Máquina de vectores de suporte no cérebro
Autora:Inventor quantificado - sonho pequeno, Criado: 2017-03-23 12:18:01, Atualizado:Máquina de vectores de suporte no cérebro
O SWM é um importante classificador de aprendizado de máquina, que usa a transformação não-linear para projetar características de baixa dimensão em alta dimensão, permitindo a execução de tarefas de classificação mais complexas. O SWM parece usar um truque matemático que coincide com o mecanismo de codificação do cérebro. Título do artigo: A importância da seletividade mista em tarefas cognitivas complexas (by Omri Barak al.)
-
SVM
O primeiro processo é chamado de codificação e o segundo processo é chamado de decodificação. A verdadeira finalidade do decodificação é decifrar os sinais para que eles possam ser decifrados. Portanto, a maneira mais simples de decifrar os sinais usando o visual da aprendizagem de máquinas é usando um classificador, ou até mesmo um modelo logístico, um classificador linear, que trata os sinais de entrada de acordo com certas categorias de características.
Então, vamos ver como a codificação neuronal é feita. Primeiro, os neurônios podem ser considerados como um circuito RC que ajusta a resistência e o capacitor de acordo com a tensão externa. Se o sinal externo for grande o suficiente, ele será conduzido, ou então fechado, representando um sinal pela frequência de descarga em um determinado período de tempo.
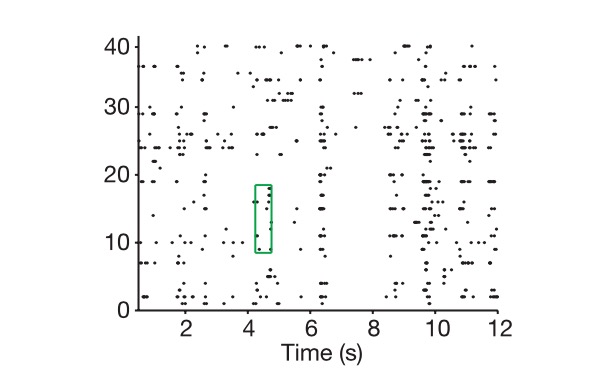
Diagrama: o eixo longitudinal é a célula, o eixo transversal é o tempo, e o diagrama mostra como extraímos o código neural.
Como definir a dimensão real de um código neuronal? Primeiro, entramos no espaço n-dimensional marcado por esse vetor n-dimensional, e depois damos todas as combinações possíveis de tarefas, como mostrar a você mil imagens, assumindo que essas imagens representam o mundo inteiro, marcando o código neuronal como um ponto desse espaço cada vez que obtemos, e, finalmente, usamos o pensamento algébrico de vetores para ver a dimensão do subespaço que compõe esse mil ponto, ou seja, a dimensão real de uma expressão neuronal.
Além da dimensão real da codificação, temos um conceito de dimensão real do sinal externo, onde o sinal refere-se ao sinal externo expresso pela rede neural. É claro que você vai repetir todos os detalhes do sinal externo. É um problema infinito, no entanto, nossa classificação e decisão sempre foram baseadas em características-chave, um processo de diminuição de dimensão.
Então, os cientistas enfrentam uma questão central: por que resolver este problema com uma dimensão de codificação e um número de neurônios muito mais elevados do que o problema real?
E a neurociência computacional e a aprendizagem de máquinas nos dizem que as características de alta dimensão de uma expressão neural são a base de suas capacidades de aprendizagem robustas. Quanto maior a dimensão de codificação, maior a capacidade de aprendizagem.
Observe que a codificação neural discutida aqui se refere principalmente à codificação neural dos centros neurais superiores, como o córtex pré-frontal (PFC) discutido neste artigo, pois a regra de codificação dos centros neurais inferiores não envolve muita classificação e decisão.
A região superior do cérebro representada pela PFC
O mistério da codificação neural é também revelado a partir do número de neurônios N, e a relação entre a dimensão K do problema real (uma diferença que pode chegar a 200 vezes maior). Por que um número aparentemente redundante de neurônios pode causar um salto qualitativo? Primeiro, assumimos que, quando a nossa dimensão de codificação é igual à dimensão das variáveis críticas na tarefa real, não podemos lidar com um problema de classificação não linear usando um classificador linear (assumindo que você vai separar as melancia da melancia, você não pode separar as melancia da melancia com uma fronteira linear), que também é um problema típico que é difícil de resolver no aprendizado profundo e no momento em que o SVM não entrou no aprendizado de máquina.
SVM (suporta vectores):
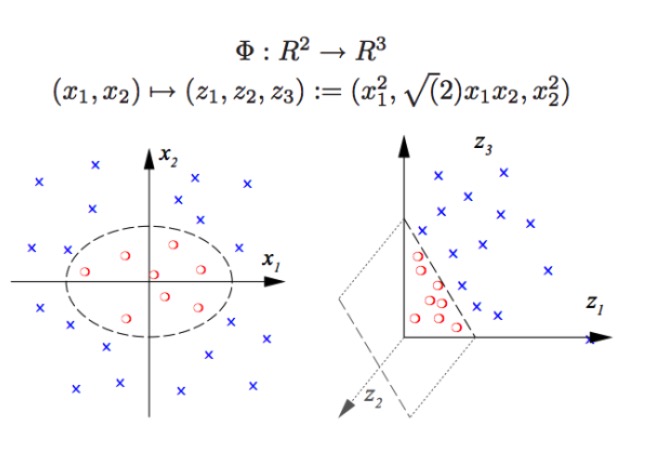
O SVM pode fazer classificações não-lineares, como separar os pontos vermelhos e azuis do gráfico, e não podemos separar os pontos vermelhos e azuis do gráfico com um limite linear (grafico à esquerda), portanto, o método do SVM é aumentar a dimensão. Mas simplesmente aumentar o número de variáveis é impossível, como mapear o sistema x1, x2, x1 + x2 para um espaço linear bidimensional (grafico é um ponto vermelho e um ponto azul em um plano), usando apenas a função não-linear (grafico x1 ^ 2, x1 * x2, x2 ^ 2) temos um cruzamento substancial de baixa dimensão para alta dimensão.
Na verdade, o que as redes neurais reais fazem é exatamente o mesmo. O tipo de classificação que um classificador linear pode fazer aumenta muito, o que significa que temos uma capacidade de reconhecimento de padrões muito mais forte do que antes.
Então, como é que se obtém uma alta dimensão de codificação de neurônios? O número de neurônios ópticos é inútil. Porque aprendemos a algebra linear e sabemos que se tivermos um grande número de neurônios N, e a taxa de descarga de cada neurônio está ligada apenas a uma característica linear K, então a nossa dimensão final de representação será apenas igual à dimensão do problema em si, e os seus N neurônios não têm importância.
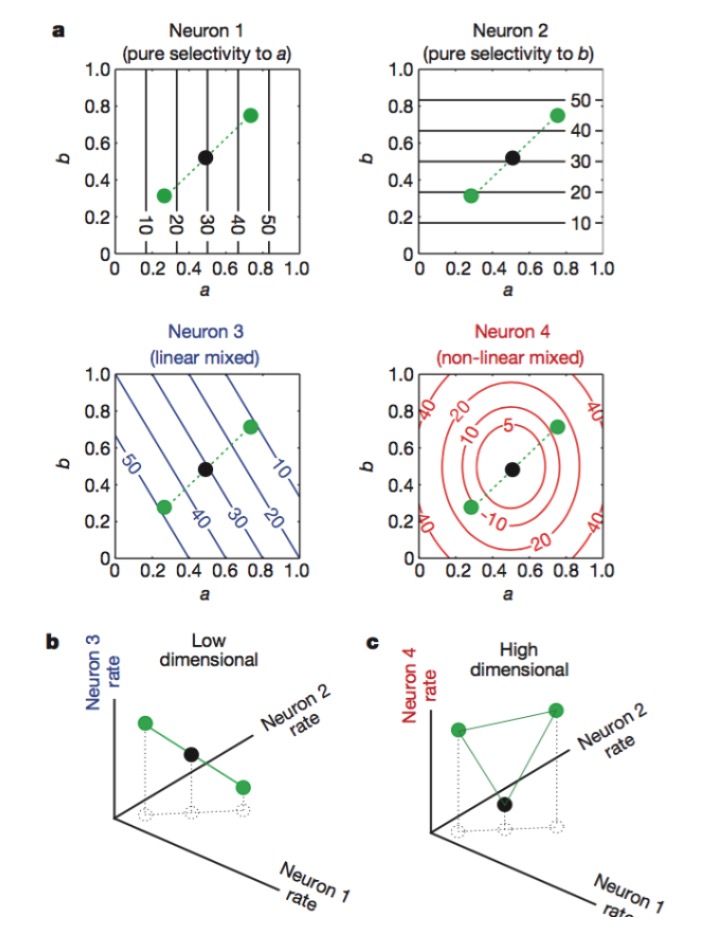
Diagrama: Os neurônios 1 e 2 são sensíveis apenas às características a e b, respectivamente, 3 são sensíveis a misturas lineares de características a e b, e 4 são sensíveis a misturas não lineares de características. Finalmente, apenas a combinação de neurônios 1, 2, 4 aumenta a dimensão de codificação neural (veja abaixo).
O nome oficial desse tipo de codificação é "seletividade mista", que é incompreensível até que se descubra o princípio deste tipo de codificação, porque é uma rede neural que responde a um sinal que parece desordenada. No sistema nervoso periférico, os neurônios funcionam como sensores para extrair diferentes características e reconhecer padrões de sinais. As funções de cada neurônio são bastante específicas, como as hastes e cones da retina, que recebem os fótons, e depois são codificados pela célula gangelion, cada neurônio é como um sentinela treinado profissionalmente.
Todos os detalhes da natureza são concebidos de forma imaginária, com uma grande quantidade de redundância e codificação mista. Esta prática aparentemente desprofissionalizada, com sinais aparentemente confusos, acaba por obter uma melhor capacidade de computação.
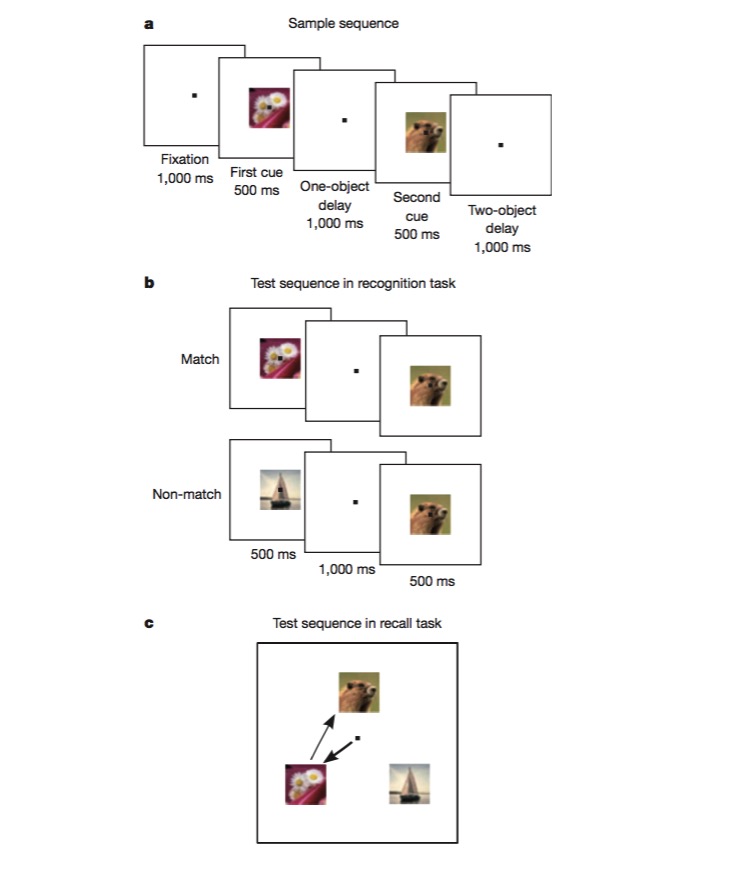
Nessa tarefa, o macaco é treinado para reconhecer se uma imagem é idêntica à anterior, e depois é treinado para julgar a sequência em que duas imagens diferentes aparecem. Para completar essa tarefa, o macaco deve ser capaz de codificar os diferentes lados da tarefa, como o tipo de tarefa (recall ou reconhecimento), o tipo de imagem, etc., e este é o teste perfeito para experimentar se há mecanismos de codificação não-lineares mistos.
Depois de ler este artigo, percebemos que projetar redes neurais pode melhorar significativamente a capacidade de reconhecimento de padrões se introduzir algumas unidades não-lineares, e que o SVM, por acaso, aplicou isso para resolver problemas de classificação não-lineares.
Estudamos o funcionamento das áreas do cérebro, processando os dados usando métodos de aprendizagem de máquina, como encontrar dimensões críticas de problemas com PCA, e depois usando o pensamento de reconhecimento de padrões de aprendizagem de máquina para entender a codificação e codificação de neurônios, e finalmente, se tivermos alguma nova inspiração, podemos melhorar o método de aprendizagem de máquina. Para o cérebro ou para algoritmos de aprendizagem de máquina, o que é mais importante no final das contas é obter a forma mais apropriada de representar a informação, e com uma boa descrição, tudo é mais fácil.
Traduzido por: Xue Xie - Cruzeiro Tecnológico
- MacD, por favor, veja o que está a ser feito.
- Indicador do desempenho das transações de algoritmos de avaliação -- Sharpe ratio
- Um novo tipo de lei de negociação de rede
- Sinto que as cenouras foram cortadas por vocês e eu ainda tenho a moeda.
- Aprender expressões regulares de forma sistemática:
- Aplicações Python e Bayes
- Análise de aplicações de estratégias de negociação de aço e minério de ferro em relação ao valor
- Como analisar a volatilidade das opções?
- Aplicação de programação em opções
- Tempo e ciclo
- Conversando como comerciante e como mãe
- O caminho mais profundo do mundo é o teu caminho: cavar profundamente os poços do lago Sutlej.
- Leia mais Probabilidade, Estatística, Superligação e cinco truques inteligentes para a teoria da probabilidade mais simples que ninguém imagina.
- Trilogia de Gestão de Finanças: Configuração Primeiro
- Eu nunca usaria multiplicações para ganhar dinheiro.
- Termos usados com frequência para a aprendizagem de máquinas e mineração de dados
- Não há previsão, apenas a mudança de preços.
- Ali Cloud Linux está executando um host, o host reiniciou, como recuperar o host original?
- A definição de risco de um investimento em valor é diferente da que você pensa.
- Eu gostaria de perguntar quais plataformas e quais moedas podem ser suportadas por uma moeda virtual.