Các báo giá thị trường thu thập nâng cấp một lần nữa
Tác giả:Tốt, Tạo: 2020-05-26 14:25:15, Cập nhật: 2024-12-10 20:35:48
Hỗ trợ nhập file định dạng CSV để cung cấp nguồn dữ liệu tùy chỉnh
Gần đây, một nhà giao dịch cần sử dụng tệp định dạng CSV của riêng mình làm nguồn dữ liệu cho hệ thống backtest nền tảng FMZ. hệ thống backtest của nền tảng của chúng tôi có nhiều chức năng và đơn giản và hiệu quả để sử dụng, do đó, miễn là người dùng có dữ liệu của riêng họ, họ có thể thực hiện backtest theo dữ liệu này, không còn giới hạn ở các sàn giao dịch và giống được hỗ trợ bởi trung tâm dữ liệu nền tảng của chúng tôi.
Ý tưởng thiết kế
Ý tưởng thiết kế thực sự rất đơn giản. chúng tôi chỉ cần thay đổi nó một chút dựa trên các nhà thu thập thị trường trước đây. chúng tôi thêm một tham sốisOnlySupportCSVđến người thu thập thị trường để kiểm tra xem liệu chỉ tệp CSV được sử dụng làm nguồn dữ liệu cho hệ thống backtest.filePathForCSVđược sử dụng để thiết lập đường dẫn của tệp dữ liệu CSV được đặt trên máy chủ nơi robot thu thập thị trường chạy.isOnlySupportCSVtham số được thiết lập thànhTrueđể quyết định nguồn dữ liệu nào để sử dụng (được thu thập bởi chính bạn hoặc dữ liệu trong tệp CSV), sự thay đổi này chủ yếu ởdo_GETchức năng củaProvider class.
File CSV là gì?
Các giá trị tách bằng dấu phẩy, còn được gọi là CSV, đôi khi được gọi là giá trị tách bằng ký tự, bởi vì ký tự tách cũng không thể là dấu phẩy. Tệp của nó lưu trữ dữ liệu bảng (số và văn bản) bằng văn bản đơn giản. Văn bản đơn giản có nghĩa là tệp là một chuỗi các ký tự và không chứa dữ liệu nào phải được giải thích như một số nhị phân. Tệp CSV bao gồm bất kỳ số lượng ghi chép nào, được tách bởi một số ký tự dòng mới; mỗi ghi chép được tạo thành từ các trường, và các bộ tách giữa các trường là các ký tự hoặc chuỗi khác, và phổ biến nhất là dấu phẩy hoặc tab. Nói chung, tất cả các ghi chép đều có cùng một chuỗi các trường. Chúng thường là các tệp văn bản đơn giản.WORDPADhoặcExcelđể mở.
Tiêu chuẩn chung của định dạng tệp CSV không tồn tại, nhưng có một số quy tắc nhất định, thường là một bản ghi trên mỗi dòng, và dòng đầu tiên là tiêu đề.
Ví dụ, tệp CSV chúng tôi sử dụng để kiểm tra được mở bằng Notepad như thế này:
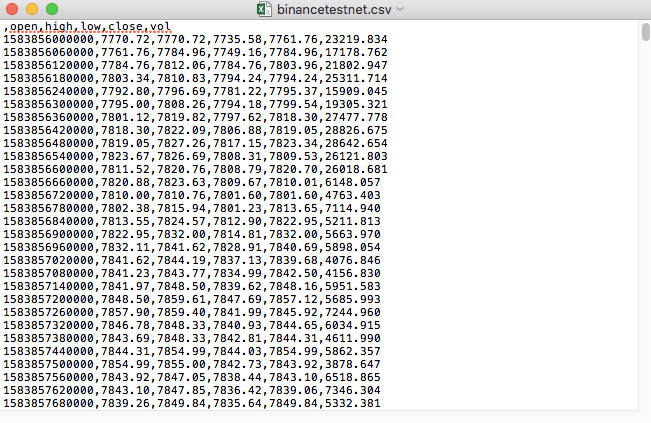
Nhận thấy rằng dòng đầu tiên của tệp CSV là tiêu đề bảng.
,open,high,low,close,vol
Chúng ta chỉ cần phân tích và sắp xếp dữ liệu này, và sau đó xây dựng nó vào định dạng được yêu cầu bởi nguồn dữ liệu tùy chỉnh của hệ thống backtest.
Mã sửa đổi
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Kiểm tra chạy
Đầu tiên, chúng ta khởi động robot thu thập thị trường, chúng ta thêm một bộ trao đổi vào robot và để robot chạy.
Cấu hình tham số:

Sau đó chúng tôi tạo ra một chiến lược thử nghiệm:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
Chiến lược rất đơn giản, chỉ cần lấy và in dữ liệu K-line ba lần.
Trên trang backtest, hãy đặt nguồn dữ liệu của hệ thống backtest như một nguồn dữ liệu tùy chỉnh, và điền vào địa chỉ của máy chủ mà robot thu thập thị trường chạy. Vì dữ liệu trong tệp CSV của chúng tôi là một dòng K 1 phút. Vì vậy, khi backtest, chúng tôi đặt khoảng thời gian K-line là 1 phút.
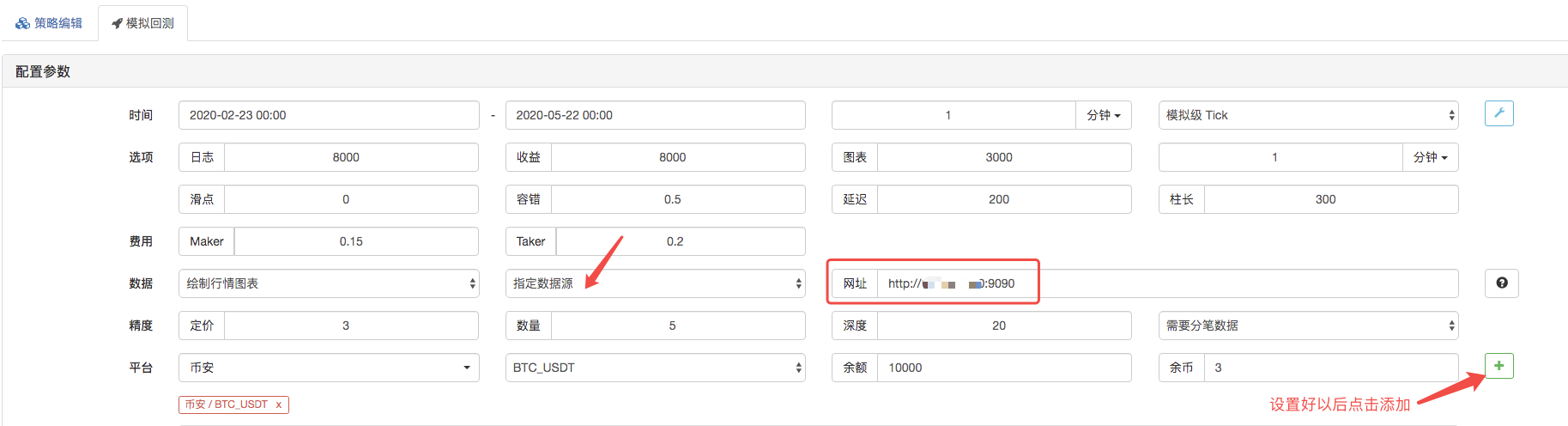
Nhấp để bắt đầu backtest, và robot thu thập thị trường nhận được yêu cầu dữ liệu:

Sau khi chiến lược thực hiện của hệ thống backtest được hoàn thành, một biểu đồ đường K được tạo ra dựa trên dữ liệu đường K trong nguồn dữ liệu.
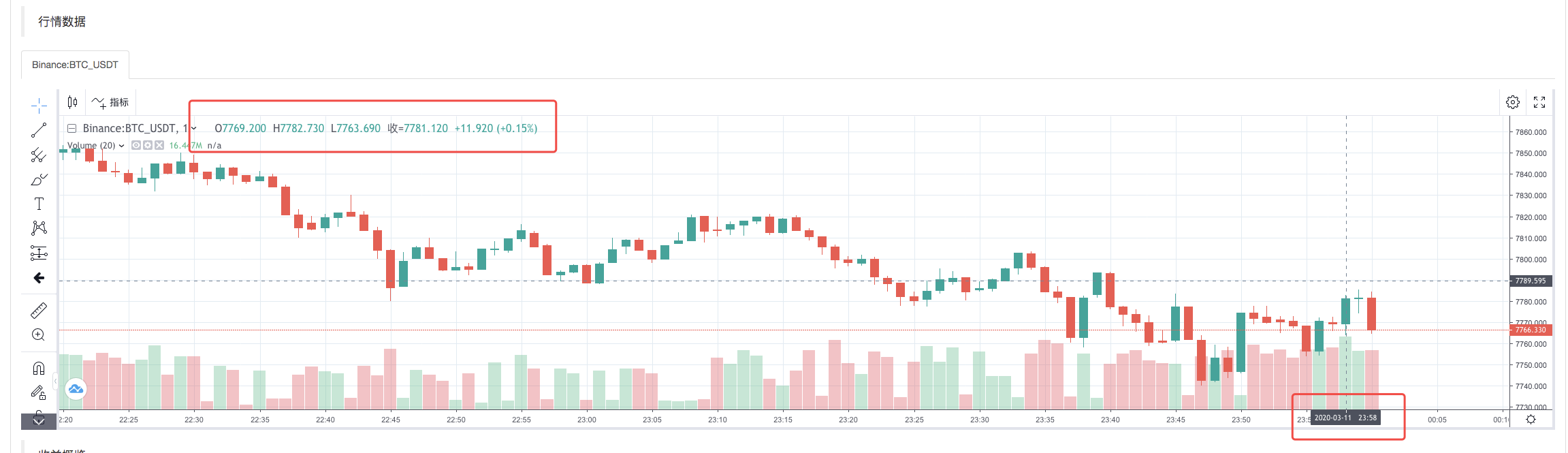
So sánh dữ liệu trong tệp:

- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (3)
- Giới thiệu về Trọng tài Lead-Lag trong Cryptocurrency (2)
- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (2)
- Thảo luận về tiếp nhận tín hiệu bên ngoài của nền tảng FMZ: Một giải pháp hoàn chỉnh để tiếp nhận tín hiệu với dịch vụ Http tích hợp trong chiến lược
- Phân tích nhận tín hiệu bên ngoài nền tảng FMZ: Chiến lược xây dựng dịch vụ HTTP để nhận tín hiệu
- Giới thiệu về Trọng tài Lead-Lag trong Cryptocurrency (1)
- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (1)
- Cuộc thảo luận về tiếp nhận tín hiệu bên ngoài của nền tảng FMZ: API mở rộng VS Chiến lược Dịch vụ HTTP tích hợp
- Phân tích nhận tín hiệu bên ngoài nền tảng FMZ: API mở rộng vs chiến lược dịch vụ HTTP tích hợp
- Cuộc thảo luận về phương pháp thử nghiệm chiến lược dựa trên Random Ticker Generator
- Khám phá phương pháp thử nghiệm chiến lược dựa trên trình tạo thị trường ngẫu nhiên
- Một số suy nghĩ về logic của giao dịch tương lai tiền điện tử
- Công cụ phân tích nâng cao dựa trên phát triển ngữ pháp Alpha101
- Dạy bạn nâng cấp các nhà thu thập thị trường backtest nguồn dữ liệu tùy chỉnh
- Những sai sót của hệ thống hồi âm tần số cao dựa trên giao dịch theo chữ cái và K-line
- Giải thích cơ chế backtest ở mức mô phỏng FMZ
- Cách tốt nhất để cài đặt và nâng cấp FMZ docker trên Linux VPS
- Chiến lược R-Breaker về tương lai hàng hóa
- Một chút suy nghĩ về logic giao dịch tương lai tiền kỹ thuật số
- Dạy bạn thực hiện một bộ sưu tập báo giá thị trường
- Phiên bản Python Tiền tương lai hàng hóa Chiến lược trung bình chuyển động
- Tăng cấp bộ thu hành - hỗ trợ nhập file định dạng CSV để cung cấp nguồn dữ liệu tùy chỉnh
- Chiến lược giao dịch tần số cao tương lai hàng hóa được viết bằng C ++
- Larry Connors Chiến lược đảo ngược RSI2
- Ok Hands dạy bạn cách sử dụng JS để ghép nối FMZ API
- Dựa trên việc sử dụng chỉ số sức mạnh tương đối mới trong các chiến lược trong ngày
- Nghiên cứu về Binance Futures Multi-currency Hedging Strategy Phần 4
- Larry Connors Larry Connors RSI2 chiến lược quay trở lại giá trị trung bình
- Nghiên cứu về Binance Futures Chiến lược phòng hộ đa tiền tệ Phần 3
- Nghiên cứu về Binance Futures Multi-currency Hedging Strategy Phần 2
- Nghiên cứu về Binance Futures Multi-currency Hedging Strategy Phần 1