Exploração inicial da aplicação do Python Crawler no FMZ Crawling Binance Anúncio de conteúdo
Autora:Ninabadass, Criado: 2022-04-08 15:47:43, Atualizado: 2022-04-13 10:07:13Exploração inicial da aplicação do Python Crawler no FMZ Crawling Binance Anúncio de conteúdo
Recentemente, eu olhei através de nossos fóruns e Digest, e não há informações relevantes sobre o rastreador Python. Com base no espírito de desenvolvimento abrangente da FMZ, eu fui simplesmente aprender sobre os conceitos e conhecimentos do rastreador. Depois de aprender sobre isso, descobri que ainda há mais a aprender sobre
Demandas
Para os comerciantes que gostam de negociação de IPO, eles sempre querem obter as informações de listagem da plataforma o mais rápido possível. É obviamente irrealista olhar manualmente para um site da plataforma o tempo todo.
Exploração inicial
Use um programa muito simples para começar (scriptos de rastreador realmente poderosos são muito mais complexos, por isso tome seu tempo). A lógica do programa é muito simples, ou seja, deixe o programa visitar continuamente a página de anúncios de uma plataforma, analisar o conteúdo HTML adquirido e detectar se o conteúdo de um rótulo especificado é atualizado.
Implementação do código
Você pode usar algumas estruturas de rastreador úteis. Considerando que a demanda é muito simples, você também pode escrever diretamente.
As bibliotecas Python a utilizar:
```bs4```, which can be simply regarded as the library used to parse the HTML code of web pages.
Code:
Importação do BeautifulSoup Pedidos de importação
UrlBinanceAnnouncement =
def openUrl ((url):
headers = {
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def main (():
PreNews_href =
”`
Operação
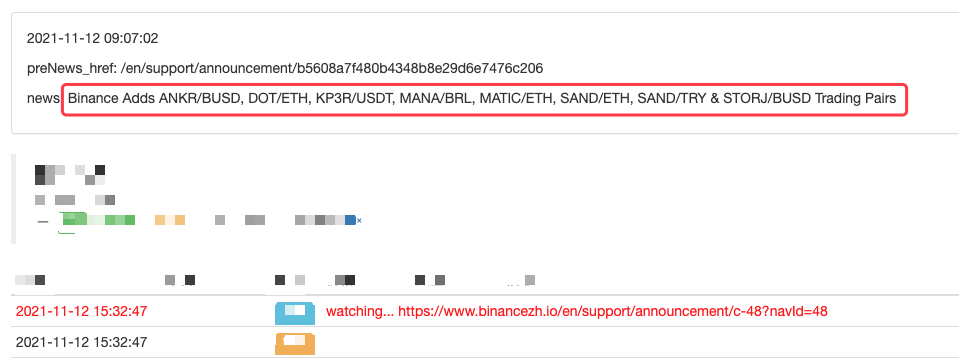
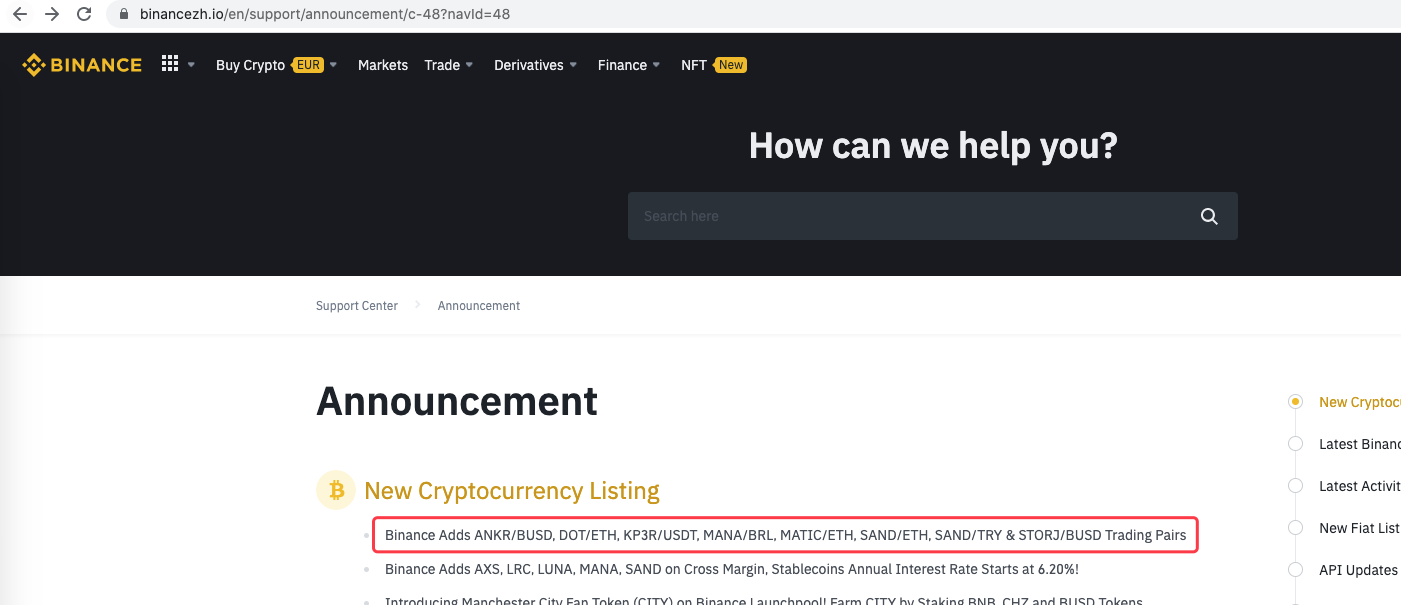
Você pode até estendê-lo, como a detecção de novos anúncios, análise de novos símbolos de moeda listados e ordenação automática de negociação de IPO.
- Cancelar a impressão de um log
- Cancelar todas as ordens pendentes de moedas atuais
- Lançamento rápido da plataforma de negociação quântica FMZ
- Realizar um bot de supervisão de ordens simples do Cryptocurrency Spot
- Baseado no FMZ como plataforma de pagamento
- Contrato de criptomoeda Bot de supervisão de ordens simples
- Quando você quer obter o cronograma correspondente usando o getdepth
- Ignorado, resolvido
- A questão do valor facial
- DYdX Exemplo de Design de Estratégia
- Pesquisa de conceção de estratégias de cobertura e exemplo de ordens pendentes de spot e futuros
- Situação recente e funcionamento recomendado da estratégia de taxa de financiamento
- Estratégia de ponto de ruptura de média móvel dupla de futuros de criptomoedas (Teaching)
- Estratégia de média móvel dupla de símbolos múltiplos de criptomoeda (Teaching)
- Realização de Fisher Indicator em JavaScript & Plotting em FMZ
- Custódia
- 2021 Revisão do TAQ da criptomoeda e estratégia simples perdida de aumento de 10 vezes
- Estratégia ART multi-símbolo de futuros de criptomoedas (Instrução)
- Atualização!
- A função Getrecords não consegue obter K-string em segundos