Actualización del recolector de transacciones - soporte para la importación de archivos en formato CSV para proporcionar fuentes de datos personalizadas
El autor:Los inventores cuantifican - sueños pequeños, Creado: 2020-05-23 15:44:47, Actualizado: 2024-12-10 20:19:56
El recolector de transacciones de actualización de archivos soporta la importación de archivos en formato CSV para proporcionar fuentes de datos personalizadas
El usuario más reciente necesita tener sus propios archivos en formato CSV como fuente de datos, para que los inventores puedan utilizar el sistema de retrospección de la plataforma de negociación cuantitativa.
La idea del diseño
La idea del diseño es muy simple, simplemente modificamos un poco la base del colector de mercados anterior, y le agregamos un parámetro al colector de mercados.isOnlySupportCSVPara controlar si solo se utiliza un archivo CSV como fuente de datos para el sistema de recuperación, se agrega un parámetrofilePathForCSV, para configurar el camino para colocar el archivo de datos CSV en el servidor operado por el robot recolector de transacciones.isOnlySupportCSVSi los parámetros están configurados comoTrueEste cambio se debe principalmente a que los usuarios de Google no pueden usar la fuente de datos (datos recopilados por ellos mismos, datos en archivos CSV) para decidir el uso de la fuente de datos.ProviderLas clasesdo_GETEn la función.
¿Qué es un archivo CSV?
Comma-Separated Values (CSV, a veces también denominados como valores de separación de caracteres, ya que los caracteres de separación también pueden no ser códigos), cuyos documentos almacenan datos de tablas en forma de texto puro (números y texto). El texto puro significa que el documento es una secuencia de caracteres, sin datos que deban ser interpretados como si fueran números binarios. Los archivos CSV están compuestos por registros de un número arbitrario de propósitos, separados por algún tipo de símbolo de intercambio de registros; cada registro está compuesto por campos separados por otros caracteres o cadenas, lo más comúnmente códigos o caracteres de tabla.
No existe un estándar general para el formato de archivo CSV, pero existe una norma, generalmente una línea de registro, el primer acto de inicio; los datos en cada línea se interponen con intervalos de coma.
Por ejemplo, el archivo CSV que usamos para probar se abrió con un diario y se veía así: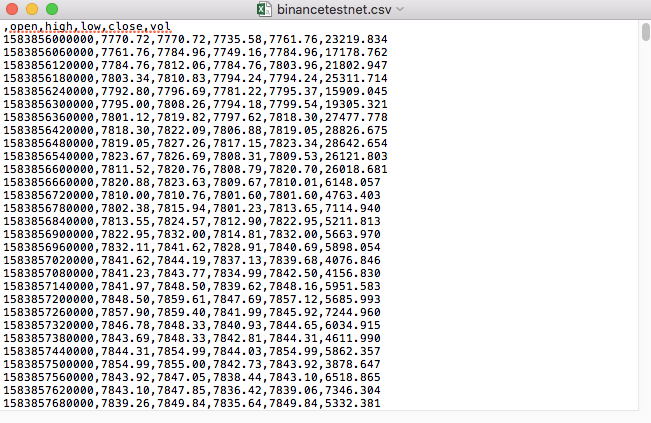
Observe que la primera línea del documento CSV es el encabezado del formulario.
,open,high,low,close,vol
Lo que hacemos es analizar este tipo de datos y luego construir un formato que permita al sistema de búsqueda personalizar los requerimientos de fuentes de datos, que ya se han tratado en el código de nuestro artículo anterior, con solo una pequeña modificación.
Código modificado
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Pruebas de ejecución
Primero, iniciamos el robot recolector de mercado, le agregamos un intercambio y lo ponemos en marcha.
Configuración de los parámetros:
Entonces creamos una estrategia de prueba:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
La estrategia es simple: sólo se obtienen y se imprimen tres K-rays de datos.
La página de repetición, la fuente de datos del sistema de repetición se configura como una fuente de datos personalizada y la dirección se llena con la dirección del servidor operado por el bot recolector de transacciones. Como los datos de nuestro archivo CSV son K líneas de 1 minuto, cuando se repite, se establece un ciclo de K líneas de 1 minuto.
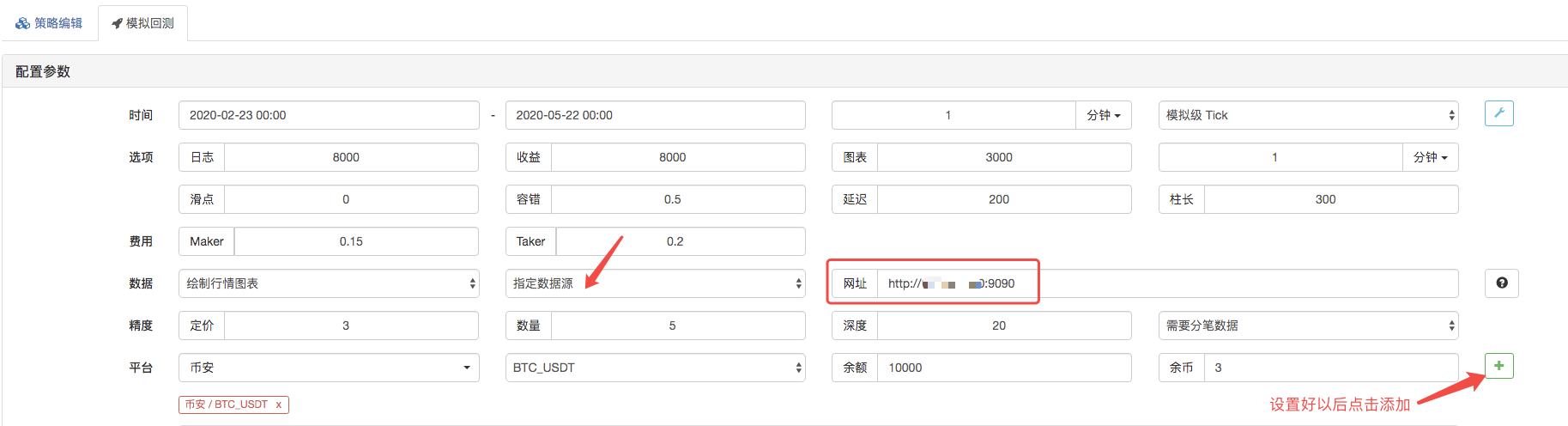
El bot de recopilación de transacciones recibe una solicitud de datos:
Una vez que la política de ejecución del sistema de repetición se ha completado, se genera un gráfico de líneas K basado en los datos de las líneas K de la fuente de datos.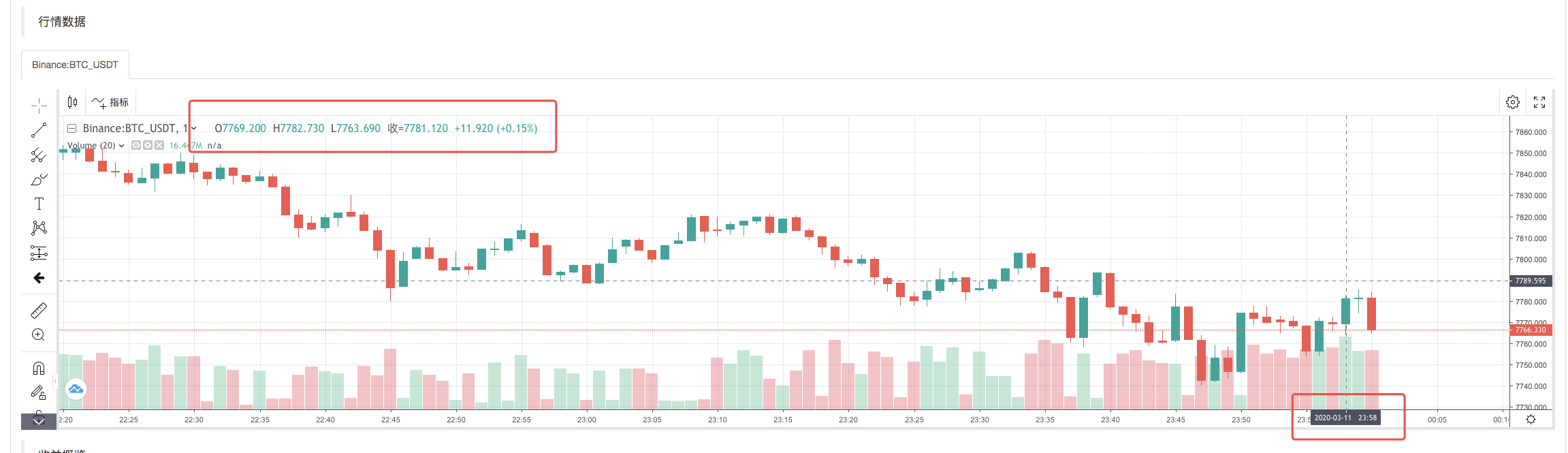
Los datos comparados en el archivo:

Los bloggers de la red social se han mostrado muy interesados en este tema.
- Introducción al arbitraje de lead-lag en criptomonedas (2)
- Introducción al conjunto de Lead-Lag en las monedas digitales (2)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: una solución completa para recibir señales con servicio HTTP incorporado en la estrategia
- Exploración de la recepción de señales externas de la plataforma FMZ: estrategias para una solución completa de recepción de señales de servicios HTTP integrados
- Introducción al arbitraje de lead-lag en criptomonedas (1)
- Introducción al conjunto de Lead-Lag en las monedas digitales (1)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: API extendida VS estrategia Servicio HTTP incorporado
- Exploración de la recepción de señales externas de la plataforma FMZ: API de expansión vs estrategia de servicio HTTP incorporado
- Discusión sobre el método de prueba de estrategias basado en el generador de tickers aleatorios
- Explorar métodos de prueba de estrategias basados en generadores de mercado aleatorios
- Nueva característica de FMZ Quant: Utilice la función _Serve para crear servicios HTTP fácilmente
- Herramienta de análisis mejorada basada en el desarrollo gramatical de Alpha101
- Enseñarle a actualizar el colector de mercado backtest la fuente de datos personalizados
- Defectos de los sistemas de resonancia de alta frecuencia basados en transacciones por letra y resonancia de línea K
- Explicación del mecanismo de ensayo posterior de nivel de simulación FMZ
- La mejor manera de instalar y actualizar FMZ docker en Linux VPS
- Estrategia R-Breaker de futuros de materias primas
- Un poco de reflexión sobre la lógica del comercio de futuros de monedas digitales
- Enseñarle a implementar un coleccionista de cotizaciones de mercado
- Versión de Python Estrategia de promedio móvil de futuros de materias primas
- Cotizaciones de mercado recolector actualizar de nuevo
- Commodity Futures High Frequency Trading Strategy escrito por C++
- Larry Connors RSI2 estrategia de reversión media
- El hombre de Oak te enseñará cómo usar la API para la extensión de FMZ con JS.
- Basado en el uso de un nuevo índice de fortaleza relativa en las estrategias intradiarias
- Investigación sobre Binance Futures estrategia de cobertura multi-moneda Parte 4
- Larry Connors Larry Connors RSI2 estrategia de retorno de la media
- Investigación sobre la estrategia de cobertura de divisas múltiples de Binance Futures Parte 3
- Investigación sobre Binance Futures estrategia de cobertura multi-moneda Parte 2
- Investigación sobre la estrategia de cobertura de divisas de futuros de Binance Parte 1
- La mano te enseña cómo actualizar la función de recolección de datos personalizada para la recopilación de datos
¿Qué es eso?¿Es necesario instalar Python en el servidor del administrador?
Esparta jugando a la cantidadAhora, esta fuente de datos personalizada se vuelve a evaluar en el navegador, y hay problemas de precisión de datos.
- ¿Qué es eso?/upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png ¿Cómo se debe llenar la dirección en el bot, el servidor de la dirección que he llenado el puerto de acceso 9090 y no hay respuesta en el recolector
el mismo¿Por qué tengo un servidor host configurado con un origen de datos CSV personalizado, con una solicitud de página que devuelve datos, y luego no devuelve datos en la revisión, cuando se configura directamente los datos como solo dos datos, el servidor HTTP puede recibir en la solicitud, /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d286587b3e.ng /upload/asset/169e8dcdbf9c0c544pbac8.png
el mismo¿Por qué tengo un servidor alojado que tiene una fuente de datos CSV personalizada, que devuelve datos con una solicitud de página y luego no devuelve datos en la retrospección, y no tiene una solicitud en el servidor de https://upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28d658795b3e.png /upload/asset/169e8ddbf9c0c544png
¿Qué es esto?¿Cómo se establecen los parámetros?
La homilíaEn el caso de las acciones, el precio de las monedas es el mismo que el precio de las monedas.
¿Qué quieres decir? 666
Los inventores cuantifican - sueños pequeños¿Cómo puedo hacer esto?
Esparta jugando a la cantidadFue un error del sistema de retrospección, que ha sido corregido.
Los inventores cuantifican - sueños pequeñosLa documentación de la API muestra las instrucciones de precisión, y puedes intentarlo.
Los inventores cuantifican - sueños pequeñosEl código de la página web es el mismo que el de los archivos CSV, que se utilizan como fuente de datos para proporcionar datos a los sistemas de retroevaluación.
Los inventores cuantifican - sueños pequeñosVer la descripción en la documentación de la API.
el mismoLos datos personalizados con el método de exchange.GetData (()) para la recuperación pueden hacer que las líneas K se conviertan en datos personalizados?
Los inventores cuantifican - sueños pequeñosEl servicio que ofrece el origen de datos personalizado debe estar en el servidor, debe ser IP pública; el sistema de retrospección local del servicio no puede acceder.
el mismoPor favor, ¿cómo se puede hacer un retorno local de datos en el servidor http local, es el retorno local no es compatible con el retorno de la fuente de datos personalizada?
Los inventores cuantifican - sueños pequeñosLa cantidad de datos es demasiado grande. La página web no se puede cargar, además de DEMO, en su investigación, debería estar bien, supongo que está mal configurado.
el mismoYo soy datos de csv de un minuto K línea de datos de otras monedas, y luego debido a que no se puede elegir el par de transacciones al momento de la retrospección, el robot y el intercambio seleccionado para retrospección se configuran como huobi, el par de transacciones es BTC-USDT, los datos de solicitud que a veces puedo recibir en el lado del robot, pero no puedo obtener datos en el lado de retrospección, y cambié la barra de tiempo de csv de segundos a milisegundos que tampoco pueden obtener datos.
Los inventores cuantifican - sueños pequeños¿Cuáles son los datos a los que te refieres específicamente? ¿Hay algún requisito para esta definición? ¿Puede verse tanto la parte del tiempo como los milisegundos?
Los inventores cuantifican - sueños pequeñosLa cantidad de datos es buena, lo probé cuando lo probé.
el mismoSe puede obtener una pequeña cantidad de datos, pero cuando especifico un archivo CSV con más de un minuto de datos durante un año, no se puede obtener. ¿Es demasiado grande?
el mismoLo que ahora configuro en mi robot es el intercambio HUOBI, y luego el par de transacciones también está configurado BTC-USDT, y así se configura cuando se retrasa, y luego se retrasa el código que se usa es una función exchange.GetRecords ((), ¿hay algún requisito para este tipo de datos definidos?
Los inventores cuantifican - sueños pequeñosEn el extremo del navegador puede ser porque usted especifica los parámetros de la consulta, el sistema de respuesta no puede activar El robot responde, indicando que el robot no aceptó la solicitud, explicando que el lugar se configuró mal cuando se respondió, y que se puede encontrar el problema al revisar y deshacerse.
Los inventores cuantifican - sueños pequeñosSi desea leer su propio archivo CSV, puede configurar el camino de este archivo según lo indicado en este artículo.