Penjelajahan Awal Menggunakan Python Crawler di FMZ Penjelajahan Kandungan Pengumuman Binance
Penulis:Ninabadass, Dicipta pada: 2022-04-08 15:47:43, Dikemas kini pada: 2022-04-13 10:07:13Penjelajahan Awal Menggunakan Python Crawler di FMZ Penjelajahan Kandungan Pengumuman Binance
Baru-baru ini, saya melihat melalui Forum dan Digest kami, dan tidak ada maklumat yang relevan mengenai crawler Python. Berdasarkan semangat FMZ pembangunan komprehensif, saya hanya belajar tentang konsep dan pengetahuan crawler. Setelah belajar tentangnya, saya mendapati bahawa masih ada lebih banyak yang perlu dipelajari mengenai
Permintaan
Bagi peniaga yang suka perdagangan IPO, mereka selalu ingin mendapatkan maklumat penyenaraian platform secepat mungkin. Jelas tidak realistik untuk menatap laman web platform secara manual sepanjang masa. Kemudian anda perlu menggunakan skrip perayap untuk memantau halaman pengumuman platform, dan mengesan pengumuman baru untuk dimaklumkan dan diingatkan pada kali pertama.
Penjelajahan Awal
Gunakan program yang sangat mudah sebagai permulaan (script perayap yang benar-benar kuat jauh lebih kompleks, jadi ambil masa anda). Logik program sangat mudah, iaitu, biarkan program terus melawat halaman pengumuman platform, menganalisis kandungan HTML yang diperoleh, dan mengesan sama ada kandungan label yang ditentukan dikemas kini.
Pelaksanaan Kod
Anda boleh menggunakan beberapa struktur crawler yang berguna. memandangkan permintaan adalah sangat mudah, anda juga boleh menulis secara langsung.
Perpustakaan Python yang akan digunakan:
```bs4```, which can be simply regarded as the library used to parse the HTML code of web pages.
Code:
dari bs4 import BeautifulSoup Permintaan import
urlBinancePengumuman =
def openUrl ((url):
header = {
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def utama (():
preNews_href =
”`
Operasi
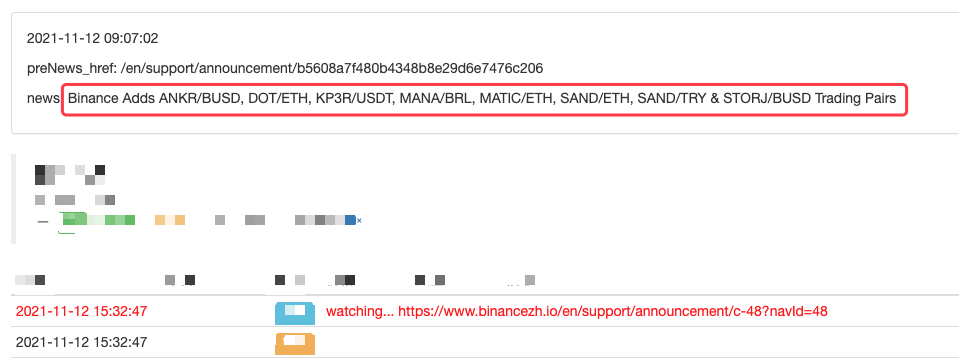
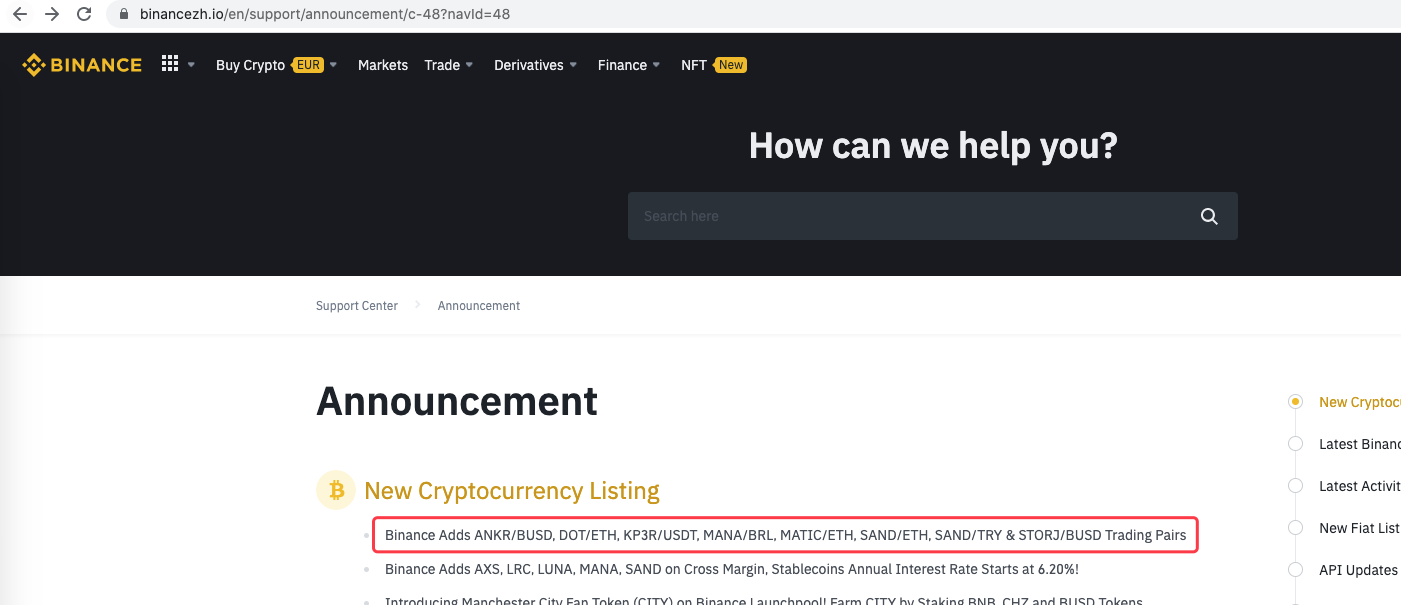
Anda juga boleh memperluaskannya, seperti pengesanan pengumuman baru, analisis simbol mata wang yang baru disenaraikan, dan pesanan automatik perdagangan IPO.
- Menghapuskan pencetakan log
- Batalkan semua pesanan yang belum selesai dalam mata wang semasa
- Permulaan Cepat APP Platform Dagangan Kuantum FMZ
- Memahami Bot Pengawasan Perintah Sederhana Cryptocurrency Spot
- Platform pembayaran berdasarkan FMZ
- Kontrak Cryptocurrency Bot Pengawasan Perintah Sederhana
- Apabila menggunakan getdepth untuk mendapatkan timestamp yang sesuai
- Mengingkari, diselesaikan
- Masalah nilai muka
- Contoh Reka Bentuk Strategi dYdX
- Penyelidikan Reka Bentuk Strategi Hedge & Contoh Perintah Tunggu Spot dan Masa Depan
- Keadaan terkini dan operasi disyorkan strategi kadar pembiayaan
- Strategi titik pemutusan purata bergerak berganda niaga hadapan cryptocurrency (Pengajaran)
- Cryptocurrency Spot Multi-Symbol Dual Moving Average Strategy (Pengajaran)
- Mencapai Fisher Indicator dalam JavaScript & Plotting pada FMZ
- Pengurus
- 2021 Ulasan TAQ Cryptocurrency & Strategi Termudah yang Terlewatkan Peningkatan 10 Kali
- Cryptocurrency Futures Multi-Symbol ART Strategy (Pengajaran)
- Peningkatan! Cryptocurrency Futures Strategi Martingale
- Fungsi Getrecords tidak dapat mendapatkan grafik K dalam unit saat