ニューラルネットワークとデジタル通貨定量取引シリーズ(2) - ビットコイン取引戦略を訓練するための深層強化学習
 7
5785
7
5785

1. はじめに
前の記事では、LSTMネットワークを使用してビットコインの価格を予測する方法を紹介しました https://www.fmz.com/digest-topic/4035。記事で述べたように、これはRNNとpytorchに慣れるための練習用の小さなプロジェクトにすぎません。 。この記事では、強化学習手法を使用して取引戦略を直接トレーニングする方法を紹介します。強化学習モデルはOpenAIがオープンソース化したPPOで、環境はジムのスタイルに基づいています。理解とテストを容易にするために、LSTM PPO モデルとバックテストジム環境は、既製のパッケージを使用せずに直接記述されています。 PPO は、Proximal Policy Optimization の正式名称であり、Policy Graident、つまりポリシー勾配の最適化の改善です。 GymもOpenAIからリリースされています。ポリシーネットワークと対話し、環境の現在の状態と報酬をフィードバックすることができます。これは、LSTM PPOモデルを使用して、環境の現在の状態に基づいて購入、販売、または操作なしを直接行う強化学習演習のようなものです。ビットコインの市場情報。バックテスト環境から指示が与えられ、戦略の収益性の目標を達成するために、モデルはトレーニングを通じて継続的に最適化されます。 この記事を読むには、Python、pytorch、DRL 深層強化学習に関する一定の基礎知識が必要です。しかし、やり方がわからなくても問題ありません。この記事で紹介したコードを使えば、簡単に学習して始めることができます。この記事は、デジタル通貨定量取引プラットフォーム (www.fmz.com) の発明者である FMZ によって作成されました。コミュニケーションには QQ グループ: 863946592 への参加を歓迎します。
2. データと学習の参考資料
ビットコインの価格データは、FMZの発明家による定量取引プラットフォームから取得されています: https://www.quantinfo.com/Tools/View/4.html DRL+gym を使用して取引戦略をトレーニングする方法に関する記事: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4 Pytorch を使い始めるための例: https://github.com/yunjey/pytorch-tutorial この記事では、LSTM-PPO モデルのこの短い実装を直接使用します: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py PPOに関する記事: https://zhuanlan.zhihu.com/p/38185553 DRLに関するその他の記事: https://www.zhihu.com/people/flood-sung/posts ジムに関しては、この記事ではインストールする必要はありませんが、強化学習は非常に一般的です:https://gym.openai.com/
3.LSTM-PPO
PPO の詳しい説明については、以前の参考文献を参照してください。ここでは、簡単な概念の紹介のみを行います。前回のLSTMネットワークでは価格を予測しただけだった。この予測価格に基づいて売買取引を行う方法は別途実装する必要がある。当然、売買アクションを直接出力した方が直接的であることは想像できる。 、 右? Policy Graident はこんな感じです。入力された環境情報 s に基づいて、さまざまなアクションの確率を与えることができます。 LSTMの損失は予測価格と実際の価格の差であり、PGの損失は-log(p)である。*Q、ここでpはアクションが出力される確率、Qはアクションの値(報酬スコアなど)です。直感的な説明は、アクションの価値が高ければ、ネットワークはより高い確率を出力するはずだということです。損失を減らすためです。 PPO ははるかに複雑ですが、原理は似ています。鍵となるのは、各アクションの価値をより適切に評価し、パラメータをより適切に更新する方法です。
LSTM-PPO のソース コードは以下に示すとおりです。これは、前の情報と組み合わせて理解できます。
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. ビットコインのバックテスト環境
ジムのフォーマットに従って、リセット初期化メソッド、ステップ入力アクションがあり、返される結果は(次の状態、アクションの利点、終了したかどうか、追加情報)です。バックテスト環境全体はわずか60行で、自分で変更しました。複雑なバージョン、特定のコード:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. 注目すべきいくつかの詳細
初期アカウントにコインがあるのはなぜですか?
バックテスト環境でのリターンの計算式は、現在のリターン = 現在のアカウント値 - 初期アカウントの現在の値です。つまり、ビットコインの価格が下がり、戦略がコインを売却した場合、アカウントの合計価値が減少しても、戦略は実際に報酬を得るはずです。バックテスト期間が長い場合、初期アカウントへの影響はそれほど大きくないかもしれませんが、それでも最初は大きな影響があります。相対的なリターンを計算することで、すべての正しい操作が正の報酬を得ることが保証されます。
トレーニング中に市場をサンプリングするのはなぜですか?
データの総量は 10,000 K ラインを超えます。毎回完全なサイクルを実行すると、長い時間がかかり、戦略は毎回まったく同じ状況に直面することになり、過剰適合につながる可能性があります。バックテスト データとして、毎回 500 本のバーが描画されます。オーバーフィッティングの可能性はありますが、この戦略では 10,000 を超える異なる開始が可能です。
コインやお金がない場合はどうすればいいですか?
この状況はバックテスト環境では考慮されていません。コインが売り切れていたり、最小取引量に達していない場合、この時点で売り操作を実行することは実際には操作を実行しないことに相当します。価格が下落した場合、相対的にリターン計算方法は、依然として戦略の正の報酬に基づいています。この状況の影響は、戦略が市場が下落していると判断し、アカウントに残っているコインを売却できない場合、売却アクションと操作なしを区別することは不可能ですが、戦略自体の判断には影響しません。市場。
なぜアカウント情報をステータスとして返すのですか?
PPO モデルには、現在の状態の価値を評価するために使用される価値ネットワークがあります。当然、戦略によって価格が上昇すると判断された場合、現在のアカウントがビットコインを保有している場合にのみ、状態全体が正の値を持ち、その逆も同様です。そのため、アカウント情報はバリューネットワークを判断する上で重要な根拠となります。過去のアクション情報は状態として返されないことに注意してください。これは、価値を判断するのに役に立たないと個人的には思います。
どのような状況で操作なしが返されるのでしょうか?
戦略では、売買による利益が取引手数料をカバーできないと判断した場合、何もしない状態に戻る必要があります。これまでの説明では、価格動向を判断するために戦略を繰り返し使用しましたが、それは理解を容易にするためだけのものでした。実際には、この PPO モデルは市場に関する予測は行わず、3 つのアクションの確率を出力するだけです。
6. データの取得とトレーニング
前回の記事と同様に、データは次の形式で取得されます:2018/5/7 から 2019/6/27 までの Bitfinex 取引所の BTC_USD 取引ペアの 1 時間 K ライン:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
LSTM ネットワークを使用していたため、トレーニング時間が非常に長かったため、約 3 倍高速な GPU バージョンに変更しました。
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. トレーニング結果と分析
長い待ち時間の後:

まずはトレーニングデータの相場動向を見てみましょう。全体的には前半は長い下落傾向で、後半は力強い反発となりました。
トレーニングの初期段階では買い操作が多く、基本的に利益が出るラウンドはありません。トレーニング期間の中盤になると、買い操作の回数は徐々に減り、利益の確率はどんどん大きくなっていきましたが、損失の確率はまだ高かったです。
ラウンドごとの収益を平滑化すると、結果は次のようになります。
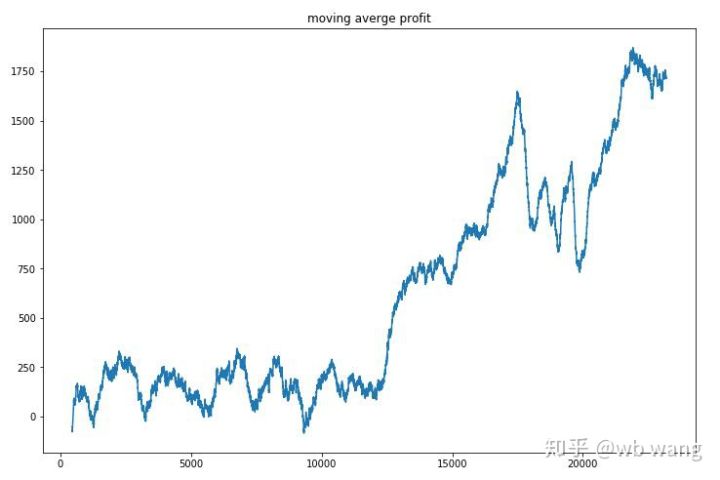
この戦略は、初期段階ではマイナスのリターンをすぐに解消しましたが、変動は大きかったです。リターンが急速に成長し始めたのは、10,000 ラウンドを過ぎてからでした。全体的に、モデルのトレーニングは困難でした。
最終トレーニングが完了したら、モデルにすべてのデータを再度実行させてパフォーマンスを確認します。この期間中、アカウントの合計市場価値、保有ビットコインの数、ビットコイン価値の割合、および総収入を記録します。 。
まず、総市場価値です。総収益は似たようなものなので、ここでは掲載しません。
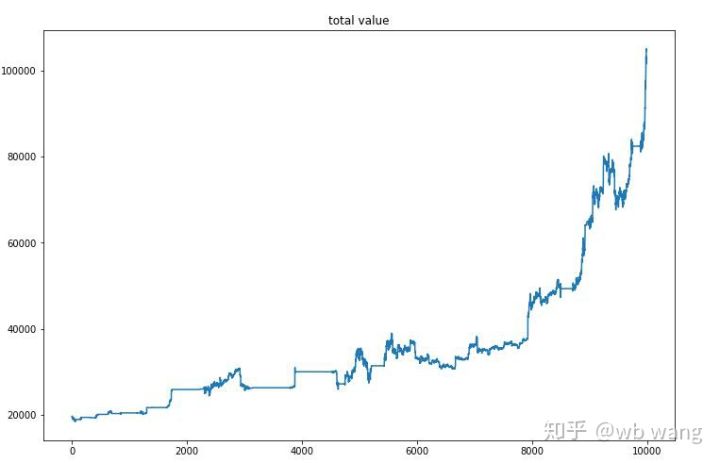
市場全体の価値は、弱気相場の初期にはゆっくりと増加し、その後の強気相場でも上昇を維持しましたが、それでも定期的に損失が発生しました。
最後に、ポジションの割合を見てみましょう。グラフの左軸はポジションの割合、右軸は市場の状況です。モデルが過剰適合していることが事前に判断できます。ポジションの頻度は弱気相場の初期には低く、市場が底値にあるときにはポジションの頻度が非常に高かった。また、モデルはポジションを長期間保持することを学習しておらず、常にすぐに売却していることもわかります。
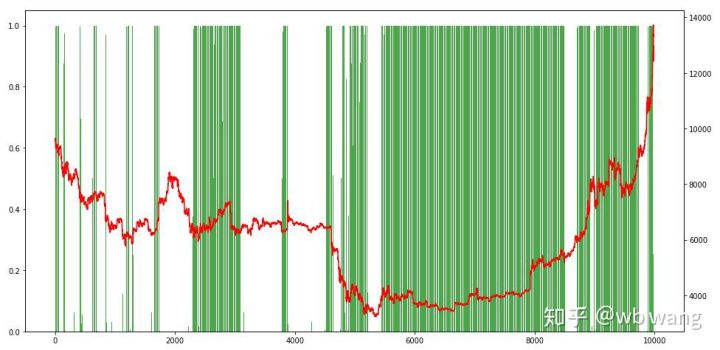
8. テストデータ分析
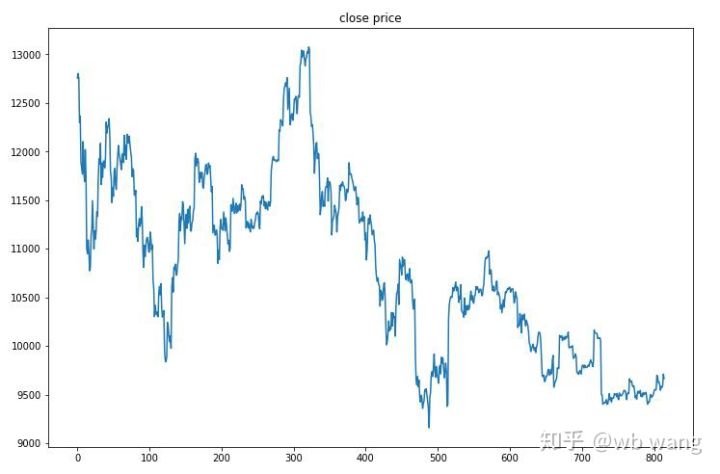
テストデータは2019/6/27から現在までの1時間のビットコイン市場から取得されました。図からわかるように、価格は当初の 13,000 ドルから現在は 9,000 ドル以上に下がっており、これはモデルにとって素晴らしいテストとなっています。
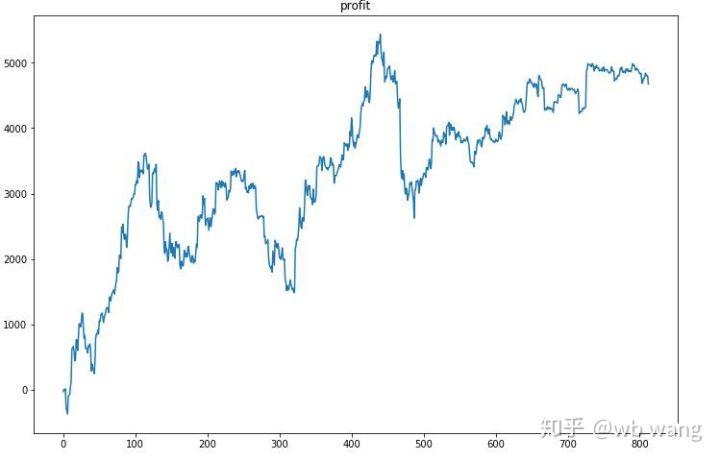
まず、最終的な相対収益は満足できるものではありませんでしたが、損失もありませんでした。
ポジションを見ると、モデルは急落後に買い、反発後に売る傾向があることが推測できます。最近、ビットコイン市場はほとんど変動しておらず、モデルはショートポジションを維持しています。
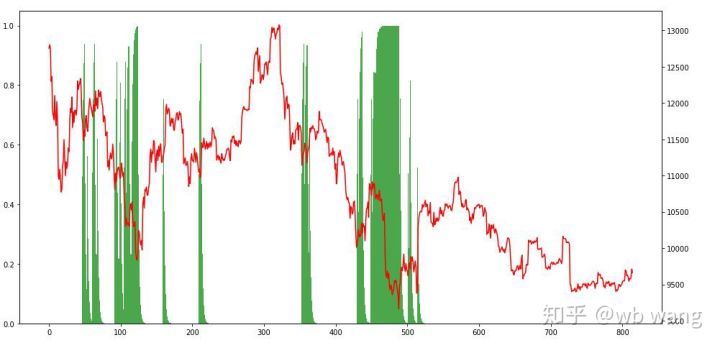
9. まとめ
この記事では、深層強化学習法 PPO を使用してビットコイン自動取引ロボットをトレーニングし、いくつかの結論を導き出します。時間が限られているため、モデルにはまだ改善できる部分がいくつかあります。どなたでも議論していただけます。最大の教訓は、データの標準化が正しい方法だということです。スケーリングなどの方法は使用しないでください。そうしないと、モデルは価格と市場状況の関係をすぐに記憶し、過剰適合に陥ります。正規化後、変化率は相対的なデータとなり、モデルが市場との関係を記憶することが難しくなり、変化率と上昇および下降の関係を見つける必要が生じます。
前の記事: FMZ Inventor Quantitative Platform での公開戦略の共有: https://zhuanlan.zhihu.com/p/64961672 NetEase Cloud Classroomのデジタル通貨定量取引コース、わずか20元:https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076 かつて非常に利益を上げた高頻度戦略を公開しました: https://www.fmz.com/bbs-topic/1211