Создайте бота для торговли биткоинами, который никогда не теряет деньги
 0
5331
0
5331

Давайте используем обучение с подкреплением в искусственном интеллекте, чтобы создать робота для торговли криптовалютой
В этой статье мы создадим и применим структуру обучения с подкреплением, чтобы научиться создавать бота для торговли биткоинами. В этом уроке мы будем использовать тренажерный зал OpenAI и робота PPO из библиотеки stable-baselines, которая является ответвлением библиотеки базовых линий OpenAI.
Большое спасибо OpenAI и DeepMind за предоставление программного обеспечения с открытым исходным кодом исследователям глубокого обучения на протяжении последних нескольких лет. Если вы не видели их удивительных достижений с такими технологиями, как AlphaGo, OpenAI Five и AlphaStar, возможно, вы весь последний год жили в изоляции, но вам стоит на них взглянуть.
Обучение AlphaStar https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Хотя мы и не создадим ничего впечатляющего, торговля биткоин-роботами все еще остается непростой задачей в повседневной торговле. Однако, как однажды сказал Тедди Рузвельт:
Вещи, которые даются слишком легко, не имеют никакой ценности.
Поэтому не только учитесь торговать сами… но и позвольте роботам торговать за вас.
план

Создайте спортивную среду, в которой наш робот сможет выполнять машинное обучение.
Создайте простую и элегантную среду визуализации.
Обучим нашего робота прибыльной торговой стратегии
Если вы еще не знакомы с тем, как создавать обстановку в спортзале с нуля или как просто визуализировать эту обстановку. Прежде чем продолжить, не стесняйтесь поискать в Google подобную статью. Эти два действия не вызовут затруднений даже у самых начинающих программистов.
начиная
В этом уроке мы будем использовать набор данных Kaggle, сгенерированный Zielak. Если вы хотите загрузить исходный код, он доступен в моем репозитории Github вместе с файлом данных .csv. Хорошо, начнем.
Для начала импортируем все необходимые библиотеки. Обязательно установите все недостающие библиотеки с помощью pip.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Далее давайте создадим наш класс для среды. Нам необходимо передать фрейм данных pandas, а также необязательные initial_balance и lookback_window_size, которые будут определять, сколько прошлых временных шагов робот будет наблюдать на каждом шаге. По умолчанию мы устанавливаем комиссию за сделку на уровне 0,075%, что соответствует текущему курсу на Bitmex, а для последовательного параметра по умолчанию установлено значение false, что означает, что по умолчанию наш фрейм данных будет обрабатываться случайными фрагментами.
Мы также вызываем dropna() и reset_index() для данных, сначала для удаления строк со значениями NaN, а затем для сброса индекса для номера кадра, поскольку мы удалили данные.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Наше action_space представлено здесь как набор из 3 вариантов (купить, продать или удерживать) и еще один набор из 10 сумм (1⁄10, 2⁄10, 3⁄10 и т. д.). При выборе действия «Купить» мы купим сумму, равную вашему балансу в BTC. Для продажи мы продадим сумму * self.btc_held в BTC. Конечно, действие удержания игнорирует сумму и ничего не делает.
Наше observation_space определяется как набор непрерывных чисел с плавающей точкой от 0 до 1 с формой (10, lookback_window_size + 1). + 1 используется для расчета текущего временного шага. Для каждого временного шага в окне мы будем наблюдать значение OHCLV. Наш чистый капитал равен сумме купленных или проданных BTC и общей сумме долларов США, которую мы потратили или получили за эти BTC.
Далее нам необходимо написать метод сброса для инициализации среды.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Здесь мы используем self._reset_session и себя._next_observation, мы их еще не определили. Давайте сначала дадим им определения.
Торговая сессия
Важной частью нашей среды является концепция торговой сессии. Если бы мы развернули этого бота за пределами рынка, мы, вероятно, никогда не запустили бы его дольше нескольких месяцев подряд. По этой причине мы ограничим количество последовательных кадров в self.df, то есть количество кадров, которые наш робот может видеть одновременно.
В нашем методе _reset_session мы сначала сбрасываем current_step на 0. Далее мы установим steps_left на случайное число от 1 до MAX_TRADING_SESSION, которое мы определим в верхней части программы.
MAX_TRADING_SESSION = 100000 # ~2个月
Далее, если мы хотим непрерывно перебирать кадры, мы должны настроить его на перебор всего кадра, в противном случае мы устанавливаем frame_start на случайную точку в self.df и создаем новый кадр данных с именем active_df, который является просто self. Срез из df от frame_start до frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Важным побочным эффектом итерации по количеству кадров данных при случайной нарезке является то, что у нашего робота будет больше уникальных данных для использования при обучении в течение длительного времени. Например, если бы мы просто последовательно перебирали количество кадров данных (т. е. в порядке от 0 до len(df)), то у нас было бы столько уникальных точек данных, сколько их в количестве кадров данных. Наше пространство наблюдения может принимать лишь дискретное число состояний на каждом временном шаге.
Однако, путем случайной итерации по срезам набора данных, мы можем создать более значимый набор результатов торговли для каждого временного шага в исходном наборе данных, т. е. комбинацию торговых действий и ранее наблюдавшегося ценового действия для создания более уникального набора данных. Позвольте мне объяснить это на примере.
При временном шаге 10 после сброса последовательной среды наш робот всегда будет работать одновременно в наборе данных и будет иметь 3 варианта выбора после каждого временного шага: купить, продать или удержать. Для каждого из этих трех вариантов есть еще один вариант: 10%, 20%, … или 100% от конкретной суммы реализации. Это означает, что наш робот может столкнуться с любой из 103 в десятой степени, то есть в общей сложности с 1030 ситуациями.
Теперь вернемся к нашей среде случайной нарезки. При временном шаге 10 наш робот может находиться на любых len(df) временных шагах в пределах количества кадров данных. Если предположить, что после каждого временного шага делается один и тот же выбор, это означает, что робот может пройти через любое уникальное состояние len(df)30 за те же 10 временных шагов.
Хотя это может внести значительный шум в большие наборы данных, я считаю, что это должно позволить роботам извлечь больше информации из ограниченного объема имеющихся у нас данных. Мы по-прежнему будем последовательно проходить по нашим тестовым данным, чтобы получить самые свежие, по-видимому, «реальные» данные и получить более точное представление об эффективности алгоритма.
Глазами робота
Часто бывает полезно иметь хороший визуальный обзор окружающей среды, чтобы понять, какие функции будет использовать наш робот. Например, вот визуализация наблюдаемого пространства, полученная с помощью OpenCV.

Наблюдение за средой визуализации OpenCV
Каждая строка на изображении представляет собой строку в нашем пространстве_наблюдений. Первые 4 линии с одинаковой частотой (красные линии) представляют данные OHCL, а оранжевые и желтые точки чуть ниже представляют объем. Колеблющаяся синяя полоса ниже — это капитал бота, а более светлые полоски ниже представляют сделки бота.
Если присмотреться, то можно даже построить свой собственный график японских свечей. Под полосой объема находится интерфейс, напоминающий азбуку Морзе, показывающий историю торговли. Похоже, наш бот должен уметь адекватно обучаться на основе данных в нашем observation_space, поэтому давайте продолжим. Здесь мы определим метод _next_observation, в котором мы будем масштабировать наблюдаемые данные от 0 до 1.
- Важно расширять только те данные, которые робот наблюдал на данный момент, чтобы избежать смещения вперед.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Принять меры
Теперь, когда у нас настроено пространство наблюдения, пришло время написать нашу ступенчатую функцию, а затем выполнить действия, которые намеревается выполнить робот. Всякий раз, когда self.steps_left == 0 для нашей текущей торговой сессии, мы продадим наши активы BTC и вызовем reset session(). В противном случае мы устанавливаем вознаграждение равным текущему размеру капитала или устанавливаем done на True, если у нас закончились средства.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Совершить торговое действие так же просто, как получить текущую цену, определить действие, которое необходимо выполнить, и сумму для покупки или продажи. Давайте быстро напишем _take_action, чтобы мы могли протестировать нашу среду.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Наконец, тем же методом мы добавим сделку в self.trades и обновим наш капитал и историю счета.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Теперь наш робот может создавать новую среду, перемещаться по ней и совершать действия, влияющие на окружающую среду. Пришло время понаблюдать за их торговлей.
Посмотрите, как торгуют наши роботы
Наш метод рендеринга мог бы быть таким же простым, как вызов print(self.net_worth) , но это было бы недостаточно интересно. Вместо этого мы нарисуем простой график свечей с полосой объема и отдельный график для нашего капитала.
Мы возьмем код StockTradingGraph.py из моей предыдущей статьи и переработаем его для соответствия среде Bitcoin. Код можно получить на моем Github.
Первое изменение, которое мы собираемся сделать, это изменить self.df.[ ‘Дата’] Обновление self.df[‘Timestamp’] и удалить все вызовы date2num, так как наши даты уже находятся в формате временной метки unix. Далее в нашем методе рендеринга мы обновим метку даты, чтобы вывести понятную человеку дату вместо числа.
from datetime import datetime
Сначала мы импортируем библиотеку datetime, затем воспользуемся методом utcfromtimestamp, чтобы получить строку UTC из каждой временной метки, и strftime, чтобы преобразовать ее в строку в формате Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Наконец, мы будем использовать self.df[‘Volume’] изменен на self.df[‘Volume_(BTC)’] для соответствия нашему набору данных, и после этого мы готовы к работе. Возвращаясь к нашему BitcoinTradingEnv, теперь мы можем написать метод рендеринга для отображения графика.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Смотреть! Теперь мы можем наблюдать, как наш робот торгует биткоинами.

Визуализация торговли нашего робота с помощью Matplotlib
Зеленые фантомные метки обозначают покупку BTC, а красные фантомные метки обозначают продажу. Белая метка в правом верхнем углу — это текущая чистая стоимость робота, а метка в правом нижнем углу — это текущая цена биткоина. Просто и элегантно. Теперь пришло время обучить нашего бота и посмотреть, сколько денег мы сможем заработать!
Время обучения
Одной из критических замечаний, высказанных мной в предыдущей статье, было отсутствие перекрестной проверки и разделения данных на обучающие и тестовые наборы. Целью этого является проверка точности окончательной модели на новых данных, которые ранее не встречались. Хотя это и не является темой данной статьи, это, безусловно, важно. Поскольку мы работаем с данными временных рядов, у нас нет особого выбора при проведении перекрестной проверки.
Например, распространенная форма перекрестной проверки называется k-кратной проверкой, при которой данные разбиваются на k равных групп, одна из групп выделяется в качестве тестовой, а остальные данные используются в качестве обучающей группы. . Однако данные временных рядов сильно зависят от времени, а это означает, что более поздние данные сильно зависят от более ранних данных. Таким образом, k-fold не сработает, поскольку наш робот будет учиться на будущих данных перед совершением сделки, что является несправедливым преимуществом.
Те же недостатки свойственны большинству других стратегий перекрестной проверки при применении к данным временных рядов. Поэтому нам нужно использовать только часть полного числа кадров данных в качестве обучающего набора, начиная с начала номера кадра до некоторого произвольного индекса, а остальные данные использовать в качестве тестового набора.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Далее, поскольку наша среда настроена на обработку только одного кадра данных, мы создадим две среды: одну для обучающих данных и одну для тестовых данных.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Теперь обучение нашей модели так же просто, как создание робота с нашей средой и вызов model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Здесь мы используем tensorboard, чтобы можно было легко визуализировать наш график tensorflow и увидеть некоторые количественные показатели нашего робота. Например, вот график скидок на вознаграждения для многих роботов за 200 000 временных шагов:
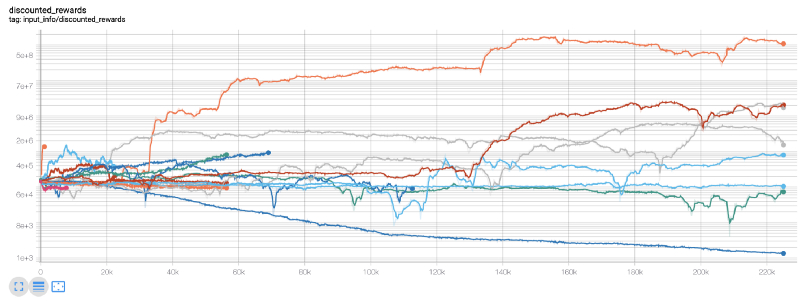
Ого, похоже, наш бот весьма прибыльный! Наш лучший робот даже смог достичь в 1000 раз лучшего равновесия за 200 000 шагов, а остальные в среднем показали как минимум 30-кратное улучшение!
Именно в этот момент я понял, что в окружении есть ошибка… После ее исправления вот новая карта наград:
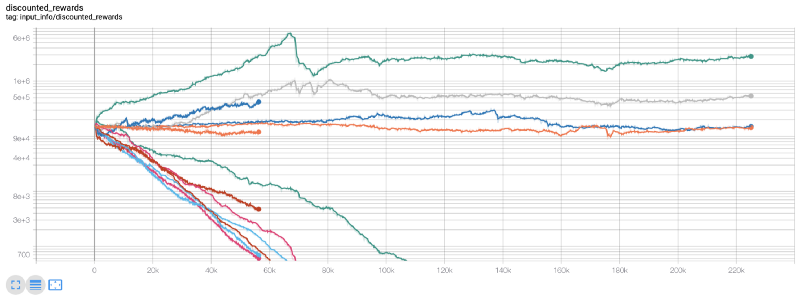
Как видите, некоторые из наших роботов отлично справились с работой, а остальные обанкротились сами по себе. Однако хорошо работающий бот может достичь увеличения первоначального баланса в 10 или даже 60 раз. Должен признать, что все прибыльные боты обучаются и тестируются без комиссий, поэтому для наших ботов нереально заработать реальные деньги. Но, по крайней мере, мы нашли направление!
Давайте протестируем наших ботов в тестовой среде (с новыми данными, с которыми они никогда раньше не сталкивались) и посмотрим, как они себя поведут.
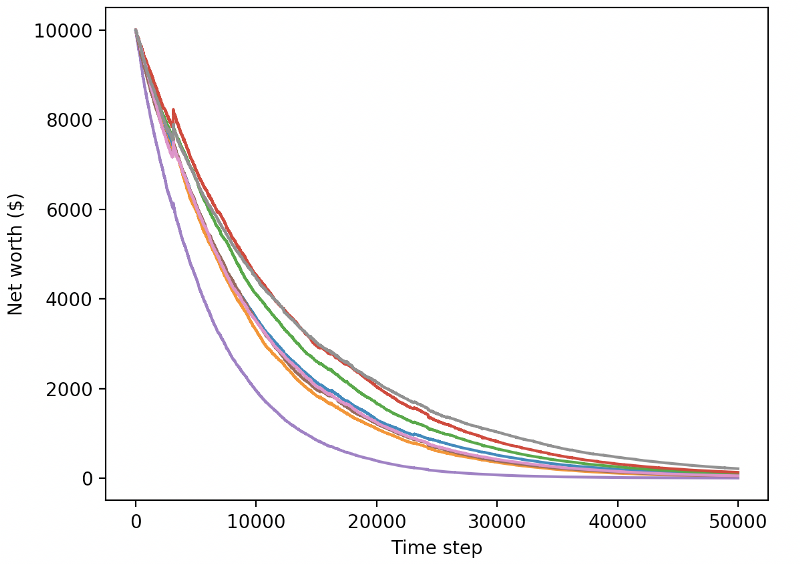
Наш обученный бот разоряется при торговле новыми тестовыми данными
Очевидно, нам еще предстоит много работы. Просто переключив модель на использование стабильного базового уровня A2C вместо текущего робота PPO2, мы можем значительно улучшить нашу производительность на этом наборе данных. Наконец, следуя предложению Шона О’Гормана, мы можем немного обновить нашу функцию вознаграждения, чтобы добавлять вознаграждения к чистому капиталу, а не просто достигать высокого чистого капитала и оставлять его на этом уровне.
reward = self.net_worth - prev_net_worth
Эти два изменения сами по себе значительно улучшают производительность на тестовом наборе данных, и, как вы можете видеть ниже, мы наконец-то можем добиться прибыльности на новых данных, которых не было в обучающем наборе.
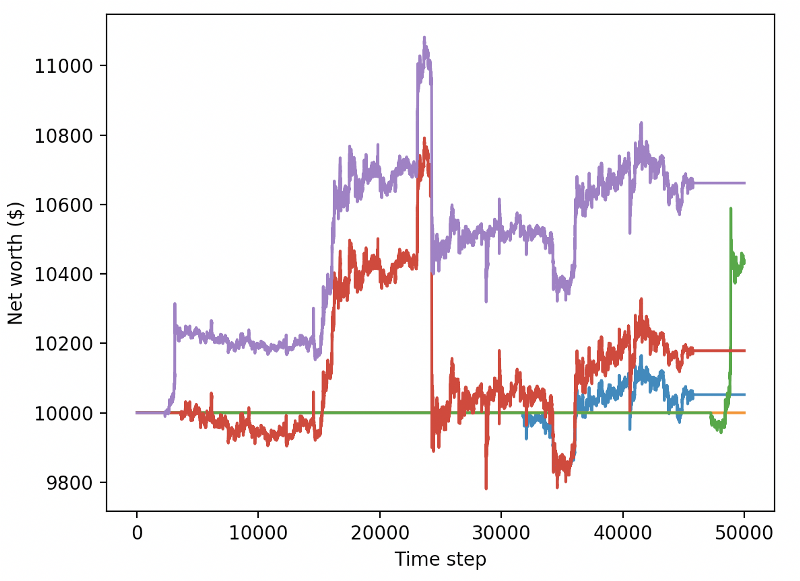
Но мы можем добиться большего. Чтобы улучшить эти результаты, нам необходимо оптимизировать наши гиперпараметры и обучать нашего бота дольше. Пришло время заставить ваш графический процессор работать на полную мощность!
На данный момент этот пост получился немного длинным, а нам еще предстоит учесть множество деталей, поэтому мы сделаем перерыв. В следующей статье мы воспользуемся байесовской оптимизацией для выделения наилучших гиперпараметров для нашего проблемного пространства и подготовимся к обучению/тестированию на графических процессорах с использованием CUDA.
в заключение
В этой статье мы намереваемся создать прибыльного бота для торговли биткоинами с нуля, используя обучение с подкреплением. Мы можем выполнить следующие задачи:
Создайте среду для торговли биткоинами с нуля, используя тренажерный зал OpenAI.
Используйте Matplotlib для построения визуализации окружающей среды.
Обучите и протестируйте нашего бота, используя простую перекрестную проверку.
Немного доработаем нашего робота, чтобы добиться прибыльности
Хотя наш торговый робот не так прибыльен, как нам бы хотелось, мы движемся в правильном направлении. В следующий раз мы убедимся, что наш бот может стабильно опережать рынок, и посмотрим, как наш торговый бот покажет себя на реальных данных. Оставайтесь с нами для прочтения моей следующей статьи, и да здравствует Биткоин!