Upgrade des Datenerfassers - Unterstützung für CSV-Dateien, um eine benutzerdefinierte Datenquelle zu erhalten
Schriftsteller:Die Erfinder quantifizieren - Kleine Träume, Erstellt: 2020-05-23 15:44:47, aktualisiert: 2024-12-10 20:19:56
Die Aktenkollektor-Neuauflage unterstützt CSV-Dateien und bietet eine benutzerdefinierte Datenquelle.
Der jüngste Benutzer benötigt seine CSV-Datei als Datenquelle, um die Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung der Quantifizierung.
Entwurfsideen
Die Designidee ist eigentlich sehr einfach, wir haben nur ein paar Änderungen an der Basis des bisherigen Markt-Sammlers gemacht, und wir haben dem Markt-Sammler einen Parameter hinzugefügt.isOnlySupportCSVUm zu kontrollieren, ob nur CSV-Dateien als Datenquelle für das Retesting-System bereitgestellt werden, wird ein Parameter hinzugefügtfilePathForCSVDer Weg, wie man CSV-Daten auf einem Server platziert, der von einem Markt-Sammler-Roboter betrieben wird.isOnlySupportCSVSollte die Parameter aufTrueDiese Änderung ist vor allem für die Verwendung von Daten, die von den Benutzern selbst gesammelt wurden, und für die Verwendung von Daten aus CSV-Dateien.ProviderKategoriedo_GETDie Funktion ist in der Funktion.
Was ist eine CSV-Datei?
Komma-Separated Values (CSV, manchmal auch als Charakter-Separated Values bezeichnet, da auch Komma-Separate Characters nicht Komma sein können) sind Dateien, die Tabellendaten in reinem Text (Zahlen und Text) speichern. Reiner Text bedeutet, dass die Datei eine Zeichenfolge ist, die keine Daten enthält, die wie eine binäre Zahl entschlüsselt werden müssen. CSV-Dateien bestehen aus beliebigen Zieldatensätzen, die in gewisser Weise von einem Wechselzeichen getrennt werden. Jeder Datensatz besteht aus Feldern, die von anderen Charakteren oder Strängen getrennt werden.
Es gibt keine allgemeine Norm für das CSV-Dateiformat, aber es gibt eine Regel, die in der Regel für eine Zeile mit einem ersten Aktenkopf verwendet wird.
Die CSV-Dateien, die wir zum Beispiel getestet haben, sehen so aus, wenn sie mit dem Logbuch geöffnet werden: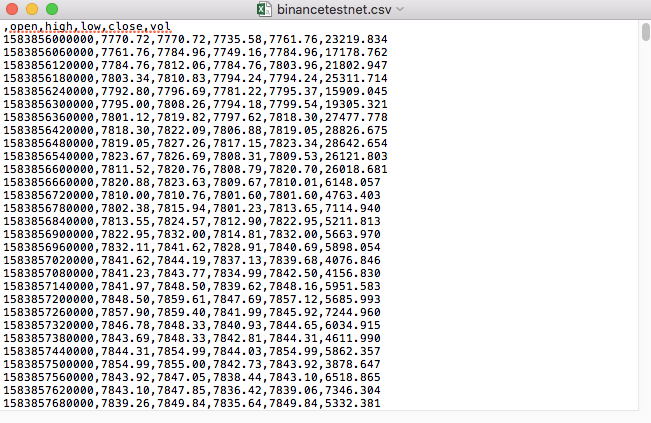
Die erste Zeile des CSV-Dokumentes ist die Formularüberschrift.
,open,high,low,close,vol
Wir müssen diese Daten analysieren und dann ein Format erstellen, in dem das Retriever-System die Datenquellenanforderungen anpassen kann, was wir in unserem vorherigen Artikel bereits behandelt haben, nur um es ein wenig zu ändern.
Geänderter Code
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Lauftest
Zuerst starten wir den Markt-Sammler-Roboter, wir fügen dem Roboter eine Börse hinzu und lassen den Roboter laufen.
Parameterkonfiguration:
Wir haben dann eine Teststrategie entwickelt:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
Die Strategie ist sehr einfach: man erhält und druckt nur drei K-Linien-Daten.
Die Datenquelle, auf der die Datenquelle des Retargeting-Systems als benutzerdefinierte Datenquelle eingestellt ist, und die Adresse, die die Serveradresse des von dem Markt-Sammler-Bot ausgeführten Server füllt. Da die Daten in unserer CSV-Datei eine K-Zeile von 1 Minute sind, setzen wir die K-Zeilzyklus auf 1 Minute, wenn wir retargeten.
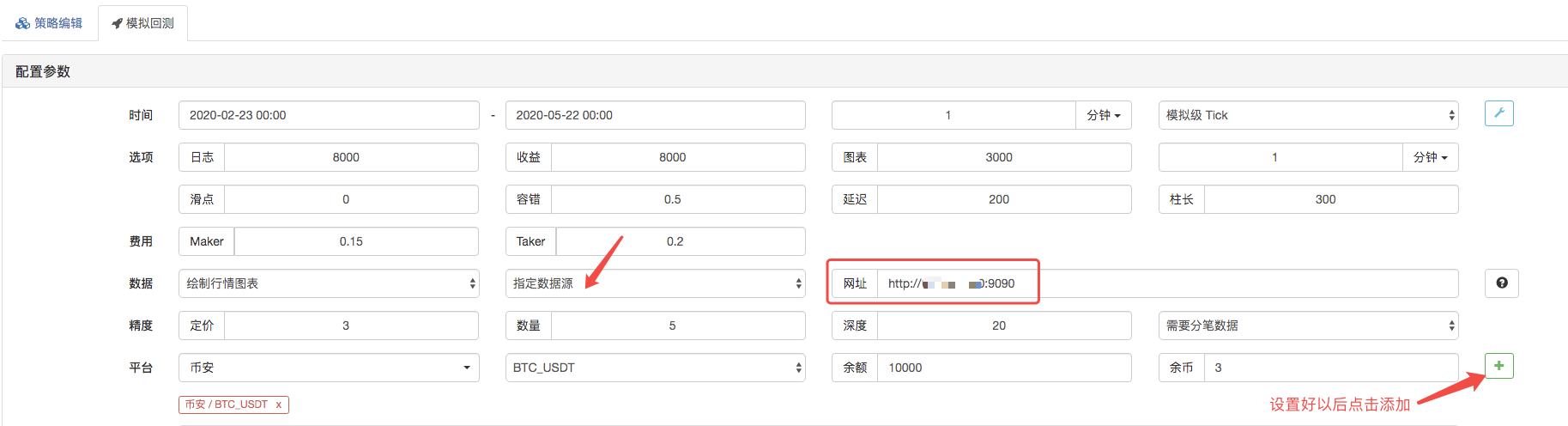
Einer von ihnen sagte, dass er sich nicht auf die Daten von der Bank konzentrieren würde.
Nach Abschluss der Ausführung der Requestsystem-Politik wird ein K-Linien-Chart nach den K-Linien-Daten in der Datenquelle erzeugt.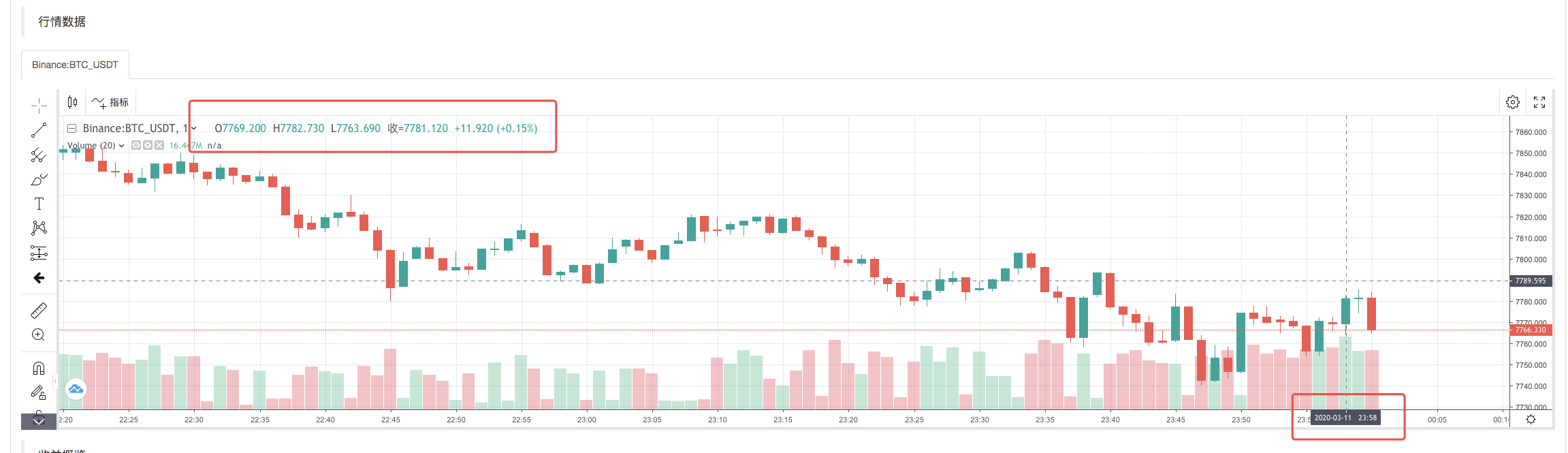
Die Daten in den Dokumenten werden verglichen:

Ich möchte Ihnen sagen, dass ich das Gefühl habe, dass ich in der Lage bin, das zu tun.
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (2)
- Einführung der Lead-Lag-Suite in der digitalen Währung (2)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Eine Komplettlösung für den Empfang von Signalen mit integriertem Http-Service in der Strategie
- FMZ-Plattform: Erforschung von Signalempfangsstrategien für externe Netzwerke
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (1)
- Einführung der Lead-Lag-Suite in der Kryptowährung (1)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Erweiterte API VS Strategie eingebauter HTTP-Service
- FMZ-Plattform-External Signal Reception: Erweiterung der API vs. Strategien für den eingebauten HTTP-Dienst
- Diskussion über die Strategie-Testmethode auf Basis eines Zufalls-Ticker-Generators
- Strategie-Testmethoden basierend auf Random-Market-Generatoren untersucht
- Neue Funktion von FMZ Quant: _Serve-Funktion zum einfachen Erstellen von HTTP-Diensten
- Erweitertes Analyse-Tool basierend auf der Alpha101-Grammatikentwicklung
- Ich zeige Ihnen, wie Sie den Market Collector aktualisieren und die benutzerdefinierte Datenquelle testen.
- Schwachstellen von Hochfrequenz-Rückmeldungssystemen und K-Linien-Rückmeldung auf Basis von Transaktionen pro Stück
- Beschreibung des Mechanismus für die Rückprüfung der FMZ-Simulationsstufe
- Der beste Weg zum Installieren und Upgrade von FMZ Docker auf Linux VPS
- Strategie für Rohstoff-Futures
- Ein Gedanke an die Logik des digitalen Futures-Handels
- Ich zeige Ihnen, wie man einen Marktzins-Sammler implementiert.
- Strategie für Rohstofffutures mit gleitendem Durchschnitt in Python-Version
- Marktnoten-Sammler erneut aktualisieren
- Strategie für den Hochfrequenzhandel mit Rohstofffutures, geschrieben in C++
- Larry Connors RSI2 Mittelumkehrstrategie
- OK Handshake lehrt Sie, wie man FMZ mit der JS-Pairing-API erweitert
- Auf der Grundlage der Verwendung eines neuen relativen Stärkenindex in Intraday-Strategien
- Forschung über Binance Futures Multi-Währung Hedging Strategie Teil 4
- Larry Connors Larry Connors RSI2 Mittelwert-Rückkehr-Strategie
- Forschung über Binance Futures Multi-Währung Hedging Strategie Teil 3
- Forschung über Binance Futures Multi-Währung Hedging Strategie Teil 2
- Forschung über Binance Futures Multi-Währung Hedging Strategie Teil 1
- Die Hand zeigt Ihnen, wie Sie die Funktionen für die Anpassung von Datenquellen an den Rechner aktualisieren können.
Ich bin ein Freund von dir.Muss Python auf dem Administrator-Server installiert werden?
Spartan spielt QuantumDrehbuch, jetzt, wenn diese benutzerdefinierte Datenquelle von der Browserseite zurückgeschaltet wird, gibt es ein Problem mit der Datenpräzision.
- Ich bin nicht derjenige./upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png Ich habe den Roboter aufgehängt, wie soll ich die Adresse dort ausfüllen, die Serveradresse, die ich ausgefüllt habe, Portpass 9090, und der Collector reagiert nicht.
WeixxBitte fragen Sie mich, warum ich auf dem Host-Server eine benutzerdefinierte CSV-Datenquelle installiert habe, die Daten mit der Seitenaufforderung zurückgibt, und dann keine Daten bei der Wiederholung zurückgibt, wenn die Daten direkt auf nur zwei Daten gesetzt werden. Der HTTP-Server kann die Anfrage /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d286587b3e.ng /upload/asset/169e8dcdbf9c0c544pbac8.png
WeixxBitte fragen Sie, warum ich auf dem Host Server eine benutzerdefinierte CSV-Datenquelle installiert habe, die Daten mit der Seitenaufforderung zurückgibt, und dann keine Daten bei der Rückprüfung zurückgibt und keine Anfragen an den HTTP-Server-Termin /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28d658795b3e.png /upload/asset/169e8dcdbf9c0c544png
- Ich weiß nicht.Wie ist die Einstellung der Parameter?
PredigtIch bin der Ansicht, dass es eine gute Idee ist, eine hochwertige Währung zu entwickeln, um jede Währung zu messen, vielleicht auch Aktien.
Siehe auch 666
Die Erfinder quantifizieren - Kleine TräumeDas ist ein sehr schwieriges Thema.
Spartan spielt QuantumEs war ein Fehler im System, der behoben wurde.
Die Erfinder quantifizieren - Kleine TräumeDie API-Dokumentation enthält Hinweise auf die Präzision.
Die Erfinder quantifizieren - Kleine TräumeSie müssen Artikel und Code verstehen. Hier geht es um CSV-Dateien als Datenquelle, um Daten an das Retrieval-System zu liefern.
Die Erfinder quantifizieren - Kleine TräumeSiehe die Beschreibung in der API-Dokumentation.
WeixxKann man die K-Zeile mit der Methode exchange.GetData (()) für die Wiederholung benutzen, um sie zu benutzerdefinierten Daten zu machen?
Die Erfinder quantifizieren - Kleine TräumeDer Dienst, der eine benutzerdefinierte Datenquelle anbietet, muss auf einem Server sein, der eine öffentliche IP-Adresse hat.
WeixxBitte fragen Sie mich, wie kann ich auf dem lokalen HTTP-Server Daten lokal zurückrufen, unterstützt lokaler Rückruf nicht die Rückrufung von benutzerdefinierten Datenquellen? Ich habe den exchanges [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"} in den lokalen Rückrufen hinzugefügt, dieser Parameter, sowie die IP des Roboter, wird auch nicht an den Server angefordert.
Die Erfinder quantifizieren - Kleine TräumeDie Datenmenge ist zu groß. Die Webseite kann nicht geladen werden, außerdem ist DEMO, das du untersucht hast, wahrscheinlich in Ordnung.
WeixxIch bin ein CSV-Daten ist eine Minute K-Linie ist die Daten der anderen Währungen, und dann, da die Transaktionspaare nicht zufällig ausgewählt werden können, wenn Sie zurückgehen, ist der Roboter und die Transaktionspaare, auf die Sie zurückgehen, auf Huobi gesetzt, und die Transaktionspaare auf BTC-USDT, die Anfrage-Daten, die ich manchmal auf der Seite des Robots empfangen kann, aber die Rücklaufseite kann keine Daten erhalten, und ich habe die CSV-Zeitleiste von Sekunden in Millisekunden geändert, die auch nicht Daten erhalten kann.
Die Erfinder quantifizieren - Kleine TräumeWas genau meinst du, wenn du mit BTC_USDT gehandelt hast? Gibt es Anforderungen an die Daten, die diese Definition enthält?
Die Erfinder quantifizieren - Kleine TräumeDie Datenmenge ist gut, und ich habe es beim Testen getestet.
WeixxEine kleine Datenmenge ist erhältlich, aber wenn ich eine CSV-Datei für mehr als ein Jahr spezifiziere und feststelle, dass ich keine Daten für mehr als eine Minute erhalte, hat das Auswirkungen auf die Datenmenge?
WeixxIch habe gerade auf meinem Roboter die HUOBI-Börse konfiguriert, und dann ist das Handelspärchen BTC-USDT, das auch eingestellt ist, so konfiguriert, und dann wird der Code für die Wiederholung verwendet, also eine exchange.GetRecords))) Funktion.
Die Erfinder quantifizieren - Kleine TräumeSie können auf der Browserseite sein, weil Sie die Anfrage-Parameter angegeben haben, und das Reaktionssystem kann nicht auslösen. Der Roboter antwortet, dass der Roboter die Anfrage nicht akzeptiert hat, und erklärt, dass der Ort beim Reaktionen falsch konfiguriert wurde.
Die Erfinder quantifizieren - Kleine TräumeSie können den Weg für diese Datei einstellen, wenn Sie Ihre CSV-Datei lesen möchten, wie in diesem Beispiel beschrieben.