FMZ에 파이썬 크롤러를 적용하기 위한 초기 탐구 크롤링 바이낸스 발표 내용
저자:니나바다스, 창작: 2022-04-08 15:47:43, 업데이트: 2022-04-13 10:07:13FMZ에 파이썬 크롤러를 적용하기 위한 초기 탐구 크롤링 바이낸스 발표 내용
최근에, 나는 우리의 포럼과 다이제스트를 통해 보았고, 파이썬 크롤러에 대한 관련 정보가 없습니다. 포괄적인 개발의 FMZ 정신에 기초하여, 나는 단순히 크롤러의 개념과 지식을 배우기 위해 갔다. 그것에 대해 알게 된 후, 나는 아직 더 많은 것을 배울 수 있다는 것을 발견했습니다. 이 기사는 단지
수요
IPO 거래를 좋아하는 거래자는 항상 가능한 한 빨리 플랫폼 목록 정보를 얻고 싶어합니다. 플랫폼 웹 사이트를 항상 수동으로 쳐다보는 것은 분명히 비현실적입니다. 그런 다음 플랫폼의 발표 페이지를 모니터링하고 첫 번째 알림과 상기시키기 위해 새로운 발표를 감지하기 위해 크롤러 스크립트를 사용해야합니다.
초기 탐사
매우 간단한 프로그램을 시작으로 사용하십시오 (실제로 강력한 크롤러 스크립트는 훨씬 더 복잡합니다. 따라서 시간을 내십시오). 프로그램 논리는 매우 간단합니다. 즉, 프로그램이 플랫폼의 발표 페이지를 지속적으로 방문하고, 획득 된 HTML 콘텐츠를 분석하고, 지정된 레이블의 내용이 업데이트되는지 감지하십시오.
코드 구현
몇 가지 유용한 크롤러 구조를 사용할 수 있습니다. 요구 사항이 매우 간단하기 때문에 직접 작성할 수도 있습니다.
사용할 파이썬 라이브러리:
```bs4```, which can be simply regarded as the library used to parse the HTML code of web pages.
Code:
bs4에서 BeautifulSoup를 가져오세요 수입 요청
urlBinanceAnnouncement =
def openUrl ((url):
헤더 = {
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def main (():
preNews_href =
”`
운영
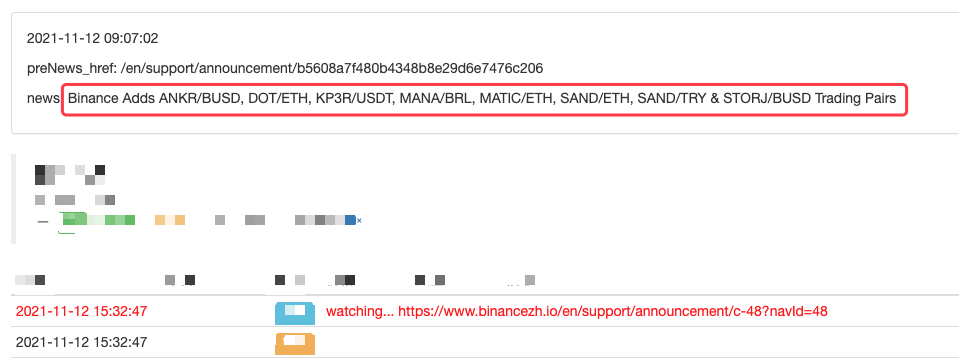
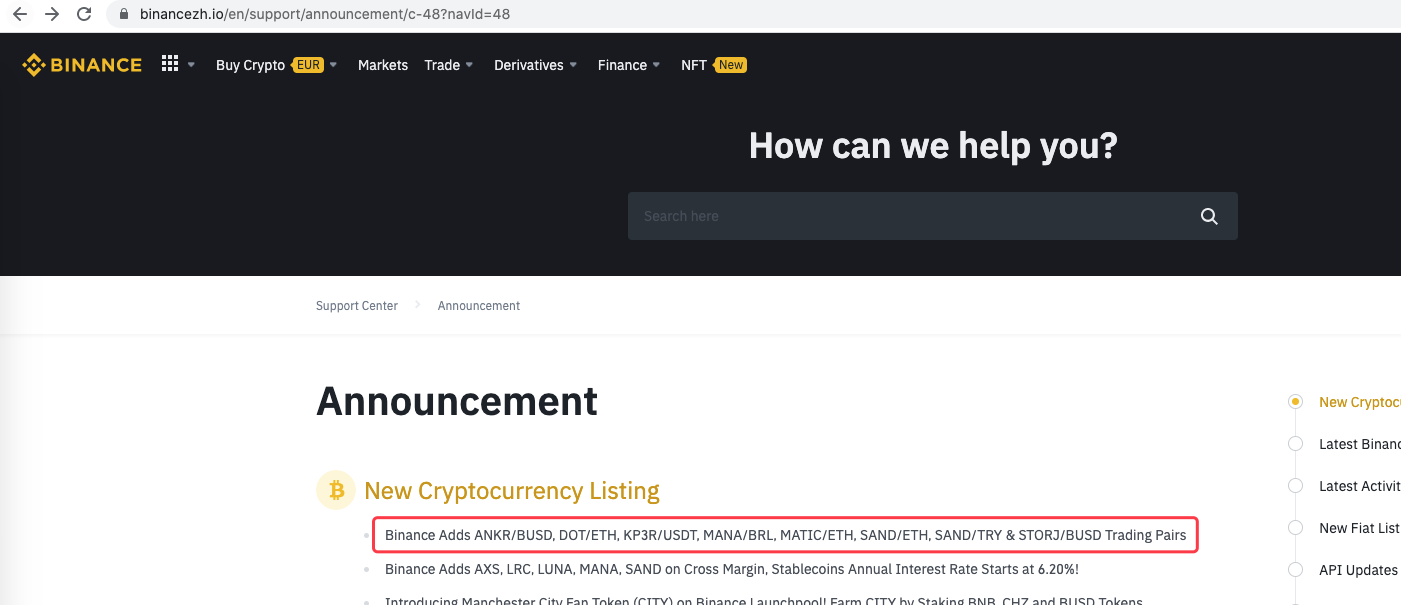
새로운 발표를 감지하고, 새로 상장된 통화 기호를 분석하고, IPO 거래를 자동으로 주문하는 등 확장할 수도 있습니다.
- 어떤 로그를 인쇄하는 것을 취소합니다
- 현재 화폐에 대한 모든 주문을 취소합니다.
- FMZ 양자 거래 플랫폼 APP의 빠른 시작
- 암호 화폐 스팟의 간단한 주문 감독 봇을 실현
- FMZ를 기반으로 한 결제 플랫폼
- 암호화폐 계약 단순 명령어 감독 로봇
- getdepth를 사용해서 해당 시간대를 얻으려면
- 방치, 해결
- 면적 문제
- dYdX 전략 설계 예제
- 헤지 전략 설계 연구 및 대기 중인 스팟 및 선물 주문의 예
- 최근 상황 및 자금율 전략의 권장 운영
- 암호화폐 선물의 이중 이동 평균 절정점 전략 (Teaching)
- 암호화폐 스팟 멀티 심볼 듀얼 이동 평균 전략 (Teaching)
- 자바스크립트에서 피셔 지표를 구현하고 FMZ에서 플롯링
- 관리자
- 2021 암호화폐 TAQ 검토 & 10배 증가의 가장 간단한 놓친 전략
- 암호화폐 선물 다중 기호 ART 전략 (교양)
- 업그레이드! 암호화폐 선물 마틴게일 전략
- Getrecords 함수는 세컨드 단위로 K 문자열을 얻을 수 없습니다