Tiga gambar tentang cara memahami pembelajaran mesin: konsep dasar, lima genre dan sembilan algoritma umum
Penulis:Penemu Kuantitas - Mimpi Kecil, Dibuat: 2017-05-02 14:49:49, Diperbarui:Tiga gambar tentang cara memahami pembelajaran mesin: konsep dasar, lima genre dan sembilan algoritma umum
- #### ## ### ### ## ### ### ### ### ### #### ### #### ### #### ### ####

Apa itu pembelajaran mesin?
Mesin belajar dengan menganalisis sejumlah besar data. Sebagai contoh, tanpa perlu diprogram untuk mengenali kucing atau wajah, mereka dapat dilatih dengan menggunakan gambar untuk mengindikasikan dan mengidentifikasi target tertentu.
Hubungan antara pembelajaran mesin dan kecerdasan buatan
Pembelajaran mesin adalah sebuah disiplin penelitian dan algoritma yang berfokus pada mencari pola dalam data dan menggunakan pola-pola tersebut untuk membuat prediksi. Pembelajaran mesin adalah bagian dari bidang kecerdasan buatan, dan saling terkait dengan penemuan pengetahuan dan penambangan data.
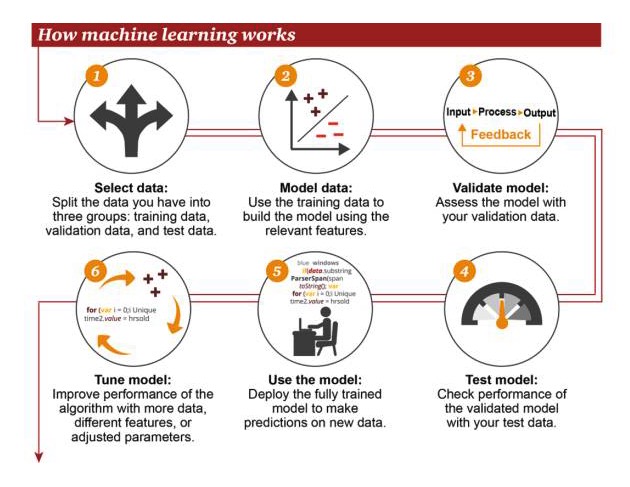
Bagaimana pembelajaran mesin bekerja
1 Pilih data: Pisahkan data Anda menjadi tiga kelompok: data pelatihan, data verifikasi, dan data pengujian 2 Data model: menggunakan data pelatihan untuk membangun model yang menggunakan fitur yang relevan 3 Model validasi: Gunakan data validasi Anda untuk mengakses model Anda 4 Model uji: Gunakan data uji Anda untuk memeriksa kinerja model yang telah diverifikasi 5 Menggunakan model: Menggunakan model terlatih untuk membuat prediksi pada data baru 6 Model tweak: menggunakan lebih banyak data, fitur yang berbeda, atau parameter yang disesuaikan untuk meningkatkan kinerja algoritma
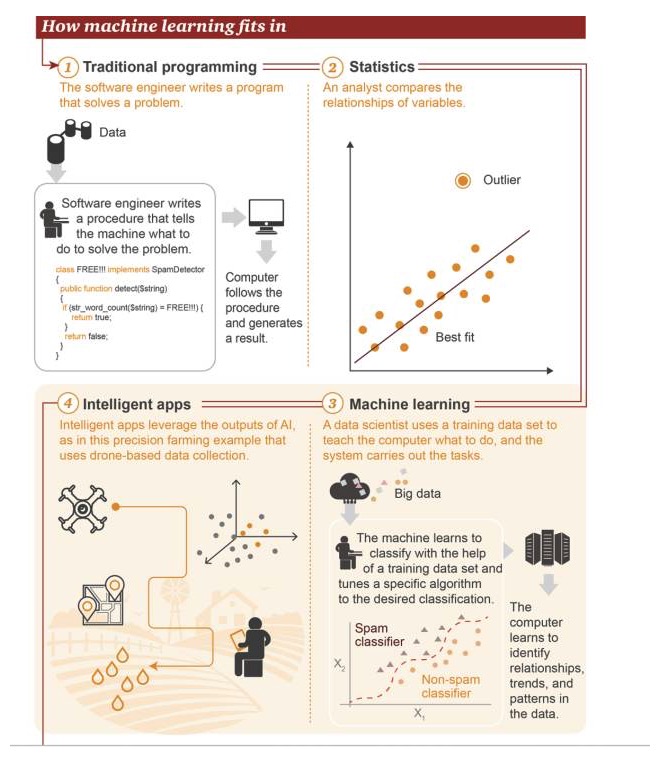
Di mana pembelajaran mesin
1 Pemrograman tradisional: insinyur perangkat lunak menulis program untuk memecahkan masalah. Pertama ada beberapa data→ Untuk memecahkan masalah, insinyur perangkat lunak menulis proses untuk memberitahu mesin bagaimana harus dilakukan→ Komputer mengikuti proses ini, dan kemudian menghasilkan hasil 2 Statistik: Analis membandingkan hubungan antara variabel 3 Pembelajaran mesin: Ilmuwan data menggunakan dataset pelatihan untuk mengajarkan komputer apa yang harus dilakukan, dan kemudian sistem melakukan tugas tersebut. Pertama ada data besar → mesin akan belajar menggunakan dataset pelatihan untuk mengklasifikasikan, menyesuaikan algoritma tertentu untuk mencapai klasifikasi target → komputer dapat belajar mengidentifikasi hubungan, tren, dan pola dalam data 4 Aplikasi cerdas: Hasil aplikasi cerdas menggunakan kecerdasan buatan, seperti yang ditunjukkan pada gambar ini adalah contoh aplikasi pertanian presisi yang didasarkan pada data yang dikumpulkan oleh drone

Aplikasi praktis dari pembelajaran mesin
Ada banyak skenario aplikasi untuk pembelajaran mesin, berikut adalah beberapa contoh, bagaimana Anda akan menggunakannya?
Pemetaan dan pemodelan peta 3D cepat: Untuk membangun jembatan kereta api, para ilmuwan data dan ahli bidang PwC menerapkan pembelajaran mesin pada data yang dikumpulkan oleh drone. Kombinasi ini memungkinkan pemantauan yang akurat dan umpan balik cepat dalam keberhasilan pekerjaan.
Analisis yang ditingkatkan untuk mengurangi risiko: Untuk mendeteksi transaksi internal, PwC menggabungkan pembelajaran mesin dengan teknik analisis lainnya untuk mengembangkan profil pengguna yang lebih komprehensif dan mendapatkan pemahaman yang lebih dalam tentang perilaku yang rumit dan mencurigakan.
Prediksi tujuan kinerja terbaik: PwC menggunakan pembelajaran mesin dan metode analisis lainnya untuk menilai potensi dari kuda-kuda yang berbeda di arena Melbourne Cup.
- #### Kedua, evolusi pembelajaran mesin

Selama beberapa dekade, berbagai "kelompok" peneliti AI telah saling bersaing untuk dominasi. Apakah sekarang saatnya kelompok-kelompok ini bersatu? Mereka mungkin juga harus melakukannya, karena kerja sama dan penggabungan algoritma adalah satu-satunya cara untuk mencapai kecerdasan buatan yang benar-benar universal (AGI).
Lima Jenis
1 Simbolisme: menggunakan simbol, aturan dan logika untuk menggambarkan pengetahuan dan melakukan penalaran logis, algoritma favorit adalah: aturan dan pohon keputusan 2 Bayesian: Mendapatkan kemungkinan terjadi untuk melakukan penalaran probabilitas, algoritma favorit adalah: Bayesian polos atau Markov 3 Kesatuanisme: menggunakan matriks probabilitas dan neuron yang ditimbang untuk secara dinamis mengenali dan mengindikasikan pola, algoritma favorit adalah: Jaringan saraf 4 Evolusi: Menghasilkan perubahan dan kemudian mengambil yang terbaik untuk tujuan tertentu, algoritma favorit adalah: algoritma genetik 5 Analogizer: untuk mengoptimalkan fungsi sesuai dengan kondisi kendala ((pergi setinggi mungkin, tetapi pada saat yang sama jangan pergi dari jalan), algoritma favorit adalah: mendukung mesin vektor
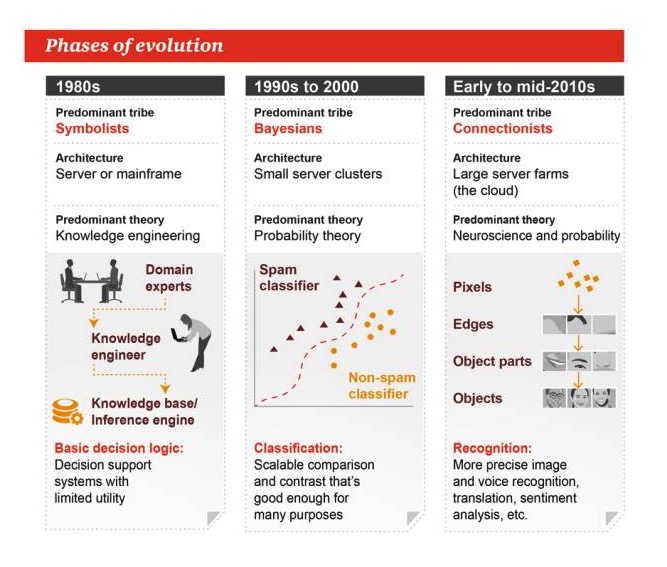
Tahap Evolusi
Tahun 1980-an
Genre utama: Simbolisme Arsitektur: server atau mesin besar Teori utama: Teknik Pengetahuan Logika keputusan dasar: sistem pendukung keputusan, kegunaan terbatas
Tahun 1990-an sampai 2000
Genre utama: Bayes Arsitektur: Kelompok server kecil Teori utama: teori probabilitas Kategori: Perbandingan atau kontras yang dapat diperluas, cukup baik untuk banyak tugas
Awal hingga pertengahan tahun 2010
Gender yang dominan: Solidarisme Arsitektur: Pertanian Server Besar Teori utama: Neuroscience dan Probabilitas Pengakuan: Pengakuan gambar dan suara yang lebih akurat, penerjemahan, analisis emosi, dll.
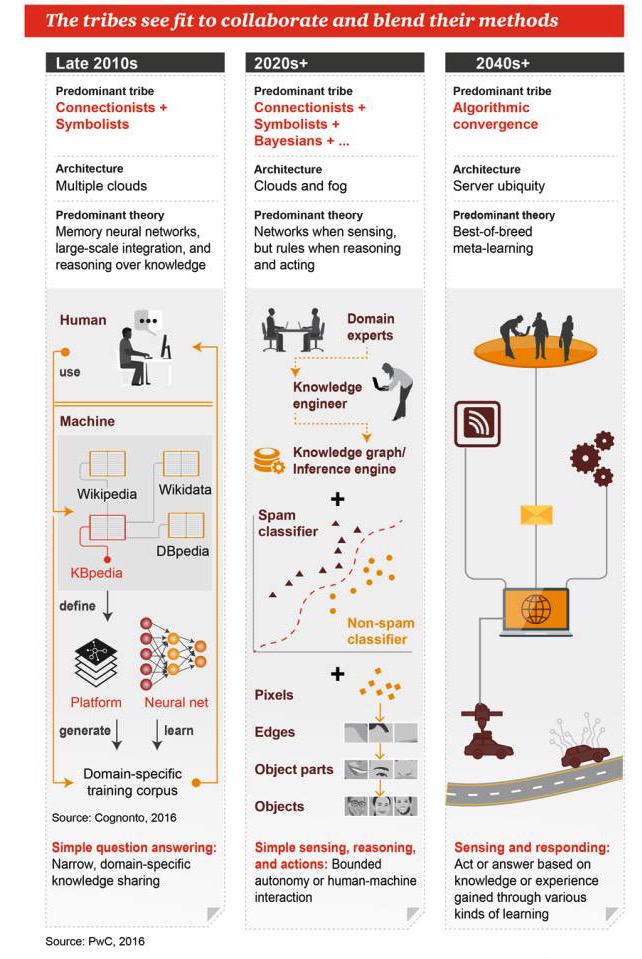
Di sini, para penggemar akan melihat bagaimana mereka bekerja sama dan menggabungkan pendekatan mereka masing-masing.
Akhir tahun 2010
Genre utama: Unionis + Simbolis Arsitektur: Banyak Awan Teori utama: jaringan saraf memori, integrasi besar-besaran, penalaran berbasis pengetahuan Jawaban sederhana: berbagi pengetahuan yang sempit dan spesifik
Tahun 2020+
Garis utama: Unionisme + Simbolisme + Bayes +... Arsitektur: komputasi awan dan komputasi kabut Teori dominan: ada jaringan saat persepsi, ada aturan saat penalaran dan kerja Persepsi, penalaran, dan tindakan sederhana: otomatisasi atau interaksi manusia-robot terbatas
Tahun 2040+
Genre yang dominan: algoritma yang berkolaborasi Arsitektur: Server di mana-mana Teori yang mendominasi: kombinasi terbaik dari meta-learning Persepsi dan respons: bertindak atau memberikan jawaban berdasarkan pengetahuan atau pengalaman yang diperoleh melalui berbagai cara belajar
- #### ### ### ### ### ### ### ### ### ### ### ### #### #### #### #### #### #### #### ##### ##### ##### #### ### #### ### ### ### ### ### ##### #### #### #### ### #### ### ##### ### #### ### ### ##### ### #### ###

Algoritma pembelajaran mesin mana yang harus Anda gunakan? Hal ini sangat tergantung pada sifat dan jumlah data yang tersedia dan tujuan pelatihan Anda dalam setiap kasus penggunaan tertentu. Jangan menggunakan algoritma yang paling rumit kecuali hasilnya layak membayar biaya dan sumber daya yang mahal.
Pohon Keputusan: Dalam proses respon bertahap, analisis pohon keputusan yang khas menggunakan variabel atau node keputusan yang terlapis, misalnya untuk mengklasifikasikan pengguna tertentu sebagai kredibel atau tidak kredibel.
Keunggulan: Mampu menilai berbagai karakteristik, kualitas, dan sifat orang, tempat, dan benda Contoh skenario: penilaian kredit berdasarkan aturan, prediksi hasil balap
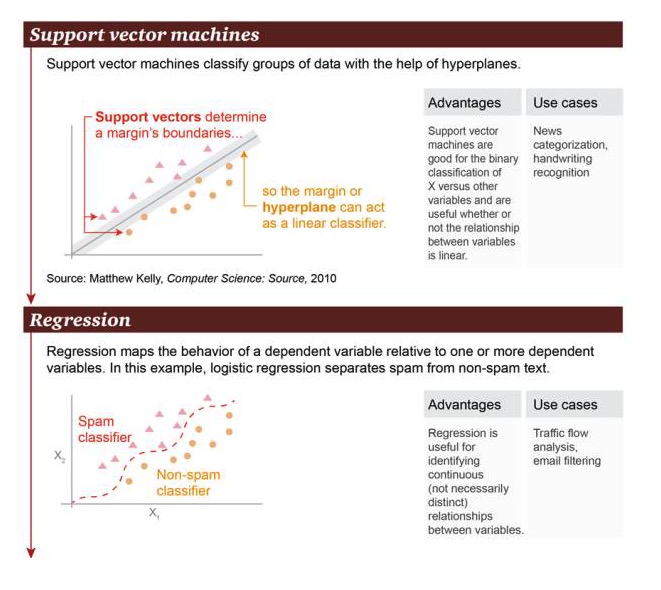
Mendukung mesin vektor: Berdasarkan hyperplane, mendukung mesin vektor untuk mengelompokkan data set.
Keuntungan: Mendukung mesin vektor yang ahli dalam melakukan operasi klasifikasi biner antara variabel X dan variabel lainnya, terlepas dari apakah hubungannya linier atau tidak Contoh skenario: Klasifikasi berita, pengenalan tulisan tangan.
Regression: Regression dapat menggambar hubungan status antara variabel penyebab dan satu atau lebih variabel penyebab. Dalam contoh ini, perbedaan antara spam dan non-spam dilakukan.
Keuntungan: Regresi dapat digunakan untuk mengidentifikasi hubungan kontinu antara variabel, bahkan jika hubungan itu tidak sangat jelas Contoh skenario: analisis lalu lintas jalan, penyaringan email
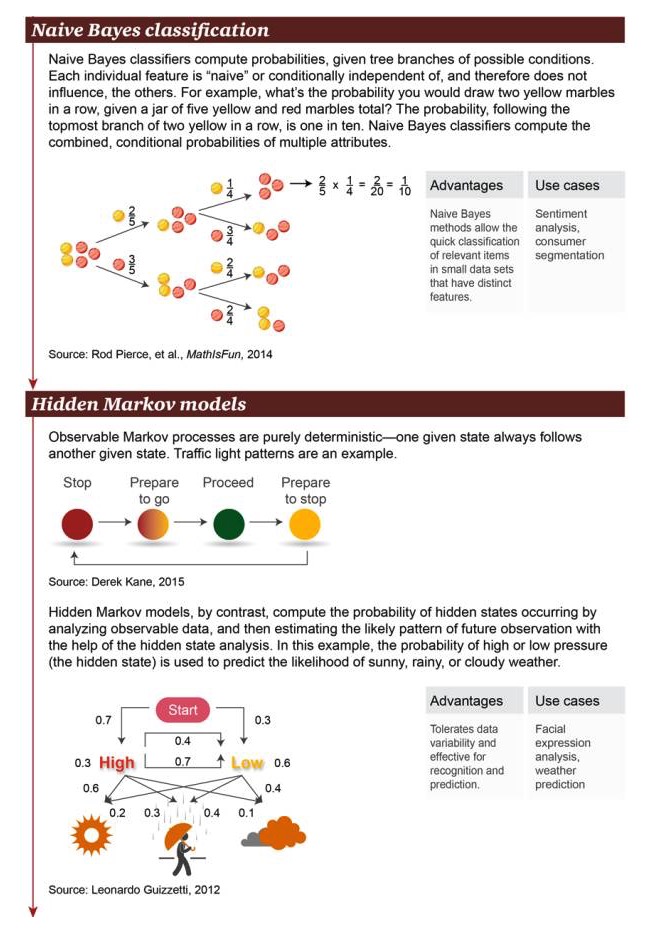
Classifikasi Bayes Naif: Classifier Bayes Naif digunakan untuk menghitung probabilitas cabang dari kondisi yang mungkin. Setiap karakteristik independen adalah "naif" atau independen dari kondisi, sehingga mereka tidak mempengaruhi objek lain. Misalnya, dalam sebuah kotak dengan total 5 bola kuning dan merah, berapa probabilitas dua bola kuning berturut-turut?
Keuntungan: Untuk objek terkait yang memiliki karakteristik yang signifikan dalam kumpulan data kecil, metode Bayesian sederhana memungkinkan untuk mengklasifikasinya dengan cepat Contoh skenario: analisis emosi, klasifikasi konsumen
Model Markov tersembunyi: proses Markov yang menampakkan kepastian penuh bahwa suatu keadaan tertentu seringkali disertai dengan keadaan lain. Lampu lalu lintas adalah contohnya. Sebaliknya, model Markov tersembunyi menghitung kejadian keadaan tersembunyi dengan menganalisis data yang terlihat. Kemudian, dengan analisis keadaan tersembunyi, model Markov tersembunyi dapat memperkirakan pola pengamatan masa depan yang mungkin. Dalam hal ini, probabilitas tekanan udara tinggi atau rendah (yang merupakan keadaan tersembunyi) dapat digunakan untuk memprediksi probabilitas hari yang cerah, hujan, atau mendung.
Keuntungan: Mengizinkan variabilitas data, digunakan untuk pengakuan dan operasi prediksi Contoh skenario: analisis ekspresi wajah, ramalan cuaca
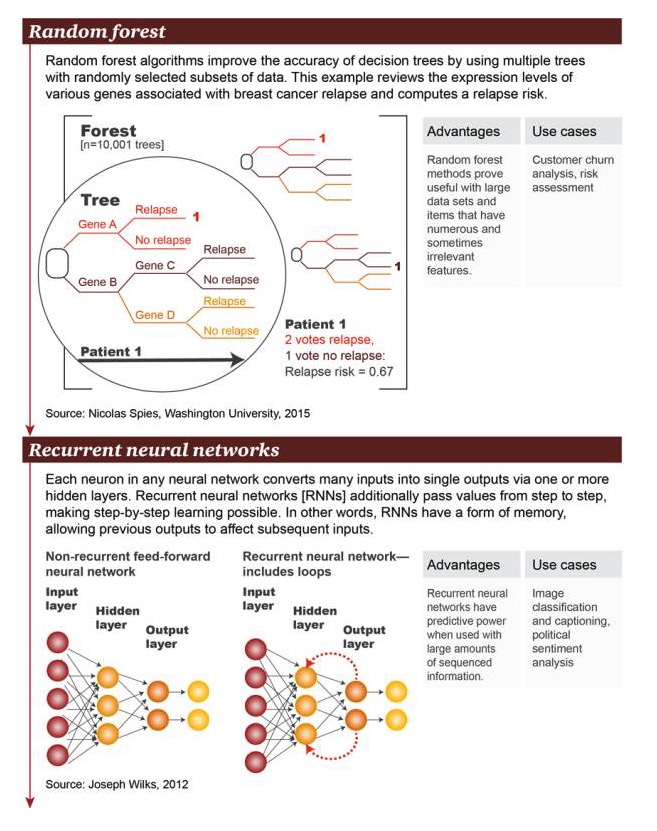
Hutan acak: Algoritma hutan acak meningkatkan keakuratan pohon keputusan dengan menggunakan beberapa pohon dengan subset data yang dipilih secara acak. Contoh ini mengamati sejumlah besar gen yang terkait dengan kambuh kanker payudara pada tingkat ekspresi gen dan menghitung risiko kambuh.
Keuntungan: Metode hutan acak terbukti berguna untuk data set besar dan item yang memiliki banyak dan kadang-kadang fitur yang tidak terkait Contoh skenario: analisis kehilangan pengguna, penilaian risiko
Jaringan syaraf berulang: Dalam jaringan syaraf acak, setiap neuron mengubah banyak input menjadi output tunggal melalui satu atau lebih lapisan tersembunyi. Jaringan syaraf berulang (RNN) akan menyampaikan nilai lebih lanjut melalui lapisan, memungkinkan pembelajaran layer-by-layer. Dengan kata lain, RNN memiliki beberapa bentuk memori yang memungkinkan output sebelumnya mempengaruhi input berikutnya.
Keuntungan: Jaringan saraf sirkulasi memiliki kemampuan untuk memprediksi ketika ada banyak informasi terorganisir Contoh skenario: pengelompokan gambar dan penambahan subtitle, analisis emosi politik

Long short-term memory (LSTM) dan gated recurrent unit neural network (gated recurrent unit neural network): Meskipun RNN awal hanya memungkinkan untuk menyimpan sejumlah kecil informasi awal, jaringan neural baru (LSTM) dan GRU memiliki memori panjang dan pendek. Dengan kata lain, RNN baru ini memiliki kemampuan yang lebih baik untuk mengendalikan memori, yang memungkinkan untuk menyimpan pengolahan sebelumnya atau mengatur ulang nilai-nilai ketika banyak langkah seri diperlukan, yang menghindari degradasi akhir dari nilai-nilai yang dapat "terdegradasi" atau ditransfer secara bertahap.
Keuntungan: Memori jangka pendek panjang dan gerbang kontrol jaringan saraf sel sirkulasi memiliki keuntungan yang sama dengan jaringan saraf sirkulasi lainnya, tetapi lebih sering digunakan karena memiliki kemampuan memori yang lebih baik Contoh skenario: pemrosesan bahasa alami, penerjemahan
Convolutional neural network: Konvolutional neural network adalah konvergensi beban dari lapisan berikutnya yang dapat digunakan untuk menandai lapisan output.
Keuntungan: Jejaring saraf convolutional sangat berguna ketika ada dataset yang sangat besar, banyak fitur, dan tugas klasifikasi yang rumit Contoh skenario: pengenalan gambar, transkripsi suara, penemuan obat
- #### Link aslinya:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Dipindahkan dari Big Data Landscape
- Mengapa perbedaan sudut dapat menunjukkan tingkat disintegrasi?
- Metode untuk menentukan kegagalan model transaksi terprogram
- BitMEX exchange API note untuk BitMEX Exchange API Penggunaan
- Ini menunjukkan perdagangan ekstrim dalam perdagangan tren
- Cara Menggunakan Kode Untuk Memperbaiki Kode Kode
- Strategi Frekuensi Tinggi
- Kesalahan Klasik Pemula Opsi
- Bagaimana Strategi Mesin Pemetik Frekuensi Tinggi Bitcoin No. 1 Terwujud?
- Mengenal seluruh pemangku kepentingan di pasar futures
- Berbagai tren mundur dan strategi
- Keseragaman pembagian yang menentukan keuntungan atau tidak
- 2.14 Cara Menggunakan API Bursa
- Bagaimana pendapat Anda tentang berbagai bangunan mata uang yang baru-baru ini muncul di platform ether dan ether?
- nol
- 6 Tips Untuk Menjaga Masa Depan Anda dengan Aman
- Kata-kata baik dari batu permata untuk perdagangan overnight (trend)
- Pemikiran Bermain
- Rintangan Rumah Tangga
- Sharp Ratio 0.6, apakah harus dibuang?
- Pemungutan suara tidak lebih baik dengan waktu yang lebih lama dan strategi pemungutan suara yang merata