통계의 기본 7장: 사기꾼의 평균 연봉
저자:발명가들의 수량화 - 작은 꿈, 2017-05-10 09:51:21, 업데이트:통계의 기본 7장: 사기꾼의 평균 연봉
중점, 중위, 정수, 많은 사람들의 개념은 다소 모호합니다.
- 유행하는 농담이 있는데, 여기 올려주세요. 이해하는데 도움이 될지도 모릅니다.
M: 미스터 지스모는 슈퍼 장난감을 생산하는 작은 공장을 가지고 있습니다.
M: 관리자는 지스모 씨, 그의 동생, 6명의 친척으로 구성되어 있습니다. 직원은 5명의 수사자와 10명의 노동자들로 구성되어 있습니다. 공장은 잘 운영되고 있으며 이제 새로운 노동자가 필요합니다.
M: 지금 Gizmodo 씨가 샘을 만나서 일에 대해 얘기하고 있습니다.
지스모: 우리는 좋은 임금을 받고 있습니다. 평균 연봉은 일주일에 300원입니다. 연습생 시절에는 일주일에 75원이나 받지만 빠르게 돈을 처리할 수 있습니다.
M: 샘은 며칠 후에 일을 하고, 공장장을 만나고 싶어합니다.
샘, 날 속였어! 나는 다른 노동자들을 찾아봤어, 한 사람도 일주일에 100달러 이상 벌지 않았다.
지스모: 아, 샘, 흥분하지 마. 평균 임금은 300원이다.
기즈모: 이건 제가 주당 받는 돈입니다. 저는 2,400원, 동생은 1,000원, 6명의 친척은 각각 250원, 5명의 채무자는 각각 200원, 10명의 노동자는 각각 100원입니다.
샘: 네, 네, 네! 당신은 맞습니다. 평균 연봉은 일주일에 300 달러입니다. 하지만 당신은 여전히 나를 속이고 있습니다.
기즈모: 난 동의하지 않아! 넌 이해가 안 돼. 난 이미 급여 표를 작성했고, 평균 급여가 200원이라고 말했어.
삼: 그럼 일주일에 100달러는 어떻게 되죠?
키즈모: "대수"라고 불리는 것은 대부분의 사람들이 받는 임금이다.
키즈모: 형님, 당신의 문제는 평균, 중위, 정수의 차이를 이해하지 못한다는 것입니다.
이 농담은 우리에게 데이터 위치를 설명하는 세 가지 매개 변수 사이의 차이를 알려줍니다.
일반적으로, 통계분포가 대칭이고, 가장 높은 지점은 중간에 있다면 평균, 중위, 숫자가 같을 것이다.
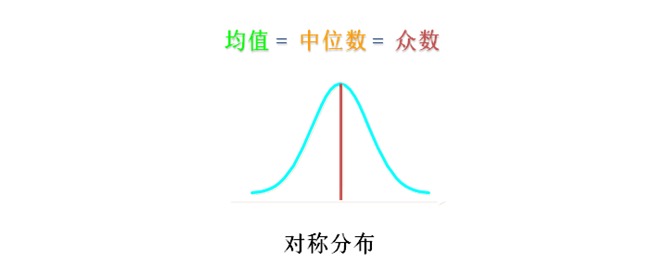
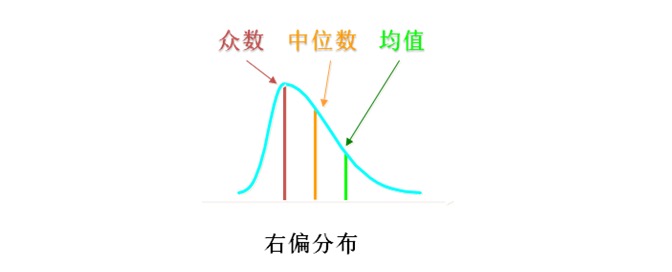
만약 통계분포가 우측으로, 즉 대부분 왼쪽에 집중되어 있고, 오른쪽은 보통 주택 가격, 국민소득 등과 같은 긴 꼬리를 끌고 다니는 분포에 속하는 경우, 일반적으로 평균> 중위> 수, 평균을 보는 것만으로도 비교가 일방적일 수 있고, 세 가지 매개 변수를 전체적으로 보는 것이 필요하며, 이는 데이터에 대한 당신의 전체적인 이해를 돕기 위해 연구 대상자를 이해하도록 도와줍니다.
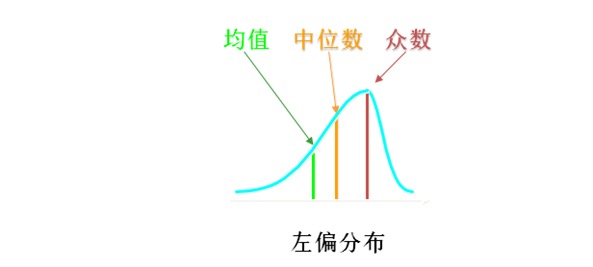
오른쪽에 있는 것은 좌측 분포가 있는 것을 의미합니다. 이 경우 평균값은 <중위수>다.
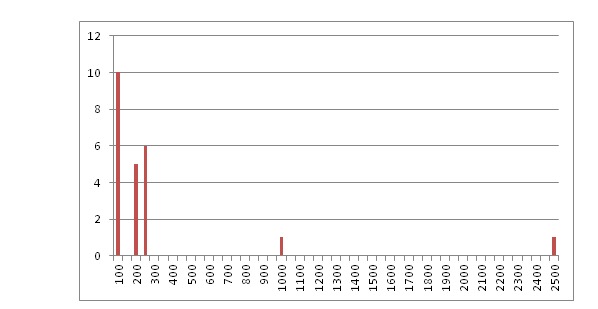
이 예에서 분포는 다음과 같습니다.
- Python에서 K줄 날짜 문제
- 비트 시대는 사용할 수 없는 시대가 아닐까요?
- 트렌드 시스템 - 70%의 충격에 대처하는 방법
- Vim 원격 프로그래밍은 특히 유용하지만 VIM은 Python 지원이 필요합니다.
- 이 모든 것이 실제로 무슨 의미인지 설명해 주시겠습니까?
- 절차적 거래, 10가지 주의사항
- 한 전략에서 여러 거래 쌍을 거래 할 수 있습니까? api는 작동하지 않는 것처럼 보입니다.
- 이 자리에서, 저는 이 자리에서, 이 자리에서, 이 자리에서, 이 자리에서,
- 블랙 스완 효과
- 세 가지 질문을 이해해야 합니다.
- 왜 분포차가 분포도를 나타낼 수 있을까요?
- 절차적 거래 모델의 실패를 판단하는 방법
- BitMEX exchange API note BitMEX 거래소 API 사용 사항
- 트렌드 트레이딩의 극단적 거래가 밝혀졌습니다.
- 코드를 사용하여 정밀하게 조정하는
리소스 시스템 기본 설정 - 고주파 전략
- 새로운 선택의 전형적인 실수
- 비트코인 HF1 전략은 어떻게 실현되었는가?
- 미래에셋 시장의 모든 이해관계자를 이해하십시오.
- 다목적 트렌드 역행 전략