When we predict probabilities, what do we predict?
Author: Inventors quantify - small dreams, Created: 2017-02-25 00:22:28, Updated:When we predict probabilities, what do we predict?
I was interviewed a long time ago, and the subject of the interview made me think again.
Interviewer: Did you know Logistic is coming back? Me: Of course I know, very often. Interviewer: So how do you think the probability of Logistic's regression prediction is to be explained? Me: Certainly not. The individual probability cannot be estimated if there is only one observation. It should be explained as, given N individuals with the same characteristics, the success rate is equal to the estimated probability.
Well, the interviewer couldn't say no, and of course the final result was that I was expelled (probably because of my background in economics and not statistics or computers).
You may find what I said above a bit contradictory or hard to understand, but when we estimated Logistic's return, we estimated:
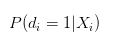
Shouldn't it be explained as the probability of individual success?
- #### I think this is a bit of a problem.
When we talk about the probability of success of a single person, it should be the average number of times the same person succeeds in 100 repetitions under the same conditions. If we remember t as the number of times someone tries, then our ideal model (data generation process) should look like this:
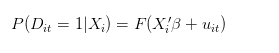
Alternatively, however, the actual data generation process might look something like this:
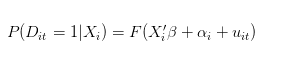

- HttpQuery is not used in Python
- What does it mean to be a "dispossessed" hedge fund?
- Talking about the odds of winning and losing
- This is probably the biggest lie in investing!
- How to Survive in a Random World
- Discover trends and follow trends
- Disclosure of the Big Data Fund
- Why are retail investors buying and selling (Contrarian)?
- If you can't win, throw a coin and make a deal, can you still make money?
- The journey of machine learning algorithms
- Programmatic transaction flow chart (an idea to the program)
- _C() Re-test the function
- _N() function, small number of decimal places, precision control
- Adaptive learning in the first place
- Real and formal trading systems
- Three short stories about understanding real estate, stocks and money
- Six branches of Quant uncovered
- Dynamic time series based pattern recognition strategies
- Thinking about an analog exchange
- Eight well-known crypto hedge EA's review of strategy
hello886lgistic itself has nothing to do with probability, just to map the distance to 0−1.
tzjistzjInteresting
Inventors quantify - small dreamsIf you have time to speak, the discussion on this forum should be very engaging.