Upgraded case collector - support for CSV file import to provide custom data sources
Author: Inventors quantify - small dreams, Created: 2020-05-23 15:44:47, Updated: 2024-12-10 20:19:56
Case collector re-upgrades to support CSV format file import to provide custom data sources
The most recent user needs to have their own CSV file as a data source, so that inventors can use the backtesting system of the quantified trading platform. The inventors of the backtesting system of the quantified trading platform have many features, using a concise and efficient way, so that as long as they have their own data, they can be backtested, no longer limited to the exchanges supported by the platform data center.
Design ideas
The design idea is actually very simple, we just make a little bit of a change based on the previous market collector, and we add a parameter to the market collector.isOnlySupportCSVTo control whether only CSV files are used as data sources for the retrieval system, add a parameterfilePathForCSV, a path to place CSV data files on a server run by a market collector robot; and finally, a path to place CSV data files on a server run by a market collector robot.isOnlySupportCSVWhether the parameter is set toTrueThis change is mainly due to the fact that the user can choose to use the data source (data collected by the user, data in CSV files).Providerclassdo_GETIn the function.
What is a CSV?
Comma-Separated Values (CSV, sometimes also called character separation values, because a separation can also be a comma) are files that store table data in plain text form (numbers and text). Plain text means that the file is a sequence of characters, without data that must be decoded like a binary number. CSV files are made up of arbitrary number of records, separated by some sort of comma; each record is made up of fields, separated by other characters or strings, most commonly commas or table characters.
There is no common standard for the CSV file format, but there is a rule of thumb, which is generally a record of one line, the first act heading.
For example, the CSV file that we used to test was opened with a notebook and looked like this: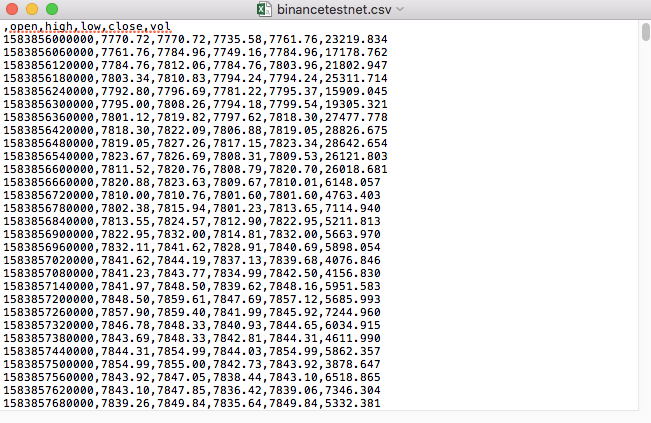
Note that the first line of a CSV file is the form header.
,open,high,low,close,vol
We're going to parse this data and then construct a format that makes the retrieval system customize the data source request, which we've already addressed in the code in our previous article, with just a few tweaks.
Modified code
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Running tests
First we start the market collector robot, we add an exchange to the robot, and we make the robot work.
The parameters are configured:
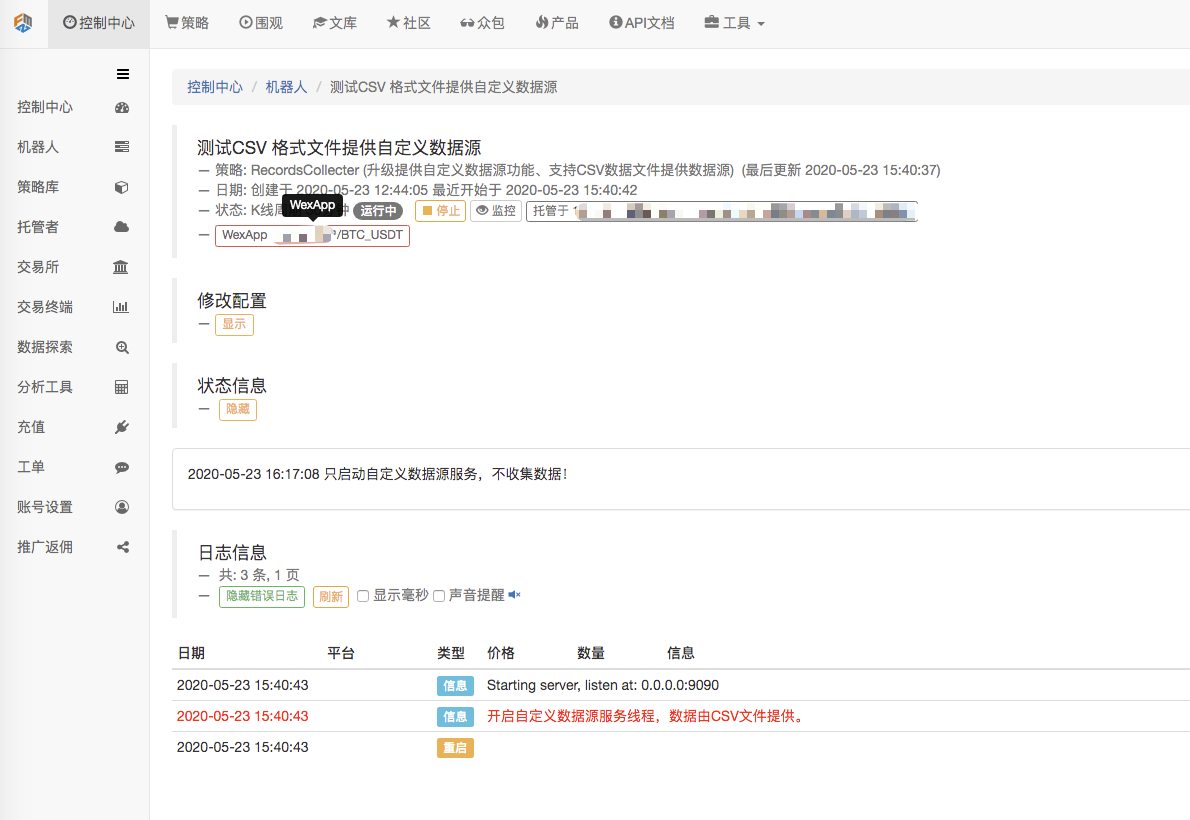
We then created a test strategy:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
The trick is simple: just get and print three K-string data.
The retrieval page, the data source for which the retrieval system is set as a custom data source, and the address filling is the server address run by the market gathering bot. Since the data in our CSV file is a 1-minute K-line, we set the K-line cycle to 1 minute when retrieving.
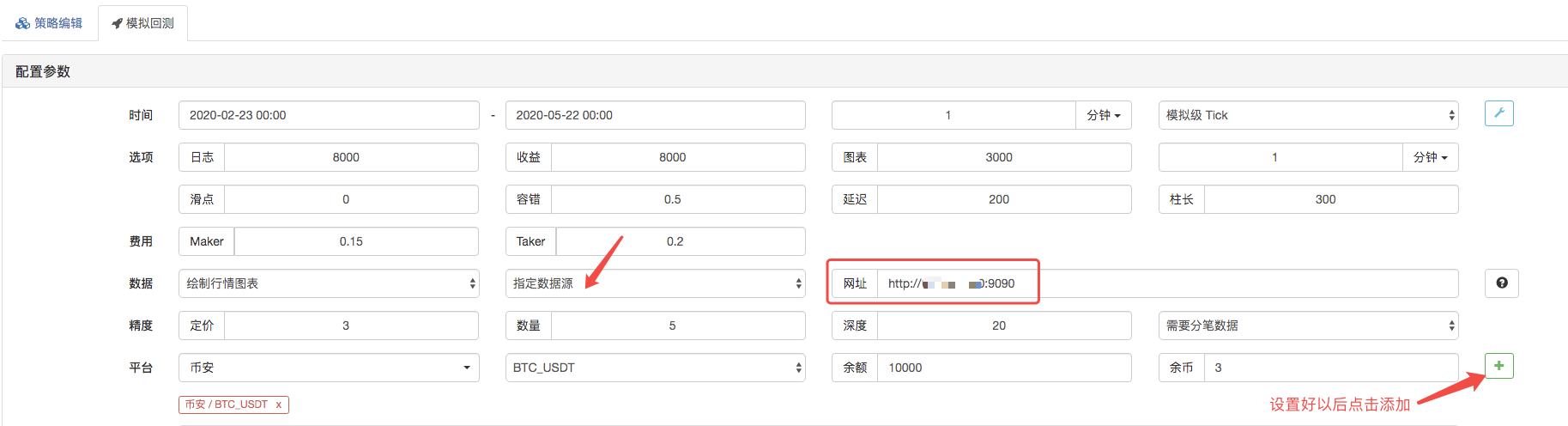
Click to start retrieving, and the market gathering robot receives a data request:
After the re-testing system execute the policy, a K-line chart is generated based on the K-line data in the data source.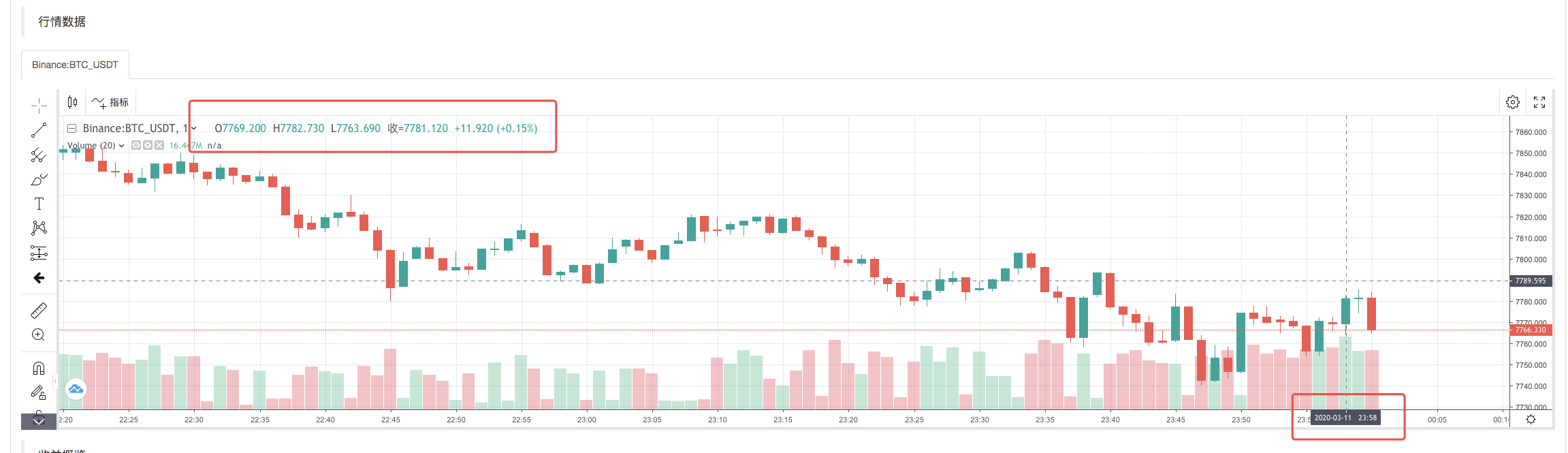
Compare the data in the file: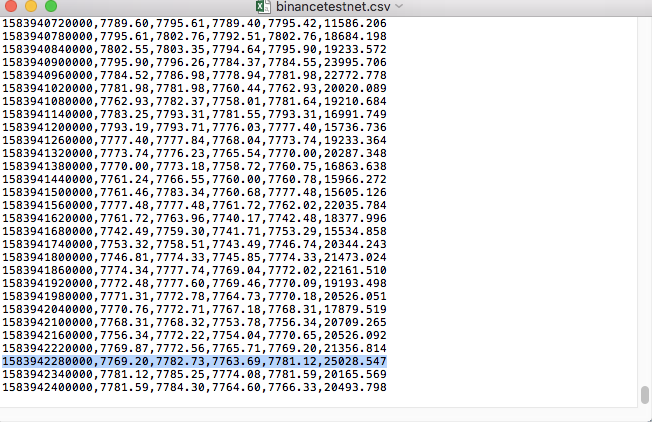

I'm glad to see you're back, and welcome to your comments.
- Introduction to Lead-Lag Arbitrage in Cryptocurrency (2)
- Introduction to the Lead-Lag suite in the digital currency (2)
- Discussion on External Signal Reception of FMZ Platform: A Complete Solution for Receiving Signals with Built-in Http Service in Strategy
- Discussing FMZ platform external signal reception: a complete set of strategies for the reception of signals from built-in HTTP services
- Introduction to Lead-Lag Arbitrage in Cryptocurrency (1)
- Introduction to the Lead-Lag suite in digital currency (1)
- Discussion on External Signal Reception of FMZ Platform: Extended API VS Strategy Built-in HTTP Service
- External signal reception on FMZ platforms: extended API vs. built-in HTTP services
- Discussion on Strategy Testing Method Based on Random Ticker Generator
- Strategy testing methods based on random market generators explored
- New Feature of FMZ Quant: Use _Serve Function to Create HTTP Services Easily
- Enhanced analysis tool based on Alpha101 grammar development
- Teach you to upgrade the market collector backtest the custom data source
- Defects in high-frequency echo systems based on pen-to-pen transaction and K-line echoes
- FMZ simulation level backtest mechanism explanation
- The best way to install and upgrade FMZ docker on Linux VPS
- Commodity Futures R-Breaker Strategy
- A bit of thinking about the logic of digital currency futures trading
- Teach you to implement a market quotes collector
- Python Version Commodity Futures Moving Average Strategy
- Market quotes collector upgrade again
- Commodity Futures High Frequency Trading Strategy written by C++
- Larry Connors RSI2 Mean Reversion Strategy
- OK hands-on teaches you how to use JS to pair FMZ extension APIs
- Based on the use of a new relative strength index in intraday strategies
- Research on Binance Futures Multi-currency Hedging Strategy Part 4
- Larry Connors Larry Connors RSI2 mean return strategy
- Research on Binance Futures Multi-currency Hedging Strategy Part 3
- Research on Binance Futures Multi-currency Hedging Strategy Part 2
- Research on Binance Futures Multi-currency Hedging Strategy Part 1
- Hands-on teaches you how to upgrade to a custom data source to retrieve custom data.
I'm not sure.Does the host need to install python on the server?
Spartan play quantifiedNow, this custom data source is backed up on the browser side, and there's a problem with the accuracy of the data, so you can try it.
AiKPM-/upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png This is a dynamic list and may never be able to satisfy particular standards for completeness. I've attached the bot, how should I fill in the URL, I filled in the server address port code 9090 and the collector is not responding.
weixxPlease ask why I set up a custom CSV data source on the host server, with a page request that returns data, and then no data return in retrieval, when the data is directly set to only two data, the https server can receive in the request, /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c6c4c3d286587b3e.png /upload/asset/169e8dcdbf9c0c544pbac8.png
weixxPlease tell me why I set up a custom CSV data source on the host server, with a page request that returns data, and then no data is returned in the retest, and no request is made to /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28d658795b3e.png /upload/asset/169e8ddbf9c0c544png
qq89520I'll ask you how the parameters are set.
homilyIf you want to measure the value of a currency, you can measure the value of any currency, and maybe even the value of stocks.
dsaidasi 666
Inventors quantify - small dreamsI need to have a python.
Spartan play quantifiedIt's a bug in the system, and it's fixed.
Inventors quantify - small dreamsThe API documentation provides a description of the accuracy, and you can try it here.
Inventors quantify - small dreamsThis is a CSV file that is used as a data source to provide data to the retrieval system.
Inventors quantify - small dreamsSee the description in the API documentation.
weixxCan the custom data be converted to custom data using the exchange.GetData ((() method for backtesting?
Inventors quantify - small dreamsThe service that provides the custom data source must be on a server, and must be a public IP; the local service retrieval system cannot access it.
weixxCan you tell me how to set up a local retrieval on the http server, is it that local retrieval does not support retrieval of custom data sources? I added exchanges to the local retrieval: [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"}] This parameter, as well as the IP of the robot, is also not requested to the server.
Inventors quantify - small dreamsThe data volume is too large. The web page can not be loaded, and DEMO you have researched, should be fine, I guess you set it wrong there.
weixxI'm a csv data is a minute K line is data of other currencies, and then since the exchange pair can't be randomly selected at the time of retesting, the robot and the exchange selected for retesting are set to huobi, the exchange pair is BTC-USDT, this request data I'm sometimes on the side of the robot can receive the request, but retesting side can't get the data, and I changed the time bar of csv from seconds to milliseconds also can't get the data.
Inventors quantify - small dreamsIs there a requirement for this definition of data? Is it possible to view both milliseconds and seconds?
Inventors quantify - small dreamsI've been testing it when I was testing it.
weixxA small amount of data can be retrieved, but when I specify a CSV file with more than a minute of data for a year and it turns out that it can't be retrieved, is the amount of data too large to affect?
weixxWhat I'm currently configuring on my robot is a HUOBI exchange, and then the trading pair is also set to BTC-USDT, which is also configured when retesting, and then the retested code is using an exchange.GetRecords))) function, is there a requirement for this defined data?
Inventors quantify - small dreamsYou may be at the browser end because you have specified the query parameters, the response system could not trigger the bot to respond, indicating that the bot did not accept the request, explaining that the site was configured incorrectly when responding, checking, debugging and finding the problem.
Inventors quantify - small dreamsIf you want to read your own CSV file, you can set the path of this file as shown in this text.