Crie um bot de negociação de Bitcoin que nunca perca dinheiro
 0
5331
0
5331

Vamos usar o aprendizado por reforço em inteligência artificial para criar um robô de negociação de criptomoedas
Neste artigo, criaremos e aplicaremos uma estrutura de aprendizado por reforço para aprender como criar um bot de negociação de Bitcoin. Neste tutorial, usaremos a academia do OpenAI e o robô PPO da biblioteca stable-baselines, que é uma bifurcação da biblioteca de linhas de base do OpenAI.
Muito obrigado à OpenAI e à DeepMind por fornecerem software de código aberto para pesquisadores de aprendizado profundo nos últimos anos. Se você não viu as conquistas incríveis que eles fizeram com tecnologias como AlphaGo, OpenAI Five e AlphaStar, você pode ter vivido isolado no último ano, mas deveria dar uma olhada.
Treinamento AlphaStar https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Embora não criemos nada impressionante, a negociação de robôs Bitcoin ainda não é uma tarefa fácil no comércio diário. No entanto, como Teddy Roosevelt disse uma vez,
Coisas que vêm muito facilmente não têm valor.
Então, não apenas aprenda a negociar para você mesmo… mas também deixe os robôs negociarem para nós.
plano

Crie um ambiente de academia para nosso robô realizar o aprendizado de máquina
Renderize um ambiente de visualização simples e elegante
Treine nosso robô para aprender uma estratégia de negociação lucrativa
Se você ainda não sabe como criar ambientes de academia do zero ou como simplesmente renderizar visualizações desses ambientes. Sinta-se à vontade para pesquisar um artigo como este no Google antes de continuar. Essas duas ações não serão difíceis nem mesmo para os programadores mais iniciantes.
começando
Neste tutorial, usaremos o conjunto de dados Kaggle gerado pelo Zielak. Se você quiser baixar o código-fonte, ele está disponível no meu repositório Github, junto com o arquivo de dados .csv. Certo, vamos começar.
Primeiro, vamos importar todas as bibliotecas necessárias. Certifique-se de instalar quaisquer bibliotecas que estejam faltando usando o pip.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Em seguida, vamos criar nossa classe para o ambiente. Precisamos passar um dataframe pandas, bem como um initial_balance opcional e um lookback_window_size que determinarão quantos passos de tempo passados o robô observará em cada passo. Definimos a comissão por negociação como padrão para 0,075%, a taxa atual na Bitmex, e o parâmetro serial como padrão falso, o que significa que nosso dataframe será percorrido em partes aleatórias por padrão.
Também chamamos dropna() e reset_index() nos dados, primeiro para remover as linhas com valores NaN e depois para redefinir o índice do número do quadro, já que descartamos os dados.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Nosso action_space é representado aqui como um conjunto de 3 opções (comprar, vender ou manter) e outro conjunto de 10 valores (1⁄10, 2⁄10, 3⁄10 etc.). Ao escolher a ação de compra, compraremos a quantidade * valor do saldo próprio em BTC. Para vender, venderemos o valor * self.btc_held de BTC. É claro que a ação de retenção ignora o valor e não faz nada.
Nosso observation_space é definido como um conjunto de floats contínuos entre 0 e 1, com formato (10, lookback_window_size + 1). + 1 é usado para calcular o passo de tempo atual. Para cada passo de tempo na janela, observaremos o valor OHCLV. Nosso patrimônio líquido é igual à quantidade de BTC comprada ou vendida e ao valor total de USD que gastamos ou recebemos com esses BTC.
Em seguida, precisamos escrever o método reset para inicializar o ambiente.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Aqui usamos self._reset_session e self._next_observation, ainda não os definimos. Vamos defini-los primeiro.
Sessão de Negociação
Uma parte importante do nosso ambiente é o conceito de sessão de negociação. Se implantássemos esse bot fora do mercado, provavelmente nunca o executaríamos por mais do que alguns meses seguidos. Por esse motivo, limitaremos o número de quadros consecutivos em self.df, ou seja, o número de quadros que nosso robô pode ver ao mesmo tempo.
Em nosso método _reset_session, primeiro redefinimos o current_step para 0. Em seguida, definiremos steps_left como um número aleatório entre 1 e MAX_TRADING_SESSION, que definiremos no topo do programa.
MAX_TRADING_SESSION = 100000 # ~2个月
Em seguida, se quisermos iterar sobre os quadros continuamente, devemos configurá-lo para iterar sobre o quadro inteiro, caso contrário, definimos frame_start para um ponto aleatório em self.df e criamos um novo quadro de dados chamado active_df que é apenas self. Uma fatia de df de frame_start a frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Um efeito colateral importante da iteração sobre o número de quadros de dados no fatiamento aleatório é que nosso robô terá mais dados exclusivos para usar ao treinar por um longo tempo. Por exemplo, se simplesmente iterássemos pelo número de quadros de dados de forma serial (ou seja, na ordem de 0 a len(df)), teríamos apenas tantos pontos de dados exclusivos quantos os quadros de dados. Nosso espaço de observação pode adotar apenas um número discreto de estados em cada passo de tempo.
No entanto, ao iterar aleatoriamente sobre fatias do conjunto de dados, podemos criar um conjunto mais significativo de resultados de negociação para cada intervalo de tempo no conjunto de dados inicial, ou seja, uma combinação de ações de negociação e ações de preço vistas anteriormente para criar um conjunto de dados mais exclusivo. Deixe-me explicar isso com um exemplo.
Em um intervalo de tempo de 10 após redefinir o ambiente serial, nosso robô sempre será executado simultaneamente no conjunto de dados e terá 3 opções após cada intervalo de tempo: Comprar, Vender ou Manter. Para cada uma dessas três opções, há outra opção: 10%, 20%, … ou 100% do valor de implementação específico. Isso significa que nosso robô pode encontrar qualquer uma das 103 elevadas a 10, totalizando 1030 situações.
Agora, de volta ao nosso ambiente de fatiamento aleatório. Em um intervalo de tempo de 10, nosso robô pode estar em qualquer intervalo de tempo len(df) dentro do número de quadros de dados. Supondo que a mesma escolha seja feita após cada intervalo de tempo, isso significa que o robô pode passar por qualquer estado único de len(df)30 nos mesmos 10 intervalos de tempo.
Embora isso possa introduzir ruído considerável em grandes conjuntos de dados, acredito que deve permitir que os robôs aprendam mais com a quantidade limitada de dados que temos. Continuaremos iterando nossos dados de teste de forma serial para obter os dados mais recentes, aparentemente em “tempo real”, a fim de obter uma compreensão mais precisa da eficácia do algoritmo.
Pelos olhos de um robô
Muitas vezes é útil ter uma boa visão geral do ambiente para entender os tipos de funções que nosso robô usará. Por exemplo, aqui está uma visualização do espaço observável renderizado usando o OpenCV.

Observação do ambiente de visualização OpenCV
Cada linha na imagem representa uma linha em nosso observation_space. As primeiras 4 linhas de frequência semelhante (linhas vermelhas) representam dados OHCL, e os pontos laranja e amarelos logo abaixo representam volume. A barra azul flutuante abaixo é o patrimônio do bot, enquanto as barras mais claras abaixo representam as negociações do bot.
Se você observar atentamente, poderá até mesmo criar seu próprio gráfico de velas. Abaixo da barra de volume, há uma interface semelhante a código Morse que mostra o histórico de negociações. Parece que nosso bot deve ser capaz de aprender adequadamente com os dados em nosso observation_space, então vamos continuar. Aqui definiremos o método _next_observation, onde escalaremos os dados observados de 0 a 1.
- É importante estender apenas os dados que o robô observou até agora para evitar viés de previsão.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Tome uma atitude
Agora que configuramos nosso espaço de observação, é hora de escrever nossa função de passo e então executar as ações que o robô pretende executar. Sempre que self.steps_left == 0 para nossa sessão de negociação atual, venderemos nossos ativos BTC e chamaremos reset session(). Caso contrário, definimos a recompensa como o patrimônio líquido atual ou definimos “done” como “True” se estivermos sem fundos.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Realizar uma ação de negociação é tão simples quanto obter o current_price, determinar a ação que precisa ser executada e o valor a ser comprado ou vendido. Vamos escrever rapidamente _take_action para que possamos testar nosso ambiente.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Por fim, usando o mesmo método, anexaremos a negociação ao self.trades e atualizaremos nosso patrimônio e histórico da conta.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Nosso robô agora pode iniciar um novo ambiente, percorrer esse ambiente e realizar ações que afetam o ambiente. É hora de vê-los negociar.
Assista nossos robôs negociando
Nosso método render poderia ser tão simples quanto chamar print(self.net_worth) , mas isso não seria interessante o suficiente. Em vez disso, desenharemos um gráfico de velas simples com uma barra de volume e um gráfico separado para nosso patrimônio.
Pegaremos o código em StockTradingGraph.py do meu artigo anterior e o reformularemos para se adequar ao ambiente do Bitcoin. Você pode obter o código do meu Github.
A primeira mudança que faremos é alterar self.df[ [‘Data’] Atualização para self.df[‘Timestamp’] e remova todas as chamadas para date2num, pois nossas datas já estão no formato unix timestamp. Em seguida, em nosso método de renderização, atualizaremos o rótulo de data para imprimir uma data legível em vez de um número.
from datetime import datetime
Primeiro, importaremos a biblioteca datetime, depois usaremos utcfromtimestampmethod para obter a string UTC de cada registro de data e hora e strftime para transformá-la em uma string no formato: A-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Por fim, usaremos self.df[[‘Volume’] é alterado para self.df[‘Volume_(BTC)’] para corresponder ao nosso conjunto de dados e, com isso feito, estamos prontos para começar. Voltando ao nosso BitcoinTradingEnv, agora podemos escrever o método render para exibir o gráfico.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Olhar! Agora podemos assistir nosso robô negociando Bitcoins.

Visualizando as negociações do nosso robô com Matplotlib
Os rótulos fantasmas verdes representam a compra de BTC, e os rótulos fantasmas vermelhos representam a venda. O rótulo branco no canto superior direito é o patrimônio líquido atual do robô, e o rótulo no canto inferior direito é o preço atual do Bitcoin. Simples e elegante. Agora é hora de treinar nosso bot e ver quanto dinheiro podemos ganhar!
Tempo de treinamento
Uma crítica que recebi no meu artigo anterior foi a falta de validação cruzada e a não divisão dos dados em conjuntos de treinamento e teste. O objetivo disso é testar a precisão do modelo final em novos dados nunca vistos antes. Embora este não seja o foco do artigo, é certamente importante. Como estamos trabalhando com dados de séries temporais, não temos muita escolha quando se trata de validação cruzada.
Por exemplo, uma forma comum de validação cruzada é chamada de validação k-fold, na qual você divide os dados em k grupos iguais, separa um dos grupos como grupo de teste e usa o restante dos dados como grupo de treinamento. . No entanto, os dados de séries temporais são altamente dependentes do tempo, o que significa que dados posteriores são altamente dependentes de dados anteriores. Então o k-fold não funcionará porque nosso robô aprenderá com dados futuros antes de negociar, o que é uma vantagem injusta.
As mesmas falhas se aplicam à maioria das outras estratégias de validação cruzada quando aplicadas a dados de séries temporais. Portanto, precisamos usar apenas uma parte do número completo de quadros de dados como o conjunto de treinamento, começando do início do número do quadro até algum índice arbitrário, e usar o restante dos dados como o conjunto de teste.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Em seguida, como nosso ambiente está configurado para manipular apenas um único quadro de dados, criaremos dois ambientes, um para os dados de treinamento e outro para os dados de teste.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Agora, treinar nosso modelo é tão simples quanto criar um robô com nosso ambiente e chamar model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Aqui, usamos o tensorboard para que possamos visualizar facilmente nosso gráfico tensorflow e ver algumas métricas quantitativas sobre nosso robô. Por exemplo, aqui está um gráfico de recompensas com desconto para muitos robôs em 200.000 passos de tempo:
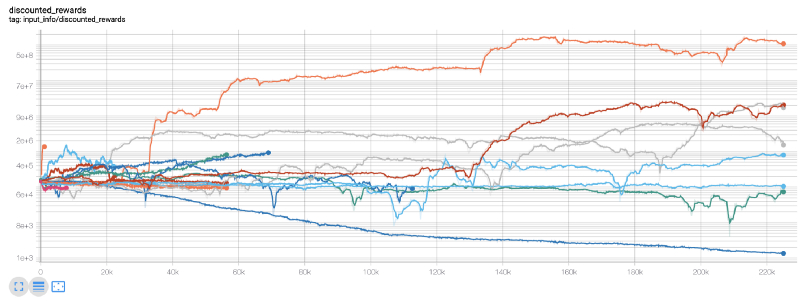
Uau, parece que nosso bot é bem lucrativo! Nosso melhor robô conseguiu atingir um equilíbrio 1.000 vezes melhor ao longo de 200.000 passos, e os demais tiveram uma melhora média de pelo menos 30 vezes!
Foi nesse ponto que percebi que havia um bug no ambiente… Depois de consertar isso, aqui está o novo mapa de recompensas:
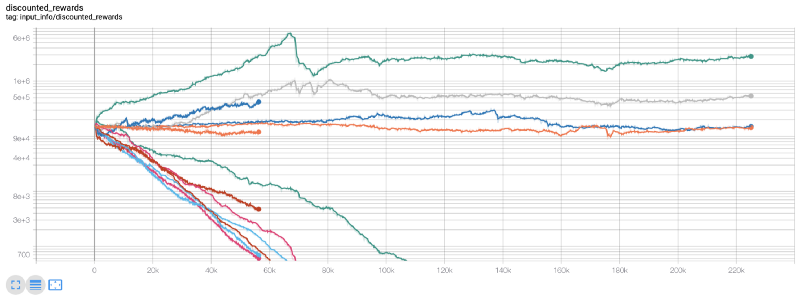
Como você pode ver, alguns dos nossos robôs fizeram um ótimo trabalho, e o resto faliu por conta própria. No entanto, um bot com bom desempenho pode atingir até 10x ou até 60x o saldo inicial. Devo admitir que todos os bots lucrativos são treinados e testados sem comissões, então não é realista que nossos bots ganhem dinheiro de verdade. Mas pelo menos encontramos a direção!
Vamos testar nossos bots em um ambiente de teste (com novos dados que eles nunca viram antes) e ver como eles funcionam.
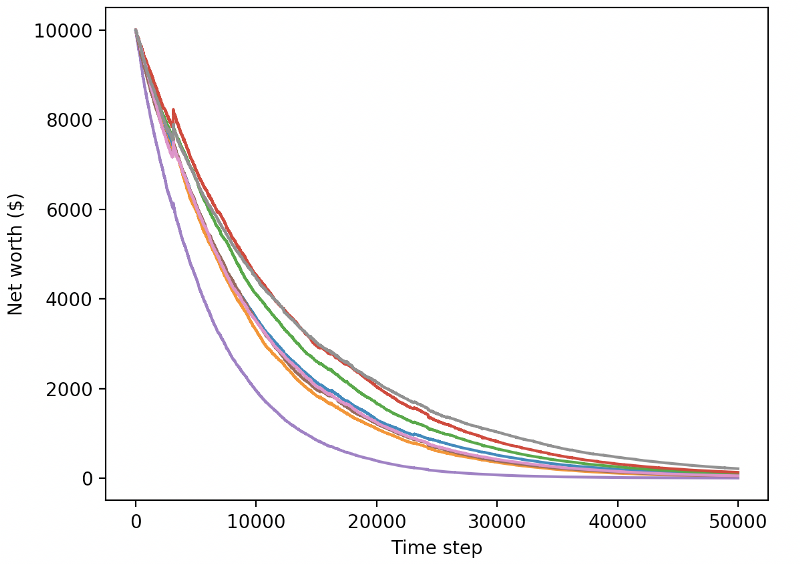
Nosso bot treinado vai à falência ao negociar novos dados de teste
Claramente, ainda temos muito trabalho a fazer. Ao simplesmente mudar o modelo para usar uma linha de base estável A2C, em vez do robô PPO2 atual, podemos melhorar significativamente nosso desempenho neste conjunto de dados. Por fim, seguindo a sugestão de Sean O’Gorman, podemos atualizar ligeiramente nossa função de recompensa para adicionar recompensas ao patrimônio líquido, em vez de apenas atingir um patrimônio líquido alto e deixá-lo lá.
reward = self.net_worth - prev_net_worth
Essas duas mudanças por si só melhoram significativamente o desempenho no conjunto de dados de teste e, como você pode ver abaixo, finalmente conseguimos obter lucratividade em novos dados que não estavam no conjunto de treinamento.
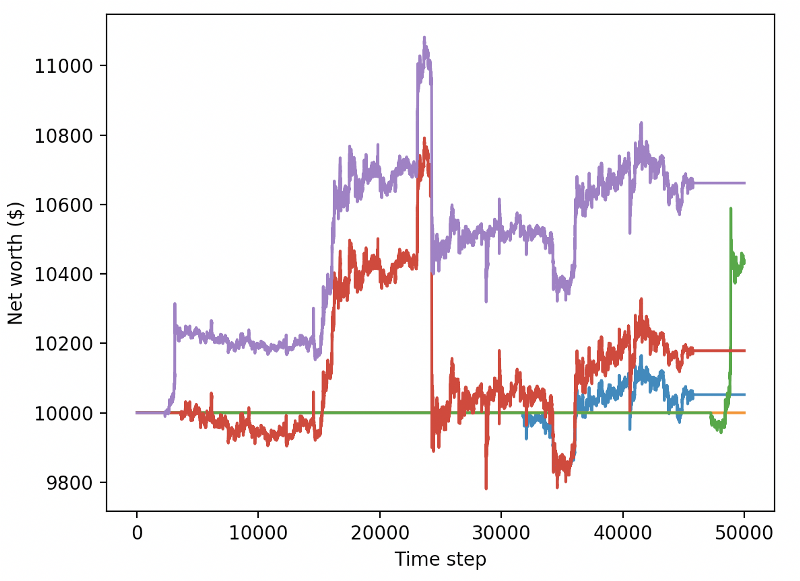
Mas podemos fazer melhor. Para melhorar esses resultados, precisamos otimizar nossos hiperparâmetros e treinar nosso bot por mais tempo. É hora de fazer sua GPU funcionar a todo vapor!
Este post ficou um pouco longo neste ponto, e ainda temos muitos detalhes a considerar, então faremos uma pausa aqui. No próximo post, usaremos a Otimização Bayesiana para particionar os melhores hiperparâmetros para nosso espaço de problemas e nos preparar para treinamento/teste em GPUs usando CUDA.
para concluir
Neste artigo, pretendemos criar um bot de negociação de Bitcoin lucrativo do zero usando aprendizado por reforço. Podemos realizar as seguintes tarefas:
Crie um ambiente de negociação de Bitcoin do zero usando o ginásio da OpenAI.
Use o Matplotlib para criar uma visualização do ambiente.
Treine e teste nosso bot usando validação cruzada simples.
Ajuste ligeiramente nosso robô para obter lucratividade
Embora nosso robô de negociação não seja tão lucrativo quanto gostaríamos, estamos indo na direção certa. Da próxima vez, garantiremos que nosso bot consiga superar o mercado de forma consistente e veremos como nosso bot de negociação se sai em dados ao vivo. Fique ligado no meu próximo artigo e Vida Longa ao Bitcoin!