/
3.LSTM-PPO
Pour une explication approfondie du PPO, vous pouvez étudier les références précédentes. Voici simplement une introduction à ce concept simple. Dans le numéro précédent, le réseau LSTM prévoyait uniquement un prix. La manière d’acheter et de vendre des transactions en fonction de ce prix prédit doit être mise en œuvre séparément. Naturellement, on peut imaginer qu’il serait plus direct de générer directement les actions d’achat et de vente , droite? Policy Gradient est ainsi conçu. Il peut donner la probabilité de diverses actions en fonction des informations environnementales saisies. La perte de LSTM est la différence entre le prix prévu et le prix réel, tandis que la perte de PG est -log(p)*Q, où p est la probabilité qu’une action soit générée et Q est la valeur de l’action (comme le score de récompense). L’explication intuitive est que si la valeur d’une action est plus élevée, le réseau devrait générer une probabilité plus élevée pour réduire la perte. Bien que le PPO soit beaucoup plus compliqué, le principe est similaire. La clé réside dans la manière de mieux évaluer la valeur de chaque action et de mieux mettre à jour les paramètres.
Le code source de LSTM-PPO est donné ci-dessous, qui peut être compris en combinaison avec les informations précédentes :
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Environnement de backtesting Bitcoin
Suivant le format de gym, il existe une méthode d’initialisation de réinitialisation, une action d’entrée d’étape et le résultat renvoyé est (état suivant, avantage de l’action, si elle est terminée, informations supplémentaires). L’environnement de backtest complet ne comporte que 60 lignes, ce qui peut être modifié par vous-même. Version complexe, code spécifique :
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Plusieurs détails remarquables
Pourquoi le compte initial contient-il des pièces ?
La formule de calcul des rendements dans l’environnement de backtesting est la suivante : Rendement actuel = Valeur actuelle du compte - Valeur actuelle du compte initial. Cela signifie que si le prix du Bitcoin baisse et que la stratégie vend les pièces, la stratégie devrait en fait être récompensée même si la valeur totale du compte diminue. Si la période de backtesting est longue, le compte initial peut ne pas être beaucoup affecté, mais cela aura quand même un impact important au début. Le calcul des rendements relatifs garantit que chaque opération correcte obtient une récompense positive.
Pourquoi échantillonner le marché lors d’une formation ?
La quantité totale de données est supérieure à 10 000 K lignes. Si un cycle complet est exécuté à chaque fois, cela prendra beaucoup de temps et la stratégie sera confrontée exactement à la même situation à chaque fois, ce qui peut conduire à un surapprentissage. 500 barres sont dessinées à chaque fois comme données de backtest. Bien que le surajustement soit toujours possible, la stratégie fait face à plus de 10 000 démarrages possibles différents.
Que faire si vous n’avez pas de pièces ou d’argent ?
Cette situation n’est pas prise en compte dans l’environnement de backtest. Si la pièce a été vendue ou si le volume de transaction minimum n’est pas atteint, l’exécution de l’opération de vente à ce moment-là équivaut en fait à n’exécuter aucune opération. Si le prix baisse, selon le méthode de calcul du retour, elle est toujours basée sur la récompense positive de la stratégie. L’impact de cette situation est que lorsque la stratégie détermine que le marché est en baisse et que les pièces restantes sur le compte ne peuvent pas être vendues, il est impossible de faire la distinction entre les actions de vente et l’absence d’opération, mais cela n’a aucun impact sur le propre jugement de la stratégie. le marché.
Pourquoi renvoyer les informations de compte sous forme de statut ?
Le modèle PPO dispose d’un réseau de valeur utilisé pour évaluer la valeur de l’état actuel. Évidemment, si la stratégie détermine que le prix va augmenter, l’état entier n’aura une valeur positive que si le compte courant détient du Bitcoin, et vice versa. Les informations sur les comptes constituent donc une base importante pour évaluer la valeur du réseau. Notez que les informations sur les actions passées ne sont pas renvoyées sous forme d’état, ce qui, à mon avis, est inutile pour juger de la valeur.
Dans quelles circonstances ne reviendra-t-il pas à une opération ?
Lorsque la stratégie détermine que le profit provenant de l’achat et de la vente ne peut pas couvrir les frais de transaction, elle doit revenir à l’absence d’action. Bien que la description précédente ait utilisé à plusieurs reprises des stratégies pour déterminer les tendances des prix, ce n’était que pour faciliter la compréhension. En fait, ce modèle PPO ne fait aucune prédiction sur le marché, mais ne génère que les probabilités de trois actions.
6. Acquisition de données et formation
Comme dans l’article précédent, les données sont obtenues au format suivant : la ligne K d’une heure de la paire de trading BTC_USD sur la bourse Bitfinex du 7/5/2018 au 27/6/2019 :
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Comme le réseau LSTM était utilisé, le temps de formation était très long, je suis donc passé à une version GPU, qui était environ 3 fois plus rapide.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Résultats et analyse de la formation
Après une longue attente :

Commençons par examiner les tendances du marché des données de formation. D’une manière générale, la première moitié a été une longue baisse et la seconde moitié a été un fort rebond.
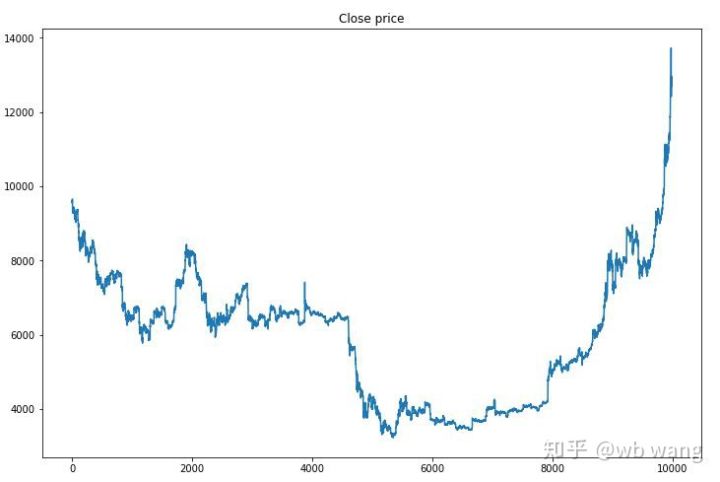
Il y a beaucoup d’opérations d’achat dans les premières étapes de la formation, et il n’y a pratiquement pas de cycles rentables. Vers le milieu de la période de formation, le nombre d’opérations d’achat a progressivement diminué et la probabilité de profit est devenue de plus en plus grande, mais la probabilité de perte était toujours élevée.
En lissant les revenus par tour, les résultats sont les suivants :
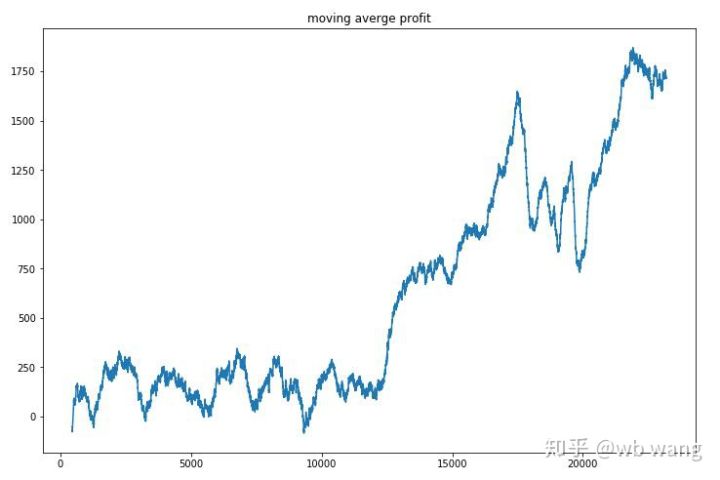
La stratégie a rapidement éliminé les rendements négatifs des premières étapes, mais les fluctuations étaient importantes. Ce n’est qu’après 10 000 tours que les rendements ont commencé à augmenter rapidement. En général, la formation du modèle était difficile.
Une fois la formation finale terminée, laissez le modèle exécuter à nouveau toutes les données pour voir comment il fonctionne. Pendant cette période, enregistrez la valeur marchande totale du compte, le nombre de bitcoins détenus, la proportion de la valeur du bitcoin et le revenu total .
Tout d’abord, il y a la valeur marchande totale. Le revenu total est similaire, je ne le publierai donc pas ici :
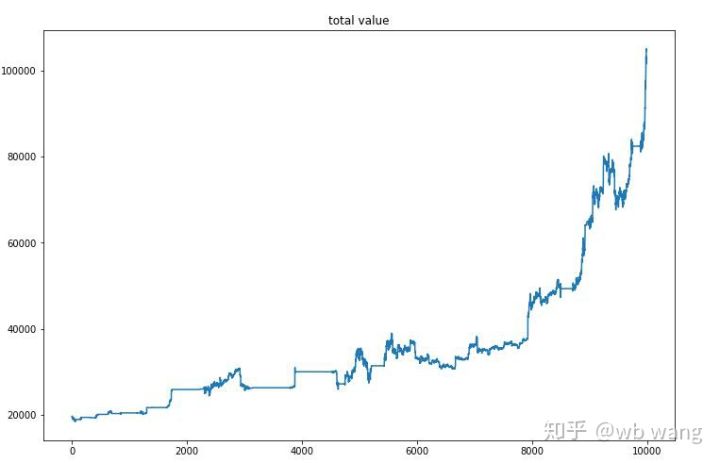
La valeur totale du marché a augmenté lentement au début du marché baissier et a également suivi la hausse au cours du marché haussier ultérieur, mais il y a eu encore des pertes périodiques.
Enfin, examinons la proportion de positions. L’axe de gauche du graphique représente la proportion de positions et l’axe de droite la situation du marché. On peut déterminer de manière préliminaire que le modèle a été surajusté. La fréquence des positions était faible au début du marché baissier, et la fréquence des positions était très élevée au plus bas du marché. Nous pouvons également voir que le modèle n’a pas appris à conserver des positions pendant longtemps et vend toujours rapidement.
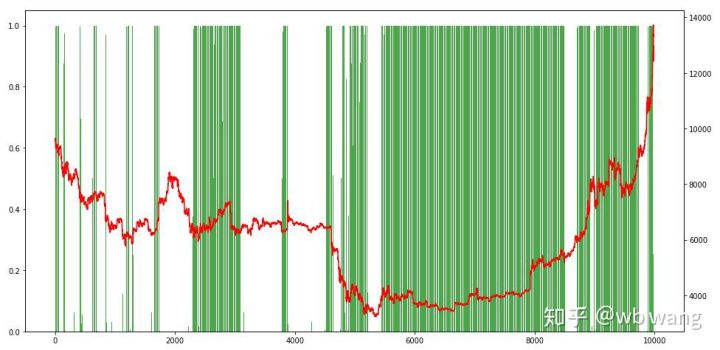
8. Analyse des données de test
Les données de test ont été obtenues à partir du marché Bitcoin d’une heure du 27/06/2019 à aujourd’hui. Comme on peut le voir sur la figure, le prix est passé de 13 000 \( au début à plus de 9 000 \) aujourd’hui, ce qui constitue un excellent test pour le modèle.
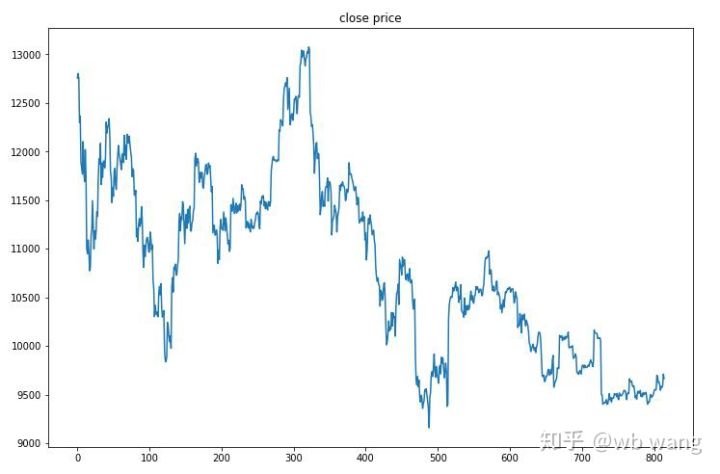
Tout d’abord, le rendement relatif final n’a pas été satisfaisant, mais il n’y a pas eu de perte non plus.
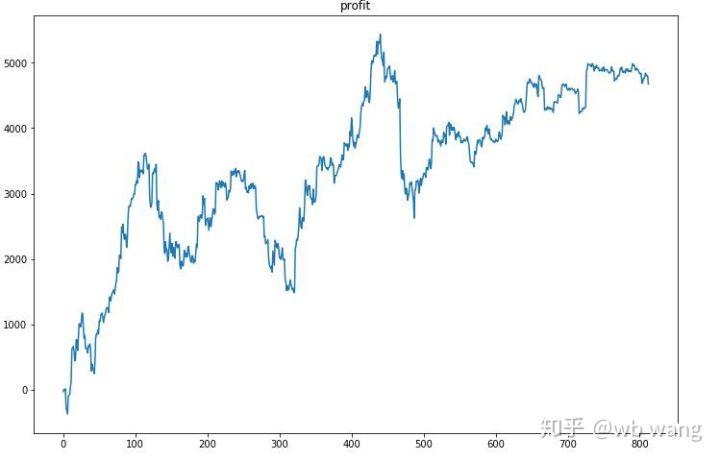
En observant les positions, on peut supposer que le modèle a tendance à acheter après une forte baisse et à vendre après un rebond. Le marché du Bitcoin a très peu fluctué ces derniers temps, et le modèle a été en position short.
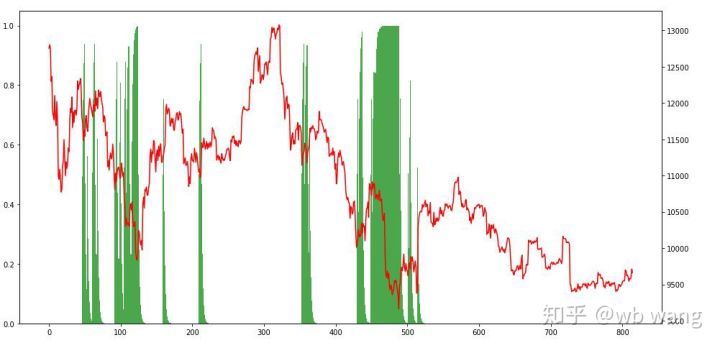
9. Résumé
Cet article utilise la méthode d’apprentissage par renforcement profond PPO pour former un robot de trading automatique Bitcoin et obtient quelques conclusions. En raison du temps limité dont nous disposons, certains aspects du modèle peuvent encore être améliorés. Tout le monde est invité à en discuter. La leçon la plus importante est que la standardisation des données est la bonne méthode. N’utilisez pas de méthodes telles que la mise à l’échelle, sinon le modèle se souviendra rapidement de la relation entre le prix et les conditions du marché et tombera dans le surajustement. Après normalisation, le taux de variation devient une donnée relative, ce qui rend difficile pour le modèle de se souvenir de sa relation avec le marché et l’oblige à trouver le lien entre le taux de variation et la hausse ou la baisse.
Articles précédents : Quelques partages de stratégies publiques sur la plateforme quantitative FMZ Inventor : https://zhuanlan.zhihu.com/p/64961672 Cours de trading quantitatif de devises numériques de NetEase Cloud Classroom, seulement 20 yuans : https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076 J’ai rendu publique une stratégie à haute fréquence qui était autrefois très rentable : https://www.fmz.com/bbs-topic/1211