Pasar kutipan kolektor upgrade lagi
Penulis:Kebaikan, Dibuat: 2020-05-26 14:25:15, Diperbarui: 2024-12-10 20:35:48
Mendukung impor file format CSV untuk menyediakan sumber data kustom
Baru-baru ini, seorang pedagang perlu menggunakan file format CSV sendiri sebagai sumber data untuk sistem backtest platform FMZ. sistem backtest platform kami memiliki banyak fungsi dan sederhana dan efisien untuk digunakan, sehingga selama pengguna memiliki data mereka sendiri, mereka dapat melakukan backtesting sesuai dengan data ini, yang tidak lagi terbatas pada pertukaran dan varietas yang didukung oleh pusat data platform kami.
Ide desain
Ide desain sebenarnya sangat sederhana. kita hanya perlu mengubahnya sedikit berdasarkan kolektor pasar sebelumnya. kita menambahkan parameterisOnlySupportCSVuntuk pengumpul pasar untuk mengontrol apakah hanya file CSV yang digunakan sebagai sumber data untuk sistem backtest.filePathForCSVdigunakan untuk mengatur jalur file data CSV yang ditempatkan di server di mana robot market collector berjalan.isOnlySupportCSVParameter diatur untukTrueuntuk memutuskan sumber data mana yang akan digunakan (dikumpulkan oleh diri sendiri atau data dalam file CSV), perubahan ini terutama dido_GETfungsi dariProvider class.
Apa itu file CSV?
Nilai yang dipisahkan oleh koma, juga dikenal sebagai CSV, kadang-kadang disebut sebagai nilai yang dipisahkan oleh karakter, karena karakter pemisah juga tidak bisa menjadi koma. Filenya menyimpan data tabel (angka dan teks) dalam teks biasa. Teks biasa berarti bahwa file adalah urutan karakter dan tidak mengandung data yang harus ditafsirkan seperti angka biner. File CSV terdiri dari sejumlah catatan, dipisahkan oleh beberapa karakter baris baru; setiap catatan terdiri dari bidang, dan pemisah antara bidang adalah karakter atau string lainnya, dan yang paling umum adalah koma atau tab. Secara umum, semua catatan memiliki urutan bidang yang sama persis.WORDPADatauExceluntuk membuka.
Standar umum dari format file CSV tidak ada, tetapi ada aturan tertentu, umumnya satu catatan per baris, dan baris pertama adalah header.
Misalnya, file CSV yang kami gunakan untuk pengujian dibuka dengan Notepad seperti ini:
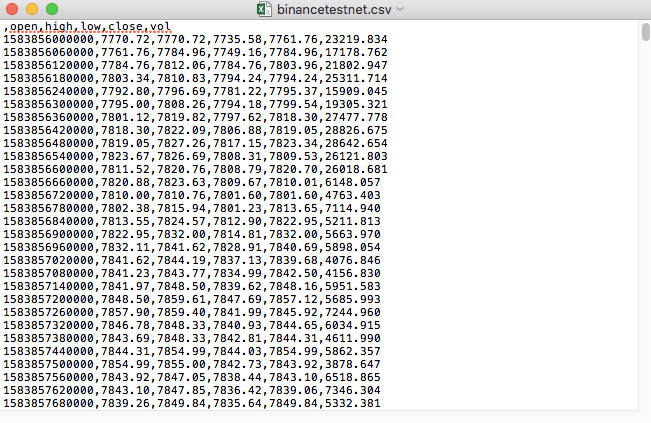
Diperhatikan bahwa baris pertama dari file CSV adalah header tabel.
,open,high,low,close,vol
Kita hanya perlu menganalisis dan menyortir data ini, dan kemudian membangunnya ke dalam format yang dibutuhkan oleh sumber data kustom dari sistem backtest. kode ini dalam artikel sebelumnya telah diproses, dan hanya perlu dimodifikasi sedikit.
Kode yang dimodifikasi
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Uji jalan
Pertama, kita menyalakan robot pengumpul pasar, kita tambahkan pertukaran ke robot dan biarkan robot berjalan.
Konfigurasi parameter:

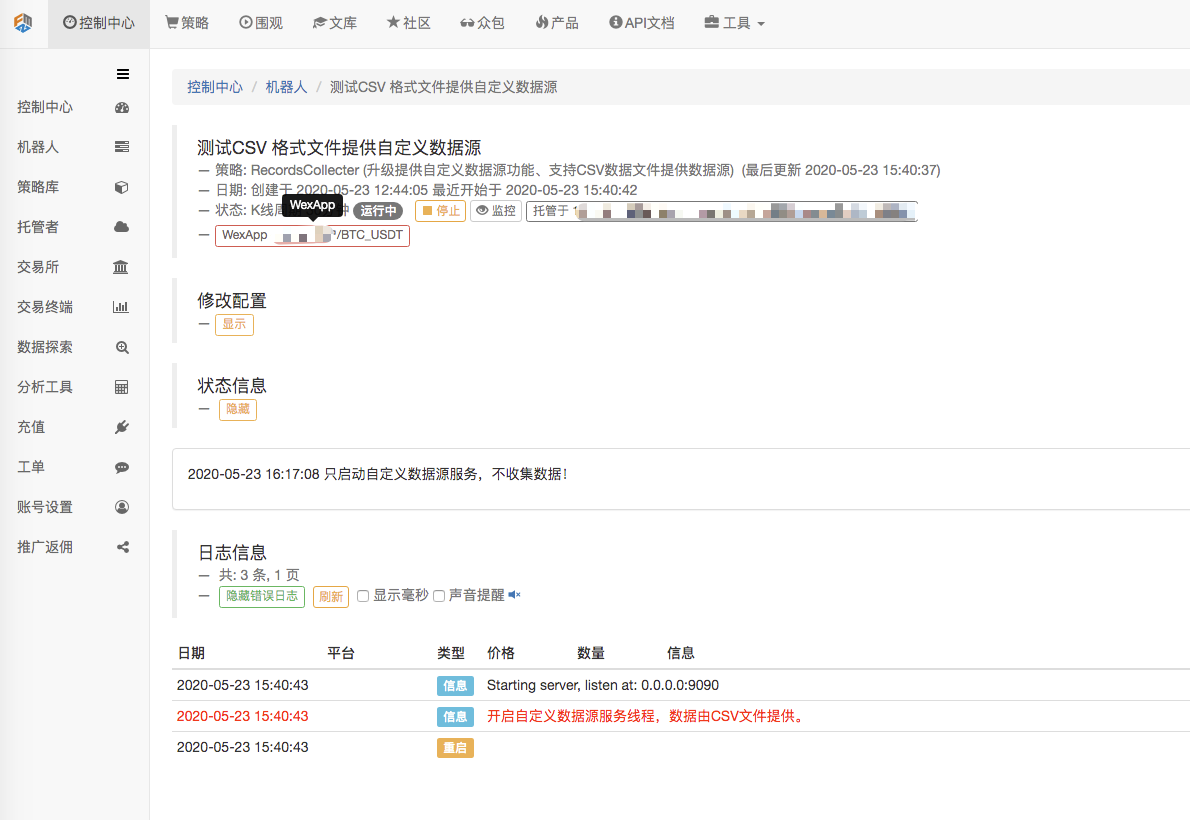
Kemudian kita membuat strategi uji:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
Strategi sangat sederhana, hanya mendapatkan dan mencetak data K-line tiga kali.
Pada halaman backtest, atur sumber data dari sistem backtest sebagai sumber data kustom, dan isi alamat server tempat robot market collector berjalan. karena data dalam file CSV kami adalah garis K 1 menit. jadi ketika backtest, kita atur periode K-line menjadi 1 menit.
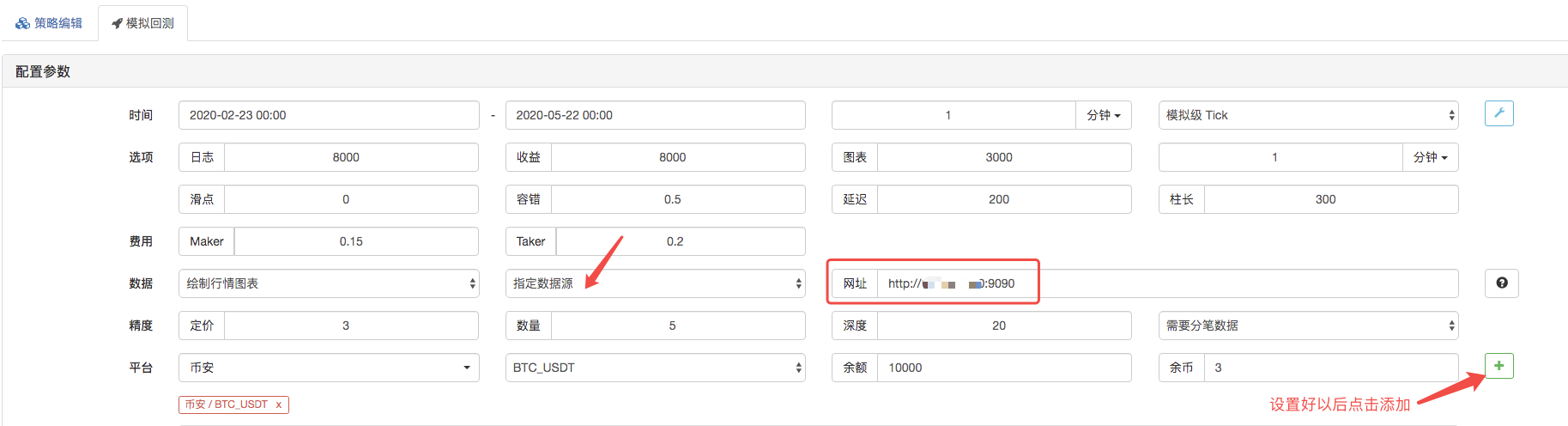
Klik untuk memulai backtest, dan robot pengumpul pasar menerima permintaan data:

Setelah strategi pelaksanaan sistem backtest selesai, grafik garis K dihasilkan berdasarkan data garis K di sumber data.
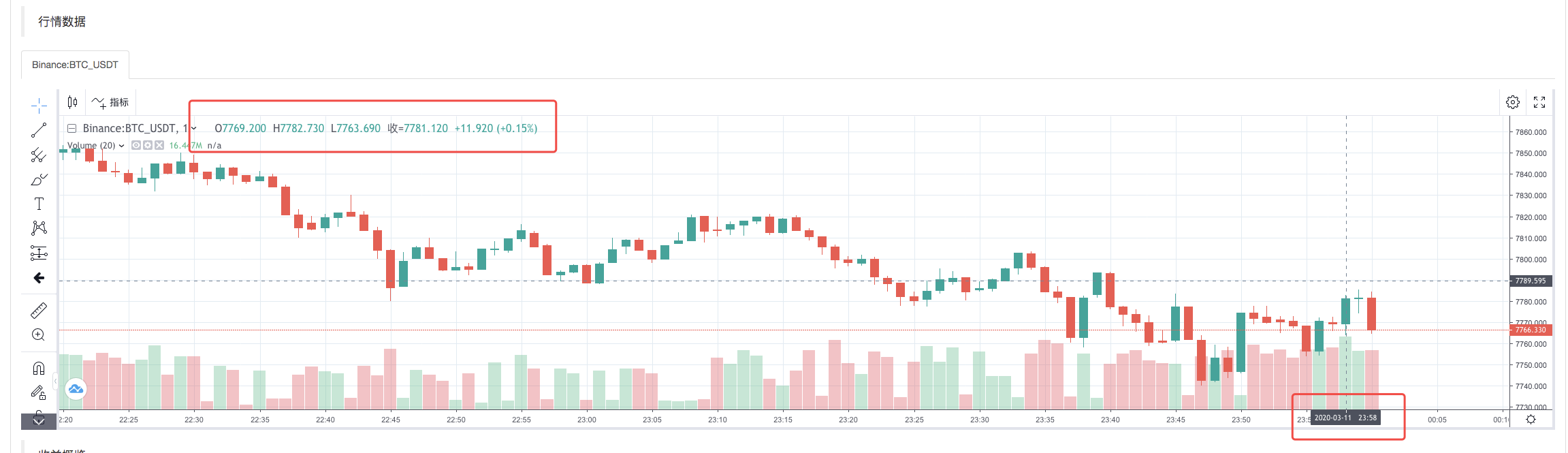
Bandingkan data dalam file:

- Penjelasan tentang suite Lead-Lag dalam mata uang digital (3)
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (2)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (2)
- Pembahasan Penerimaan Sinyal Eksternal Platform FMZ: Solusi Lengkap untuk Penerimaan Sinyal dengan Layanan Http Terbina dalam Strategi
- FMZ platform eksplorasi penerimaan sinyal eksternal: strategi built-in https layanan solusi lengkap untuk penerimaan sinyal
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (1)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (1)
- Diskusi tentang Penerimaan Sinyal Eksternal dari Platform FMZ: API Terluas VS Strategi Layanan HTTP Terintegrasi
- FMZ Platform Eksternal Signal Reception: Extension API vs Strategi Layanan HTTP Terbentuk
- Diskusi tentang Metode Pengujian Strategi Berdasarkan Generator Random Ticker
- Metode pengujian strategi berdasarkan generator pasar acak
- Beberapa Pikiran tentang Logika Perdagangan Berjangka Mata Uang Crypto
- Alat analisis yang ditingkatkan berdasarkan pengembangan tata bahasa Alpha101
- Mengajarkan Anda untuk meningkatkan market collector backtest sumber data kustom
- Cacat dari sistem reverse osmosis frekuensi tinggi dan reverse osmosis linear
- Penjelasan mekanisme backtest tingkat simulasi FMZ
- Cara terbaik untuk menginstal dan meningkatkan FMZ docker pada Linux VPS
- Komoditas Futures R-Breaker Strategy
- Pikirkan Logika Trading Futures Mata Uang Digital
- Mengajarkan Anda untuk menerapkan pasar kutipan kolektor
- Versi Python Komoditas Futures Moving Average Strategi
- Upgrade prosesor - mendukung impor file format CSV untuk menyediakan sumber data yang disesuaikan
- Strategi Trading Frekuensi Tinggi Komoditas Berjangka yang ditulis oleh C++
- Larry Connors RSI2 Rata-rata Strategi Reversi
- Oker handshake mengajarkan Anda menggunakan JS untuk menghubungkan FMZ ekstensi API
- Berdasarkan penggunaan indeks kekuatan relatif baru dalam strategi intraday
- Penelitian tentang Binance Futures Multi-Values Hedging Strategy Bagian 4
- Larry Connors Larry Connors RSI2 Strategi Kembali Rata-rata
- Penelitian tentang Binance Futures Multi-currency Hedging Strategy Bagian 3
- Penelitian tentang Binance Futures Multi-Values Hedging Strategy Bagian 2
- Penelitian tentang Binance Futures Multi-currency Hedging Strategy Bagian 1