Рыночные котировки коллектор обновление снова
Автор:Доброта, Создано: 2020-05-26 14:25:15, Обновлено: 2024-12-10 20:35:48
Поддержка импорта файлов в формате CSV для предоставления источника данных
В последнее время трейдеру необходимо использовать свой собственный файл формата CSV в качестве источника данных для системы бэкстеста платформы FMZ. Система бэкстеста нашей платформы имеет много функций и проста и эффективна в использовании, так что до тех пор, пока пользователи имеют свои собственные данные, они могут выполнять бэкстестинг в соответствии с этими данными, что больше не ограничивается биржами и сортами, поддерживаемыми нашим центром обработки данных платформы.
Идеи дизайна
Идея дизайна на самом деле очень проста. нам нужно только немного изменить ее на основе предыдущего коллектора рынка. мы добавляем параметрisOnlySupportCSVдля того, чтобы контролировать, используется ли только файл CSV в качестве источника данных для системы бэкстеста.filePathForCSVИспользуется для установки пути CSV файла данных, размещенного на сервере, где работает робот сборщик рынка.isOnlySupportCSVпараметр установлен наTrueДля того, чтобы решить, какой источник данных использовать (собранный самим или данные в файле CSV), это изменение происходит главным образом вdo_GETФункцияProvider class.
Что такое файл CSV?
Файл хранит данные таблицы (числа и текст) в простом тексте. Простой текст означает, что файл представляет собой последовательность символов и не содержит данных, которые должны быть интерпретированы как двоичное число. Файл CSV состоит из любого числа записей, разделенных каким-либо новым символом; каждая запись состоит из полей, а разделителями между полями являются другие символы или строки, а наиболее распространенными являются запятые или вкладки.WORDPADилиExcelоткрыть.
Общий стандарт формата файла CSV не существует, но существуют определенные правила, как правило, одна запись на строку, а первая строка - заголовок.
Например, файл CSV, который мы использовали для тестирования, открывается в блокноте так:
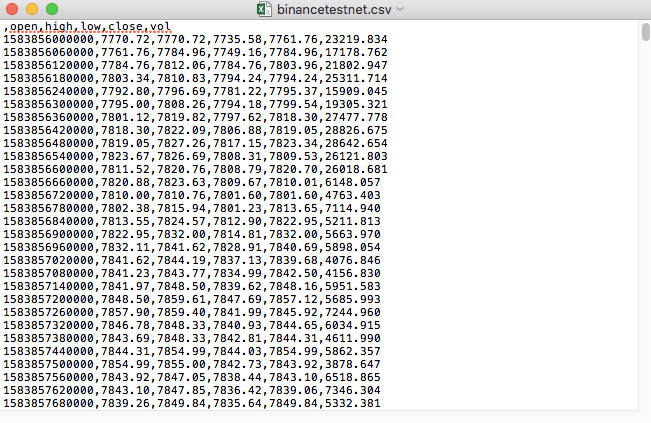
Замечено, что первая строка файла CSV - это заголовок таблицы.
,open,high,low,close,vol
Нам просто нужно проанализировать и отсортировать эти данные, а затем построить их в формате, требуемом пользовательским источником данных системы бэкстеста.
Измененный код
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Испытание запуска
Сначала мы запускаем робота-собирателя, добавляем к нему обменник и даем ему работать.
Конфигурация параметров:

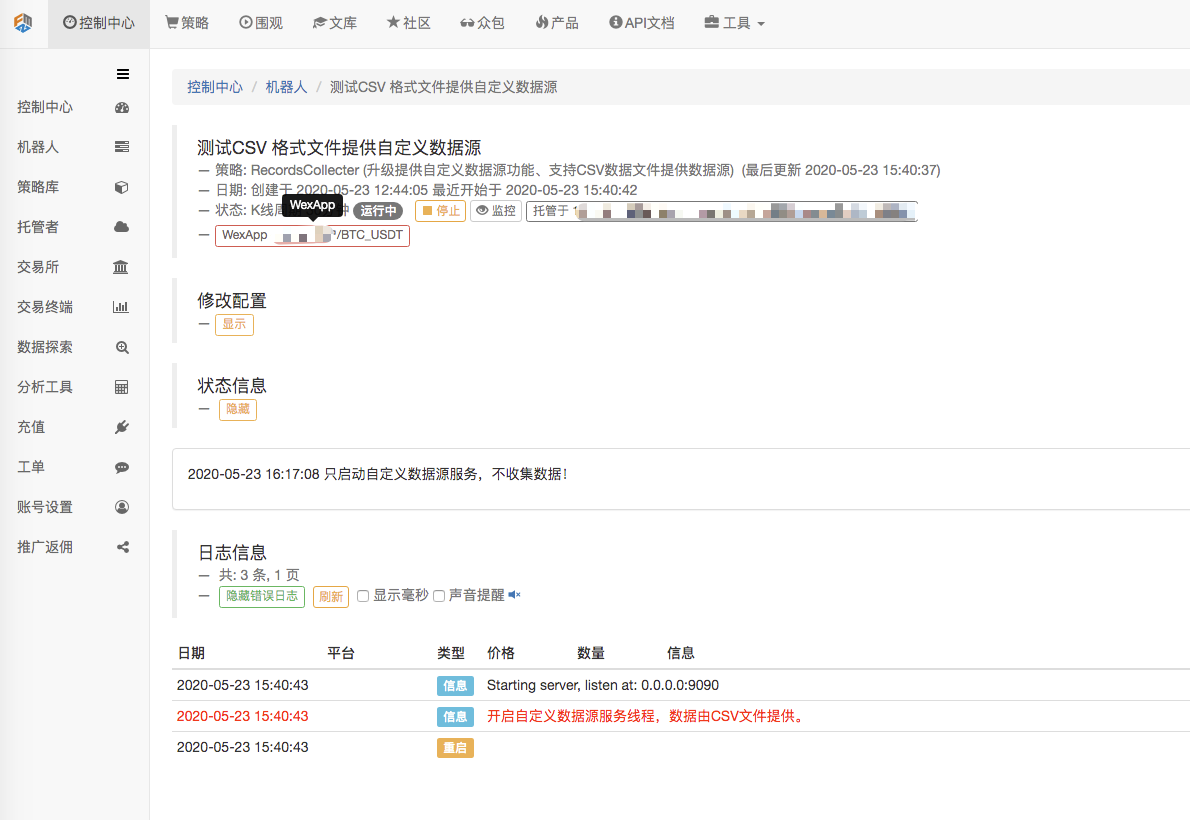
Затем мы создаем стратегию тестирования:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
Стратегия очень проста, просто получите и напечатайте данные K-линии три раза.
На странице backtest, установите источник данных системы backtest как пользовательский источник данных, и заполните адрес сервера, где работает робот-собиратель рынка. Поскольку данные в нашем файле CSV составляют 1-минутную K-строку. Поэтому при backtest, мы устанавливаем период K-строки на 1 минуту.
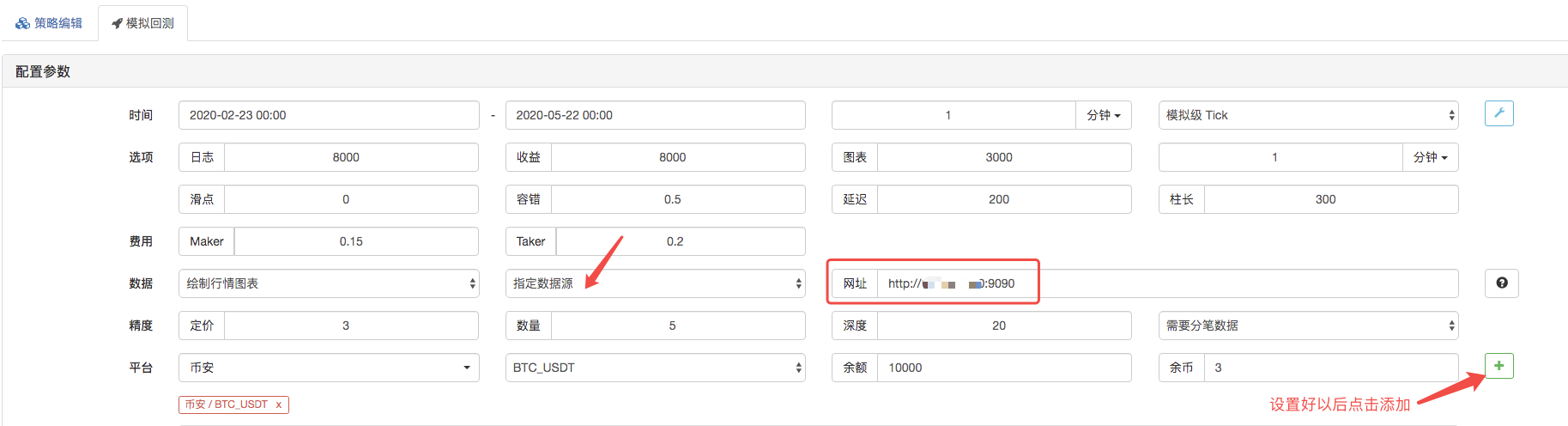
Нажмите, чтобы запустить обратный тест, и робот-собиратель данных получает запрос:

После завершения стратегии выполнения системы обратного тестирования на основе данных K-линии в источнике данных генерируется K-линейная диаграмма.
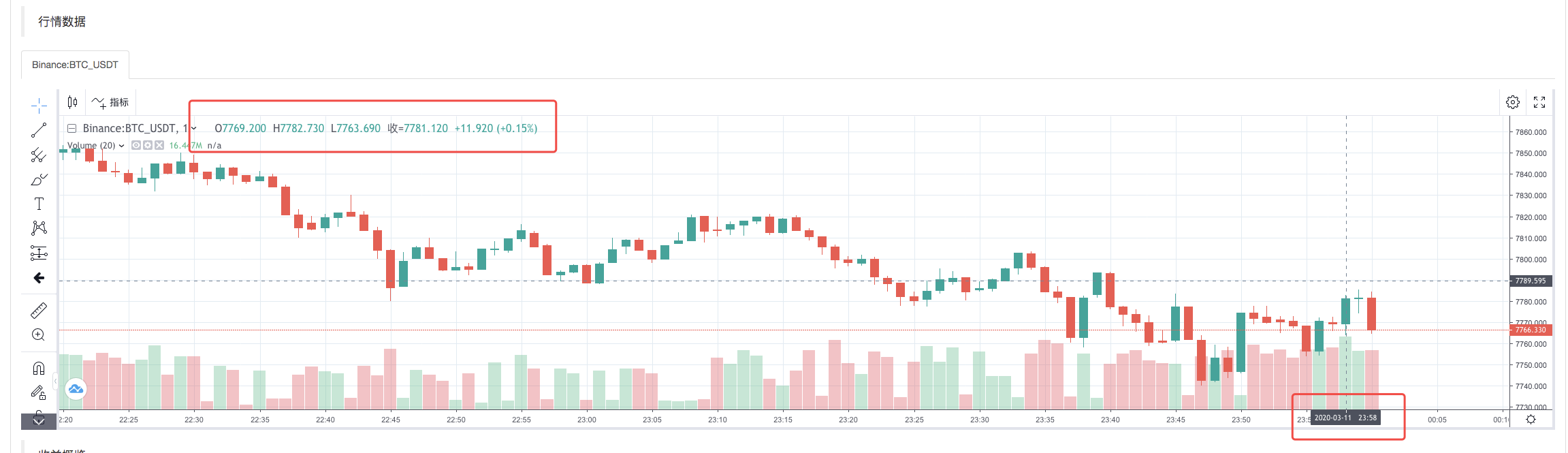
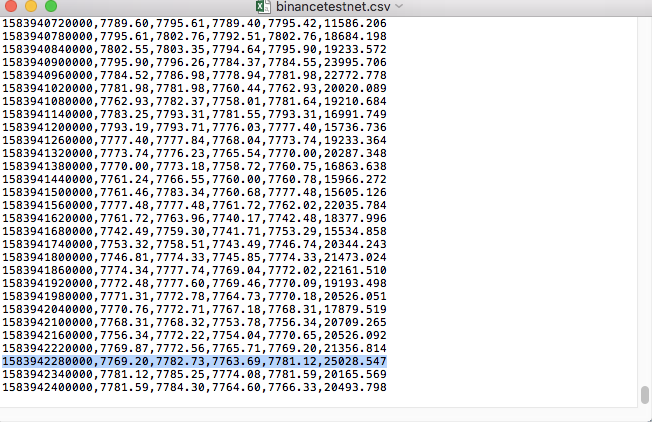
Сравните данные в файле:

- Презентация о своде Lead-Lag в цифровой валюте (3)
- Введение в арбитраж с задержкой свинца в криптовалюте (2)
- Презентация о своде Lead-Lag в цифровой валюте (2)
- Обсуждение по внешнему приему сигналов платформы FMZ: полное решение для приема сигналов с встроенным сервисом Http в стратегии
- Обзор приема внешних сигналов на платформе FMZ: стратегию полного решения приема сигналов встроенного сервиса HTTP
- Введение в арбитраж с задержкой свинца в криптовалюте (1)
- Введение Lead-Lag в цифровой валюте (1)
- Дискуссия по внешнему приему сигнала платформы FMZ: расширенный API VS стратегия встроенного HTTP-сервиса
- Обзор FMZ-платформы для получения внешних сигналов: расширение API против стратегии встроенного HTTP-сервиса
- Обсуждение метода тестирования стратегии на основе генератора случайных тикеров
- Исследование методов тестирования стратегии на основе генератора случайных рынков
- Некоторые мысли о логике торговли криптовалютными фьючерсами
- Усовершенствованный инструмент анализа на основе развития грамматики Alpha101
- Научить вас обновлять рынок коллектор backtest пользовательский источник данных
- Недостатки системы высокочастотного повторения, основанной на транзакциях по буквам, и K-линейного повторения
- Объяснение механизма обратного тестирования на уровне моделирования FMZ
- Лучший способ установить и обновить FMZ docker на Linux VPS
- Фьючерсы на сырьевые товары Стратегия R-Breaker
- Мысли о логике торговли фьючерсами цифровых валют
- Научить вас внедрять рыночные котировки коллектор
- Python версия Фьючерсы на сырьевые товары Стратегия скользящей средней
- Переоборудование сборщиков данных - поддержка импорта файлов в формате CSV для предоставления персонализированных источников данных
- Стратегия торговли высокочастотными фьючерсами на сырьевые товары, написанная на C++
- Ларри Коннорс RSI2 Средняя стратегия обратного движения
- Окс руководит и учит вас использовать JS пары для расширения FMZ API
- На основе использования нового индекса относительной прочности в внутридневных стратегиях
- Исследования фьючерсной стратегии хеджирования в нескольких валютах Binance Часть 4
- Ларри Коннорс Ларри Коннорс RSI2 Стратегия регрессии среднего значения
- Исследования фьючерсной стратегии хеджирования в нескольких валютах Binance Часть 3
- Исследование стратегии хеджирования в нескольких валютах Binance Futures Часть 2
- Исследования фьючерсной стратегии хеджирования в нескольких валютах Binance Часть 1