Khám phá ban đầu về ứng dụng Python Crawler trên FMZ Crawling Binance Content Announcement
Tác giả:Ninabadass, Tạo: 2022-04-08 15:47:43, Cập nhật: 2022-04-13 10:07:13Khám phá ban đầu về việc áp dụng Python Crawler trên FMZ Crawling Binance Nội dung thông báo
Gần đây, tôi đã xem qua các diễn đàn của chúng tôi, và không có thông tin liên quan về trình thu thập thông tin Python. Dựa trên tinh thần phát triển toàn diện của FMZ, tôi chỉ đơn giản là tìm hiểu về các khái niệm và kiến thức của trình thu thập thông tin. Sau khi tìm hiểu về nó, tôi thấy rằng vẫn còn nhiều điều để tìm hiểu về kỹ thuật
Nhu cầu
Đối với các nhà giao dịch thích giao dịch IPO, họ luôn muốn có được thông tin niêm yết nền tảng càng sớm càng tốt.
Khám phá ban đầu
Sử dụng một chương trình rất đơn giản để bắt đầu (các kịch bản trình thu thập dữ liệu thực sự mạnh mẽ phức tạp hơn nhiều, vì vậy hãy dành thời gian của bạn).
Thực hiện mã
Bạn có thể sử dụng một số cấu trúc trình thu thập thông tin hữu ích.
Các thư viện python được sử dụng:
```bs4```, which can be simply regarded as the library used to parse the HTML code of web pages.
Code:
từ bs4 nhập BeautifulSoup Yêu cầu nhập khẩu
urlBinanceAnnouncement =
def openUrl ((url):
tiêu đề = {
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
defin main (():
preNews_href =
”`
Hoạt động
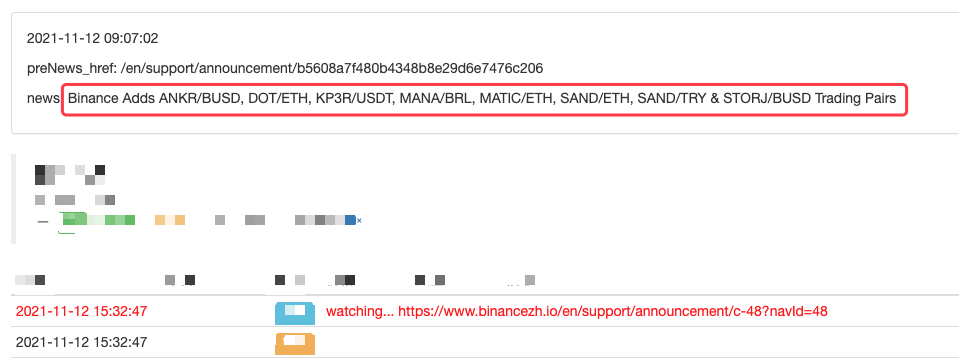
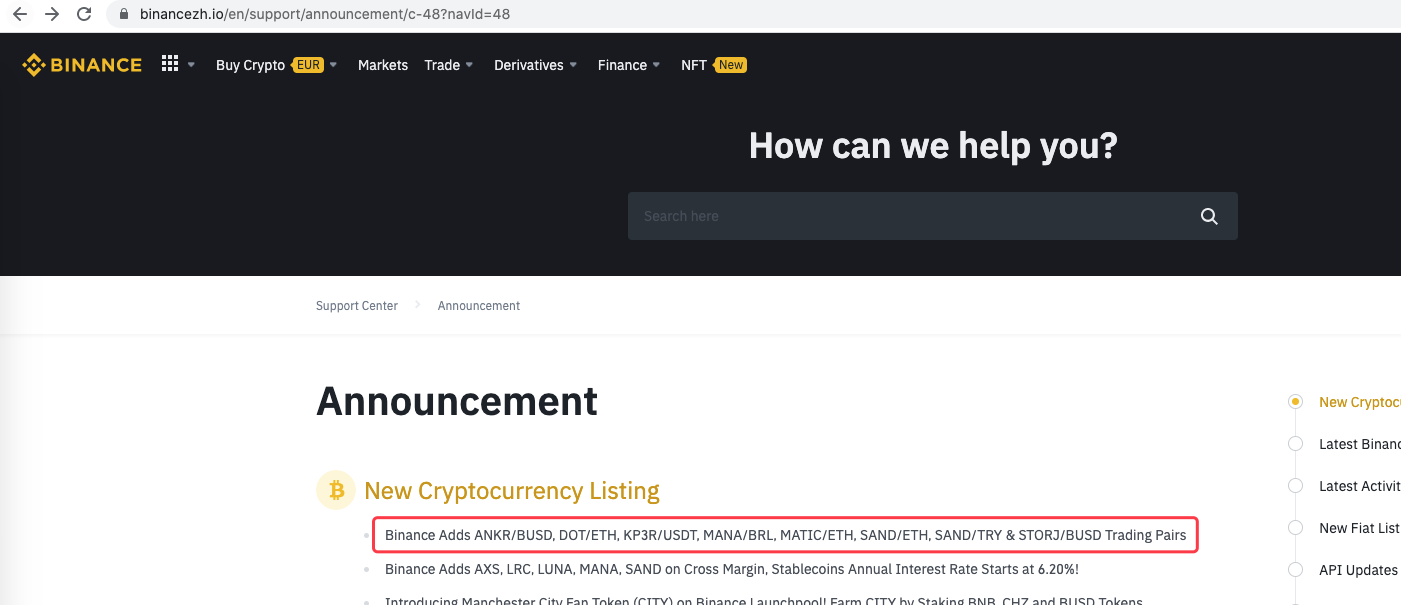
Bạn thậm chí có thể mở rộng nó, chẳng hạn như phát hiện thông báo mới, phân tích các biểu tượng tiền tệ mới niêm yết và tự động đặt hàng giao dịch IPO.
- Bỏ bỏ việc in nhật ký
- Hủy bỏ tất cả các đơn đặt hàng chưa hoàn thành
- Khởi động nhanh APP nền tảng giao dịch lượng tử FMZ
- Thực hiện một lệnh đơn giản giám sát bot của Cryptocurrency Spot
- FMZ là nền tảng để trả tiền
- Cryptocurrency Contract Simple Order-Supervising Bot
- Bạn muốn lấy một khung thời gian tương ứng khi sử dụng getdepth
- Bỏ qua, giải quyết
- Vấn đề giá trị mặt
- Ví dụ thiết kế chiến lược dYdX
- Nghiên cứu thiết kế chiến lược phòng ngừa rủi ro & Ví dụ về lệnh chờ giao dịch tại chỗ và tương lai
- Tình hình gần đây và hoạt động khuyến nghị của chiến lược tỷ lệ tài trợ
- Chiến lược điểm cắt trung bình động kép của hợp đồng tương lai tiền điện tử (Giảng dạy)
- Cryptocurrency Spot Multi-Symbol Dual Moving Average Strategy (Teaching)
- Thực hiện Fisher Indicator trong JavaScript & Plotting trên FMZ
- Người quản lý
- 2021 Cryptocurrency TAQ Review & Chiến lược bỏ lỡ đơn giản nhất tăng 10 lần
- Cryptocurrency Futures Multi-Symbol ART Strategy (Giảng dạy)
- Nâng cấp! Cryptocurrency tương lai chiến lược Martingale
- Chức năng Getrecords không thể lấy biểu đồ K theo giây