Analyse quantitative du marché de la monnaie numérique
Auteur:La bonté, Créé: 2019-08-16 10:37:23, Mis à jour: 2023-10-19 21:04:20
Une méthode d'analyse spéculative de la monnaie numérique basée sur les données
Comment le prix du Bitcoin se déplace-t-il? Quelles sont les raisons de l'augmentation et de la baisse du prix de la crypto-monnaie? Les prix du marché des différentes crypto-monnaies sont-ils inextricablement liés ou sont-ils largement indépendants?
Les articles sur les monnaies numériques comme Bitcoin et Ethereum sont maintenant pleins de spéculations, et des centaines de soi-disant experts préconisent les tendances qu'ils attendent.
L'objectif de cet article est d'offrir une brève introduction à l'analyse des monnaies numériques en utilisant Python. Nous allons rechercher, analyser et visualiser des données sur différentes monnaies numériques à l'aide d'un simple script Python. En cours de route, nous découvrirons ces comportements volatiles du marché et les tendances intéressantes de leur évolution.
Ce n'est pas un article qui explique les crypto-monnaies, ni un point de vue sur les monnaies spécifiques qui vont augmenter et celles qui vont diminuer. Au contraire, notre objectif dans ce tutoriel est simplement d'obtenir des données brutes et de découvrir les histoires cachées dans les chiffres.
Première étape: construire notre environnement de travail sur les données
Ce tutoriel est conçu pour les amateurs, les ingénieurs et les scientifiques de données de tous niveaux de compétence. Que vous soyez un gros buff ou un petit programmeur, la seule compétence dont vous avez besoin est une connaissance de base du langage de programmation Python et suffisamment de connaissances en ligne de commande (pour configurer un projet de science des données).
1.1 Installer le gestionnaire de quantification des inventeurs et configurer Anaconda
- Système de gestionnaire quantifié par l'inventeur
发明者量化平台FMZ.COM除了提供优质的各大主流交易所的数据源,还提供一套丰富的API接口以帮助我们在完成数据的分析后进行自动化交易。这套接口包括查询账户信息,查询各个主流交易所的高,开,低,收价格,成交量,各种常用技术分析指标等实用工具,特别是对于实际交易过程中连接各大主流交易所的公共API接口,提供了强大的技术支持。
Toutes les fonctionnalités mentionnées ci-dessus sont enveloppées dans un système similaire à Docker, et nous devons simplement acheter ou louer notre propre service de cloud computing et le déployer.
Dans le nom officiel de la plate-forme de quantification des inventeurs, ce système Docker est appelé système d'hébergement.
Pour savoir comment déployer des hôtes et des robots, veuillez vous référer à mon précédent article:https://www.fmz.com/bbs-topic/4140
Les lecteurs qui souhaitent acheter leur propre hôte de déploiement de serveur en nuage peuvent consulter cet article:https://www.fmz.com/bbs-topic/2848
Après avoir déployé avec succès de bons services de cloud computing et un système d'administrateur, nous allons installer le plus grand temple de Python à ce jour: Anaconda.
Pour mettre en œuvre tous les environnements de programmation nécessaires à cet article (la bibliothèque de dépendances, la gestion des versions, etc.), le moyen le plus simple est d'utiliser Anaconda. Il s'agit d'un écosystème de data science Python et d'un gestionnaire de bibliothèque de dépendances.
Comme nous installons Anaconda sur un service cloud, nous vous recommandons d'installer une version Anaconda sur un serveur cloud avec une ligne de commande sur le système Linux.
Pour savoir comment installer Anaconda, consultez le guide officiel d'Anaconda:https://www.anaconda.com/distribution/
Si vous êtes un programmeur Python expérimenté et que vous n'avez pas besoin d'utiliser Anaconda, ce n'est pas un problème. Je suppose que vous n'avez pas besoin d'aide pour installer les dépendances nécessaires, vous pouvez passer directement à la deuxième partie.
1.2 Créer un environnement de projet d'analyse de données avec Anaconda
Une fois Anaconda installé, nous devons créer un nouvel environnement pour gérer nos packs de dépendances. Dans l'interface de la ligne de commande linux, nous saisissons:
conda create --name cryptocurrency-analysis python=3
Nous avons créé un nouvel environnement Anaconda pour notre projet.
Ensuite, entrez
source activate cryptocurrency-analysis (linux/MacOS操作)
或者
activate cryptocurrency-analysis (windows操作系统)
Nous avons besoin d'un peu de temps pour créer cet environnement.
Il y a aussi une autre version de l'article:
conda install numpy pandas nb_conda jupyter plotly
Le projet est conçu pour être installé avec les différents packs de dépendances nécessaires.
Remarque: Pourquoi utiliser l'environnement Anaconda? Si vous avez l'intention d'exécuter de nombreux projets Python sur votre ordinateur, il est utile d'éviter les conflits en séparant les packs de dépendance des différents projets (libraries et paquets).
1.3 Comment créer un ordinateur portable Jupiter
Une fois que l'environnement et les packs de dépendance sont installés, ils fonctionnent.
jupyter notebook
Pour démarrer le noyau de Python, utilisez votre navigateur pour accéder à http://localhost:8888/Pour créer un nouveau cahier Python, assurez-vous qu'il utilise:
Python [conda env:cryptocurrency-analysis]
Le noyau

1.4 Importation de paquet de dépendances
La première chose à faire est d'importer les packs de dépendances nécessaires.
import os
import numpy as np
import pandas as pd
import pickle
from datetime import datetime
Nous avons aussi besoin d'importer Plotly et d'activer le mode hors ligne.
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
Deuxième étape: obtenir des informations sur le prix des monnaies numériques
Les préparatifs sont terminés et nous pouvons maintenant commencer à obtenir les données à analyser. Tout d'abord, nous allons utiliser l'API de la plate-forme de quantification des inventeurs pour obtenir les données sur le prix du bitcoin.
Pour plus de détails sur l'utilisation de ces deux fonctions, voir:https://www.fmz.com/api
2.1 Écrire des fonctions de collecte de données pour Quandl
Pour faciliter l'acquisition de données, nous avons écrit une fonction pour télécharger et synchroniser les données de Quandl.quandl.comCette plateforme offre également une interface de données similaire, principalement utilisée pour les transactions en direct. Comme cet article est principalement consacré à l'analyse de données, nous utilisons ici les données de Quandl.
Lors de la négociation en direct, les fonctions GetTicker et GetRecords peuvent être appelées directement dans Python pour obtenir des données de prix.https://www.fmz.com/api
def get_quandl_data(quandl_id):
# 下载和缓冲来自Quandl的数据列
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return df
Ici, la bibliothèque pickle est utilisée pour sérialiser les données et stocker les données téléchargées dans un fichier, de sorte que le programme ne télécharge pas les mêmes données à chaque exécution. Cette fonction renvoie des données au format Dataframe de Panda.
2.2 Obtenir des données sur les prix des crypto-monnaies sur l'échange Kraken
Prenons l'exemple de l'échange Bitcoin Kraken, qui commence par le prix du Bitcoin qu'il a obtenu.
# 获取Kraken比特币交易所的价格
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
Pour voir les cinq premières lignes d'une zone de données, utilisez la méthode head ().
btc_usd_price_kraken.head()
Le résultat:
| BTC | Il est ouvert. | Très haut | Faible | Je suis proche. | Le volume (BTC) | Volume (monnaie) | Prix pondéré |
|---|---|---|---|---|---|---|---|
| 2014-01-07 | 874.67040 | 892.06753 | 810.00000 | 810.00000 | 15.622378 | 13151.472844 | 841.835522 |
| 2014-01-08 | 810.00000 | 899.84281 | 788.00000 | 824.98287 | 19.182756 | 16097.329584 | 839.156269 |
| 2014-01-09 | 825.56345 | 870.00000 | 807.42084 | 841.86934 | 8.158335 | 6784.249982 | 831.572913 |
| 2014-01-10 | 839.99000 | 857.34056 | 817.00000 | 857.33056 | 8.024510 | 6780.220188 | 844.938794 |
| 2014-01-11 | 858.20000 | 918.05471 | 857.16554 | 899.84105 | 18.748285 | 16698.566929 | 890.671709 |
La prochaine étape est de faire une simple table pour vérifier la véracité des données à l'aide d'une méthode visuelle.
# 做出BTC价格的表格
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
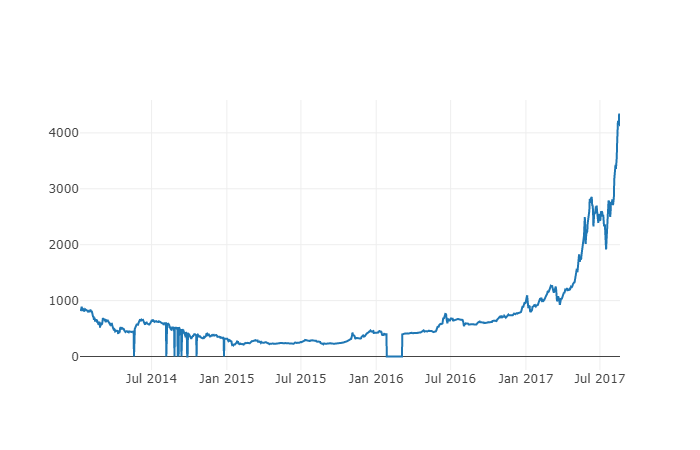
这里,我们用Plotly来完成可视化部分。相对于使用一些更成熟的Python数据可视化库,比如Matplotlib,用Plotly是一个不那么普遍的选择,但Plotly确实是一个不错的选择,因为它可以调用D3.js的充分交互式图表。这些图表有非常漂亮的默认设置,易于探索,而且非常方便嵌入到网页中。
Petit conseil: les graphiques générés peuvent être comparés aux graphiques de prix Bitcoin des échanges traditionnels (comme ceux sur OKEX, Binance ou Huobi) pour un contrôle d'intégrité rapide afin de confirmer que les données téléchargées sont globalement cohérentes.
2.3 Obtenir des données sur les prix des principaux échanges Bitcoin
Les lecteurs attentifs ont peut-être remarqué qu'il y avait des données manquantes dans les données ci-dessus, en particulier à la fin de 2014 et au début de 2016.
Les échanges de crypto-monnaie sont caractérisés par le fait que les relations d'offre et de demande déterminent le prix de la monnaie. Par conséquent, aucun prix de transaction n'est en mesure de devenir le prix dominant du marché. Pour résoudre ce problème, ainsi que le problème de l'absence de données mentionné précédemment (peut-être due à des pannes techniques et à des erreurs de données), nous allons télécharger des données des trois principaux échanges de bitcoins dans le monde et calculer le prix moyen du bitcoin.
Commençons par télécharger les données de chaque échange dans une pile de données composée de types de dictionnaires.
# 下载COINBASE,BITSTAMP和ITBIT的价格数据
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_df
2.4 Intégrer toutes les données dans une pile
Dans la prochaine étape, nous allons définir une fonction spéciale pour fusionner les colonnes partagées dans chaque colonne de données dans une nouvelle colonne de données.
def merge_dfs_on_column(dataframes, labels, col):
'''Merge a single column of each dataframe into a new combined dataframe'''
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
Maintenant, les prix de la couche de couches sur la base des différents ensembles de données sont classés et tous les couches de données sont regroupées.
# 整合所有数据帧
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
Enfin, nous utilisons la méthode de la queue de queue pour examiner les cinq dernières lignes de données après la fusion afin de nous assurer que les données sont correctes et complètes.
btc_usd_datasets.tail()
Les résultats sont les suivants:
| BTC | Le BITSTAMP | Nom de l'entreprise | Le projet ITBIT | Je vous en prie. |
|---|---|---|---|---|
| 2017-08-14 | 4210.154943 | 4213.332106 | 4207.366696 | 4213.257519 |
| 2017-08-15 | 4101.447155 | 4131.606897 | 4127.036871 | 4149.146996 |
| 2017-08-16 | 4193.426713 | 4193.469553 | 4190.104520 | 4187.399662 |
| 2017-08-17 | 4338.694675 | 4334.115210 | 4334.449440 | 4346.508031 |
| 2017-08-18 | 4182.166174 | 4169.555948 | 4175.440768 | 4198.277722 |
Comme vous pouvez le voir sur le graphique ci-dessus, ces données sont conformes à nos attentes, la portée des données étant à peu près la même, mais légèrement différente selon les délais ou les caractéristiques de chaque échange.
2.5 Processus de visualisation des données sur les prix
Logiquement, la prochaine étape consiste à comparer ces données par visualisation. Pour cela, nous devons d'abord définir une fonction auxiliaire, appelée df_scatter.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
'''Generate a scatter plot of the entire dataframe'''
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
# 每个系列的表格跟踪
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
# 为系列添加单独的轴
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
Pour vous faciliter la compréhension, nous n'examinerons pas trop la logique de cette fonctionnalité auxiliaire. Pour en savoir plus, consultez les manuels officiels de Pandas et Plotly.
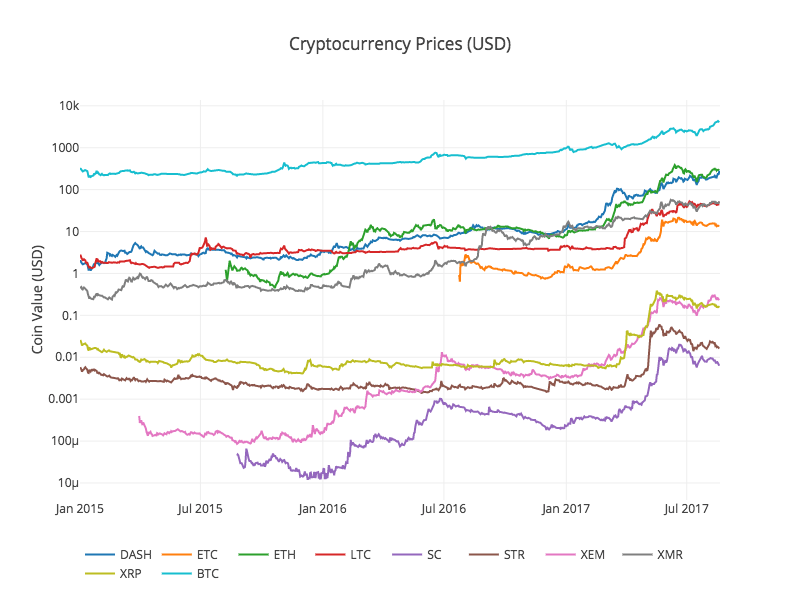
Maintenant, nous pouvons facilement créer un graphique des données sur le prix du Bitcoin!
# 绘制所有BTC交易价格
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
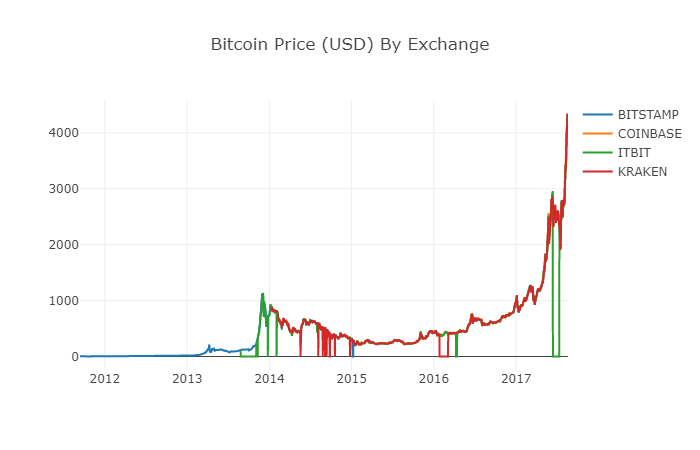
2.6 Nettoyer et ajouter les données de prix totaux
Comme vous pouvez le voir sur le graphique ci-dessus, bien que ces quatre séries de données suivent à peu près le même chemin, il y a des variations irrégulières, et nous allons essayer de les éliminer.
Pendant la période 2012-2017, nous savons que le prix de Bitcoin n'a jamais été égal à zéro, donc nous avons supprimé tous les zéros de la zone de données.
# 清除"0"值
btc_usd_datasets.replace(0, np.nan, inplace=True)
Après avoir reconstruit la pile de données, nous pouvons voir des graphiques plus clairs, sans aucune situation de données manquantes.
# 绘制修订后的数据框
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
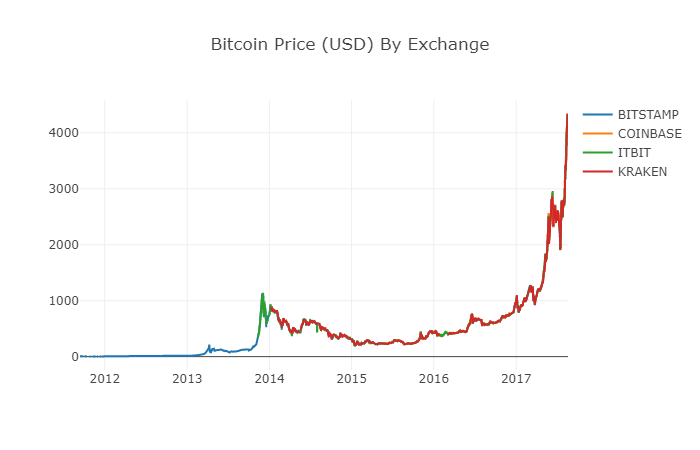
Nous pouvons maintenant calculer une nouvelle colonne: le prix moyen quotidien du bitcoin sur tous les échanges.
# 将平均BTC价格计算为新列
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
La nouvelle colonne est l'indice de prix du Bitcoin! Nous l'avons dessiné pour voir si les données semblent avoir un problème.
# 绘制平均BTC价格
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])
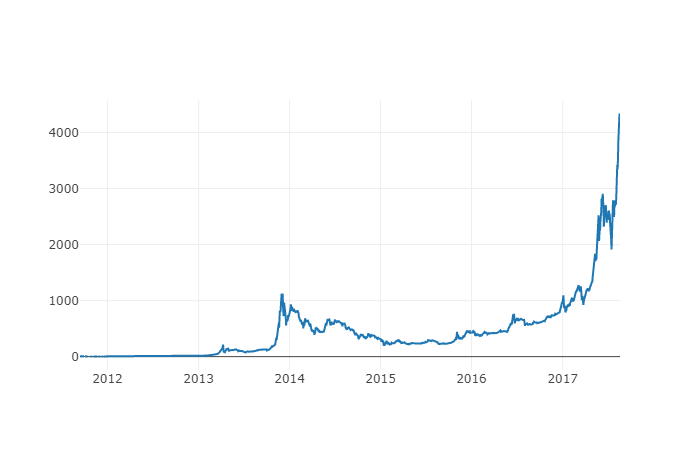
Il semble que cela ne pose pas de problème, et nous continuerons à utiliser ces données de séquence de prix cumulées plus tard pour déterminer les taux de conversion entre d'autres crypto-monnaies et le dollar.
Troisième étape: collecter les prix des altcoins
À ce stade, nous avons des données chronologiques sur le prix du Bitcoin. Nous allons maintenant examiner certaines données sur les monnaies numériques non-Bitcoin, à savoir les altcoins, bien sûr, le terme altcoin peut être un peu exagéré, mais en ce qui concerne l'évolution des monnaies numériques actuelles, à l'exception des dix premières monnaies en valeur marchande telles que Bitcoin, Ethereum, EOS, USDT, etc., la plupart peuvent être qualifiées de monnaies sans problème, et nous devrions nous éloigner autant que possible de ces monnaies lors des transactions, car elles sont trop déroutantes et trompeuses.
3.1 Définition des fonctions auxiliaires par l'intermédiaire de l'API de Poloniex
Tout d'abord, nous avons utilisé l'API de l'échange Poloniex pour obtenir des informations sur les transactions de crypto-monnaie. Nous avons défini deux fonctions auxiliaires pour obtenir les données relatives aux crypto-monnaies, qui sont principalement le téléchargement et la mise en cache des données JSON via l'API.
Tout d'abord, nous définissons la fonction get_json_data, qui télécharge et cache les données JSON à partir d'une URL donnée.
def get_json_data(json_url, cache_path):
'''Download and cache JSON data, return as a dataframe.'''
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached {} at {}'.format(json_url, cache_path))
return df
Ensuite, nous définissons une nouvelle fonction qui générera une requête HTTP de l'API Polonix et qui appellera la fonction get_json_data qui vient d'être définie pour enregistrer les résultats de l'appel.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # 从2015年开始获取数据
end_date = datetime.now() # 直到今天
pediod = 86400 # pull daily data (86,400 seconds per day)
def get_crypto_data(poloniex_pair):
'''Retrieve cryptocurrency data from poloniex'''
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_df
La fonction ci-dessus extrait le code de caractère de l'appariement de la monnaie numérique (par exemple, le code BTC_ETH) et renvoie une pile de données contenant les deux prix historiques de la monnaie.
3.2 Télécharger des données de prix de transaction à partir de Poloniiex
La plupart des crypto-monnaies ne peuvent pas être achetées directement en dollars, les individus doivent généralement acheter des bitcoins avant de les échanger en crypto-monnaies en fonction du rapport de prix entre eux. Nous devons donc télécharger le taux de change de chaque crypto-monnaie pour les bitcoins, puis les convertir en dollars à l'aide des données existantes sur les prix des bitcoins. Nous téléchargerons les données de transaction des 9 crypto-monnaies les plus performantes: Ethereum, Litecoin, Ripple, EthereumClassic, Stellar, Dash, Siacoin, Monero et NEM.
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_df
Aujourd'hui, nous avons un dictionnaire qui contient neuf tranches de données, chacune contenant des données sur les prix moyens historiques quotidiens entre les crypto-monnaies et le bitcoin.
Nous pouvons déterminer si les données sont correctes à partir des dernières lignes de la table des prix Ethereum.
altcoin_data['ETH'].tail()
| ETH | Il est ouvert. | Très haut | Faible | Je suis proche. | Le volume (BTC) | Volume (monnaie) | Prix pondéré |
|---|---|---|---|---|---|---|---|
| 2017-08-18 | 0.070510 | 0.071000 | 0.070170 | 0.070887 | 17364.271529 | 1224.762684 | 0.070533 |
| 2017-08-18 | 0.071595 | 0.072096 | 0.070004 | 0.070510 | 26644.018123 | 1893.136154 | 0.071053 |
| 2017-08-18 | 0.071321 | 0.072906 | 0.070482 | 0.071600 | 39655.127825 | 2841.549065 | 0.071657 |
| 2017-08-19 | 0.071447 | 0.071855 | 0.070868 | 0.071321 | 16116.922869 | 1150.361419 | 0.071376 |
| 2017-08-19 | 0.072323 | 0.072550 | 0.071292 | 0.071447 | 14425.571894 | 1039.596030 | 0.072066 |
3.3 Unifier toutes les données de prix en dollars
Maintenant, nous pouvons combiner les données de BTC et de Bitcoin avec notre indice de prix Bitcoin pour calculer directement le prix historique de chaque Bitcoin (unité: USD).
# 将USD Price计算为每个altcoin数据帧中的新列
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
Ici, nous ajoutons une nouvelle colonne pour chaque pile de données de crypto-monnaie afin de stocker son prix en dollars correspondant.
Ensuite, nous pouvons réutiliser la fonction merge_dfs_on_column définie précédemment pour créer une pile de données fusionnée qui intègre les prix en dollars de chaque crypto-monnaie.
# 将每个山寨币的美元价格合并为单个数据帧
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
Ça y est!
Maintenant, ajoutons le prix du Bitcoin comme dernier élément à la pile de données fusionnée.
# 将BTC价格添加到数据帧
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
Maintenant, nous avons une pile de données unique qui contient les prix quotidiens en dollars des dix monnaies numériques que nous vérifions.
Nous avons réutilisé la fonction df_scatter précédente pour afficher les prix correspondants de toutes les pièces sous forme de graphiques.
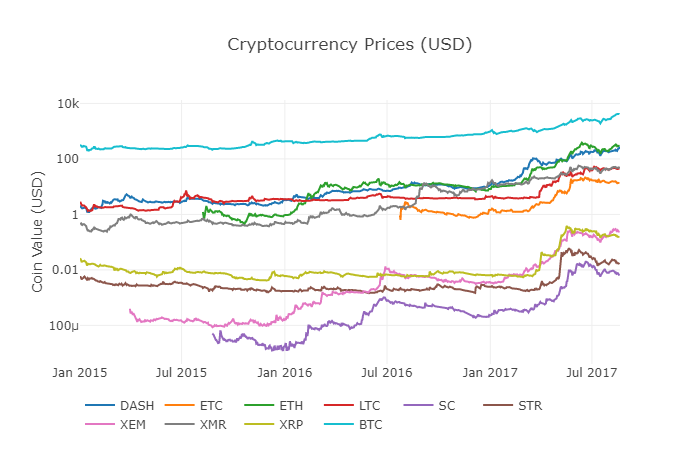
Ce graphique nous donne une vue d'ensemble des variations des prix de chaque crypto-monnaie au cours des dernières années.
Remarque: ici, nous utilisons l'axe y des spécifications de l'algorithme pour comparer toutes les monnaies numériques sur le même graphique. Vous pouvez également essayer d'autres valeurs de paramètres différentes (par exemple, scale =
3.4 Commencez une analyse de la pertinence
Un lecteur attentif peut remarquer que les prix des crypto-monnaies semblent être liés, malgré la grande différence de valeur et la grande volatilité de leurs devises.
Bien sûr, les conclusions fondées sur des données sont plus convaincantes que les intuitions basées sur des images.
Nous pouvons utiliser la fonction Panda's corr () pour vérifier l'hypothèse de corrélation ci-dessus. Cette méthode de vérification calcule le coefficient de relation Pearson correspondant à l'autre coefficient pour chaque pile de données.
Note de modification du 22.8.2017: Cette partie a été modifiée afin d'utiliser la valeur absolue du taux de rendement quotidien au lieu de la valeur du prix pour calculer les coefficients associés.
Un calcul direct basé sur une séquence de temps non statique (par exemple, des données de prix primitives) peut entraîner une déviation des coefficients de corrélation. Notre solution à ce problème est d'utiliser la méthode pct_change (), qui convertit la valeur absolue de chaque prix dans l'arbre de données en un taux de rendement quotidien correspondant.
Par exemple, nous allons calculer les coefficients correspondants pour 2016.
# 计算2016年数字货币的皮尔森相关系数
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')
| Nom | DASH | Le secteur privé | ETH | LTC | SC | RTE | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.003992 | 0.122695 | -0.012194 | 0.026602 | 0.058083 | 0.014571 | 0.121537 | 0.088657 | -0.014040 |
| Le secteur privé | 0.003992 | 1.000000 | -0.181991 | -0.131079 | -0.008066 | -0.102654 | -0.080938 | -0.105898 | -0.054095 | -0.170538 |
| ETH | 0.122695 | -0.181991 | 1.000000 | -0.064652 | 0.169642 | 0.035093 | 0.043205 | 0.087216 | 0.085630 | -0.006502 |
| LTC | -0.012194 | -0.131079 | -0.064652 | 1.000000 | 0.012253 | 0.113523 | 0.160667 | 0.129475 | 0.053712 | 0.750174 |
| SC | 0.026602 | -0.008066 | 0.169642 | 0.012253 | 1.000000 | 0.143252 | 0.106153 | 0.047910 | 0.021098 | 0.035116 |
| RTE | 0.058083 | -0.102654 | 0.035093 | 0.113523 | 0.143252 | 1.000000 | 0.225132 | 0.027998 | 0.320116 | 0.079075 |
| XEM | 0.014571 | -0.080938 | 0.043205 | 0.160667 | 0.106153 | 0.225132 | 1.000000 | 0.016438 | 0.101326 | 0.227674 |
| XMR | 0.121537 | -0.105898 | 0.087216 | 0.129475 | 0.047910 | 0.027998 | 0.016438 | 1.000000 | 0.027649 | 0.127520 |
| XRP | 0.088657 | -0.054095 | 0.085630 | 0.053712 | 0.021098 | 0.320116 | 0.101326 | 0.027649 | 1.000000 | 0.044161 |
| BTC | -0.014040 | -0.170538 | -0.006502 | 0.750174 | 0.035116 | 0.079075 | 0.227674 | 0.127520 | 0.044161 | 1.000000 |
Le graphique ci-dessus montre tous les coefficients relatifs. Les coefficients proches de 1 ou de -1 signifient respectivement que la séquence est liée positivement ou inversement, et les coefficients relatifs proches de 0 indiquent que les objets correspondants ne sont pas liés et que leurs fluctuations sont indépendantes les unes des autres.
Nous avons créé une nouvelle fonctionnalité d'aide à la visualisation pour une meilleure présentation des résultats.
def correlation_heatmap(df, title, absolute_bounds=True):
'''Plot a correlation heatmap for the entire dataframe'''
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
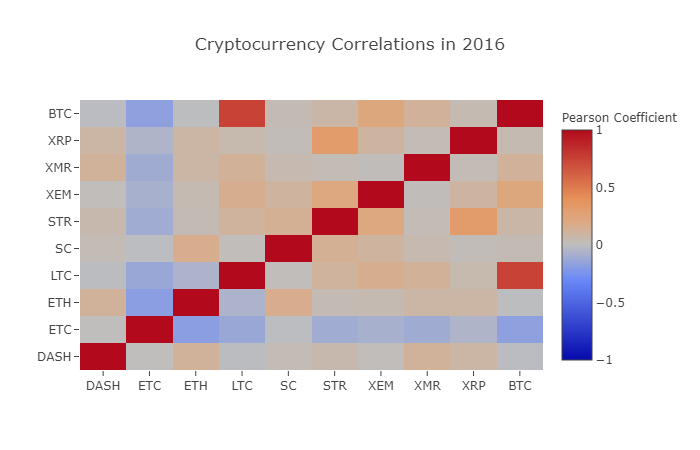
Ici, les valeurs en rouge foncé représentent une forte correlation (chaque monnaie est clairement liée à sa propre hauteur) et les valeurs en bleu foncé représentent une correlation inverse. Toutes les couleurs intermédiaires - bleu clair/orange/gris/brun - représentent des valeurs de faible correlation ou non-corrélation à des degrés divers.
Ce graphique montre que les prix des différentes crypto-monnaies ont essentiellement fluctué au cours de l'année 2016 et qu'il n'y a pratiquement aucune corrélation statistiquement significative.
Maintenant, afin de vérifier notre hypothèse de l'augmentation de la pertinence des crypto-monnaies au cours des derniers mois, nous allons répéter le même test en utilisant des données commençant en 2017.
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')
| Nom | DASH | Le secteur privé | ETH | LTC | SC | RTE | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.384109 | 0.480453 | 0.259616 | 0.191801 | 0.159330 | 0.299948 | 0.503832 | 0.066408 | 0.357970 |
| Le secteur privé | 0.384109 | 1.000000 | 0.602151 | 0.420945 | 0.255343 | 0.146065 | 0.303492 | 0.465322 | 0.053955 | 0.469618 |
| ETH | 0.480453 | 0.602151 | 1.000000 | 0.286121 | 0.323716 | 0.228648 | 0.343530 | 0.604572 | 0.120227 | 0.421786 |
| LTC | 0.259616 | 0.420945 | 0.286121 | 1.000000 | 0.296244 | 0.333143 | 0.250566 | 0.439261 | 0.321340 | 0.352713 |
| SC | 0.191801 | 0.255343 | 0.323716 | 0.296244 | 1.000000 | 0.417106 | 0.287986 | 0.374707 | 0.248389 | 0.377045 |
| RTE | 0.159330 | 0.146065 | 0.228648 | 0.333143 | 0.417106 | 1.000000 | 0.396520 | 0.341805 | 0.621547 | 0.178706 |
| XEM | 0.299948 | 0.303492 | 0.343530 | 0.250566 | 0.287986 | 0.396520 | 1.000000 | 0.397130 | 0.270390 | 0.366707 |
| XMR | 0.503832 | 0.465322 | 0.604572 | 0.439261 | 0.374707 | 0.341805 | 0.397130 | 1.000000 | 0.213608 | 0.510163 |
| XRP | 0.066408 | 0.053955 | 0.120227 | 0.321340 | 0.248389 | 0.621547 | 0.270390 | 0.213608 | 1.000000 | 0.170070 |
| BTC | 0.357970 | 0.469618 | 0.421786 | 0.352713 | 0.377045 | 0.178706 | 0.366707 | 0.510163 | 0.170070 | 1.000000 |
Est-ce que ces chiffres sont plus pertinents? Est-ce qu'ils sont suffisants pour juger de l'investissement?
Cependant, il est intéressant de noter que presque toutes les monnaies numériques sont devenues de plus en plus interconnectées.
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")
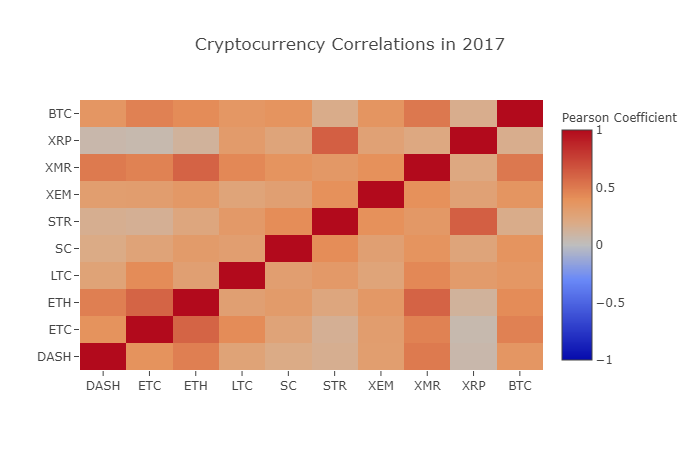
Comme vous pouvez le voir sur le graphique ci-dessus, les choses deviennent de plus en plus intéressantes.
Pourquoi cela arrive-t-il?
C'est une bonne question! Mais en fait, je ne suis pas vraiment sûr...
Ma première réaction a été que les hedge funds ont récemment commencé à négocier publiquement sur les marchés de crypto-monnaie. Ces fonds détiennent beaucoup plus de capital que les traders ordinaires, et il est logique que cette tendance à la forte corrélation se développe si un fonds utilise une stratégie de trading similaire pour chaque monnaie en fonction de variables indépendantes (par exemple, le marché boursier).
Une meilleure compréhension de XRP et STR
Par exemple, il est évident de voir dans le graphique ci-dessus que XRP (le jeton de Ripple) est le moins lié aux autres crypto-monnaies. Mais il y a une exception notable: STR (le jeton de Stellar, officiellement appelé "Lumens"), est fortement lié à XRP (coefficient de corrélation: 0.62).
Il est intéressant de noter que Stellar et Ripple sont des plates-formes de FinTech très similaires, qui visent à réduire les étapes fastidieuses lors des transferts transnationaux interbancaires. Il est concevable que, compte tenu de la similitude des services blockchain utilisant des jetons, certains grands joueurs et hedge funds pourraient utiliser des stratégies de trading similaires pour leurs investissements sur Stellar et Ripple.
C'est votre tour!
Les explications ci-dessus sont largement spéculatives et vous feriez peut-être mieux. Sur la base de ce que nous avons établi, vous avez des centaines et des milliers de façons différentes de continuer à explorer les histoires cachées dans les données.
Voici quelques conseils que je peux donner aux lecteurs pour faire des recherches plus approfondies dans ces domaines:
- Ajouter plus de données sur les crypto-monnaies pour l'ensemble de l'analyse
- Adaptez la portée et la granularité de l'analyse de la corrélation pour obtenir une vue de tendance optimisée ou grossière.
- La recherche de tendances est centrée sur le volume de transactions ou la recherche de données de la blockchain. Si vous souhaitez prédire les fluctuations futures des prix, vous aurez probablement besoin de données sur les ratios achat/vente par rapport aux données de prix brutes.
- Ajoutez des données de prix sur les actions, les produits et les devises légales pour déterminer lequel d'entre eux est lié à la monnaie numérique (mais n'oubliez pas que le dicton n'a pas de lien de causalité).
- Utilisez le Registre d'événements, GDELT et Google Trends pour quantifier le nombre de phrases en suspens autour d'une crypto-monnaie spécifique.
- Si vous avez des ambitions plus grandes, vous pouvez même envisager d'essayer la formation ci-dessus avec des réseaux de neurones circulaires (RNN).
- Utilisez vos analyses pour créer un robot de trading automatisé, via l'interface de programmation d'applications (API) correspondante, appliquée sur des sites d'échanges tels que Polonix ou Coinbase. Attention: un robot peu performant peut facilement faire disparaître vos actifs instantanément.这里推荐使用发明者量化平台FMZ.COM。
La meilleure partie à propos de Bitcoin, et de la monnaie numérique en général, est sa nature décentralisée, ce qui la rend plus libre et démocratique que n'importe quel autre actif. Vous pouvez partager vos analyses en open source, participer à la communauté ou écrire un blog!https://www.fmz.com/bbsJe ne suis pas d'accord avec toi.
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (2)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (2)
- Discussion sur la réception de signaux externes de la plateforme FMZ: une solution complète pour la réception de signaux avec un service Http intégré dans la stratégie
- Exploration de la réception de signaux externes sur la plateforme FMZ: stratégie intégrée pour la réception de signaux sur le service HTTP
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (1)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (1)
- Discussion sur la réception de signaux externes de la plateforme FMZ: API étendue VS stratégie intégrée au service HTTP
- Débat sur la réception de signaux externes sur la plateforme FMZ: API étendue contre stratégie de service HTTP intégré
- Discussion sur la méthode de test de stratégie basée sur le générateur de tickers aléatoires
- Une méthode de test stratégique basée sur un générateur de marché aléatoire
- Nouvelle fonctionnalité de FMZ Quant: Utilisez la fonction _Serve pour créer facilement des services HTTP
- Configuration de l'échange de la stratégie de négociation quantitative de crypto-monnaie
- Mécanisme de correspondance des transactions au niveau du tick développé pour le backtesting de stratégies à haute fréquence
- Expérience dans le développement de stratégies de négociation
- Traitement des données de ligne K dans le commerce quantitatif
- Détails de la configuration des plateformes d'échange de devises numériques
- "Version C++ de la stratégie de couverture des contrats à terme d'OKEX" qui vous emmène à travers une stratégie quantitative hardcore
- Application de la technologie d'apprentissage automatique dans les transactions
- "OKEX Contract Hedging Strategy en C++", qui vous aide à apprendre la stratégie du noyau.
- Une stratégie multi-espaces équilibrée de droits et intérêts
- Des transactions en paire basées sur des technologies basées sur les données
- Une stratégie de transaction quantitative de monnaie numérique à double poussée en Python
- Le traitement des données K-line dans les transactions programmatiques
- Stratégie de négociation quantitative pour l'analyse de la dynamique des prix en Python
- Analyse des données de séquence chronologique et retouche des données Tick
- Développer une stratégie de négociation
- Calcul et application des indicateurs DMI
- Utilisation détaillée et compétences pratiques de l'indicateur de marée énergétique (OBV) dans le commerce quantitatif
- Bibliothèque standard pour la mise au point de stratégies de CTA et la quantification des plateformes d'inventeurs
- Utilisation de la stratégie de la combinaison de l'indice fort et faible par rapport à l'indice normal et au RSI
- Mise à niveau de la stratégie de négociation du canal Keltner
Ruixiao1989L'article est très précieux, j'ai appris, merci.
La bontéMerci pour votre amour!