行事収集器再アップグレード - CSV形式のファイル輸入をサポートし,カスタマイズされたデータソースを提供します
作者: リン・ハーン発明者 量化 - 微かな夢作成日:2020年5月23日 15:44:47 更新日:2024年12月10日 20:19:56
行事収集器再アップグレード キット CSV 形式のファイル輸入をサポートし,カスタマイズされたデータソースを提供
最近のユーザーは,自社のCSV形式のファイルがデータ源として発明者の量化取引プラットフォームの回測システムを使用できるようにする必要があります. 発明者の量化取引プラットフォームの回測システムは,機能が豊富で,簡潔で効率的に使用され,自分のデータがある限り,再測を行うことができるので,プラットフォームのデータセンターがサポートする取引所や品種に限定されることはありません.
デザインのアイデア
デザインのアイデアは簡単です. 市場収集器にパラメータを追加するだけで, 市場収集器の基礎を少し変えることができます.isOnlySupportCSVCSV ファイルのみをデータ源として復習システムに提供するかどうかを制御するパラメータを追加します.filePathForCSV市場収集ロボットが実行するサーバーにCSVデータファイルを置くための経路を設定します.isOnlySupportCSV設定されているかTrueこの変更は主に,データ源 (自分の収集した1、2、CSVファイル内のデータ) の使用を決定するために行われています.Providerクラスdo_GETこの関数には,
CSVファイルとは何か?
コマ分離値 (Comma-Separated Values,CSV,文字隔離値とも呼ばれるが,文字隔離文字がコマではない場合もある) は,表のデータ (数字とテキスト) を純粋なテキスト形式で保存するファイルである.純粋なテキストは,ファイルが文字配列であることを意味し,二進法数字のように解読されなければならないデータを含まない.CSVファイルは任意の数目的の記録から構成され,記録の間隔は何らかの交替文字隔離で構成される.各記録はフィールドから構成され,段落の隔離文字は他の文字または文字列で,最も一般的なのはコマまたは表文字である.通常,すべての記録はまったく同じ段落配列を有する.通常は純粋なテキストファイルである.WORDPADを使用することをお勧めするか,または事象を再開するか,または別のファイルを新しいEXCELで開く方法の一つである.
CSV ファイル形式の一般的な基準は存在しないが,ある規則がある.一般的に,記録の1行,最初の行為の先頭.各行内のデータはコマ間隔で割り振られる.
例えば,私たちがテストしたCSVファイルが,メモリで開くと,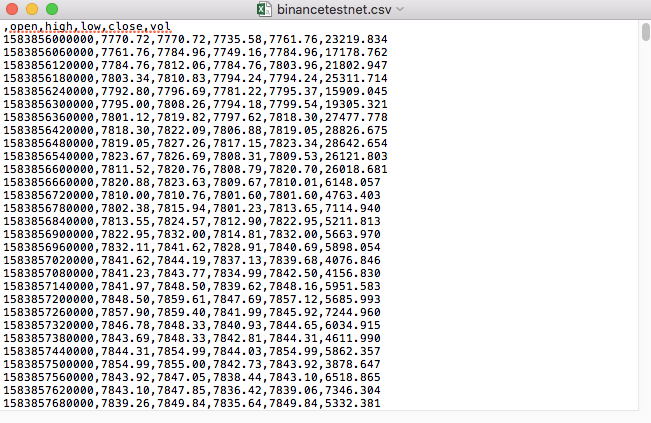
CSV ファイルの最初の行は表のヘッダーです.
,open,high,low,close,vol
このデータ解析を整理し,リサーチシステムにデータソースの設定要求を構成する形式を構成する. これは,前回の記事で扱ったコードで,ほんの少し修正しただけです.
変更されたコード
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
実行テスト
まず,市場収集ロボットを起動し,ロボットに取引所を追加し,ロボットが動かせます.
パラメータ設定:
テスト戦略を作りました.
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
簡単な戦略で,K線データを3回だけ取得してプリントします.
復習ページは,復習システムのデータソースをカスタムデータソースとして設定し,アドレス記入は,市場収集ボットが実行するサーバーのアドレスです. 私たちのCSVファイル内のデータは1分K行であるため,復習時に,K行周期を1分に設定します.
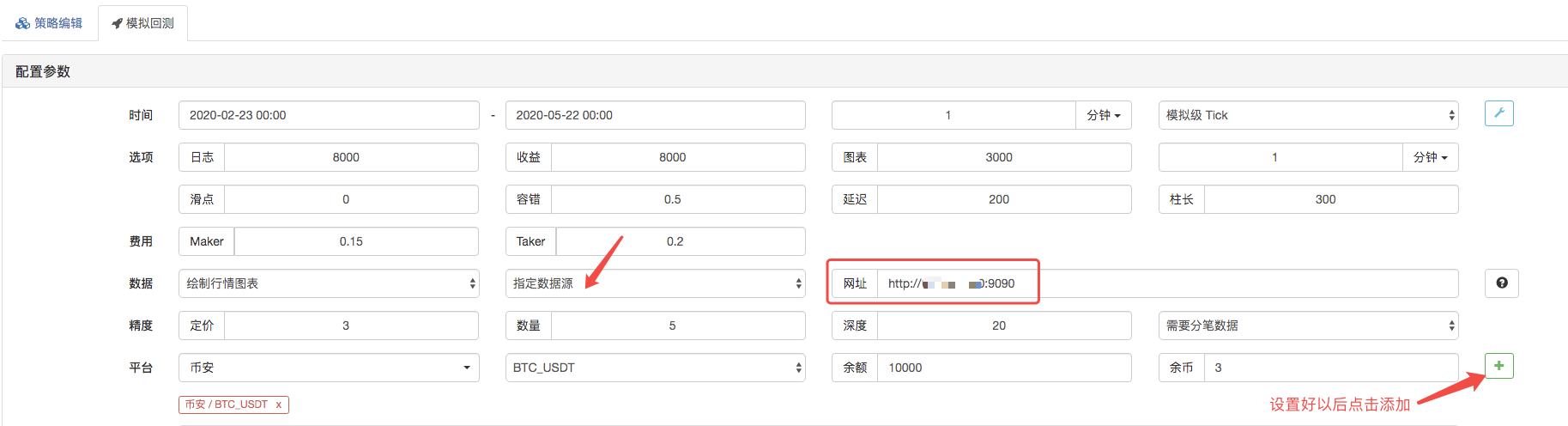
市場収集ロボットがデータ要求を受け,クリックして再テストを開始します.
復習システムが実行するポリシーが完了すると,データソースのK線データに基づいてK線グラフを生成します.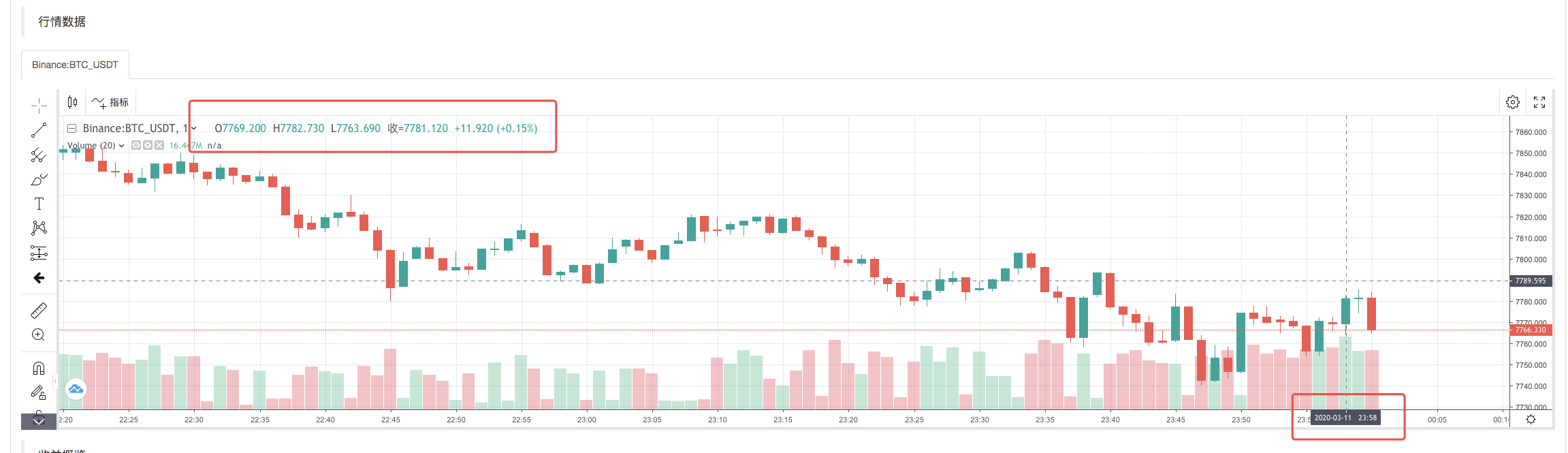
比較ファイルのデータ: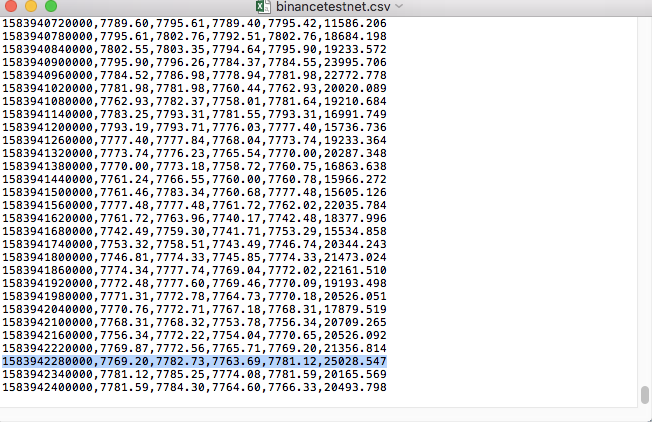

RecordsCollector (カスタマイズされたデータソースの機能,CSVデータファイルのデータソースのサポートのアップグレード)
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (2)
- デジタル通貨におけるリード-ラグ套路の紹介 (2)
- FMZプラットフォームの外部信号受信に関する議論: 戦略におけるHttpサービス内蔵の信号受信のための完全なソリューション
- FMZプラットフォームの外部信号受信に関する探求:戦略内蔵Httpサービス信号受信の完全な方案
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (1)
- デジタル通貨におけるリード-ラグ套路の紹介 (1)
- FMZプラットフォームの外部信号受信に関する議論:拡張API VS戦略内蔵HTTPサービス
- FMZプラットフォームの外部信号受信に関する探究:拡張API vs 戦略内蔵HTTPサービス
- ランダム・ティッカー・ジェネレーターに基づく戦略テスト方法に関する議論
- ランダム市場生成器に基づく戦略テスト方法について
- FMZ Quant の新しい機能: _Serve 機能を使用して HTTP サービスを簡単に作成する
- Alpha101 の文法開発に基づいた強化分析ツール
- カスタムデータソースをバックテストする
- 筆付取引に基づく高周波回音システムとK線回音の欠陥
- FMZシミュレーションレベルバックテストメカニズムの説明
- Linux VPS に FMZ ドッカー をインストールしてアップグレードする最良の方法
- コモディティ・フューチャーズR-ブレイカー戦略
- デジタル通貨の先物取引の論理について考える
- 市場 コート 収集器の実装を教えます
- Python バージョン コモディティ・フューチャーズ 移動平均戦略
- 市場 コート コレクター 再びアップグレード
- C++ で書かれた高周波取引戦略
- ラリー・コナーズ RSI2 平均逆転戦略
- JSでFMZ拡張APIを学ぶ
- 日中戦略における新しい相対強度指数の使用に基づいて
- ビナンス・フューチャーズ・マルチ通貨ヘッジ戦略に関する研究 第4部分
- ラリー・コナーズ ラリー・コナーズ RSI2 平均回帰戦略
- ビナンス・フューチャーズ・マルチ通貨・ヘッジ戦略に関する研究 第3部
- ビナンス・フューチャーズ・マルチ通貨・ヘッジ戦略に関する研究 第2部
- バイナンス・フューチャーズ・マルチ通貨・ヘッジ戦略に関する研究 第1部
- 手がかりは,行事収集器にリクエストをアップグレードするために,カスタマイズされたデータソースの機能を教えます
ブラッド・ミッチ管理者サーバーにpythonをインストールする必要があるか?
スパダは量化されているブラウザの端で復元され,データの精度が問題になります.
AiKPMは.../upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png /upload/acet/19c100ceb1eb25a38a970.png /upload/acet/19cd73173.png /upload/acet/19cd100ceb1cb1cb1cb1cb1cb ロボットが接続され, サーバーのアドレスを入力し, ポート番号9090を入力し, コレクターに反応しなかった.
ウェイックスなぜ,ホストサーバで設定したカスタムCSVデータソースで,ページリクエストでデータ返信があり,その後,リクエストでデータ返信がない場合,データを直接2つのデータに設定したときに,httpserver端末はリクエストに /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c6c4c3d286587b3e.ng /upload/asset/169e8dcdbf9c0c544pbac8.png /upload/asset/169e8dcdbf9c0c544png
ウェイックスなぜ私はホストサーバーでカスタムCSVデータソースを設定し,ページリクエストでデータの返信が表示され,再テストではデータ返信が表示されず,httpserver端末 /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28d658795b3e.png /upload/asset/169e8dcdbf9c0c544png /bac
QQ89520参数はどう設定されているのか?
説教高い水準で,どんなコインも測れるし,おそらく株式も測れるだろう.
言った 666
発明者 量化 - 微かな夢Python を使って,
スパダは量化されているシステムバグです 修正しました
発明者 量化 - 微かな夢APIのドキュメントで精度に関する説明は,こちらをご覧ください.
発明者 量化 - 微かな夢文章やコードを理解する必要がある. CSVファイルがデータ源として,復習システムにデータを提供する.
発明者 量化 - 微かな夢詳細については,APIドキュメントを参照してください.
ウェイックスカスタムデータは,exchange.GetData ((() の方法を使って,K行をカスタムデータに変換できるかを復元する.
発明者 量化 - 微かな夢この自定义データソースを提供するサービスはサーバー上に置かれ,公共のIPである必要があります. ローカルサービス回線システムはアクセスできません.
ウェイックスこのパラメータは,ロボットに変換されたIPもサーバーに要求されません. このパラメータは,ロボットに変換されたIPも,サーバーに要求されません.
発明者 量化 - 微かな夢ウェブページは負荷が大きすぎる.また,DEMOは,あなたの研究で,問題ではないはず,あなたが間違った設定を推測します.
ウェイックス私はcsvデータで,1分K線は他の通貨のデータで,その後,復習時に取引ペアをランダムに選択できないため,ロボットと復習選択した取引所は,すべてhuobiに設定され,取引ペアはBTC-USDTです.この要求データ 私は時々ロボット側から要求を受けることができますが,復習側ではデータを取得できません.また,私はcsvの時間軸を秒からミリ秒に変更しました.
発明者 量化 - 微かな夢取引はBTC_USDTで,あなたは具体的に何を指しているのですか? この定義のデータには要求がありますか? 例えば,時間の一部はミリ秒と秒の両方を閲覧することができますか?
発明者 量化 - 微かな夢データを大量に使うこともできます.
ウェイックス少ない量のデータを取得することは可能ですが,CSVファイルに1年以上のデータを指定したときに1分間のデータを取得できなくなってしまいます. データの量が大きすぎると影響がありますか?
ウェイックス私のロボットの設定はHUOBI取引所で,取引ペアもBTC-USDTで設定されています. 復習時に設定されています. 復習のコードは,exchange.GetRecords))) 関数を使用しています. この定義のデータには要求がありますか? 例えば,時間の一部はミリ秒と秒の両方を閲覧することができますか?
発明者 量化 - 微かな夢ブラウザ端では,あなたが指定したクエリパラメータが入力されているため,応答システムは起動できず,ロボットが応答し,要求が受け入れられていないことを説明し,応答時にその場所が間違って設定されていることを説明し,チェック,デュックで問題を発見することができます.
発明者 量化 - 微かな夢この例では,自分のCSVファイルを読む場合は,このファイルへの経路を設定できます.