Chuỗi giao dịch định lượng về mạng nơ-ron và tiền kỹ thuật số (2) - Học tăng cường sâu để đào tạo các chiến lược giao dịch Bitcoin
 7
5790
7
5790

1. Giới thiệu
Bài viết trước đã giới thiệu cách sử dụng mạng LSTM để dự đoán giá Bitcoin https://www.fmz.com/digest-topic/4035. Như đã đề cập trong bài viết, đây chỉ là một dự án nhỏ để thực hành và làm quen với RNN và pytorch . Bài viết này sẽ giới thiệu việc sử dụng phương pháp học tăng cường để đào tạo trực tiếp các chiến lược giao dịch. Mô hình học tăng cường là PPO mã nguồn mở của OpenAI và môi trường dựa trên phong cách phòng tập thể dục. Để tạo điều kiện thuận lợi cho việc hiểu và thử nghiệm, mô hình LSTM PPO và môi trường phòng thử nghiệm ngược được viết trực tiếp mà không sử dụng các gói có sẵn. PPO, tên đầy đủ của Proximal Policy Optimization, là cải tiến tối ưu hóa của Policy Graident, tức là độ dốc chính sách. Gym cũng được OpenAI phát hành. Nó có thể tương tác với mạng lưới chính sách và phản hồi trạng thái hiện tại và phần thưởng của môi trường. Nó giống như bài tập học tăng cường sử dụng mô hình LSTM PPO để trực tiếp thực hiện mua, bán hoặc không hoạt động dựa trên thông tin thị trường Bitcoin. Hướng dẫn được đưa ra bởi môi trường kiểm thử ngược và mô hình liên tục được tối ưu hóa thông qua đào tạo để đạt được mục tiêu lợi nhuận chiến lược. Để đọc bài viết này, bạn cần có nền tảng nhất định về Python, pytorch và học tăng cường sâu DRL. Nhưng không sao nếu bạn không biết cách thực hiện. Thật dễ dàng để học và bắt đầu với mã được cung cấp trong bài viết này. Bài viết này được thực hiện bởi FMZ, nhà phát minh ra nền tảng giao dịch định lượng tiền kỹ thuật số (www.fmz.com). Chào mừng bạn tham gia nhóm QQ: 863946592 để giao lưu.
2. Dữ liệu và tài liệu tham khảo học tập
Dữ liệu giá Bitcoin đến từ nền tảng giao dịch định lượng của FMZ: https://www.quantinfo.com/Tools/View/4.html Bài viết về việc sử dụng DRL+gym để đào tạo các chiến lược giao dịch: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4 Một số ví dụ về cách bắt đầu với pytorch: https://github.com/yunjey/pytorch-tutorial Bài viết này sẽ trực tiếp sử dụng bản triển khai ngắn này của mô hình LSTM-PPO: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py Bài viết về PPO: https://zhuanlan.zhihu.com/p/38185553 Thêm bài viết về DRL: https://www.zhihu.com/people/flood-sung/posts Về gym thì bài viết này không cần cài đặt nhưng học tăng cường rất phổ biến: https://gym.openai.com/
3.LSTM-PPO
Để có lời giải thích sâu hơn về PPO, bạn có thể nghiên cứu các tài liệu tham khảo trước đó. Sau đây chỉ là phần giới thiệu về khái niệm đơn giản. Trong số trước, mạng LSTM chỉ dự đoán giá. Cách mua và bán giao dịch dựa trên giá dự đoán này cần được triển khai riêng. Đương nhiên, có thể hình dung rằng sẽ trực tiếp hơn khi xuất trực tiếp các hành động mua và bán , Phải? Chính sách Graident giống như vậy. Nó có thể đưa ra xác suất của nhiều hành động khác nhau dựa trên thông tin môi trường đầu vào. Sự mất mát của LSTM là sự khác biệt giữa giá dự đoán và giá thực tế, trong khi sự mất mát của PG là -log(p)*Q, trong đó p là xác suất của một hành động được đưa ra, và Q là giá trị của hành động (chẳng hạn như điểm thưởng). Giải thích trực quan là nếu giá trị của một hành động cao hơn, mạng sẽ đưa ra xác suất cao hơn để giảm thiểu tổn thất. Mặc dù PPO phức tạp hơn nhiều, nhưng nguyên tắc thì tương tự. Chìa khóa nằm ở cách đánh giá tốt hơn giá trị của từng hành động và cách cập nhật các tham số tốt hơn.
Mã nguồn của LSTM-PPO được đưa ra bên dưới, có thể hiểu khi kết hợp với thông tin trước đó:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Môi trường kiểm tra ngược Bitcoin
Theo định dạng của phòng tập thể dục, có một phương pháp khởi tạo lại, hành động nhập bước và kết quả trả về là (trạng thái tiếp theo, lợi ích của hành động, liệu nó đã hoàn thành hay chưa, thông tin bổ sung). Toàn bộ môi trường kiểm tra ngược chỉ có 60 dòng, có thể do chính bạn sửa đổi. Phiên bản phức tạp, mã cụ thể:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Một số chi tiết đáng chú ý
Tại sao tài khoản ban đầu lại có tiền xu?
Công thức tính lợi nhuận trong môi trường kiểm tra ngược là: Lợi nhuận hiện tại = Giá trị tài khoản hiện tại - Giá trị tài khoản hiện tại ban đầu. Điều này có nghĩa là nếu giá Bitcoin giảm và chiến lược bán đồng tiền này, chiến lược đó thực sự sẽ được đền đáp ngay cả khi tổng giá trị tài khoản giảm. Nếu thời gian kiểm tra ngược dài, tài khoản ban đầu có thể không bị ảnh hưởng nhiều, nhưng vẫn có tác động lớn lúc đầu. Tính toán lợi nhuận tương đối đảm bảo rằng mọi thao tác đúng đều nhận được phần thưởng tích cực.
Tại sao chúng ta lấy mẫu thị trường trong quá trình đào tạo?
Tổng lượng dữ liệu lớn hơn 10.000 K-line. Nếu chạy một chu kỳ đầy đủ mỗi lần, sẽ mất nhiều thời gian và chiến lược sẽ gặp phải tình huống giống hệt nhau mỗi lần, có thể dẫn đến tình trạng quá khớp. Mỗi lần vẽ 500 thanh như dữ liệu kiểm tra ngược. Mặc dù vẫn có thể xảy ra tình trạng quá khớp, chiến lược này phải đối mặt với hơn 10.000 lần khởi đầu khác nhau.
Phải làm gì nếu bạn không có tiền xu hoặc tiền mặt?
Tình huống này không được xem xét trong môi trường kiểm tra ngược. Nếu đồng tiền đã được bán hết hoặc khối lượng giao dịch tối thiểu không đạt được, việc thực hiện hoạt động bán tại thời điểm này thực sự tương đương với việc không thực hiện hoạt động nào. Nếu giá giảm, theo tương đối Phương pháp tính toán lợi nhuận vẫn dựa trên phần thưởng tích cực của chiến lược. Tác động của tình huống này là khi chiến lược xác định thị trường đang giảm và số tiền còn lại trong tài khoản không thể bán được, không thể phân biệt giữa hành động bán và không hoạt động, nhưng nó không ảnh hưởng đến phán đoán riêng của chiến lược. thị trường.
Tại sao phải trả lại thông tin tài khoản dưới dạng trạng thái?
Mô hình PPO có mạng lưới giá trị được sử dụng để đánh giá giá trị của trạng thái hiện tại. Rõ ràng, nếu chiến lược xác định rằng giá sẽ tăng, toàn bộ trạng thái sẽ chỉ có giá trị dương nếu tài khoản hiện tại nắm giữ Bitcoin và ngược lại. Do đó, thông tin tài khoản là cơ sở quan trọng để đánh giá mạng lưới giá trị. Lưu ý rằng thông tin hành động trong quá khứ không được trả về dưới dạng trạng thái, cá nhân tôi cho rằng điều này vô ích để đánh giá giá trị.
Trong trường hợp nào thì nó sẽ không trả về kết quả hoạt động nào?
Khi chiến lược xác định rằng lợi nhuận từ việc mua và bán không đủ để trang trải phí giao dịch thì nên dừng lại. Mặc dù mô tả trước đó đã sử dụng nhiều lần các chiến lược để xác định xu hướng giá, nhưng chỉ vì mục đích dễ hiểu. Trên thực tế, mô hình PPO này không đưa ra bất kỳ dự đoán nào về thị trường, mà chỉ đưa ra xác suất của ba hành động.
6. Thu thập dữ liệu và đào tạo
Như trong bài viết trước, dữ liệu được lấy theo định dạng sau: đường K một giờ của cặp giao dịch BTC_USD trên sàn giao dịch Bitfinex từ ngày 7/5/2018 đến ngày 27/6/2019:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Vì sử dụng mạng LSTM nên thời gian đào tạo rất dài, vì vậy tôi đã chuyển sang phiên bản GPU, nhanh hơn khoảng 3 lần.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Kết quả đào tạo và phân tích
Sau một thời gian dài chờ đợi:

Đầu tiên, chúng ta hãy xem xét xu hướng thị trường của dữ liệu đào tạo. Nhìn chung, nửa đầu là một đợt suy giảm dài, và nửa sau là một đợt phục hồi mạnh mẽ.
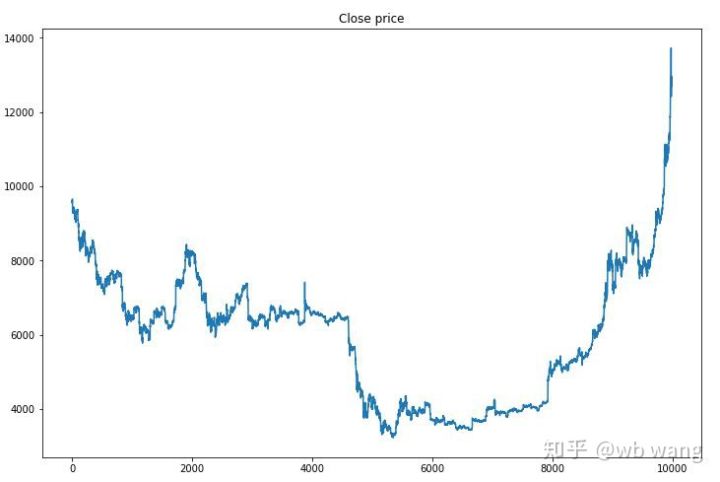
Có rất nhiều hoạt động mua hàng trong giai đoạn đầu của quá trình đào tạo và về cơ bản không có vòng nào có lợi nhuận. Đến giữa thời gian đào tạo, số lượng giao dịch mua giảm dần, xác suất lợi nhuận ngày càng lớn nhưng xác suất thua lỗ vẫn cao.
Làm mịn doanh thu theo từng vòng, kết quả như sau:
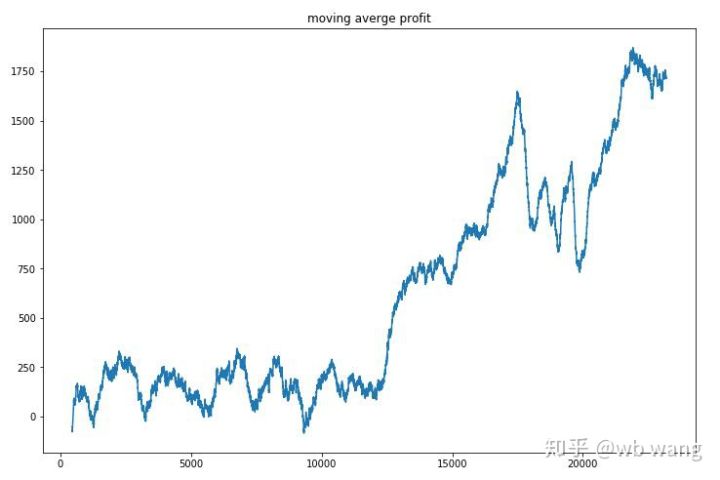
Chiến lược này nhanh chóng loại bỏ được lợi nhuận âm trong giai đoạn đầu, nhưng biến động rất lớn. Phải đến 10.000 vòng, lợi nhuận mới bắt đầu tăng nhanh. Nhìn chung, việc đào tạo mô hình rất khó khăn.
Sau khi hoàn tất quá trình đào tạo cuối cùng, hãy để mô hình chạy lại tất cả dữ liệu để xem nó hoạt động như thế nào. Trong thời gian này, hãy ghi lại tổng giá trị thị trường của tài khoản, số lượng bitcoin nắm giữ, tỷ lệ giá trị bitcoin và tổng thu nhập .
Đầu tiên là tổng giá trị thị trường. Tổng doanh thu cũng tương tự, nên tôi sẽ không đăng ở đây:
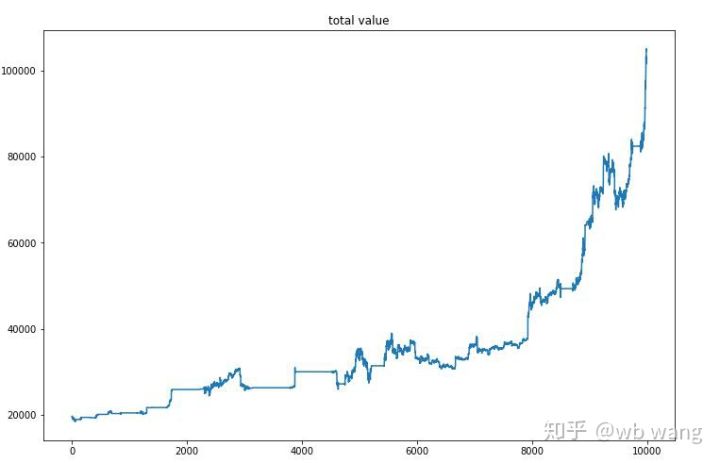
Tổng giá trị thị trường tăng chậm trong giai đoạn đầu của thị trường giá xuống và cũng theo kịp đà tăng trong giai đoạn sau của thị trường giá lên, nhưng vẫn có những khoản lỗ định kỳ.
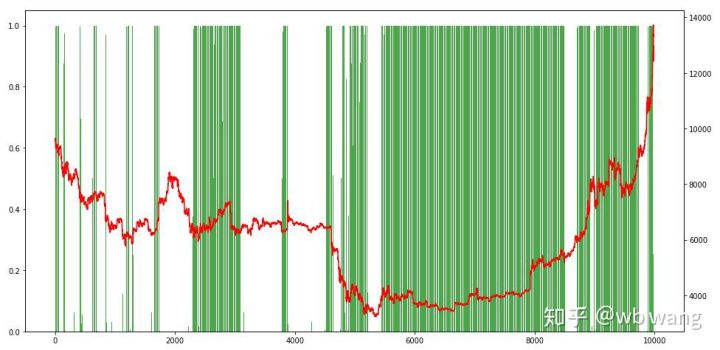
Cuối cùng, chúng ta hãy xem xét tỷ lệ các vị trí. Trục trái của đồ thị là tỷ lệ các vị trí, và trục phải là tình hình thị trường. Có thể xác định sơ bộ rằng mô hình đã được lắp quá mức. Tần suất các vị trí là thấp ở giai đoạn đầu của thị trường giá xuống và tần suất các vị thế rất cao ở đáy của thị trường. Chúng ta cũng có thể thấy rằng mô hình này không học được cách giữ vị thế trong thời gian dài và luôn bán nhanh.
8. Phân tích dữ liệu thử nghiệm
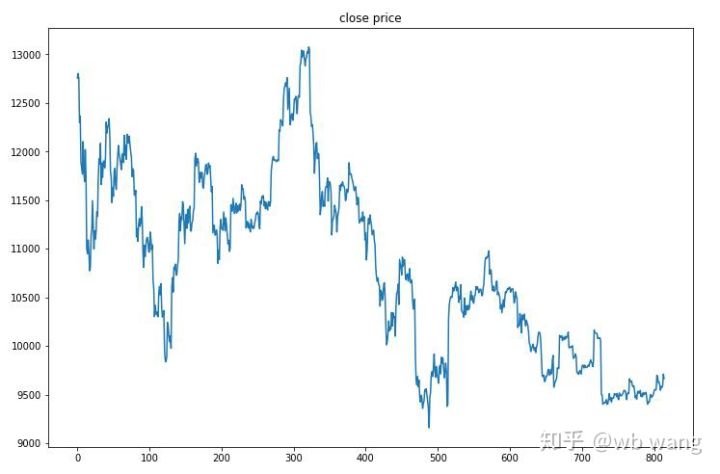
Dữ liệu thử nghiệm được lấy từ thị trường Bitcoin một giờ từ ngày 27/6/2019 đến nay. Như có thể thấy trong hình, giá đã giảm từ 13.000 đô la lúc đầu xuống còn hơn 9.000 đô la hiện nay, đây là một thử nghiệm tuyệt vời cho mô hình.
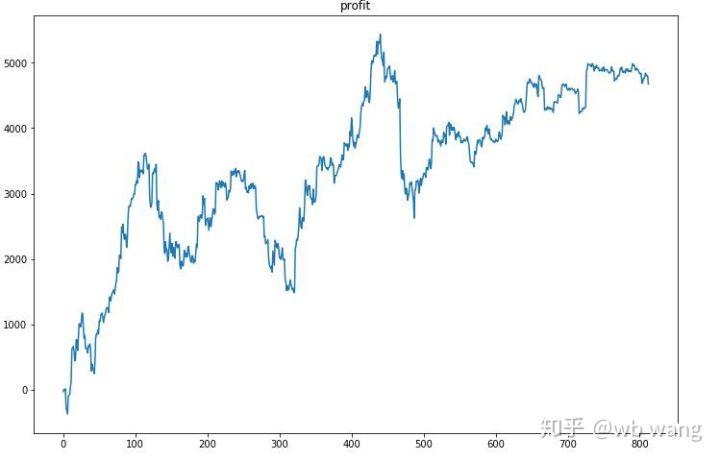
Trước hết, lợi nhuận tương đối cuối cùng không đạt yêu cầu, nhưng cũng không có tổn thất.
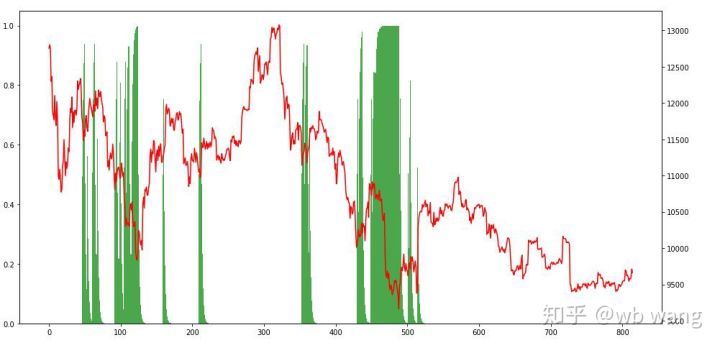
Nhìn vào các vị thế, chúng ta có thể đoán rằng mô hình có xu hướng mua sau khi giảm mạnh và bán sau khi phục hồi. Trong thời gian gần đây, thị trường Bitcoin biến động rất ít và mô hình đã ở vị thế bán khống.
9. Tóm tắt
Bài viết này sử dụng phương pháp học tăng cường sâu PPO để đào tạo robot giao dịch Bitcoin tự động và đưa ra một số kết luận. Do thời gian có hạn nên vẫn còn một số điểm có thể cải thiện trong mô hình. Mọi người đều được hoan nghênh thảo luận. Bài học lớn nhất là chuẩn hóa dữ liệu là phương pháp đúng đắn. Không sử dụng các phương pháp như mở rộng quy mô, nếu không mô hình sẽ nhanh chóng ghi nhớ mối quan hệ giữa giá cả và điều kiện thị trường và rơi vào tình trạng quá khớp. Sau khi chuẩn hóa, tốc độ thay đổi trở thành dữ liệu tương đối, khiến mô hình khó ghi nhớ mối quan hệ của nó với thị trường và buộc phải tìm mối liên hệ giữa tốc độ thay đổi với mức tăng và giảm.
Bài viết trước: Một số chia sẻ chiến lược công khai trên Nền tảng định lượng FMZ Inventor: https://zhuanlan.zhihu.com/p/64961672 Khóa học giao dịch định lượng tiền kỹ thuật số của NetEase Cloud Classroom, chỉ 20 nhân dân tệ: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076 Tôi đã công khai một chiến lược tần suất cao từng rất có lợi nhuận: https://www.fmz.com/bbs-topic/1211