디지털 통화 시장의 정량 분석
저자:선함, 2019-08-16 10:37:23, 업데이트: 2023-10-19 21:04:20
데이터에 기반한 디지털 통화 스펙탈 분석 방법
비트코인 가격이 어떻게 변하는 걸까요? 디지털 화폐의 가격 상승과 하락의 원인은 무엇일까요? 다른 동전의 시장 가격은 불가분의 관계인가, 아니면 크게 독립적인가? 다음으로 어떤 일이 일어날지 어떻게 예측할 수 있을까요?
비트코인이나 이더리움과 같은 디지털 화폐에 대한 기사들은 현재 수백 명의 자칭 전문가들이 예상하는 추세를 주장하는 다양한 추측으로 가득합니다. 이러한 분석의 많은 부분은 기본 데이터와 통계 모델의 단단한 기초가 부족합니다.
이 문서의 목표는 파이썬을 사용하여 디지털 화폐 분석에 대한 간단한 소개를 제공하는 것입니다. 우리는 간단한 파이썬 스크립트를 통해 다양한 디지털 화폐의 데이터를 검색, 분석 및 시각화 할 것입니다. 이 과정에서 우리는 이러한 변동적인 시장 행동과 그들이 어떻게 발전하는지에 대한 흥미로운 추세를 발견 할 것입니다.
이것은 디지털 화폐를 설명하는 기사가 아닙니다. 어떤 특정 화폐가 상승하고 어떤 것이 하락할지에 대한 관점이 아닙니다. 오히려 이 튜토리얼에서는 원료 데이터를 가져와 숫자에 숨겨진 이야기를 발견하는 것에 초점을 맞추고 있습니다.
첫 번째 단계는 데이터 작업 환경을 구축하는 것입니다.
이 튜토리얼은 모든 수준의 기술 수준의 아마추어, 엔지니어 및 데이터 과학자를 위해 고안되었습니다. 업계의 거소 또는 프로그래밍의 초등자일지라도 필요한 유일한 기술은 파이썬 프로그래밍 언어의 기본 지식과 명령 줄 동작에 대한 충분한 지식 (데이터 과학 프로젝트를 설정 할 수있는 것) 입니다.
1.1 발명자 양적 호스트를 설치하고 아나콘다를 설정합니다
- 발명가들의 양적 관리자 시스템
发明者量化平台FMZ.COM除了提供优质的各大主流交易所的数据源,还提供一套丰富的API接口以帮助我们在完成数据的分析后进行自动化交易。这套接口包括查询账户信息,查询各个主流交易所的高,开,低,收价格,成交量,各种常用技术分析指标等实用工具,特别是对于实际交易过程中连接各大主流交易所的公共API接口,提供了强大的技术支持。
위와 같은 모든 기능들은 Docker와 비슷한 시스템으로 포장되어 있습니다. 우리가 해야 할 일은 클라우드 컴퓨팅 서비스를 구입하거나 임대한 후 Docker 시스템을 배치하는 것입니다.
발명가들의 정량화 플랫폼의 공식 명칭에서, 이 도커 시스템은 호스트 시스템이라고 불린다.
관리자와 로봇을 배치하는 방법에 대해 이전 기사를 참조하십시오.https://www.fmz.com/bbs-topic/4140
클라우드 서버 배포 관리자를 구입하려는 독자들은 이 기사를 참조할 수 있습니다:https://www.fmz.com/bbs-topic/2848
좋은 클라우드 서비스와 관리자 시스템을 성공적으로 배치한 다음, 우리는 현재 가장 큰 파이썬 신비를 설치합니다: 아나콘다
이 문서에서 필요한 모든 관련 프로그램 환경을 구현하기 위해 ( 의존도, 버전 관리 등) 가장 쉬운 방법은 아나콘다 (Anaconda) 이다. 그것은 패키지 된 파이썬 데이터 과학 생태계와 의존도 관리자이다.
우리는 Anaconda를 클라우드 서비스에서 설치하기 때문에, 우리는 클라우드 서버에 Anaconda의 명령 줄 버전의 리눅스 시스템을 설치하는 것이 좋습니다.
아나콘다를 설치하는 방법에 대해 아나콘다 공식 지침서를 참조하십시오:https://www.anaconda.com/distribution/
만약 당신이 경험이 많은 파이썬 프로그래머라면 아나콘다를 사용하지 않아도 됩니다. 저는 당신이 필수적인 의존 환경을 설치하는 데 도움이 필요 없다고 가정합니다. 당신은 바로 두 번째 부분으로 넘을 수 있습니다.
1.2 아나콘다 데이터 분석 프로젝트 환경을 만드는 방법
아나콘다 설치가 완료되면, 우리는 우리의 의존 패키지를 관리하는 새로운 환경을 만들어야합니다.
conda create --name cryptocurrency-analysis python=3
이 프로젝트의 새로운 아나콘다 환경을 만들기 위해 왔습니다.
다음으로 입력합니다.
source activate cryptocurrency-analysis (linux/MacOS操作)
或者
activate cryptocurrency-analysis (windows操作系统)
이 환경을 활성화하기 위해
다음으로, 입력:
conda install numpy pandas nb_conda jupyter plotly
이 프로젝트를 설치하는 데 필요한 모든 의존 패키지들.
참고: 왜 아나콘다 환경을 사용해야 합니까? 컴퓨터에서 많은 파이썬 프로젝트를 실행할 계획이라면 충돌을 피하기 위해 다른 프로젝트의 의존 패키지를 분리하는 것이 도움이 됩니다. 아나콘다는 모든 패키지를 적절히 관리하고 구분할 수 있도록 각 프로젝트의 의존 패키지에 대해 특별한 환경 디렉토리를 만듭니다.
1.3 유피터 노트북을 만드는 방법
환경과 의존 패키지가 설치되면 실행됩니다.
jupyter notebook
아이파톤 커널을 시작해서 브라우저로 http://localhost:8888/새로운 파이썬 노트북을 만들 때,
Python [conda env:cryptocurrency-analysis]
핵

1.4 의존 패키지 수입
새로운 빈 유피터 노트북을 만들고, 우리가 해야 할 첫 번째 일은 필요한 의존 패키지를 수입하는 것입니다.
import os
import numpy as np
import pandas as pd
import pickle
from datetime import datetime
우리는 Plotly를 가져와 오프라인 모드를 켜야 합니다.
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
두 번째 단계: 디지털 화폐 가격 정보를 얻으십시오.
준비 작업이 완료되어 이제 분석할 데이터를 얻을 수 있습니다. 먼저, 우리는 발명자의 양적 플랫폼 API를 사용하여 비트코인 가격 데이터를 얻을 것입니다.
이것은 GetTicker 함수를 사용할 것입니다. 이 두 함수의 사용에 대한 자세한 내용은 다음을 참조하십시오:https://www.fmz.com/api
2.1 Quandl에서 데이터 집합 함수를 작성
데이터를 쉽게 얻을 수 있도록, 우리는 Quandl에서 다운로드 및 동기화 함수를 작성했습니다.quandl.com이 자료는 무료 금융 데이터 인터페이스이며 해외에서 높은 인지도를 가지고 있습니다. 발명자 양자 플랫폼은 또한 유사한 데이터 인터페이스를 제공하며, 주로 실제 거래 시 사용됩니다. 이 문서가 주로 데이터 분석을위한 것이기 때문에 우리는 Quandl 데이터를 사용합니다.
실제 거래 시, 파이썬에서 직접 GetTicker 및 GetRecords 함수를 호출하여 가격 데이터를 얻을 수 있습니다.https://www.fmz.com/api
def get_quandl_data(quandl_id):
# 下载和缓冲来自Quandl的数据列
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return df
여기서는 피클 라이브러리를 사용하여 데이터를 서열화하고 다운로드 된 데이터를 파일로 저장하여 프로그램이 실행할 때마다 동일한 데이터를 다시 다운로드하지 않도록합니다. 이 함수는 판다 데이터 프레임 형식의 데이터를 반환합니다.
2.2 크라켄 거래소에서 디지털 통화 가격 데이터를 얻으십시오
크라켄 비트코인 거래소를 예로 들자면, 비트코인 가격으로 시작해 보겠습니다.
# 获取Kraken比特币交易所的价格
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
두 번째 방법으로는, 두 번째 방법으로는, 두 번째 방법으로는, 두 번째 방법으로는, 두 번째 방법으로는, 두 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로는, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세 번째 방법으로도, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세번째로, 세로, 세 세로로로, 세로 세로 세로 세로 세로 세로 세로 세로 세로 세
btc_usd_price_kraken.head()
그 결과:
| BTC | 오픈 | 높은 | 낮은 | 닫아 | 부피 (BTC) | 부피 (화폐) | 가중화 된 가격 |
|---|---|---|---|---|---|---|---|
| 2014-01-07 | 874.67040 | 892.06753 | 810.00000 | 810.00000 | 15.622378 | 13151.472844 | 841.835522 |
| 2014-01-08 | 810.00000 | 899.84281 | 788.00000 | 824.98287 | 19.182756 | 16097.329584 | 839.156269 |
| 2014-01-09 | 825.56345 | 870.00000 | 807.42084 | 841.86934 | 8.158335 | 6784.249982 | 831.572913 |
| 2014-01-10 | 839.99000 | 857.34056 | 817.00000 | 857.33056 | 8.024510 | 6780.220188 | 844.938794 |
| 2014-01-11 | 858.20000 | 918.05471 | 857.16554 | 899.84105 | 18.748285 | 16698.566929 | 890.671709 |
다음으로, 우리는 간단한 표를 만들고 시각화 방법을 통해 데이터의 정확성을 확인할 것입니다.
# 做出BTC价格的表格
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
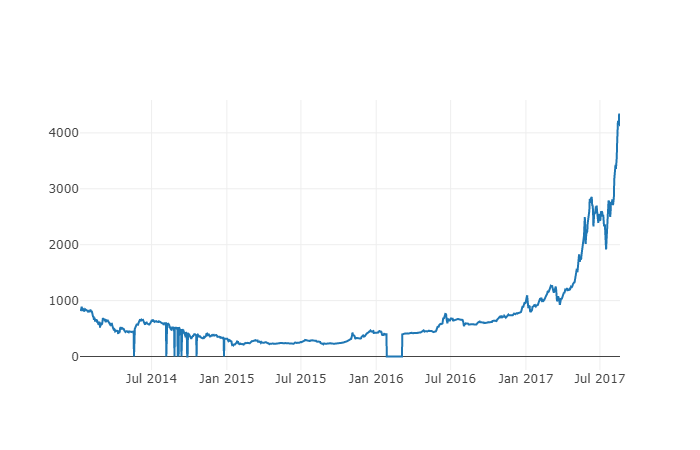
这里,我们用Plotly来完成可视化部分。相对于使用一些更成熟的Python数据可视化库,比如Matplotlib,用Plotly是一个不那么普遍的选择,但Plotly确实是一个不错的选择,因为它可以调用D3.js的充分交互式图表。这些图表有非常漂亮的默认设置,易于探索,而且非常方便嵌入到网页中。
작은 팁: 생성된 그래프를 주류 거래소의 비트코인 가격 차트 (예: OKEX, Binance 또는 Huobi의 그래프) 와 비교하여 다운로드된 데이터가 대체로 일치하는지 확인하는 빠른 완전성 검사로 사용할 수 있습니다.
2.3 주요 비트코인 거래소에서 가격 데이터를 얻는다
주의 깊게 읽는 독자들은 2014년 말과 2016년 초에, 특히 크라켄 거래소에서, 위의 데이터의 일부에서 데이터가 부족하다는 것을 알아차렸을 것입니다. 특히 이러한 데이터의 부족은 특히 분명합니다. 우리는 물론 이러한 자료의 부족이 가격 분석에 영향을 줄 것을 원하지 않습니다.
디지털 화폐 거래소의 특징은 공급과 수요 관계가 동전의 가격을 결정한다는 것입니다. 따라서 어떤 거래의 가격도 시장의 주류 가격으로 변할 수 없습니다. 이 문제를 해결하기 위해, 그리고 방금 언급한 데이터 결핍 문제 (기술 장애와 데이터 오류로 인해 발생할 수 있습니다) 를 해결하기 위해, 우리는 세계에서 세 가지 주요 비트코인 거래소에서 데이터를 다운로드하여 평균 비트코인 가격을 계산합니다.
먼저 각 거래소의 데이터를 사전 타입으로 구성된 데이터 패드로 다운로드하여 시작해보자.
# 下载COINBASE,BITSTAMP和ITBIT的价格数据
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_df
2.4 모든 데이터를 하나의 데이터 패드에 통합합니다.
다음 단계에서는 특정 함수를 정의하여 각 데이터줄에 공유된 열을 새로운 데이터줄로 결합합니다.
def merge_dfs_on_column(dataframes, labels, col):
'''Merge a single column of each dataframe into a new combined dataframe'''
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
이제, 각 데이터 세트에 기반한
# 整合所有数据帧
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
마지막으로, 우리는
btc_usd_datasets.tail()
그 결과는 다음과 같습니다.
| BTC | BITSTAMP | 코인베이스 | ITBIT | KRAKEN |
|---|---|---|---|---|
| 2017-08-14 | 4210.154943 | 4213.332106 | 4207.366696 | 4213.257519 |
| 2017-08-15 | 4101.447155 | 4131.606897 | 4127.036871 | 4149.146996 |
| 2017-08-16 | 4193.426713 | 4193.469553 | 4190.104520 | 4187.399662 |
| 2017-08-17 | 4338.694675 | 4334.115210 | 4334.449440 | 4346.508031 |
| 2017-08-18 | 4182.166174 | 4169.555948 | 4175.440768 | 4198.277722 |
위의 표에서 볼 수 있듯이, 이 데이터는 우리가 예상했던 것과 일치하고, 데이터 범위는 거의 동일하지만, 지연 또는 각 거래소의 특성에 따라 약간 다릅니다.
2.5 가격 데이터의 시각화 과정
분석 논리적으로 다음 단계는 데이터를 시각화하여 비교하는 것입니다. 이를 위해 먼저 보조 함수를 정의해야 합니다.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
'''Generate a scatter plot of the entire dataframe'''
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
# 每个系列的表格跟踪
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
# 为系列添加单独的轴
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
쉽게 이해할 수 있도록, 이 문서에서는 이 보조 함수의 논리 원리를 너무 많이 다루지 않습니다. 더 많은 것을 알기 위해, Pandas와 Plotly의 공식 설명 문서를 참조하십시오.
이제 우리는 쉽게 비트코인 가격 데이터를 그래프로 만들 수 있습니다.
# 绘制所有BTC交易价格
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
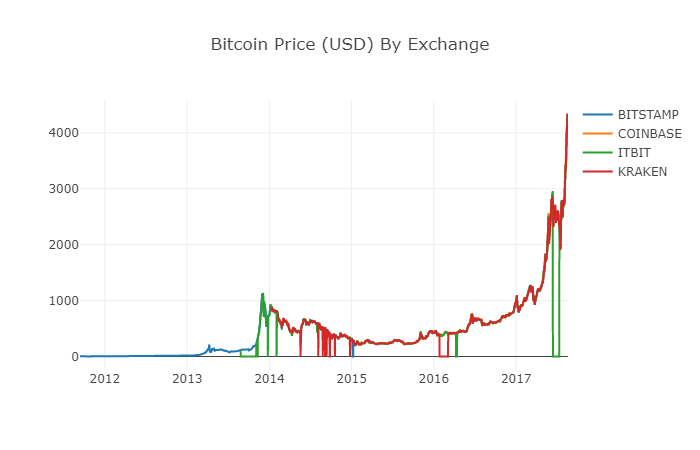
2.6 전체 가격 데이터를 정리하고 추가합니다.
위의 그래프에서 볼 수 있듯이, 이 네 개의 일련의 데이터가 거의 동일한 경로를 따라가지만, 그 안에 몇 가지 불규칙한 변화가 있습니다. 우리는 이러한 불규칙한 변화를 제거하려고 노력하겠습니다.
2012년에서 2017년 사이에는 비트코인의 가격이 결코 0에 해당하지 않는다는 것을 알고 있기 때문에 먼저 데이터 박스에서 모든 0을 제거했습니다.
# 清除"0"值
btc_usd_datasets.replace(0, np.nan, inplace=True)
데이터
# 绘制修订后的数据框
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
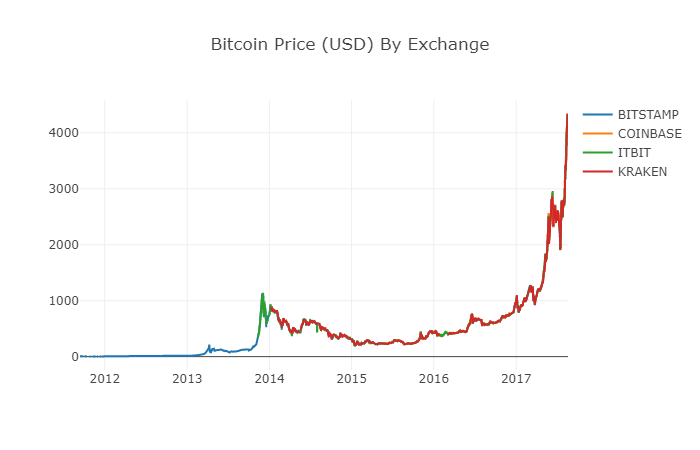
우리는 이제 새로운 열을 계산할 수 있습니다: 모든 거래소의 하루 평균 비트코인 가격.
# 将平均BTC价格计算为新列
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
새로운 열은 비트코인 가격 지표입니다! 우리는 그것을 다시 그려서 데이터에 문제가 있는지 확인합니다.
# 绘制平均BTC价格
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])
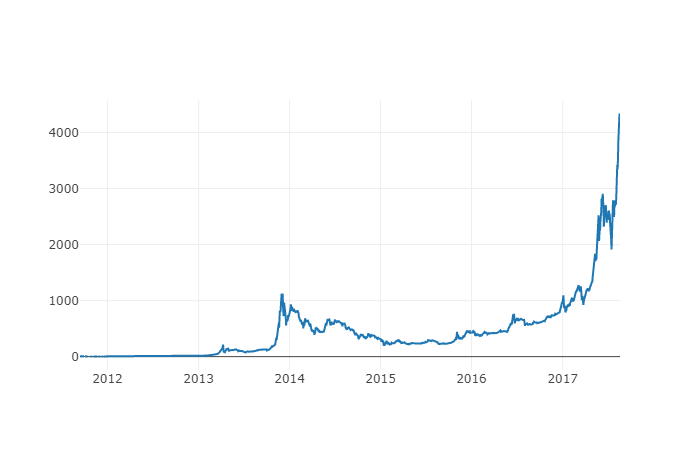
실제로 문제가 없는 것처럼 보이지만, 나중에 우리는 다른 디지털 화폐와 달러 사이의 환율을 결정하기 위해 이 집계된 가격 계열 데이터를 계속 사용할 것입니다.
세 번째 단계: Altcoins의 가격을 수집합니다.
이제까지 우리는 비트코인 가격의 시간 순서 데이터를 가지고 있습니다. 다음은 비 비트코인 디지털 화폐의 일부 데이터, 즉 Altcoins의 경우입니다. 물론, Altcoins라는 단어가 약간 과대화 될 수 있지만, 현재 디지털 화폐의 발전에 대해서는 시장 가치 10위 (비트코인, 이더리움, EOS, USDT 등) 를 제외한 대부분의 디지털 화폐가 Zombies라고 불릴 수 있는 것은 문제가 없습니다. 우리는 거래할 때 이러한 화폐로부터 최대한 멀리 떨어져 있어야합니다. 왜냐하면 그들은 너무 혼란스럽고 속임수이기 때문입니다.
3.1 Poloniex 거래소의 API를 통해 보조 기능을 정의합니다.
먼저, 우리는 디지털 통화 거래의 데이터 정보를 얻기 위해 Poloniex 거래소의 API를 사용합니다. 우리는 JSON 데이터를 API를 통해 다운로드하고 캐시하는 두 가지 보조 기능을 정의했습니다.
먼저, 우리는 get_json_data 함수를 정의합니다. 그것은 주어진 URL에서 JSON 데이터를 다운로드하고 저장합니다.
def get_json_data(json_url, cache_path):
'''Download and cache JSON data, return as a dataframe.'''
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached {} at {}'.format(json_url, cache_path))
return df
다음으로, 우리는 새로운 함수를 정의하고, 이 함수는 Poloniex API의 HTTP 요청을 생성하고, 방금 정의한 get_json_data 함수를 호출하여 호출된 데이터 결과를 저장합니다.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # 从2015年开始获取数据
end_date = datetime.now() # 直到今天
pediod = 86400 # pull daily data (86,400 seconds per day)
def get_crypto_data(poloniex_pair):
'''Retrieve cryptocurrency data from poloniex'''
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_df
위의 함수는 디지털 화폐가 결합된 문자 코드를 (예를 들어, BTC_ETH 주머니) 추출하고 두 개의 화폐의 역사적 가격을 포함하는 데이터 주머니를 반환합니다.
3.2 Poloniex에서 거래 가격 데이터를 다운로드
대부분의 도화폐는 달러로 직접 구매할 수 없으며, 개인이 이 디지털 화폐를 얻기 위해서는 일반적으로 먼저 비트코인을 구입하고, 그 사이의 가격 비율에 따라 도화폐로 교환해야 합니다. 따라서 우리는 각각의 디지털 화폐를 비트코인으로 교환하는 환율을 다운로드하고, 기존의 비트코인 가격 데이터를 사용하여 달러로 변환해야 합니다. 우리는 9개의 랭킹 상위 디지털 화폐 거래 데이터를 다운로드합니다: 에테리움, 리테코인, 립플, 에테리움 클래식, 스텔러, 대시, 시아코인, 몬레로, 그리고 NEM.
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_df
현재, 우리는 9개의 데이터 팩을 가진 사전을 가지고 있으며, 각각의 데이터 팩은
우리는 이더리움 가격표의 마지막 몇 줄을 통해 데이터의 정확성을 판단할 수 있습니다.
altcoin_data['ETH'].tail()
| ETH | 오픈 | 높은 | 낮은 | 닫아 | 부피 (BTC) | 부피 (화폐) | 가중화 된 가격 |
|---|---|---|---|---|---|---|---|
| 2017-08-18 | 0.070510 | 0.071000 | 0.070170 | 0.070887 | 17364.271529 | 1224.762684 | 0.070533 |
| 2017-08-18 | 0.071595 | 0.072096 | 0.070004 | 0.070510 | 26644.018123 | 1893.136154 | 0.071053 |
| 2017-08-18 | 0.071321 | 0.072906 | 0.070482 | 0.071600 | 39655.127825 | 2841.549065 | 0.071657 |
| 2017-08-19 | 0.071447 | 0.071855 | 0.070868 | 0.071321 | 16116.922869 | 1150.361419 | 0.071376 |
| 2017-08-19 | 0.072323 | 0.072550 | 0.071292 | 0.071447 | 14425.571894 | 1039.596030 | 0.072066 |
3.3 모든 가격 데이터의 통화 단위를 달러로 통합
이제 우리는 BTC와 동전의 환율 데이터를 우리의 비트코인 가격 지표와 결합하여 각각의 동전의 역사적 가격을 직접 계산할 수 있습니다.
# 将USD Price计算为每个altcoin数据帧中的新列
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
여기서는 각 도자기의 데이터
다음으로, 우리는 이전에 정의된 merge_dfs_on_column 함수를 다시 사용하여 각 디지털 화폐의 달러 가격을 통합하는 통합 데이터 파이를 만들 수 있습니다.
# 将每个山寨币的美元价格合并为单个数据帧
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
다 됐어!
이제 Bitcoin의 가격을 합성된 데이터베이스에 마지막으로 추가하도록 합시다.
# 将BTC价格添加到数据帧
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
이제 우리는 우리가 검증하고 있는 10개의 디지털 화폐의 매일 달러 가격을 포함하는 유일한 데이터 패드를 가지고 있습니다.
우리는 이전 함수df_scatter를 다시 호출하여 모든
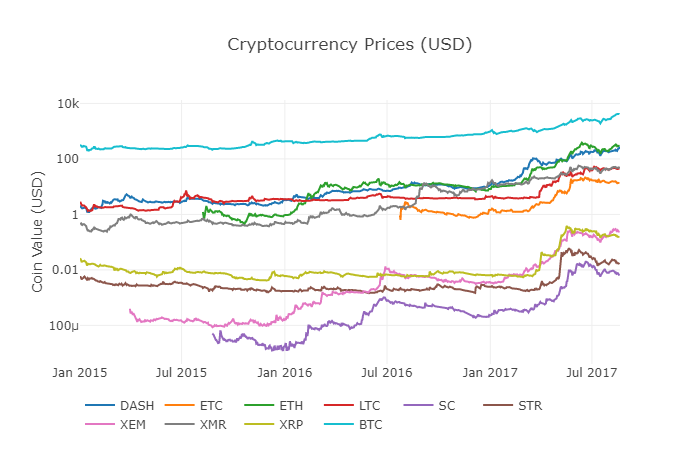
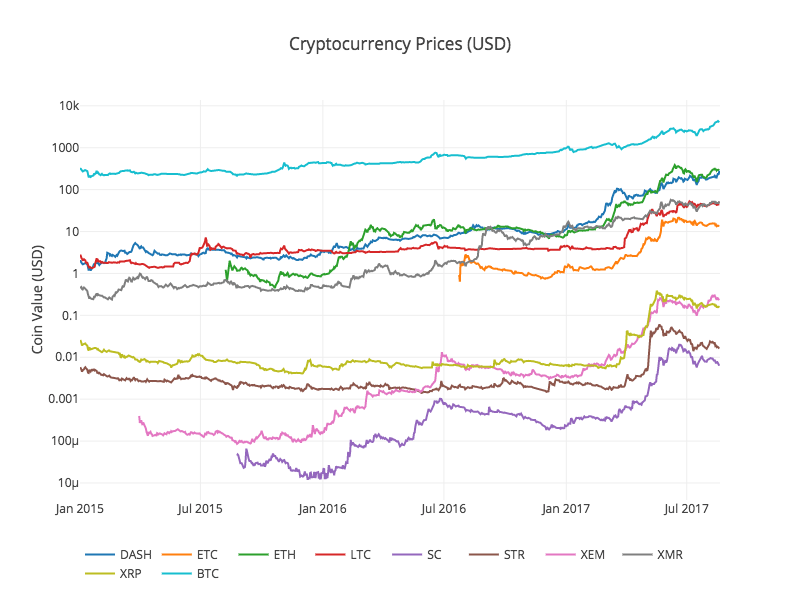
이 그래프는 지난 몇 년 동안 각 디지털 화폐 교환 가격의 변화를 보여주는 전체적인 그림을 보여줍니다.
참고: 여기서는 대수학적 특성의 y축을 사용하여 모든 디지털 화폐를 동일한 도면에 비교합니다. 다른 다른 매개 변수 값을 시도할 수도 있습니다 (예를 들어, scale=
3.4 연관성 분석 시작
주의 깊게 읽는 독자들은 디지털 화폐의 가격이 큰 차이점과 높은 변동성에도 불구하고 관련이있는 것처럼 보인다는 것을 알아차릴 수 있습니다. 특히 2017년 4월 급격한 상승 이후 많은 작은 변동이 전체 시장의 변동과 동시에 나타나는 것처럼 보입니다.
물론, 데이터에 근거한 결론은 이미지에 근거한 직관보다 더 설득력이 있다.
위와 같은 상관관계 가정을 판다스의 corr () 함수로 확인할 수 있다. 이 검사는 데이터
2017.8.22 수정 설명: 이 부분의 변경은 관련 계수를 계산할 때 가격 대신 일일 수익률의 절대값을 사용하기 위한 것이다.
비상태적 시간 계열 (예를 들어 원시 가격 데이터) 에 기반한 직접적인 계산은 상관성 계수 오차를 초래할 수 있다. 이 문제에 대한 우리의 해결책은 pct_change (pct_change) 방법을 사용하여 데이터 스레드의 각 가격의 절대값을 그에 따른 일일 수익률으로 변환하는 것이다.
예를 들어, 2016년 관련 계수를 계산해보죠.
# 计算2016年数字货币的皮尔森相关系数
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')
| 이름 | DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.003992 | 0.122695 | -0.012194 | 0.026602 | 0.058083 | 0.014571 | 0.121537 | 0.088657 | -0.014040 |
| ETC | 0.003992 | 1.000000 | -0.181991 | -0.131079 | -0.008066 | -0.102654 | -0.080938 | -0.105898 | -0.054095 | -0.170538 |
| ETH | 0.122695 | -0.181991 | 1.000000 | -0.064652 | 0.169642 | 0.035093 | 0.043205 | 0.087216 | 0.085630 | -0.006502 |
| LTC | -0.012194 | -0.131079 | -0.064652 | 1.000000 | 0.012253 | 0.113523 | 0.160667 | 0.129475 | 0.053712 | 0.750174 |
| SC | 0.026602 | -0.008066 | 0.169642 | 0.012253 | 1.000000 | 0.143252 | 0.106153 | 0.047910 | 0.021098 | 0.035116 |
| STR | 0.058083 | -0.102654 | 0.035093 | 0.113523 | 0.143252 | 1.000000 | 0.225132 | 0.027998 | 0.320116 | 0.079075 |
| XEM | 0.014571 | -0.080938 | 0.043205 | 0.160667 | 0.106153 | 0.225132 | 1.000000 | 0.016438 | 0.101326 | 0.227674 |
| XMR | 0.121537 | -0.105898 | 0.087216 | 0.129475 | 0.047910 | 0.027998 | 0.016438 | 1.000000 | 0.027649 | 0.127520 |
| XRP | 0.088657 | -0.054095 | 0.085630 | 0.053712 | 0.021098 | 0.320116 | 0.101326 | 0.027649 | 1.000000 | 0.044161 |
| BTC | -0.014040 | -0.170538 | -0.006502 | 0.750174 | 0.035116 | 0.079075 | 0.227674 | 0.127520 | 0.044161 | 1.000000 |
위의 그림은 모든 연관 계수들을 나타낸다. 계수들은 각각 1이나 -1에 가깝게, 즉 이 순서가 긍정적으로 연관되어 있거나, 역관계되어 있고, 연관 계수들은 0에 가깝게, 즉 해당 객체들이 연관되지 않고, 그들의 변동이 서로 독립되어 있음을 나타낸다.
더 나은 시각화 결과를 보여주기 위해 새로운 시각화 도움말 기능을 만들었습니다.
def correlation_heatmap(df, title, absolute_bounds=True):
'''Plot a correlation heatmap for the entire dataframe'''
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
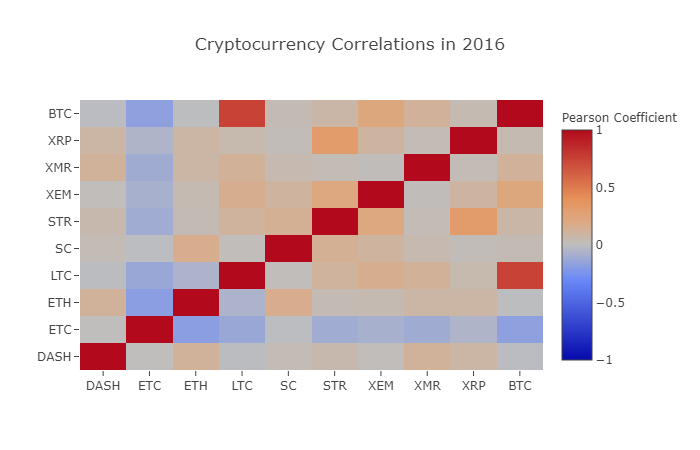
여기서, 어두운 빨간색의 값은 강한 상관관계를 나타냅니다 (각 통화 종류는 분명히 자신의 높이에 관련이 있습니다), 깊은 파란색의 값은 역 상관관계를 나타냅니다. 중간 모든 색상 - 밝은 파란색 / 오렌지 / 회색 / 갈색 - 그 값은 다른 정도의 약한 상관관계를 나타냅니다. 또는 상관관계가 없습니다.
이 그래프는 우리에게 무엇을 알려줍니다? 기본적으로 2016년 동안 다른 디지털 화폐 가격의 변동에 대한 통계적으로 유의미한 연관성이 거의 없습니다.
이제, 우리의 가설을 검증하기 위해, 디지털 화폐가 최근 몇 달 동안 관련성을 강화하는 것을 확인하기 위해, 다음으로, 우리는 2017년부터 시작되는 데이터를 사용하여 동일한 테스트를 반복할 것입니다.
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')
| 이름 | DASH | ETC | ETH | LTC | SC | STR | XEM | XMR | XRP | BTC |
|---|---|---|---|---|---|---|---|---|---|---|
| DASH | 1.000000 | 0.384109 | 0.480453 | 0.259616 | 0.191801 | 0.159330 | 0.299948 | 0.503832 | 0.066408 | 0.357970 |
| ETC | 0.384109 | 1.000000 | 0.602151 | 0.420945 | 0.255343 | 0.146065 | 0.303492 | 0.465322 | 0.053955 | 0.469618 |
| ETH | 0.480453 | 0.602151 | 1.000000 | 0.286121 | 0.323716 | 0.228648 | 0.343530 | 0.604572 | 0.120227 | 0.421786 |
| LTC | 0.259616 | 0.420945 | 0.286121 | 1.000000 | 0.296244 | 0.333143 | 0.250566 | 0.439261 | 0.321340 | 0.352713 |
| SC | 0.191801 | 0.255343 | 0.323716 | 0.296244 | 1.000000 | 0.417106 | 0.287986 | 0.374707 | 0.248389 | 0.377045 |
| STR | 0.159330 | 0.146065 | 0.228648 | 0.333143 | 0.417106 | 1.000000 | 0.396520 | 0.341805 | 0.621547 | 0.178706 |
| XEM | 0.299948 | 0.303492 | 0.343530 | 0.250566 | 0.287986 | 0.396520 | 1.000000 | 0.397130 | 0.270390 | 0.366707 |
| XMR | 0.503832 | 0.465322 | 0.604572 | 0.439261 | 0.374707 | 0.341805 | 0.397130 | 1.000000 | 0.213608 | 0.510163 |
| XRP | 0.066408 | 0.053955 | 0.120227 | 0.321340 | 0.248389 | 0.621547 | 0.270390 | 0.213608 | 1.000000 | 0.170070 |
| BTC | 0.357970 | 0.469618 | 0.421786 | 0.352713 | 0.377045 | 0.178706 | 0.366707 | 0.510163 | 0.170070 | 1.000000 |
이 자료들은 더 관련성이 있는가? 투자에 대한 판단 기준으로 충분한가? 답은 '아니오'이다.
그러나 주목할 점은 거의 모든 디지털 화폐가 점점 더 상호 연결되고 있다는 것입니다.
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")
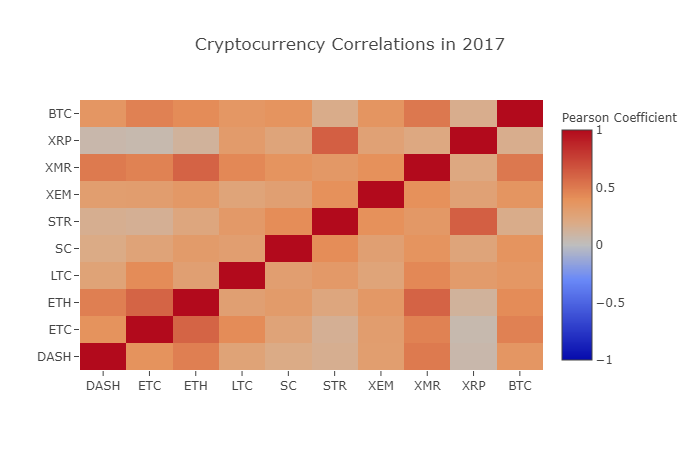
이 그림에서 볼 수 있듯이, 일이 점점 더 재미있게 진행되고 있습니다.
왜 이런 일이 일어나는 걸까요?
하지만 사실, 저는 확신할 수 없습니다.
제 첫 번째 반응은 헤지펀드가 최근 디지털 화폐 시장에서 공개적으로 거래하기 시작했다는 것입니다. 이러한 펀드는 일반 거래자보다 훨씬 더 많은 자본을 보유하고 있으며, 펀드가 여러 디지털 화폐를 헤지핑하면 독립적인 변수 (예를 들어, 주식 시장) 에 따라 각각의 화폐에 대한 유사한 거래 전략을 사용하면 이러한 관점에서 볼 때 이러한 증가하는 연관성이 합리적입니다.
XRP와 STR에 대한 더 깊은 이해
예를 들어, 위의 그래프에서 XRP (리플의 토큰) 이 다른 디지털 통화와 가장 낮은 관련이 있음을 분명히 볼 수 있습니다. 그러나 여기서 주목할만한 예외는 STR (스텔러의 토큰, 공식 이름은 "루멘스") 이 XRP와 강한 관련이 있습니다. (관계 계수: 0.62).
흥미롭게도, Stellar와 Ripple는 매우 유사한 금융 기술 플랫폼이며, 둘 다 은행 간 국가 간 송금에 대한 번거로운 단계를 줄이기 위해 고안되었습니다. 이해 할 수 있듯이, 블록체인 서비스가 토큰을 사용하는 유사성을 고려하면 일부 대형 플레이어와 헤지펀드가 Stellar와 Ripple에 대한 투자에 유사한 거래 전략을 사용할 수 있습니다. 이것이 XRP가 다른 디지털 통화보다 STR와 더 강하게 연관되어있는 이유입니다.
네, 네 차례야!
위의 설명들은 대부분 가설적이기 때문에, 아마도 당신은 더 잘 할 것입니다. 우리가 이미 놓은 기초를 바탕으로, 데이터에 숨겨진 이야기를 계속 탐구할 수 있는 수백 가지 다른 방법이 있습니다.
이 부분의 본문은 제 생각에는 이 부분의 독자들이 더 많은 연구를 할 수 있는 몇 가지 조언입니다.
- 전체 분석에 더 많은 디지털 화폐 데이터를 추가합니다.
- 연동 분석의 시간 범위와 입자를 조정하여 최적화 또는 거시적인 입자성의 경향 관점을 얻습니다.
- 거래량이나 블록체인 데이터에서 트렌드를 집중적으로 검색한다. 원료 가격 데이터에 비해 미래의 가격 변동을 예측하려면 구매/판매 비율 데이터가 더 필요할 수 있다.
- 주식, 상품, 법정 화폐에 대한 가격 데이터를 추가하여 어느 것이 디지털 화폐와 관련이 있는지 결정하십시오.
- 이벤트 레지스트리, GDELT, 그리고 Google 트렌드를 사용하여 특정 디지털 화폐에 대한 화두의 수를 정량화하십시오.
- 데이터로 예측 가능한 기계 학습 모델을 훈련하여 내일의 가격을 예측하십시오. 더 큰 야망을 가지고 있다면 회전 신경망 (RNN) 을 사용하여 위의 훈련을 시도하는 것을 고려할 수도 있습니다.
- 당신의 분석을 활용하여 해당 응용 프로그램 프로그래밍 인터페이스 (API) 를 통해 자동화 된 거래 로봇을 만들 수 있습니다. 예를 들어 Poloniex 또는 Coinbase의 거래소에 적용됩니다. 주의하십시오: 낮은 성능의 로봇은 쉽게 당신의 자산을 즉시 소멸시킬 수 있습니다.这里推荐使用发明者量化平台FMZ.COM。
비트코인, 그리고 디지털 화폐에 대한 가장 좋은 부분은 그들의 탈중앙화 성질이며, 이것은 다른 어떤 자산보다 자유롭고 민주적입니다. 당신은 당신의 분석을 오픈 소스로 공유하거나 커뮤니티에 참여하거나 블로그를 작성할 수 있습니다.https://www.fmz.com/bbs이 글은 멘토와 함께 올라왔습니다.
- 암호화폐의 리드-래그 중재에 대한 소개 (2)
- 디지털 화폐의 리드-래그 스위트 소개 (2)
- FMZ 플랫폼의 외부 신호 수신에 대한 논의: 전략 내 내장 Http 서비스와 함께 신호 수신에 대한 완전한 솔루션
- FMZ 플랫폼 외부 신호 수신에 대한 탐구: 전략 내장 HTTP 서비스 신호 수신의 전체 방안
- 암호화폐의 리드-래그 중재에 대한 소개 (1)
- 디지털 화폐의 리드-래그 스위트 소개 (1)
- FMZ 플랫폼의 외부 신호 수신에 대한 논의: 확장 API VS 전략 내장 HTTP 서비스
- FMZ 플랫폼 외부 신호 수신에 대한 탐구: 확장 API vs 전략 내장 HTTP 서비스
- 무작위 틱커 생성기에 기반한 전략 테스트 방법 논의
- 무작위 시장 생성기에 기반한 전략 테스트 방법을 탐구합니다.
- FMZ Quant의 새로운 기능: _Serve 기능을 사용하여 HTTP 서비스를 쉽게 만들 수 있습니다
- 가상화폐 양적 거래 전략 거래소 구성
- 고주파 전략 백테스팅을 위해 개발된 틱 레벨 트랜잭션 매칭 메커니즘
- 거래 전략 개발 경험
- 양적 거래에서 K 라인 데이터 처리
- 디지털 화폐 정량화 거래 전략 거래소 구성 세부 사항
- "C++ 버전의 OKEX 선물 계약 헤지 전략"
- 거래에서 기계 학습 기술의 적용
- "C++ 버전의 OKEX 계약 헤지 전략"에서 하드 코어 전략을 배우게 됩니다.
- 정렬된 다공간 균형 권익 전략 실현
- 데이터 기반의 기술로 거래를 결합합니다.
- 파이썬으로 듀얼 트러스트 디지털 화폐의 양적 거래 전략을 구현합니다
- K-라인 데이터 처리가 절차적 거래에 대한 소소한 이야기
- 파이썬을 사용하여 가격 동력 분석을 구현하는 양적 거래 전략
- 타임시리즈 데이터 분석 및 틱 데이터 재검토
- 거래 전략 개발 경험 이야기
- DMI 지표의 계산 및 적용
- 양적 거래에서 에너지 기류 (OBV) 지표의 상세한 사용 및 실제 기술
- CTA 전략의 발전과 발명자 계량화 플랫폼의 표준 클래식 라이브러리
- 평행선과 RSI의 상대적으로 강한 약한 지수 포괄 전략의 사용
- 켈트너 채널 거래 전략의 업그레이드 버전
루이시아오1989이 글은 매우 가치있는 글입니다. 배웠습니다. 감사합니다.
선함감사합니다. 감사합니다.