ঘটনা সংগ্রাহক পুনরায় আপগ্রেড - কাস্টম ডেটা উত্স সরবরাহ করতে CSV ফর্ম্যাট ফাইল আমদানি সমর্থন
লেখক:উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্ন, তৈরিঃ 2020-05-23 15:44:47, আপডেটঃ 2024-12-10 20:19:56
অ্যাকাউন্ট সংগ্রাহক পুনরায় আপগ্রেড করুন টেম্পলেট সমর্থন CSV ফর্ম্যাট ফাইল আমদানি কাস্টমাইজড ডেটা উত্স প্রদান
সাম্প্রতিক ব্যবহারকারীরা তাদের CSV ফর্ম্যাট ফাইলগুলিকে ডেটা উত্স হিসাবে ব্যবহার করতে চান, যাতে উদ্ভাবকরা প্ল্যাটফর্মের ডেটা সেন্টার সমর্থিত এক্সচেঞ্জের মধ্যে সীমাবদ্ধ না হয়ে, তাদের ডেটা থাকা পর্যন্ত পুনরায় পরীক্ষা করার জন্য সংক্ষিপ্ত এবং দক্ষতার সাথে ব্যবহার করে।
ডিজাইন
এই ডিজাইনের ধারণাগুলো খুবই সহজ, আমরা শুধু আগের মার্কেট গ্যালারেটর এর উপর ভিত্তি করে কিছু পরিবর্তন করেছি, আমরা মার্কেট গ্যালারেটর এর জন্য একটি প্যারামিটার যুক্ত করেছি।isOnlySupportCSVএকটি প্যারামিটার যোগ করা হয়েছে যা নিয়ন্ত্রণ করে যে কেবলমাত্র CSV ফাইলগুলিকে ডেটা উত্স হিসাবে পুনর্বিবেচনার সিস্টেমে সরবরাহ করা হয় কিনাfilePathForCSV, যা একটি সার্ভারে CSV ডেটা ফাইল স্থাপন করার পথ নির্ধারণ করে যা একটি মার্কেট সংগ্রাহক রোবট দ্বারা চালিত হয়।isOnlySupportCSVপ্যারামিটার সেট করা আছে কি নাTrueএই পরিবর্তনটি মূলত সেই ডেটা উত্স (১, নিজের দ্বারা সংগৃহীত, ২, সিএসভি ফাইলের ডেটা) ব্যবহার করার সিদ্ধান্ত নেওয়ার জন্য করা হয়েছে।Providerশ্রেণীdo_GETফাংশনগুলোতে।
সিএসভি ফাইল কি?
কমা-বিভক্ত মান (CSV, কখনও কখনও কমা-বিভক্ত মানও বলা হয়, কারণ বিভাজক অক্ষরগুলিও কমা হতে পারে) এর ফাইলগুলি খাঁটি পাঠ্য আকারে সারণীর ডেটা (সংখ্যা এবং পাঠ্য) সঞ্চয় করে। খাঁটি পাঠ্য মানে এই যে ফাইলটি একটি অক্ষর সিরিজ যা বাইনারি সংখ্যার মতো বিশ্লেষণ করা আবশ্যক নয়। CSV ফাইলগুলি যে কোনও সংখ্যার রেকর্ড দ্বারা গঠিত হয়, রেকর্ডের ব্যবধানে কিছু রূপান্তরিত সারি দ্বারা পৃথক করা হয়; প্রতিটি রেকর্ড ক্ষেত্র দ্বারা গঠিত হয়, এবং ব্যবধানের বিভাজকটি অন্য অক্ষর বা স্ট্রিং, সর্বাধিক সাধারণভাবে কমা বা টেমপ্লেট অক্ষর হয়। সাধারণত, সমস্ত রেকর্ডের ঠিক একই অনুচ্ছেদ সিরিজ থাকে। এটি সাধারণত খাঁটি পাঠ্য ফাইল। এটি WORDPAD ব্যবহার করার পরামর্শ দেওয়া হয় বা এটি পুনরায় চালু করা হয়, অন্যথায় ফাইলটি নতুন EXCEL দিয়ে শুরু হয়, এটিও একটি পদ্ধতি।
সিএসভি ফাইল ফরম্যাটের জন্য কোন সাধারণ মানদণ্ড নেই, কিন্তু একটি নিয়ম আছে, যা সাধারণত একটি রেকর্ডের জন্য একটি লাইন, প্রথম ক্রিয়া শিরোনাম; প্রতিটি লাইনের ডেটা একটি কমা ব্যবধান ব্যবহার করে।
উদাহরণস্বরূপ, আমরা যে CSV ফাইলটি পরীক্ষা করতে চেয়েছিলাম তা একটি ডায়ালগ দিয়ে খোলা হয়েছিলঃ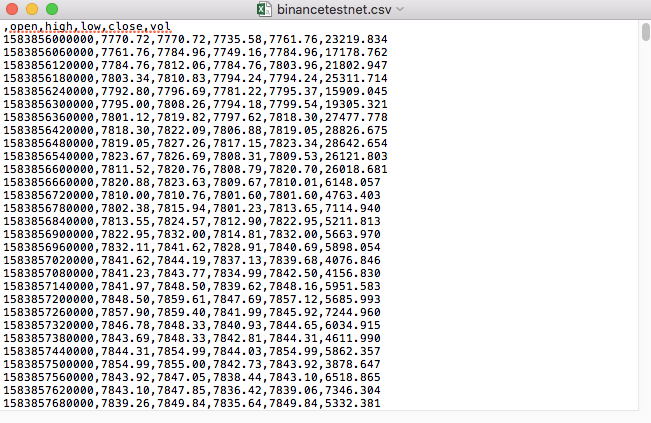
লক্ষ্য করুন, CSV ফাইলের প্রথম লাইনটি হল ফর্মের শিরোনাম।
,open,high,low,close,vol
আমরা এই ধরনের ডেটা বিশ্লেষণের জন্য একটি ফর্ম্যাট তৈরি করতে চাই যা রিভিউ সিস্টেমের কাস্টমাইজড ডেটা উত্সের প্রয়োজনীয়তা তৈরি করে, যা আমাদের পূর্ববর্তী নিবন্ধের কোডে ইতিমধ্যে পরিচালনা করা হয়েছে, কেবলমাত্র সামান্য পরিবর্তন করে।
সংশোধিত কোড
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
পরীক্ষা চালান
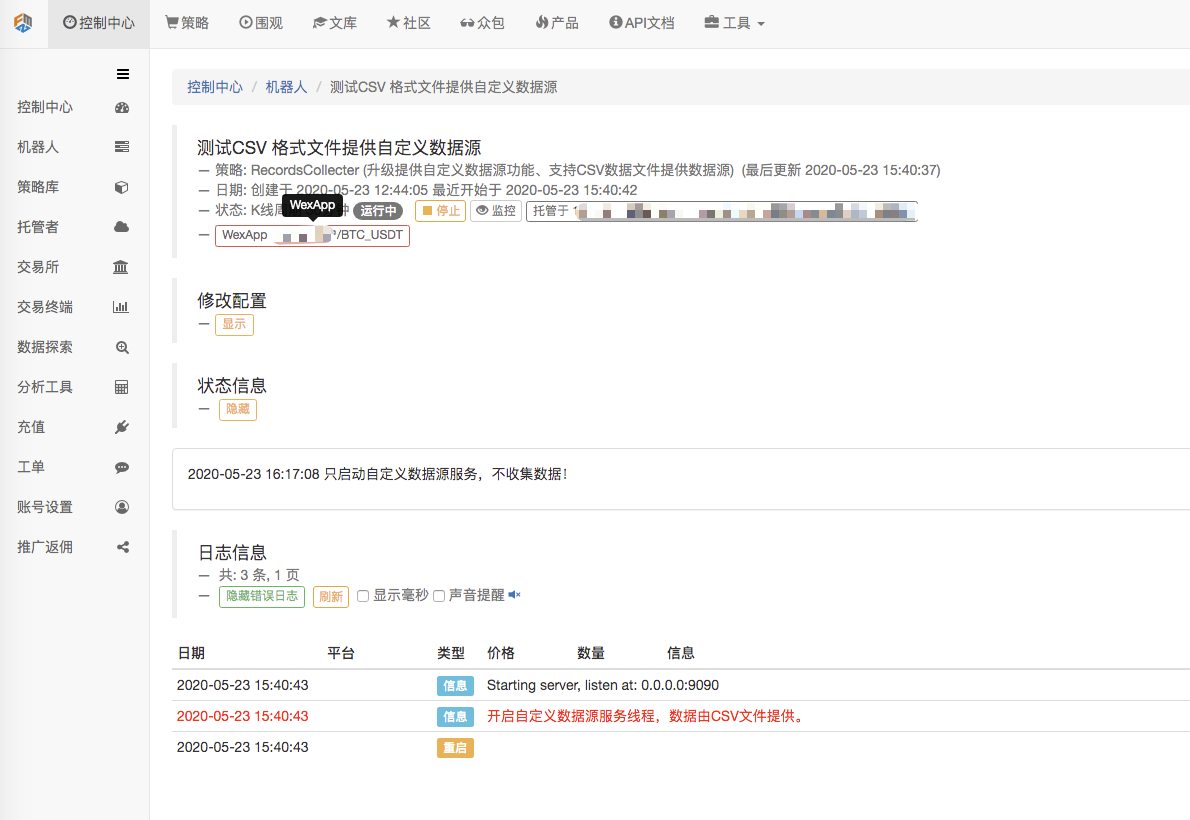
প্রথমত, আমরা মার্কেট-গ্রাহক রোবট চালু করি, আমরা রোবটকে একটি এক্সচেঞ্জ যোগ করি এবং রোবটকে চালিত করি।
প্যারামিটার কনফিগারেশনঃ
এবং তারপর আমরা একটি পরীক্ষা কৌশল তৈরি করেছিঃ
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
কৌশলটি খুবই সহজ, মাত্র তিনটি কে-লাইন ডেটা সংগ্রহ এবং প্রিন্ট করুন।
পুনরাবৃত্তি পৃষ্ঠা, পুনরাবৃত্তি সিস্টেমের ডেটা উত্সকে কাস্টম ডেটা উত্স হিসাবে সেট করুন, এবং ঠিকানাটি মার্কেট সংগ্রহকারী বট দ্বারা চালিত সার্ভারের ঠিকানা পূরণ করুন। যেহেতু আমাদের সিএসভি ফাইলের ডেটা 1 মিনিটের কে লাইন। তাই পুনরাবৃত্তি করার সময়, আমরা 1 মিনিটের জন্য কে লাইন চক্র সেট করি।
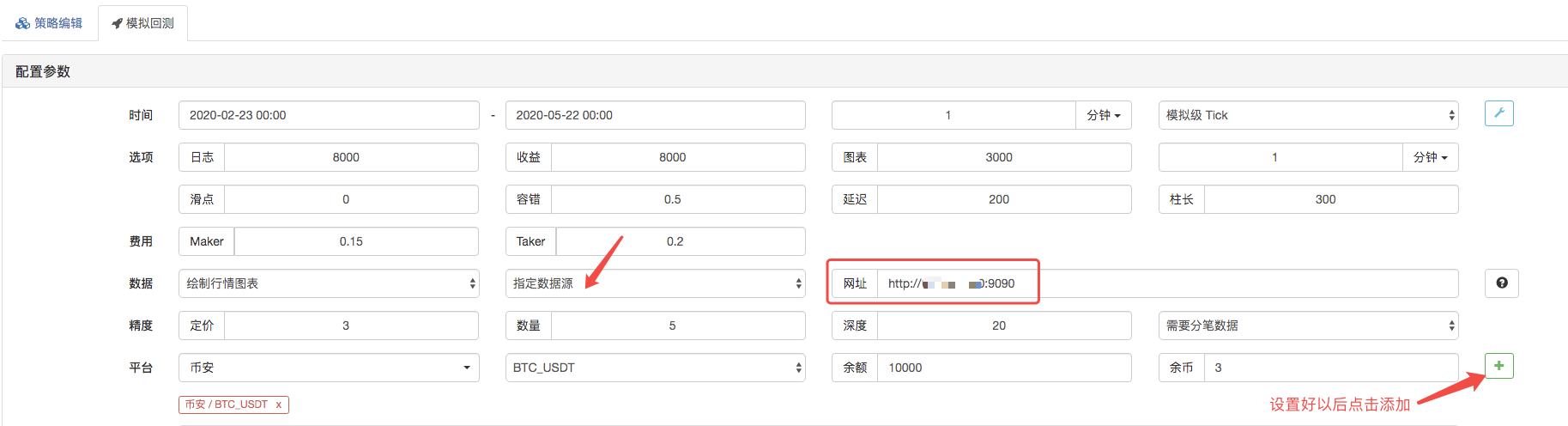
এটির নাম হল "প্যাকেজিং" এবং এটির নাম হল "প্যাকেজিং" ।
পুনর্বিবেচনা সিস্টেম কার্যকর করার পর, ডাটা উত্সের K-লাইন ডেটার উপর ভিত্তি করে K-লাইন চার্ট তৈরি করুন।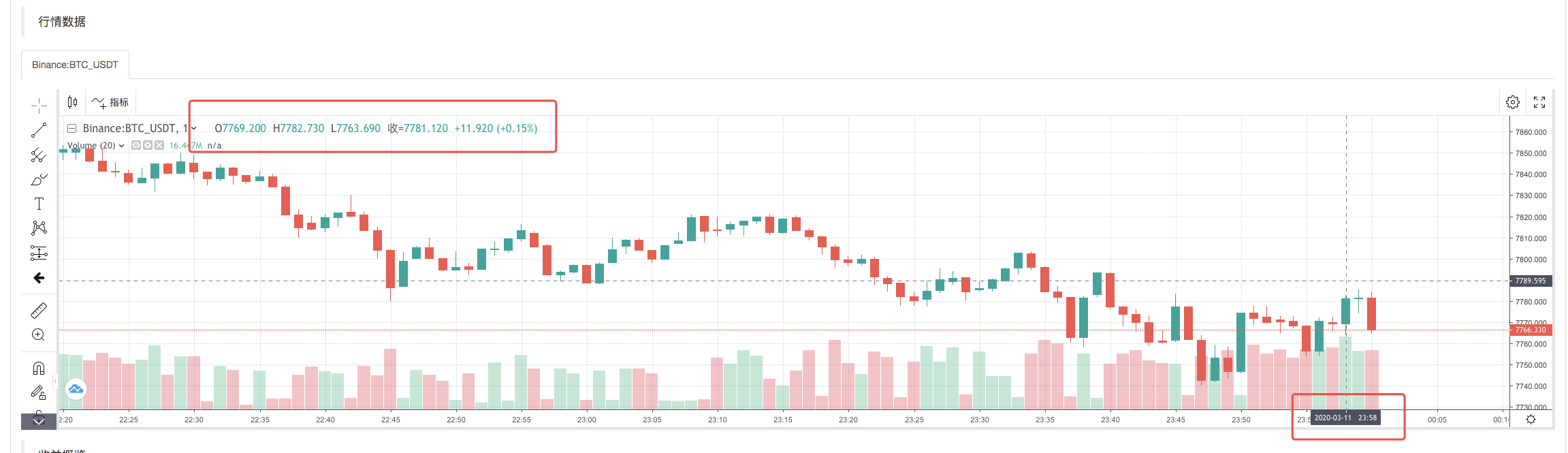
তথ্যের তুলনাঃ

RecordsCollector (কাস্টম ডেটা উত্সের জন্য আপগ্রেড, CSV ডেটা ফাইলের জন্য ডেটা উত্সের জন্য সমর্থন)
এই ভিডিওতে, আপনি আপনার প্রিয় বন্ধুদের সাথে কথা বলতে পারেন।
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (2)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (২)
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণ নিয়ে আলোচনাঃ কৌশলগতভাবে অন্তর্নির্মিত এইচটিটিপি পরিষেবা সহ সংকেত গ্রহণের জন্য একটি সম্পূর্ণ সমাধান
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ কৌশলগুলি অন্তর্নির্মিত এইচটিটিপি পরিষেবাগুলির সংকেত গ্রহণের সম্পূর্ণ সমাধান
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (1)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণের বিষয়ে আলোচনাঃ বর্ধিত এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ এক্সটেনশান এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- র্যান্ডম টিকার জেনারেটরের উপর ভিত্তি করে কৌশল পরীক্ষার পদ্ধতি নিয়ে আলোচনা
- র্যান্ডম মার্কেট জেনারেটরের উপর ভিত্তি করে কৌশলগত পরীক্ষার পদ্ধতিগুলি অনুসন্ধান করুন
- এফএমজেড কোয়ান্টের নতুন বৈশিষ্ট্যঃ সহজেই এইচটিটিপি সার্ভিস তৈরি করতে _সার্ভ ফাংশন ব্যবহার করুন
- আলফা১০১ ব্যাকরণ বিকাশের উপর ভিত্তি করে উন্নত বিশ্লেষণ সরঞ্জাম
- আপনি বাজার সংগ্রাহক আপগ্রেড শেখান ব্যাকটেস্ট কাস্টম তথ্য উৎস
- উচ্চ-ফ্রিকোয়েন্সি পুনরাবৃত্তি সিস্টেম এবং কে-লাইন পুনরাবৃত্তির ত্রুটিগুলি
- এফএমজেড সিমুলেশন স্তরের ব্যাকটেস্ট প্রক্রিয়া ব্যাখ্যা
- লিনাক্স ভিপিএসে এফএমজেড ডকার ইনস্টল এবং আপগ্রেড করার সর্বোত্তম উপায়
- কমোডিটি ফিউচার R-Breaker কৌশল
- ডিজিটাল মুদ্রার ফিউচার ট্রেডিংয়ের যুক্তি সম্পর্কে একটু চিন্তা করুন
- আপনাকে শেখান কিভাবে একটি বাজার কোট সংগ্রহকারী বাস্তবায়ন
- পাইথন সংস্করণ কমোডিটি ফিউচার মুভিং গড় কৌশল
- বাজার কোট সংগ্রহকারী আবার আপগ্রেড
- কমোডিটি ফিউচার হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল C++ দ্বারা লিখিত
- ল্যারি কনরস আরএসআই ২-এর অর্থ বিপরীতমুখী কৌশল
- ওক হ্যান্ডশেক আপনাকে JS এর সাথে FMZ এক্সটেনশন এপিআই জুড়তে শেখায়
- ইনট্রা ডে কৌশলগুলিতে একটি নতুন আপেক্ষিক শক্তি সূচক ব্যবহারের ভিত্তিতে
- বাইনারেন্স ফিউচার মাল্টি-ভারেন্সি হেজিং স্ট্র্যাটেজি পার্ট 4 এর উপর গবেষণা
- ল্যারি Connors ল্যারি Connors RSI2 গড় মূল্য প্রত্যাবর্তন কৌশল
- বাইনারেন্স ফিউচার মাল্টি-কার্উয়েন্সি হেজিং স্ট্র্যাটেজি পার্ট ৩ নিয়ে গবেষণা
- বাইনারেন্স ফিউচার মাল্টি-কার্উয়েন্সি হেজিং স্ট্র্যাটেজি পার্ট ২ নিয়ে গবেষণা
- বাইনারেন্স ফিউচার মাল্টি-ভারেন্সি হেজিং স্ট্র্যাটেজি পার্ট 1 এর উপর গবেষণা
- হ্যান্ডশেক আপনাকে কাস্টমাইজড ডেটা উত্সের বৈশিষ্ট্যগুলি পুনরুদ্ধার করতে শেয়ার সংগ্রাহককে আপগ্রেড করতে শেখায়
ভাইয়েরা।অ্যাডমিনিস্ট্রেটর সার্ভারে কি পাইথন ইনস্টল করা দরকার?
স্পার্ডা খেলুনএখন, এই কাস্টমাইজড ডাটা সোর্সটি আবার ব্রাউজারের দিকে ফিরে আসে, ডাটা সঠিকতা নিয়ে সমস্যা আছে, আপনি চেষ্টা করে দেখুন।
এআইকেপিএম-/upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png আমি রোবটকে সংযুক্ত করেছি, ঠিকানাটি কিভাবে পূরণ করব, আমি সার্ভারের ঠিকানাটি পূরণ করেছি, পোর্ট পাসওয়ার্ড 9090। সংগ্রাহকটিও সাড়া দিচ্ছে না।
weixxদয়া করে জিজ্ঞাসা করুন কেন আমি হোস্ট সার্ভারে কাস্টম CSV ডেটা উত্স সেট আপ করেছি, পৃষ্ঠা অনুরোধে ডেটা রিটার্ন রয়েছে, এবং পুনরায় পরীক্ষা করার সময় কোনও ডেটা রিটার্ন নেই, যখন ডেটা কেবল দুটি ডেটা হিসাবে সরাসরি সেট করা হয়, তখন HTTP সার্ভার টার্মিনাল অনুরোধে /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d286587b3e.ng /upload/asset/169e8dcdbf9c0c544pbac8.png
weixxঅনুগ্রহ করে জিজ্ঞাসা করুন কেন আমি হোস্ট সার্ভারে কাস্টম সিএসভি ডেটা উত্স সেট আপ করেছি, পৃষ্ঠা অনুরোধে ডেটা রিটার্ন আছে, তারপর রিটার্নে কোনও ডেটা রিটার্ন নেই, এবং HTTP সার্ভার টার্মিনে /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28d658795b3e.png /upload/asset/169e8dcdbf9c0c544p8.png /upload/asset/169c6c4c3d28658795b3e.png
qq89520প্যারামিটারগুলো কিভাবে সেট করা হয়?
উপদেশআমি মনে করি যে, আমি এই বিষয়ে খুব বেশি সচেতন নই, কিন্তু আমি মনে করি যে, আমি এই বিষয়ে খুব সচেতন।
ডসাইডাসি 666
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নআমি পাইথন ব্যবহার করতে চাই।
স্পার্ডা খেলুনএটি একটি সিস্টেম ত্রুটি যা সংশোধন করা হয়েছে।
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নএপিআই ডকুমেন্টেশনে নির্ভুলতার বিষয়ে নির্দেশাবলী রয়েছে।
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নএখানে CSV ফাইলগুলিকে ডেটা উত্স হিসাবে ব্যবহার করা হয়েছে, যা পুনর্বিবেচনার সিস্টেমে ডেটা সরবরাহ করে।
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নএপিআই ডকুমেন্টেশনে বর্ণনা দেখুন।
weixxকাস্টম ডেটা ব্যবহার করে exchange.GetData (()) পদ্ধতিতে, কি K লাইনকে কাস্টম ডেটাতে রূপান্তরিত করতে পারে?
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নকাস্টম ডেটা উত্স সরবরাহকারী এই পরিষেবাটি অবশ্যই সার্ভারে থাকা উচিত, এটি অবশ্যই পাবলিক নেটওয়ার্ক আইপি হতে হবে। স্থানীয় পরিষেবা পুনরুদ্ধার সিস্টেমগুলি অ্যাক্সেসযোগ্য নয়।
weixxঅনুগ্রহ করে জিজ্ঞাসা করুন কিভাবে স্থানীয়ভাবে http সার্ভার এ স্থানীয় পুনরাবৃত্তি করা যায়, স্থানীয় পুনরাবৃত্তি কাস্টম ডেটা উত্স পুনরাবৃত্তি সমর্থন করে না? আমি স্থানীয় পুনরাবৃত্তি এক্সচেঞ্জ যোগ করা হয়েছেঃ [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"}] এই পরামিতি, এবং বট রূপান্তরিত আইপি এছাড়াও সার্ভার অনুরোধ করা হয় না
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নডেটা ভলিউম খুব বেশি. ওয়েব পেজ লোড করা সম্ভব নয়, এছাড়াও ডেমো. আপনার গবেষণায়, এটি ঠিক হওয়া উচিত, আমি অনুমান করি যে আপনি ভুলভাবে সেট আপ করেছেন।
weixxআমি csv ডেটা এক মিনিট K লাইন অন্যান্য মুদ্রার ডেটা, তারপর যেহেতু পুনরাবৃত্তি সময় লেনদেনের জোড়া বেছে নিতে পারেন না, তারপর রোবট এবং পুনরাবৃত্তি সময় নির্বাচন বিনিময় উভয় জন্য সেট করা হয় huobi, লেনদেনের জোড়া জন্য BTC-USDT, এই অনুরোধ তথ্য আমি কখনও কখনও রোবট পক্ষ থেকে অনুরোধ গ্রহণ করতে পারে, কিন্তু পুনরাবৃত্তি পক্ষ থেকে তথ্য অর্জন করতে পারে না, এবং আমি csv সময় বিন্দু সেকেন্ড থেকে ক্ষুদ্রতম সেকেন্ডে পরিবর্তন এমনকি তথ্য অর্জন করতে পারে না। জানি না স্থানীয়ভাবে পুনরাবৃত্তি ডেটা অপ্টিমাইজ করার কোন উপায় আছে, যখন কৌশল পরামিতি অপ্টিমাইজ করা হয়, ওয়েব পৃষ্ঠা ক্র্যাশ হবে।
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নবিটিসি_ইউএসডিটি-র সাথে লেনদেন, আপনি কোনটি নির্দিষ্টভাবে উল্লেখ করছেন? এই সংজ্ঞার ডেটা কি প্রয়োজনীয়? উদাহরণস্বরূপ, সময় অংশটি মিলিসেকেন্ড এবং সেকেন্ড উভয়ই দেখা যায়?
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নআমি পরীক্ষার সময় এটি পরীক্ষা করেছি।
weixxখুব কম পরিমাণে তথ্য পাওয়া যায়, কিন্তু যখন আমি একটি CSV ফাইল নির্দিষ্ট করি যেখানে এক বছরের বেশি সময় ধরে এক মিনিটের বেশি ডেটা পাওয়া যায় না, তখন কি খুব বড় পরিমাণে ডেটা পাওয়া যায়? তাহলে কি এটি স্থানীয়ভাবে একটি কাস্টম ডেটা উত্স খুলতে পারে এবং স্থানীয়ভাবে পুনরায় পরীক্ষা করতে পারে?
weixxআমি বর্তমানে আমার রোবটে HUOBI এক্সচেঞ্জ কনফিগার করছি, তারপর বিটিসি-ইউএসডিটি ট্রেডিং প্যারে সেট করা আছে, পুনরায় পরীক্ষা করার সময়ও এটি কনফিগার করা আছে, এবং পুনরায় পরীক্ষা করার জন্য কোডটি একটি exchange.GetRecords (()) ফাংশন ব্যবহার করে, এই সংজ্ঞায়িত ডেটা কি প্রয়োজনীয়?
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নআপনি ব্রাউজারে থাকতে পারেন কারণ আপনি আপনার নির্দিষ্ট প্রশ্নের প্যারামিটার লিখেছেন, উত্তর সিস্টেমটি ট্রিগার করতে পারেনি বট উত্তর দেয়, এটি বোঝায় যে বটটি অনুরোধটি গ্রহণ করেনি, ব্যাখ্যা করে যে উত্তর দেওয়ার সময় জায়গাটি ভুলভাবে কনফিগার করা হয়েছে, পরীক্ষা, ডিবাগিংয়ের সময় সমস্যাটি খুঁজে পাওয়া যায়।
উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্নআপনি যদি আপনার নিজের CSV ফাইলটি পড়তে চান তবে এই ফাইলটির পথটি সেট করতে পারেন।