ایک بٹ کوائن ٹریڈنگ بوٹ بنائیں جو کبھی بھی پیسے سے محروم نہ ہو۔
 0
5331
0
5331

آئیے کرپٹو کرنسی ٹریڈنگ روبوٹ بنانے کے لیے مصنوعی ذہانت میں کمک سیکھنے کا استعمال کریں
اس آرٹیکل میں، ہم بٹ کوائن ٹریڈنگ بوٹ بنانے کا طریقہ سیکھنے کے لیے ایک کمک سیکھنے کا فریم ورک بنائیں گے اور لاگو کریں گے۔ اس ٹیوٹوریل میں، ہم اوپن اے آئی کے جم اور پی پی او روبوٹ کو اسٹیبل بیس لائنز لائبریری سے استعمال کریں گے، جو اوپن اے آئی بیس لائنز لائبریری کا ایک کانٹا ہے۔
پچھلے کچھ سالوں میں گہری سیکھنے والے محققین کو اوپن سورس سافٹ ویئر فراہم کرنے کے لیے OpenAI اور DeepMind کا بہت شکریہ۔ اگر آپ نے وہ حیرت انگیز کامیابیاں نہیں دیکھی ہیں جو انہوں نے AlphaGo، OpenAI Five، اور AlphaStar جیسی ٹیکنالوجیز کے ساتھ کی ہیں، تو ہو سکتا ہے کہ آپ پچھلے ایک سال سے تنہائی میں رہ رہے ہوں، لیکن آپ کو انہیں چیک کرنا چاہیے۔
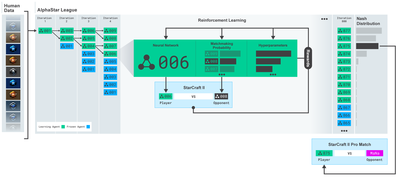
الفا اسٹار ٹریننگ https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
اگرچہ ہم کچھ متاثر کن نہیں بنائیں گے، بٹ کوائن روبوٹ ٹریڈنگ اب بھی روزمرہ کی تجارت میں کوئی آسان کام نہیں ہے۔ تاہم، جیسا کہ ٹیڈی روزویلٹ نے ایک بار کہا تھا،
جو چیزیں بہت آسانی سے آتی ہیں ان کی کوئی اہمیت نہیں ہوتی۔
لہذا، نہ صرف اپنے لیے تجارت کرنا سیکھیں…بلکہ روبوٹ کو ہمارے لیے تجارت کرنے دیں۔
منصوبہ

ہمارے روبوٹ کو مشین لرننگ کرنے کے لیے ایک جم ماحول بنائیں
ایک سادہ اور خوبصورت تصوراتی ماحول پیش کریں۔
منافع بخش تجارتی حکمت عملی سیکھنے کے لیے ہمارے روبوٹ کو تربیت دیں۔
اگر آپ ابھی تک اس بات سے واقف نہیں ہیں کہ شروع سے جم ماحول کیسے بنایا جائے، یا ان ماحول کے تصورات کو کس طرح پیش کیا جائے۔ جاری رکھنے سے پہلے بلا جھجھک اس طرح کے مضمون کو گوگل کریں۔ یہ دونوں اعمال سب سے زیادہ ابتدائی پروگرامرز کے لیے بھی مشکل نہیں ہوں گے۔
شروع کرنا
اس ٹیوٹوریل میں، ہم زیلک کے ذریعے تیار کردہ Kaggle ڈیٹاسیٹ کا استعمال کریں گے۔ اگر آپ سورس کوڈ کو ڈاؤن لوڈ کرنا چاہتے ہیں، تو یہ .csv ڈیٹا فائل کے ساتھ میرے Github ریپوزٹری میں دستیاب ہے۔ ٹھیک ہے، چلو شروع کرتے ہیں۔
پہلے، آئیے تمام ضروری لائبریریوں کو درآمد کریں۔ pip کا استعمال کرتے ہوئے کسی بھی لائبریری کو انسٹال کرنا یقینی بنائیں۔
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
اگلا، آئیے ماحولیات کے لیے اپنی کلاس بنائیں۔ ہمیں پانڈا ڈیٹا فریم کے ساتھ ساتھ ایک اختیاری ابتدائی_بیلنس اور ایک lookback_window_size میں گزرنے کی ضرورت ہے جو یہ بتائے گا کہ روبوٹ ہر قدم پر ماضی کے کتنے مراحل کا مشاہدہ کرے گا۔ ہم فی تجارت کمیشن کو 0.075%، Bitmex پر موجودہ شرح پر ڈیفالٹ کرتے ہیں، اور سیریل پیرامیٹر کو غلط پر ڈیفالٹ کرتے ہیں، مطلب یہ ہے کہ ہمارا ڈیٹا فریم ڈیفالٹ کے لحاظ سے بے ترتیب ٹکڑوں میں منتقل ہو جائے گا۔
ہم ڈیٹا پر dropna() اور reset_index() کو بھی کال کرتے ہیں، پہلے NaN ویلیوز والی قطاروں کو ہٹانے کے لیے اور پھر فریم نمبر کے لیے انڈیکس کو ری سیٹ کرنے کے لیے جب سے ہم نے ڈیٹا چھوڑا ہے۔
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
ہمارے ایکشن_اسپیس کو یہاں 3 اختیارات (خریدنے، بیچنے یا ہولڈ) کے ایک سیٹ اور 10 رقوم کے ایک دوسرے سیٹ (1/10، 2/10، 3⁄10 وغیرہ) کے طور پر دکھایا گیا ہے۔ خرید ایکشن کا انتخاب کرتے وقت، ہم BTC کی رقم * self.balance مالیت خریدیں گے۔ فروخت کے لیے، ہم بی ٹی سی کی *self.btc_held مالیت کی رقم فروخت کریں گے۔ یقینا، ہولڈ ایکشن رقم کو نظر انداز کرتا ہے اور کچھ نہیں کرتا ہے۔
ہمارے مشاہداتی_اسپیس کی تعریف 0 اور 1 کے درمیان مسلسل فلوٹس کے ایک سیٹ کے طور پر کی گئی ہے، جس میں شکل (10، lookback_window_size + 1) ہے۔ + 1 موجودہ وقت کے قدم کا حساب لگانے کے لیے استعمال کیا جاتا ہے۔ ونڈو میں ہر بار قدم کے لیے، ہم OHCLV قدر کا مشاہدہ کریں گے۔ ہماری خالص مالیت BTC کی خریدی یا بیچی گئی رقم کے برابر ہے، اور ان BTC پر ہم نے خرچ یا وصول کی جانے والی USD کی کل رقم کے برابر ہے۔
اگلا، ہمیں ماحول کو شروع کرنے کے لیے ری سیٹ کا طریقہ لکھنے کی ضرورت ہے۔
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
یہاں ہم خود استعمال کرتے ہیں۔_reset_session اور خود۔_next_observation، ہم نے ابھی تک ان کی وضاحت نہیں کی ہے۔ آئیے پہلے ان کی تعریف کرتے ہیں۔
تجارتی سیشن
ہمارے ماحول کا ایک اہم حصہ تجارتی سیشن کا تصور ہے۔ اگر ہم اس بوٹ کو مارکیٹ سے باہر تعینات کرتے ہیں، تو شاید ہم اسے ایک وقت میں چند مہینوں سے زیادہ نہیں چلائیں گے۔ اس وجہ سے، ہم self.df میں لگاتار فریموں کی تعداد کو محدود کر دیں گے، یعنی ان فریموں کی تعداد جو ہمارا روبوٹ ایک وقت میں دیکھ سکتا ہے۔
ہمارے _reset_session طریقہ میں، ہم پہلے کرنٹ_سٹیپ کو 0 پر ری سیٹ کرتے ہیں۔ اس کے بعد، ہم steps_left کو 1 اور MAX_TRADING_SESSION کے درمیان بے ترتیب نمبر پر سیٹ کریں گے، جسے ہم پروگرام کے اوپری حصے میں بیان کریں گے۔
MAX_TRADING_SESSION = 100000 # ~2个月
اس کے بعد، اگر ہم مسلسل فریموں پر اعادہ کرنا چاہتے ہیں، تو ہمیں اسے پورے فریم پر اعادہ کرنے کے لیے سیٹ کرنا ہوگا، بصورت دیگر ہم frame_start کو self.df میں ایک رینڈم پوائنٹ پر سیٹ کرتے ہیں اور ایک نیا ڈیٹا فریم بناتے ہیں جسے ایکٹیو_ڈی ایف کہتے ہیں جو کہ صرف ایک سلائس ہے۔ of df frame_start سے frame_start + steps_left تک۔
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
بے ترتیب سلائسنگ میں ڈیٹا فریموں کی تعداد پر تکرار کا ایک اہم ضمنی اثر یہ ہے کہ ہمارے روبوٹ کے پاس طویل عرصے تک تربیت کے دوران استعمال کرنے کے لیے زیادہ منفرد ڈیٹا ہوگا۔ مثال کے طور پر، اگر ہم سیریل انداز میں ڈیٹا فریموں کی تعداد کے ذریعے (یعنی 0 سے len(df) تک کی ترتیب میں) اعادہ کرتے ہیں، تو ہمارے پاس صرف اتنے ہی منفرد ڈیٹا پوائنٹس ہوں گے جتنے ڈیٹا فریمز کی تعداد میں ہیں۔ ہمارے مشاہدے کی جگہ ہر بار قدم پر ریاستوں کی صرف مجرد تعداد کو اپنا سکتی ہے۔
تاہم، ڈیٹاسیٹ کے ٹکڑوں پر تصادفی طور پر اعادہ کرتے ہوئے، ہم ابتدائی ڈیٹاسیٹ میں ہر بار کے مرحلے کے لیے تجارتی نتائج کا ایک زیادہ معنی خیز سیٹ بنا سکتے ہیں، یعنی زیادہ منفرد ڈیٹا بنانے کے لیے تجارتی کارروائیوں اور پہلے دیکھی گئی قیمت کی کارروائی کا مجموعہ۔ میں اسے ایک مثال سے سمجھاتا ہوں۔
سیریل ماحول کو دوبارہ ترتیب دینے کے بعد 10 کے مرحلے پر، ہمارا روبوٹ ہمیشہ ڈیٹاسیٹ کے اندر ایک ساتھ چلے گا اور ہر بار کے مرحلے کے بعد اس کے پاس 3 انتخاب ہوں گے: خریدیں، بیچیں یا پکڑیں۔ ان تینوں اختیارات میں سے ہر ایک کے لیے، ایک اور آپشن ہے: 10%، 20%، … یا 100% مخصوص نفاذ کی رقم۔ اس کا مطلب ہے کہ ہمارا روبوٹ کل 1030 حالات کے لیے 103 سے 10 کی طاقت میں سے کسی کا بھی سامنا کر سکتا ہے۔
اب واپس ہمارے بے ترتیب سلائسنگ ماحول کی طرف۔ 10 کے ٹائم سٹیپ پر، ہمارا روبوٹ ڈیٹا فریموں کی تعداد کے اندر کسی بھی len(df) ٹائم سٹیپ پر ہو سکتا ہے۔ یہ فرض کرتے ہوئے کہ ہر بار قدم کے بعد ایک ہی انتخاب کیا جاتا ہے، اس کا مطلب یہ ہے کہ روبوٹ 10 وقت کے ایک ہی مراحل میں len(df)30 کی کسی بھی منفرد حالت سے گزر سکتا ہے۔
اگرچہ اس سے بڑے ڈیٹاسیٹس میں کافی شور ہو سکتا ہے، لیکن میرا خیال ہے کہ اس سے روبوٹس کو ہمارے پاس موجود محدود ڈیٹا سے مزید سیکھنے کی اجازت ملنی چاہیے۔ الگورتھم کی تاثیر کے بارے میں زیادہ درست سمجھ حاصل کرنے کے لیے ہم اب بھی تازہ ترین، بظاہر ‘حقیقی وقت’ ڈیٹا حاصل کرنے کے لیے سیریل انداز میں اپنے ٹیسٹ ڈیٹا کو دہرائیں گے۔
روبوٹ کی آنکھوں کے ذریعے
ہمارے روبوٹ کے استعمال کردہ افعال کی اقسام کو سمجھنے کے لیے ماحول کا ایک اچھا بصری جائزہ لینا اکثر مددگار ثابت ہوتا ہے۔ مثال کے طور پر، یہاں اوپن سی وی کا استعمال کرتے ہوئے قابل مشاہدہ جگہ کا تصور ہے۔

اوپن سی وی ویژولائزیشن ماحول کا مشاہدہ
تصویر کی ہر قطار ہمارے مشاہداتی_اسپیس میں ایک قطار کی نمائندگی کرتی ہے۔ اسی طرح کی فریکوئنسی سرخ لکیروں کی پہلی 4 لائنیں OHCL ڈیٹا کی نمائندگی کرتی ہیں، اور اس کے بالکل نیچے نارنجی اور پیلے رنگ کے نقطے حجم کی نمائندگی کرتے ہیں۔ نیچے کی اتار چڑھاؤ والی نیلی بار بوٹ کی ایکویٹی ہے، جب کہ نیچے کی ہلکی باریں بوٹ کی تجارت کی نمائندگی کرتی ہیں۔
اگر آپ قریب سے دیکھیں تو آپ اپنا ایک کینڈل سٹک چارٹ بھی بنا سکتے ہیں۔ والیوم بار کے نیچے ایک مورس کوڈ جیسا انٹرفیس ہے جو ٹریڈنگ کی تاریخ کو ظاہر کرتا ہے۔ ایسا لگتا ہے کہ ہمارے بوٹ کو ہمارے observation_space میں موجود ڈیٹا سے مناسب طریقے سے سیکھنے کے قابل ہونا چاہیے، تو آئیے جاری رکھیں۔ یہاں ہم _next_observation طریقہ کی وضاحت کریں گے جہاں ہم مشاہدہ شدہ ڈیٹا کو 0 سے 1 تک پیمانہ کریں گے۔
- یہ ضروری ہے کہ صرف اس ڈیٹا کو بڑھایا جائے جس کا روبوٹ نے اب تک مشاہدہ کیا ہے تاکہ نظر آنے والے تعصب کو روکا جا سکے۔
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
ایکشن لیں۔
اب جب کہ ہمارے پاس اپنا مشاہدہ کرنے کی جگہ قائم ہے، اب وقت آگیا ہے کہ ہم اپنا سٹیپ فنکشن لکھیں اور پھر وہ اقدامات کریں جو روبوٹ کرنا چاہتا ہے۔ جب بھی ہمارے موجودہ تجارتی سیشن کے لیے self.steps_left == 0، ہم اپنے BTC ہولڈنگز کو فروخت کریں گے اور reset session() کو کال کریں گے۔ بصورت دیگر، ہم موجودہ ایکویٹی پر انعام مقرر کرتے ہیں، یا اگر ہمارے پاس فنڈز ختم ہوتے ہیں تو درست پر سیٹ کرتے ہیں۔
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
تجارتی کارروائی کرنا اتنا ہی آسان ہے جتنا موجودہ_قیمت حاصل کرنا، اس کارروائی کا تعین کرنا جس کو انجام دینے کی ضرورت ہے، اور خرید و فروخت کی رقم کا تعین کرنا۔ آئیے جلدی سے _take_action لکھیں تاکہ ہم اپنے ماحول کو جانچ سکیں۔
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
آخر میں، اسی طریقہ میں، ہم تجارت کو self.trades میں شامل کریں گے اور اپنی ایکویٹی اور اکاؤنٹ کی تاریخ کو اپ ڈیٹ کریں گے۔
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
ہمارا روبوٹ اب ایک نیا ماحول شروع کر سکتا ہے، اس ماحول میں قدم رکھ سکتا ہے، اور ماحول کو متاثر کرنے والے اقدامات کر سکتا ہے۔ یہ ان کی تجارت کو دیکھنے کا وقت ہے۔
ہمارے روبوٹس کی تجارت دیکھیں
ہمارا رینڈر کا طریقہ اتنا ہی آسان ہو سکتا ہے جتنا کہ کالنگ print(self.net_worth)، لیکن یہ کافی دلچسپ نہیں ہوگا۔ اس کے بجائے، ہم حجم بار کے ساتھ ایک سادہ کینڈل سٹک چارٹ اور اپنی ایکویٹی کے لیے ایک الگ چارٹ بنائیں گے۔
ہم اپنے پچھلے مضمون سے StockTradingGraph.py میں کوڈ لیں گے اور بٹ کوائن کے ماحول کے مطابق ہونے کے لیے اس پر دوبارہ کام کریں گے۔ آپ میرے گیتھب سے کوڈ حاصل کرسکتے ہیں۔
پہلی تبدیلی جو ہم کرنے جا رہے ہیں وہ ہے self.df کو تبدیل کرنا[ ‘تاریخ’] self.df پر اپ ڈیٹ کریں۔[‘ٹائم اسٹیمپ’] اور date2num کی تمام کالز کو ہٹا دیں کیونکہ ہماری تاریخیں پہلے سے ہی یونکس ٹائم اسٹیمپ فارمیٹ میں ہیں۔ اس کے بعد، ہمارے رینڈر کے طریقہ کار میں، ہم تاریخ کے لیبل کو اپ ڈیٹ کریں گے تاکہ کسی نمبر کی بجائے انسانی پڑھنے کے قابل تاریخ پرنٹ کر سکیں۔
from datetime import datetime
سب سے پہلے، ہم ڈیٹ ٹائم لائبریری کو درآمد کریں گے، پھر ہم ہر ٹائم اسٹیمپ سے UTC سٹرنگ حاصل کرنے کے لیے utcfromtimestampmethod استعمال کریں گے اور strftime اسے Y-m-d H:M کی شکل میں سٹرنگ میں بنائیں گے۔
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
آخر میں، ہم self.df استعمال کریں گے۔[‘حجم’] کو self.df میں تبدیل کر دیا گیا ہے۔[‘حجم_(BTC)’] ہمارے ڈیٹاسیٹ سے مماثل ہے، اور اس کے ساتھ، ہم جانے کے لیے تیار ہیں۔ اپنے BitcoinTradingEnv پر واپس، اب ہم گراف کو ظاہر کرنے کے لیے رینڈر کا طریقہ لکھ سکتے ہیں۔
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
دیکھو! اب ہم اپنے روبوٹ کی تجارت Bitcoins کو دیکھ سکتے ہیں۔

Matplotlib کے ساتھ ہمارے روبوٹ کی تجارت کا تصور کرنا
سبز فینٹم لیبل BTC کی خریداری کی نمائندگی کرتے ہیں، اور سرخ فینٹم لیبل فروخت کی نمائندگی کرتے ہیں۔ اوپری دائیں کونے میں سفید لیبل روبوٹ کی موجودہ خالص قیمت ہے، اور نیچے دائیں کونے میں موجود لیبل Bitcoin کی موجودہ قیمت ہے۔ سادہ اور خوبصورت۔ اب وقت آگیا ہے کہ ہم اپنے بوٹ کو تربیت دیں اور دیکھیں کہ ہم کتنا پیسہ کما سکتے ہیں!
تربیت کا وقت
ایک تنقید جو مجھے اپنے پچھلے مضمون میں موصول ہوئی وہ تھی کراس توثیق کی کمی اور ڈیٹا کو تربیت اور ٹیسٹ سیٹ میں تقسیم نہ کرنا۔ اس کا مقصد نئے ڈیٹا پر حتمی ماڈل کی درستگی کو جانچنا ہے جو اس نے پہلے کبھی نہیں دیکھا۔ اگرچہ یہ اس مضمون کا مرکز نہیں ہے، یہ یقینی طور پر اہم ہے۔ چونکہ ہم ٹائم سیریز کے ڈیٹا کے ساتھ کام کر رہے ہیں، اس لیے جب کراس توثیق کی بات آتی ہے تو ہمارے پاس زیادہ انتخاب نہیں ہوتا ہے۔
مثال کے طور پر، کراس توثیق کی ایک عام شکل کو k-fold validation کہا جاتا ہے، جس میں آپ ڈیٹا کو k برابر گروپس میں تقسیم کرتے ہیں، ایک گروپ کو ٹیسٹ گروپ کے طور پر الگ کرتے ہیں، اور بقیہ ڈیٹا کو ٹریننگ گروپ کے طور پر استعمال کرتے ہیں۔ . تاہم، ٹائم سیریز کا ڈیٹا بہت زیادہ وقت پر منحصر ہے، جس کا مطلب ہے کہ بعد کا ڈیٹا پہلے کے ڈیٹا پر بہت زیادہ انحصار کرتا ہے۔ لہذا k-fold کام نہیں کرے گا کیونکہ ہمارا روبوٹ ٹریڈنگ سے پہلے مستقبل کے ڈیٹا سے سیکھے گا، جو کہ ایک غیر منصفانہ فائدہ ہے۔
ٹائم سیریز کے ڈیٹا پر لاگو ہونے پر یہی خامیاں زیادہ تر دوسری کراس توثیق کی حکمت عملیوں پر لاگو ہوتی ہیں۔ لہذا، ہمیں ڈیٹا فریموں کی مکمل تعداد کا صرف ایک حصہ استعمال کرنے کی ضرورت ہے جیسا کہ ٹریننگ سیٹ فریم نمبر کے شروع سے کچھ صوابدیدی انڈیکس تک ہوتا ہے، اور باقی ڈیٹا کو ٹیسٹ سیٹ کے طور پر استعمال کرنا ہوتا ہے۔
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
اگلا، چونکہ ہمارا ماحول صرف ڈیٹا کے ایک فریم کو ہینڈل کرنے کے لیے ترتیب دیا گیا ہے، اس لیے ہم دو ماحول بنائیں گے، ایک تربیتی ڈیٹا کے لیے اور دوسرا ٹیسٹنگ ڈیٹا کے لیے۔
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
اب، ہمارے ماڈل کو تربیت دینا اتنا ہی آسان ہے جتنا کہ ہمارے ماحول کے ساتھ روبوٹ بنانا اور model.learn کو کال کرنا۔
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
یہاں، ہم ٹینسر بورڈ استعمال کرتے ہیں تاکہ ہم اپنے ٹینسر فلو گراف کو آسانی سے دیکھ سکیں اور اپنے روبوٹ کے بارے میں کچھ مقداری میٹرکس دیکھ سکیں۔ مثال کے طور پر، یہاں 200,000 سے زیادہ وقت کے مراحل سے زیادہ روبوٹ کے لیے رعایتی انعامات کا ایک پلاٹ ہے:
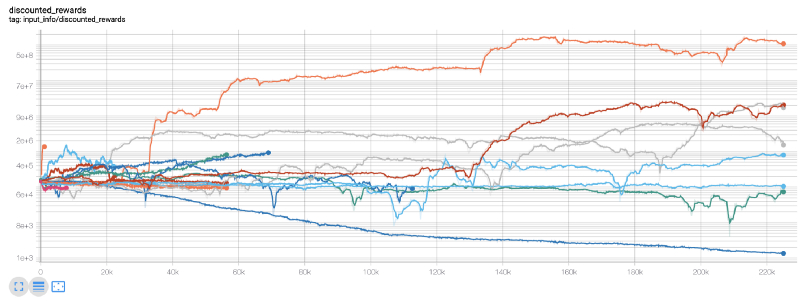
واہ، ایسا لگتا ہے کہ ہمارا بوٹ کافی منافع بخش ہے! ہمارا بہترین روبوٹ یہاں تک کہ 200,000 قدموں کے دوران 1000x بہتر توازن حاصل کرنے میں کامیاب رہا، اور باقی کا اوسط کم از کم 30x بہتری!
یہ اس وقت تھا جب مجھے احساس ہوا کہ ماحول میں ایک بگ ہے… اسے ٹھیک کرنے کے بعد، یہ رہا انعام کا نیا نقشہ:
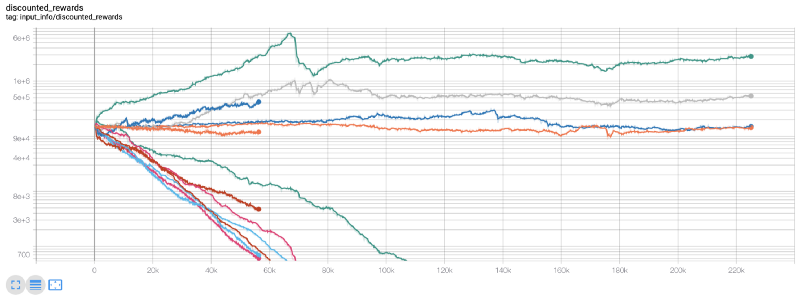
جیسا کہ آپ دیکھ سکتے ہیں، ہمارے کچھ روبوٹس نے بہت اچھا کام کیا، اور باقی اپنے طور پر دیوالیہ ہو گئے۔ تاہم، ایک اچھی کارکردگی کا مظاہرہ کرنے والا بوٹ ابتدائی بیلنس سے 10x یا اس سے بھی 60x تک حاصل کر سکتا ہے۔ مجھے یہ تسلیم کرنا چاہیے کہ تمام منافع بخش بوٹس بغیر کمیشن کے تربیت یافتہ اور جانچے جاتے ہیں، اس لیے ہمارے بوٹس کے لیے کوئی حقیقی رقم کمانا غیر حقیقی ہے۔ لیکن کم از کم ہمیں سمت مل گئی!
آئیے اپنے بوٹس کو آزمائشی ماحول میں جانچتے ہیں (نئے ڈیٹا کے ساتھ جو انہوں نے پہلے کبھی نہیں دیکھا ہوگا) اور دیکھیں کہ وہ کیسا کارکردگی دکھاتے ہیں۔
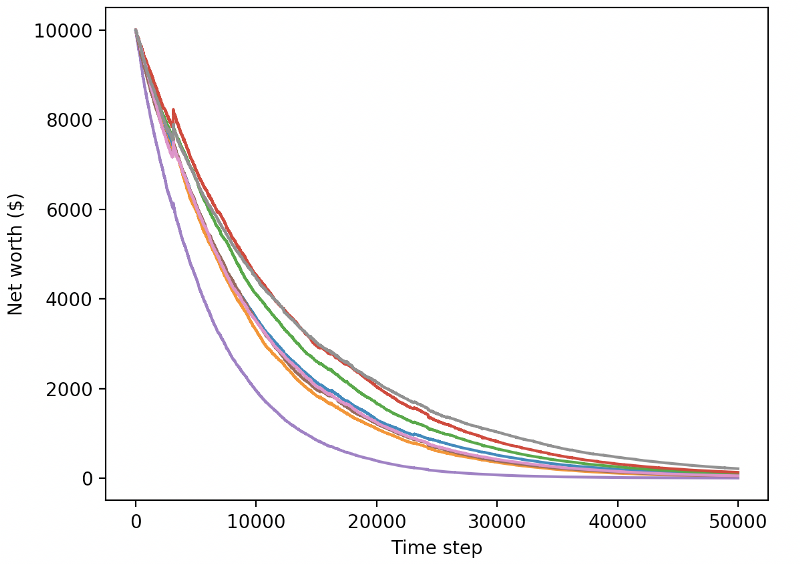
نئے ٹیسٹ ڈیٹا کی تجارت کرتے وقت ہمارا تربیت یافتہ بوٹ دیوالیہ ہو جاتا ہے۔
واضح طور پر، ہمیں ابھی بھی بہت کام کرنا ہے۔ موجودہ PPO2 روبوٹ کے بجائے ایک مستحکم بیس لائن A2C استعمال کرنے کے لیے صرف ماڈل کو تبدیل کر کے، ہم اس ڈیٹا سیٹ پر اپنی کارکردگی کو نمایاں طور پر بہتر بنا سکتے ہیں۔ آخر میں، شان او گورمین کے مشورے پر عمل کرتے ہوئے، ہم اپنے انعام کے فنکشن کو قدرے اپ ڈیٹ کر سکتے ہیں تاکہ ہم انعامات کو خالص مالیت میں شامل کر سکیں بجائے اس کے کہ صرف ایک اعلیٰ مالیت حاصل کر کے اسے وہیں چھوڑ دیں۔
reward = self.net_worth - prev_net_worth
یہ دونوں تبدیلیاں ہی ٹیسٹ ڈیٹاسیٹ پر کارکردگی کو نمایاں طور پر بہتر کرتی ہیں، اور جیسا کہ آپ نیچے دیکھ سکتے ہیں، ہم آخر کار نئے ڈیٹا پر منافع حاصل کرنے کے قابل ہو گئے ہیں جو تربیتی سیٹ میں نہیں تھا۔
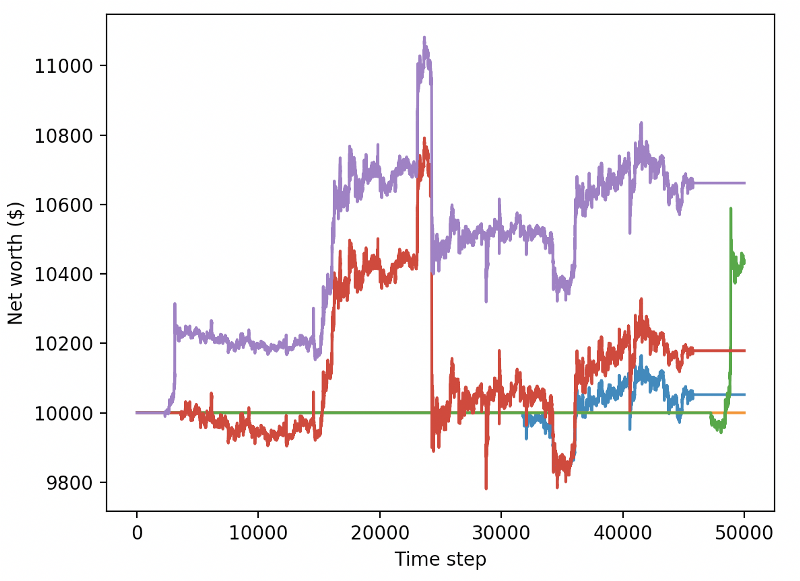
لیکن ہم بہتر کر سکتے ہیں۔ ان نتائج کو بہتر بنانے کے لیے، ہمیں اپنے ہائپر پیرامیٹر کو بہتر بنانے اور اپنے بوٹ کو زیادہ دیر تک تربیت دینے کی ضرورت ہے۔ یہ آپ کے GPU کو کام کرنے اور تمام سلنڈروں پر فائر کرنے کا وقت ہے!
اس مقام پر یہ پوسٹ تھوڑی لمبی ہو گئی ہے، اور ہمارے پاس ابھی بھی بہت ساری تفصیلات پر غور کرنا ہے، لہذا ہم یہاں ایک وقفہ کرنے جا رہے ہیں۔ اگلی پوسٹ میں، ہم Bayesian Optimization کا استعمال کریں گے تاکہ ہمارے مسئلے کی جگہ کے لیے بہترین ہائپر پیرامیٹر تقسیم کریں اور CUDA کا استعمال کرتے ہوئے GPUs پر تربیت/ٹیسٹنگ کے لیے تیاری کریں۔
آخر میں
اس مضمون میں، ہم کمک سیکھنے کا استعمال کرتے ہوئے شروع سے ایک منافع بخش بٹ کوائن ٹریڈنگ بوٹ بنانے کے لیے نکلے ہیں۔ ہم درج ذیل کاموں کو پورا کر سکتے ہیں۔
OpenAI کے جم کا استعمال کرتے ہوئے شروع سے ہی Bitcoin تجارتی ماحول بنائیں۔
ماحول کا تصور بنانے کے لیے Matplotlib کا استعمال کریں۔
سادہ کراس توثیق کا استعمال کرتے ہوئے ہمارے بوٹ کی تربیت اور جانچ کریں۔
منافع حاصل کرنے کے لیے ہمارے روبوٹ کو تھوڑا سا موافقت کریں۔
اگرچہ ہمارا تجارتی روبوٹ اتنا منافع بخش نہیں ہے جتنا کہ ہم اسے بنانا چاہتے ہیں، لیکن ہم صحیح سمت میں جا رہے ہیں۔ اگلی بار، ہم اس بات کو یقینی بنائیں گے کہ ہمارا بوٹ مارکیٹ کو مسلسل شکست دے سکتا ہے اور ہم دیکھیں گے کہ ہمارا ٹریڈنگ بوٹ لائیو ڈیٹا پر کیسے کارکردگی کا مظاہرہ کرتا ہے۔ میرے اگلے مضمون کے لیے دیکھتے رہیں، اور لانگ لائیو بٹ کوائن!