Réaménagement du collecteur de données - support des importations de fichiers au format CSV pour fournir des sources de données personnalisées
Auteur:L'inventeur de la quantification - un petit rêve, Créé: 2020-05-23 15:44:47, Mis à jour: 2024-12-10 20:19:56
L'appareil de collecte de données de revalorisation de l'appareil prend en charge l'importation de fichiers au format CSV pour fournir des sources de données personnalisées
Le dernier utilisateur a besoin de ses propres fichiers de format CSV comme source de données pour permettre aux inventeurs de quantifier le système de retouche de la plate-forme de trading.
Des idées de conception
L'idée de la conception est très simple, nous avons juste un petit changement sur la base de l'ancienne collecteur de marché, nous avons ajouté un paramètre à l'ancienne collecteur de marché.isOnlySupportCSVAjouter un paramètre pour contrôler si un fichier CSV est uniquement utilisé comme source de données pour le système de retouchefilePathForCSVLe processus de création d'un fichier CSV est basé sur le processus de création d'un fichier CSV.isOnlySupportCSVSi les paramètres sont définis commeTruePour décider de l'utilisation d'une source de données (des données collectées par vous-même, des données dans des fichiers CSV), ce changement est principalement lié à l'utilisation d'une autre source de données (des données collectées par vous-même, des données dans des fichiers CSV).ProviderLes classesdo_GETDans les fonctions.
Que sont les fichiers CSV?
Les valeurs séparées par virgules (CSV, parfois appelées valeurs séparées par virgules, car les virgules peuvent aussi ne pas être des virgules) sont des fichiers qui stockent des données de table sous forme de texte pur (numéros et texte). Le texte pur signifie que le fichier est une séquence de caractères qui ne contient pas de données qui doivent être déchiffrées comme des nombres binaires.
Il n'existe pas de norme générale pour le format de fichier CSV, mais il existe une règle générale pour un enregistrement en une seule ligne, le premier acte étant le début; les données dans chaque ligne sont séparées par des virgules.
Par exemple, le fichier CSV que nous avons utilisé pour le test s'ouvre comme ceci avec un journal: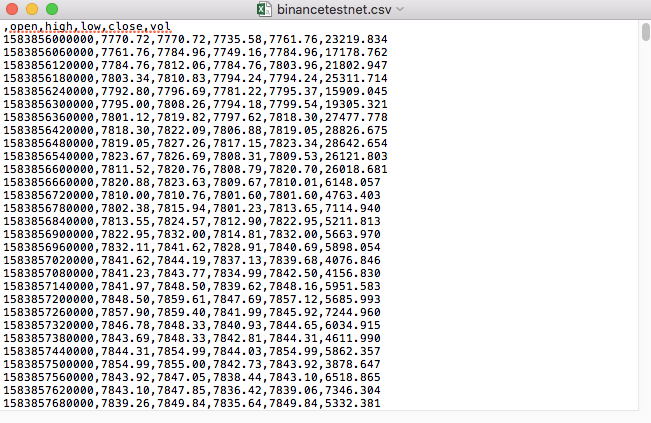
Notez que la première ligne d'un fichier CSV est le titre du formulaire.
,open,high,low,close,vol
Nous allons donc analyser ces données et les organiser en un format permettant au système de retouche de personnaliser les requêtes de source de données, ce que nous avons déjà traité dans le code de notre précédent article, avec quelques modifications.
Code modifié
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Les tests sont en cours
Tout d'abord, nous lançons le robot collecteur de marché, nous ajoutons une bourse au robot et le laissons fonctionner.
Configuration des paramètres:
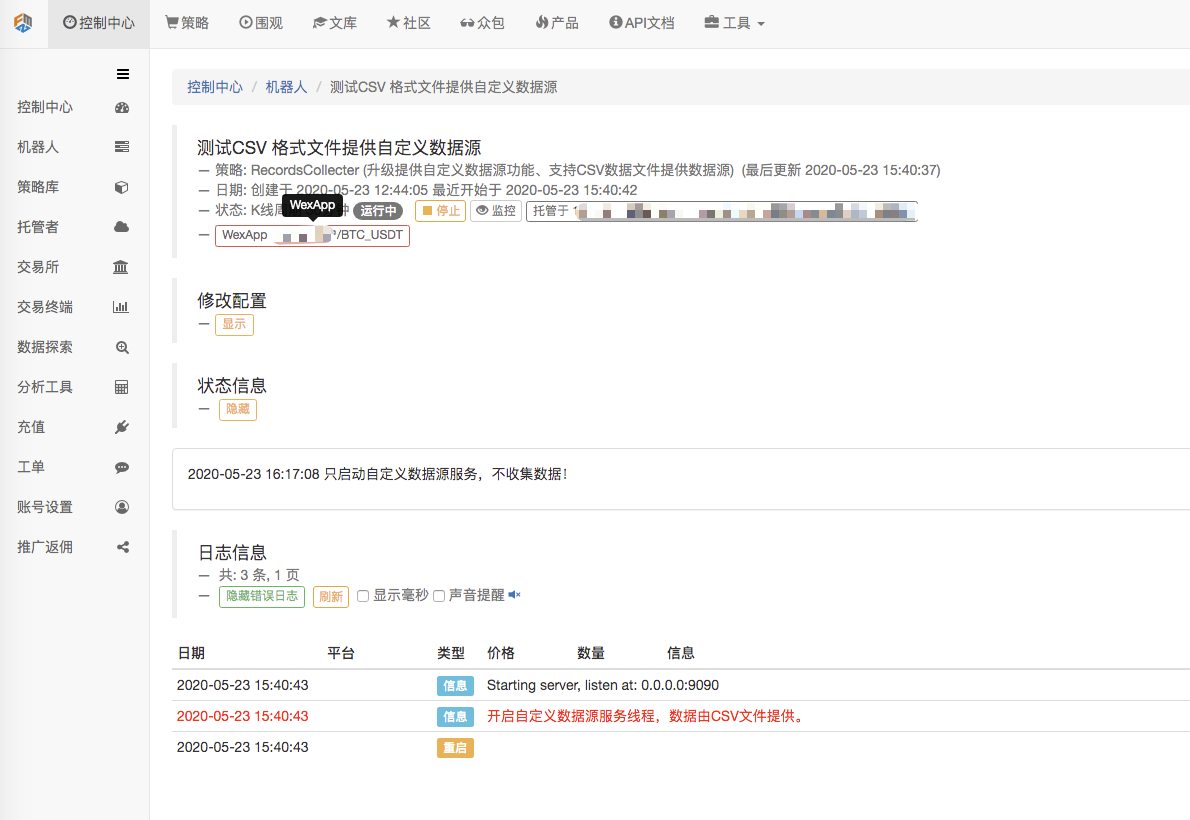
Nous avons ensuite créé une stratégie de test:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
La stratégie est simple: il suffit d'obtenir et d'imprimer trois lignes K de données.
La page de retouche, la source de données du système de retouche est configurée comme source de données personnalisée, et l'adresse remplit l'adresse du serveur géré par le robot de collecte de transactions. Puisque les données de notre fichier CSV sont des lignes K de 1 minute, nous avons configuré le cycle des lignes K de 1 minute lors du retouche.
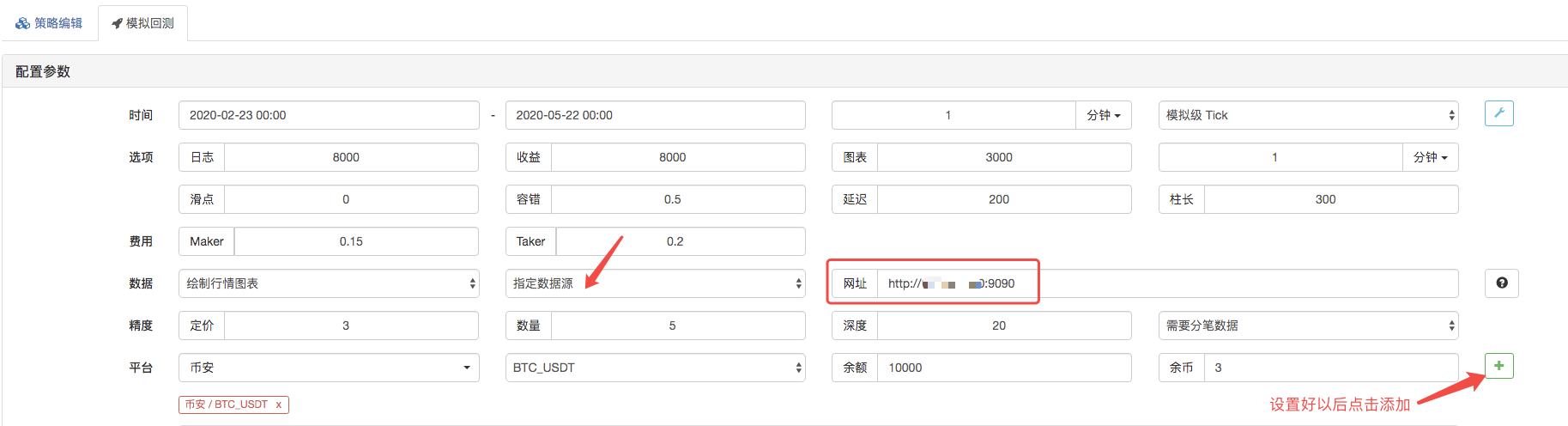
En cliquant sur le bouton, le robot collecteur de données reçoit une demande de données:
Une fois la stratégie d'exécution du système de retouche terminée, un diagramme de ligne K est généré en fonction des données de ligne K dans la source de données.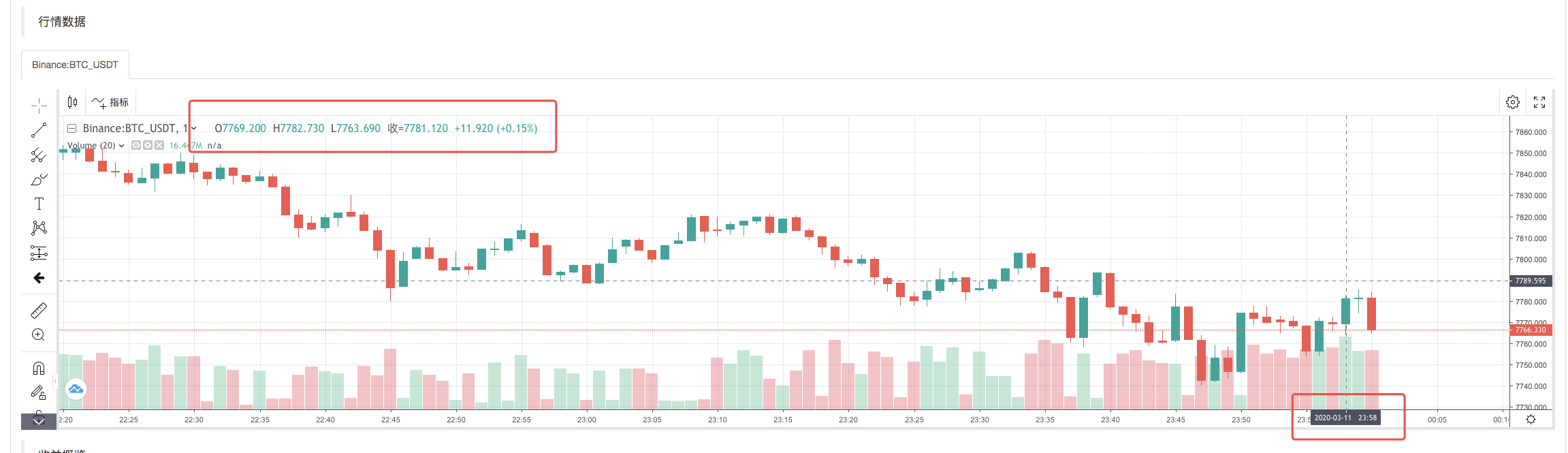
Comparer les données dans les fichiers:

Je vous invite à me rejoindre et à me donner votre avis.
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (2)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (2)
- Discussion sur la réception de signaux externes de la plateforme FMZ: une solution complète pour la réception de signaux avec un service Http intégré dans la stratégie
- Exploration de la réception de signaux externes sur la plateforme FMZ: stratégie intégrée pour la réception de signaux sur le service HTTP
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (1)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (1)
- Discussion sur la réception de signaux externes de la plateforme FMZ: API étendue VS stratégie intégrée au service HTTP
- Débat sur la réception de signaux externes sur la plateforme FMZ: API étendue contre stratégie de service HTTP intégré
- Discussion sur la méthode de test de stratégie basée sur le générateur de tickers aléatoires
- Une méthode de test stratégique basée sur un générateur de marché aléatoire
- Nouvelle fonctionnalité de FMZ Quant: Utilisez la fonction _Serve pour créer facilement des services HTTP
- Outil d'analyse amélioré basé sur le développement de la grammaire Alpha101
- Apprendre à mettre à niveau le collecteur de marché backtest la source de données personnalisée
- Les défauts du système de retouche haute fréquence basé sur les transactions à la lettre et de la retouche K-line
- Explication du mécanisme de backtest au niveau de simulation FMZ
- La meilleure façon d'installer et de mettre à niveau FMZ docker sur Linux VPS
- Stratégie R-Breaker des contrats à terme sur matières premières
- Un peu de réflexion sur la logique des échanges de devises numériques
- Vous apprendre à mettre en œuvre un collecteur de cotations de marché
- Stratégie de moyenne mobile des contrats à terme sur matières premières
- Le collecteur de cotations de marché est à nouveau mis à niveau.
- Stratégie de négociation à haute fréquence sur les contrats à terme sur matières premières écrite en C++
- Larry Connors RSI2 Stratégie d'inversion moyenne
- Les ouvriers vous apprennent à utiliser l'API de couplage JS pour étendre FMZ
- Basé sur l'utilisation d'un nouvel indice de résistance relative dans les stratégies intraday
- Recherche sur la stratégie de couverture multi-monnaie des contrats à terme de Binance Partie 4
- Larry Connors Larry Connors RSI2 stratégie de régression moyenne
- Recherche sur la stratégie de couverture multi-monnaie des contrats à terme de Binance Partie 3
- Recherche sur la stratégie de couverture multi-monnaie des contrats à terme de Binance Partie 2
- Recherche sur la stratégie de couverture multi-monnaie des contrats à terme de Binance Partie 1
- Le manuel vous apprend à mettre à niveau la fonctionnalité de récupération des sources de données personnalisées pour le collecteur de transactions
Je ne sais pas.Est-il nécessaire d'installer Python sur le serveur de l'administrateur?
Les Spartans jouent à la quantificationMon Dieu, maintenant, cette source de données personnalisée est à nouveau testée par le navigateur, et il y a un problème d'exactitude des données, vous pouvez essayer.
Il est à l'AIKPM.Le fichier de téléchargement de l'appareil est le suivant: /upload/asset/19cfcf5244f5e2cd73173.png J'ai mis le robot, comment est-ce qu'il doit remplir l'adresse, j'ai rempli l'adresse du serveur, le port 9090 et le collecteur ne répond pas.
le weixxS'il vous plaît expliquez-moi pourquoi j'ai configuré sur le serveur hébergé une source de données CSV personnalisée pour que les requêtes de page renvoient des données, puis aucune donnée ne soit renvoyée lors de la vérification de retour, lorsque les données sont directement réglées à deux données uniquement, le serveur http peut recevoir dans la requête /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d286587b3e.png /upload/asset/169e8dcdbf9c0c544pbac8.png
le weixxS'il vous plaît, expliquez-moi pourquoi j'ai mis en place sur le serveur hébergé une source de données CSV personnalisée, avec une demande de page avec un retour de données, puis aucun retour de données lors de la vérification de retour, et aucune requête au serveur HTTP /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28d658795b3e.png /upload/asset/169e8dcdbf9c0c544png
Je ne sais pas.Je vous demande comment les paramètres sont réglés.
l' homélieIl y a une grande différence entre les deux types de devises: les devises peuvent être évaluées comme des monnaies, et les actions peut-être aussi.
Je vous en prie. 666
L'inventeur de la quantification - un petit rêveIl faut avoir Python.
Les Spartans jouent à la quantificationC'est un bug de système de retouche, et il a été corrigé.
L'inventeur de la quantification - un petit rêvePour des informations sur la précision dans la documentation de l'API, vous pouvez essayer de lire ci-dessous.
L'inventeur de la quantification - un petit rêveIl faut comprendre les articles, le code. Il s'agit d'utiliser un fichier CSV comme source de données pour fournir des données au système de retouche.
L'inventeur de la quantification - un petit rêveVous pouvez consulter la description dans la documentation de l'API.
le weixxLes données personnalisées utilisent la méthode exchange.GetData (()) pour vérifier si les lignes K peuvent être transformées en données personnalisées.
L'inventeur de la quantification - un petit rêveLe service qui fournit une source de données personnalisée doit être placé sur un serveur, et doit être une adresse IP publique.
le weixxS'il vous plaît, comment faire pour créer des données de redirection locale sur le serveur http, est-ce que le redirection local ne prend pas en charge le redirection des sources de données personnalisées? J'ai ajouté des exchanges au redirection local: [{ "eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"}] Ce paramètre, ainsi que l'IP du robot, n'est pas non plus demandé au serveur.
L'inventeur de la quantification - un petit rêveIl y a trop de données. La page Web ne peut pas être chargée, en plus de la DEMO que vous avez étudiée, cela ne devrait pas être un problème, je suppose que vous avez mal configuré.
le weixxJe suis le csv data est une minute K ligne de données d'autres devises, puis comme les paires de transactions ne peuvent pas être sélectionnées au hasard lors de la réévaluation, le robot et l'échange sélectionné pour la réévaluation sont tous configurés pour huobi, la paire de transactions pour BTC-USDT, cette demande de données Je suis parfois le côté du robot peut recevoir des demandes, mais le côté de réévaluation ne peut pas obtenir des données, et je change le chronomètre du csv de seconde à millisecondes ne peut pas obtenir de données.
L'inventeur de la quantification - un petit rêvePour les transactions sur BTC_USDT, à quoi vous référez-vous? Est-ce que cette définition de données est requise? Par exemple, une partie du temps peut-elle être consultée en millisecondes et en secondes?
L'inventeur de la quantification - un petit rêveLes données volumineuses sont également acceptables, comme je l'ai testé lors de mes tests.
le weixxUne petite quantité de données peut être récupérée, mais si je spécifie un fichier CSV avec plus d'une minute de données par an et que je trouve que cela ne fonctionne pas, est-ce qu'il y a un impact sur la quantité de données?
le weixxJe configure actuellement sur mon robot l'échange HUOBI, puis la paire BTC-USDT, qui est également configurée pour le retrait, puis le code retrait est utilisé par une fonction exchange.GetRecords (), cette définition de données a-t-elle des exigences?
L'inventeur de la quantification - un petit rêveVous êtes peut-être à la fin du navigateur parce que vous avez spécifié des paramètres de requête, le système de réponse n'a pas pu déclencher le robot répond, indiquant que le robot n'a pas accepté la requête, expliquant que l'endroit n'était pas configuré correctement lors de la requête, et que vous pouvez trouver le problème en vérifiant et en débattant.
L'inventeur de la quantification - un petit rêveSi vous souhaitez lire votre propre fichier CSV, vous pouvez configurer le chemin pour ce fichier, comme indiqué dans cet article.