Cotações de mercado coletor atualizar novamente
Autora:Bem-estar, Criado: 2020-05-26 14:25:15, Atualizado: 2024-12-10 20:35:48
Suporte à importação de arquivos em formato CSV para fornecer fonte de dados personalizada
Recentemente, um comerciante precisa usar seu próprio arquivo em formato CSV como fonte de dados para o sistema de backtest da plataforma FMZ. nosso sistema de backtest da plataforma tem muitas funções e é simples e eficiente de usar, de modo que, desde que os usuários tenham seus próprios dados, eles podem realizar backtesting de acordo com esses dados, o que não está mais limitado às exchanges e variedades suportadas pelo nosso centro de dados da plataforma.
Ideias de design
A ideia de design é realmente muito simples. só precisamos de mudá-lo ligeiramente com base no coletor de mercado anterior.isOnlySupportCSVO parâmetro de repatriação de dados para o sistema de backtest é o parâmetro de repatriação de dados para o sistema de backtest.filePathForCSVA função de selecção de um caminho para o ficheiro de dados CSV colocado no servidor onde o robô coletor de mercado é executado.isOnlySupportCSVO parâmetro está definido emTruePara decidir qual a fonte de dados a utilizar (coletada por si ou os dados no ficheiro CSV), esta alteração é essencialmente nado_GETFunção doProvider class.
O que é um ficheiro CSV?
Valores separados por vírgulas, também conhecidos como CSV, às vezes referidos como valores separados por caracteres, porque o caráter separador também não pode ser uma vírgula. Seu arquivo armazena os dados da tabela (números e texto) em texto simples. O texto simples significa que o arquivo é uma sequência de caracteres e não contém dados que devem ser interpretados como um número binário. O arquivo CSV consiste em qualquer número de registros, separados por algum caráter de linha nova; cada registro é composto por campos, e os separadores entre os campos são outros caracteres ou strings, e os mais comuns são vírgulas ou guias. Geralmente, todos os registros têm a mesma sequência exata de campos. Geralmente são arquivos de texto simples.WORDPADouExcelpara abrir.
O padrão geral do formato de arquivo CSV não existe, mas existem certas regras, geralmente um registro por linha, e a primeira linha é o cabeçalho.
Por exemplo, o arquivo CSV que usamos para testes é aberto com o bloco de notas assim:
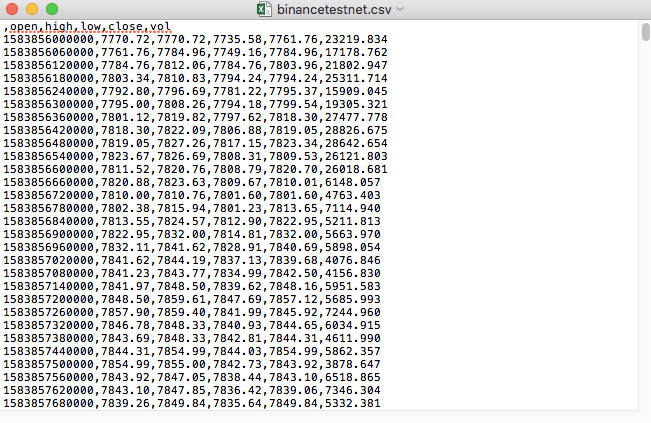
Observado que a primeira linha do ficheiro CSV é o cabeçalho da tabela.
,open,high,low,close,vol
Nós só precisamos de analisar e classificar esses dados, e depois construí-lo no formato exigido pela fonte de dados personalizada do sistema de backtest.
Código modificado
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Teste de execução
Primeiro, ligamos o robô coletor do mercado, adicionamos uma troca ao robô e deixamos o robô funcionar.
Configuração do parâmetro:

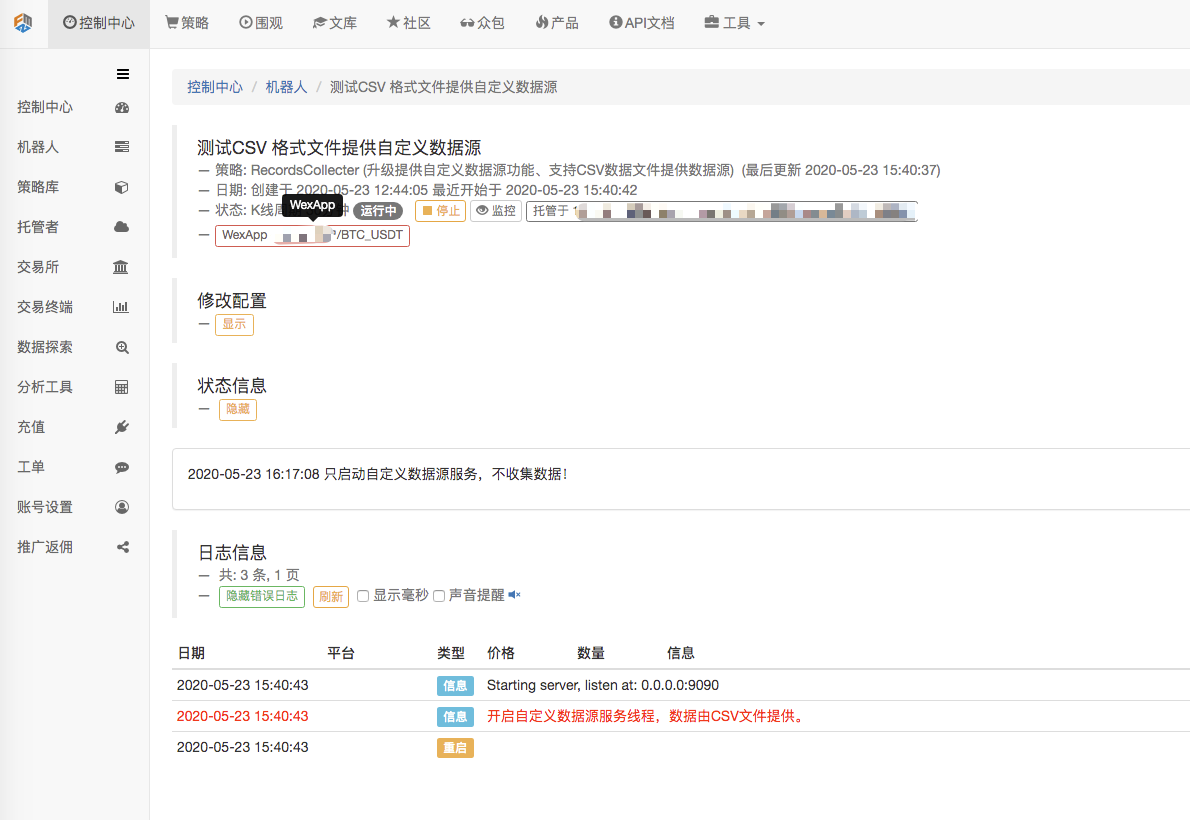
Depois criamos uma estratégia de teste:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
A estratégia é muito simples, basta obter e imprimir dados da linha K três vezes.
Na página de backtest, defina a fonte de dados do sistema de backtest como uma fonte de dados personalizada e preencha o endereço do servidor onde o robô coletor de mercado é executado.
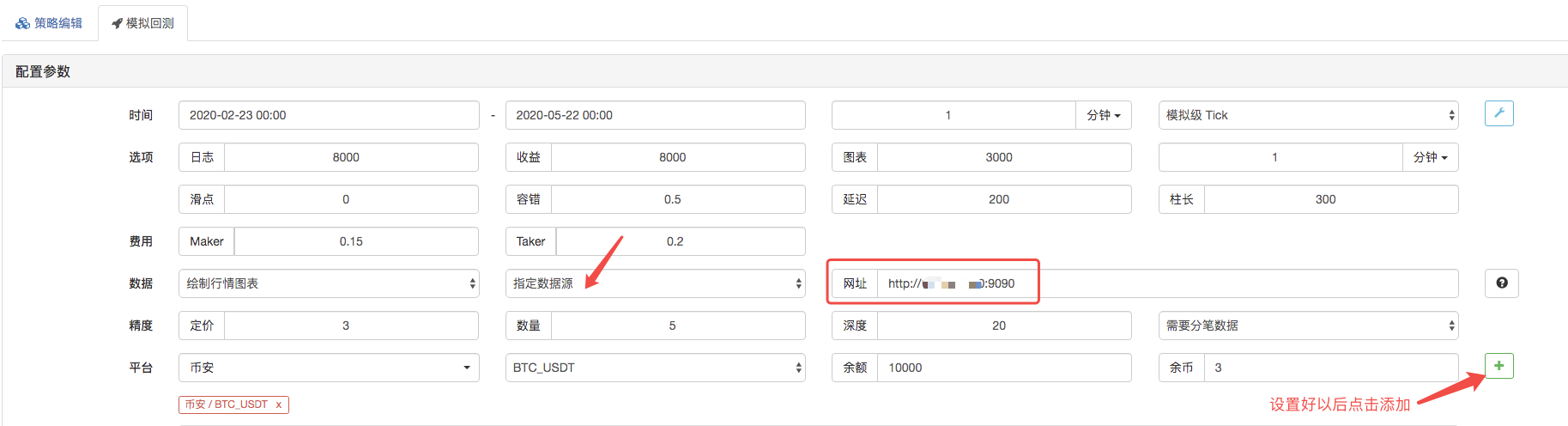
Clique para iniciar o backtest, e o robô coletor de mercado recebe o pedido de dados:

Após a conclusão da estratégia de execução do sistema de backtest, é gerado um gráfico de linhas K com base nos dados de linhas K da fonte de dados.
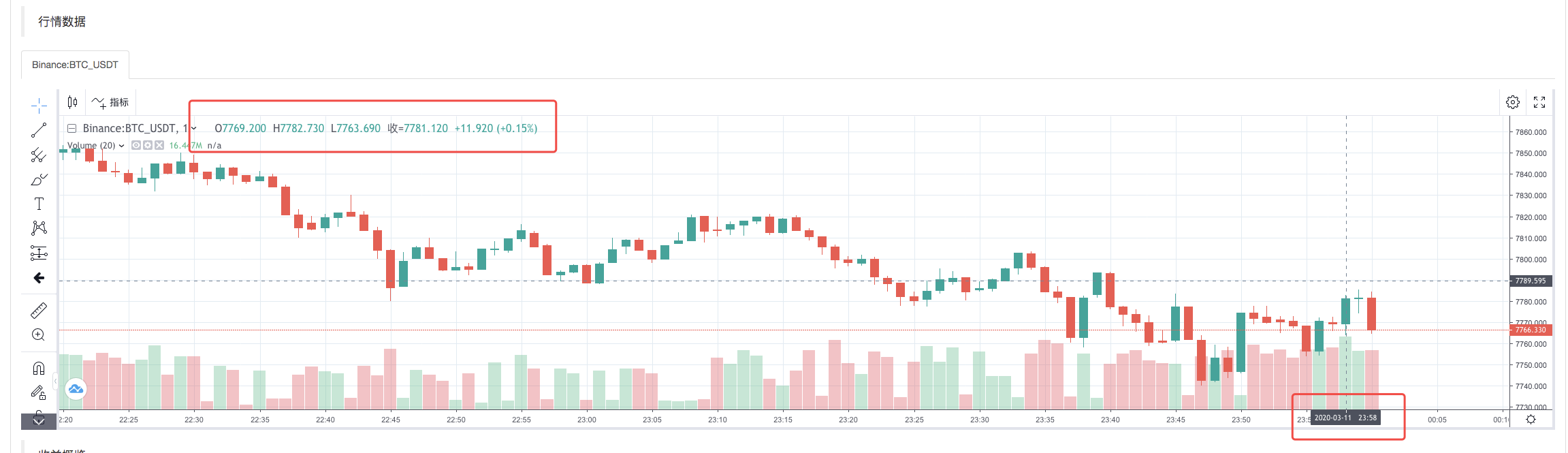
Compare os dados do ficheiro:

- Introdução ao conjunto de Lead-Lag na moeda digital (3)
- Introdução à arbitragem de lead-lag em criptomoedas (2)
- Introdução ao suporte de Lead-Lag na moeda digital (2)
- Discussão sobre a recepção de sinais externos da plataforma FMZ: uma solução completa para receber sinais com serviço HTTP em estratégia
- Discussão da recepção de sinais externos da plataforma FMZ: estratégias para o sistema completo de recepção de sinais do serviço HTTP embutido
- Introdução à arbitragem de lead-lag em criptomoedas (1)
- Introdução ao suporte de Lead-Lag na moeda digital
- Discussão sobre a recepção de sinais externos da plataforma FMZ: API estendida VS estratégia Serviço HTTP integrado
- Exploração da recepção de sinais externos da plataforma FMZ: API de extensão vs estratégia de serviços HTTP embutidos
- Discussão sobre o método de teste de estratégia baseado no gerador de tickers aleatórios
- Métodos de teste de estratégias baseados em geradores de mercado aleatórios
- Alguns pensamentos sobre a lógica da negociação de futuros de criptomoedas
- Ferramenta de análise avançada baseada no desenvolvimento da gramática Alpha101
- Ensinar-lhe a atualizar o coletor de mercado backtest a fonte de dados personalizados
- Deficiência do sistema de retorno de alta frequência baseado em transações por papel e retorno de linha K
- Explicação do mecanismo de backtest do nível de simulação FMZ
- A melhor maneira de instalar e atualizar FMZ docker no Linux VPS
- Estratégia R-Breaker de Futuros de Commodities
- Uma reflexão sobre a lógica de negociação de futuros em moeda digital
- Ensinar-lhe a implementar um coletor de cotações de mercado
- Versão Python Commodity Futures Moving Average Estratégia
- Reaproveitamento do coletor de transações - suporte à importação de arquivos no formato CSV para fornecer fontes de dados personalizadas
- Commodity Futures High Frequency Trading Strategy escrito em C++
- Larry Connors RSI2 Estratégia de Reversão Mean
- A mão de Oak ensinou-lhe a usar o JS para pautar a API de extensão FMZ
- Baseado na utilização de um novo índice de força relativa nas estratégias intradiárias
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 4
- Larry Connors Larry Connors RSI2 estratégia de retorno da média
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 3
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 2
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 1