趣味 朴素なベイエスを理解
作者: リン・ハーン発明者 量化 - 微かな夢作成日:2016年12月28日 10時30分22秒 更新日:2016年12月28日 10:34時52分趣味 朴素なベイエスを理解
ナビベイズ
ニュース分類や患者分類などの実用的な使用シナリオなど,人生の多くの場面で分類が必要である.この記事では,実用的な応用から始め,簡単な一般的な分類アルゴリズム - Navie Bayes classifier を紹介します.
-
01 患者の分類の例
この例から始めましょう. バイエスの分類器はよく理解できていて,全く難しくありません. ある病院は朝に6人の診療室の患者を診察しました.
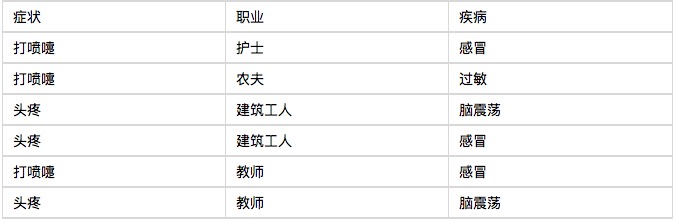
七番目の患者は,スズメをしている建築作業員です. 風邪をひいている可能性はどれくらいですか?
P(A|B) = P(B|A) P(A) / P(B)メディアは,
P(感冒|打喷嚏x建筑工人)
= P (
假定"打喷嚏"和"建筑工人"这两个特征是独立的,因此,上面的等式就变成了
P (風邪をひいて建築工に噴霧)
= P (吐き気で風邪をひいている) x P (建築工の風邪をひいている) x P (風邪をひいている)
/P (
这是可以计算的。
P (風邪をひいて建築工に噴霧) この式は,この式を 0.66 × 0.33 × 0.5 / 0.5 × 0.33 とします. これは 0.66 です.
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
- 02 朴素贝叶斯分类器的公式
假设某个体有n项特征(Feature),分别为F1、F2、...、Fn。现有m个类别(Category),分别为C1、C2、...、Cm。贝叶斯分类器就是计算出概率最大的那个分类,也就是求下面这个算式的最大值:
P (C) はF1F2...Fn) = P (F1F2...Fn) についてC (P© / P (F1F2...Fn)
由于 P(F1F2...Fn) 对于所有的类别都是相同的,可以省略,问题就变成了求
P ((F1F2...Fn について) P
的最大值。
朴素贝叶斯分类器则是更进一步,假设所有特征都彼此独立,因此
F1F2...F1F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2F2
=P (F1)
上式等号右边的每一项,都可以从统计资料中得到,由此就可以计算出每个类别对应的概率,从而找出最大概率的那个类。
虽然"所有特征彼此独立"这个假设,在现实中不太可能成立,但是它可以大大简化计算,而且有研究表明对分类结果的准确性影响不大。
#### 下面再通过两个例子,来看如何使用朴素贝叶斯分类器。
- 03 账号分类
根据某社区网站的抽样统计,该站10000个账号中有89%为真实账号(设为C0),11%为虚假账号(设为C1)。接下来,就要用统计资料判断一个账号的真实性。
C0 = 0.89
C1 = 0.11
假定某一个账号有以下三个特征
F1: 日志数量/注册天数
F2: 好友数量/注册天数
F3: 是否使用真实头像(真实头像为1,非真实头像为0)
F1 = 0.1
F2 = 0.2
F3 = 0
请问该账号是真实账号还是虚假账号?方法是使用朴素贝叶斯分类器,计算下面这个计算式的值。
P(F1|C)P(F2|C)P(F3|C)P(C)
虽然上面这些值可以从统计资料得到,但是这里有一个问题:F1和F2是连续变量,不适宜按照某个特定值计算概率。一个技巧是将连续值变为离散值,计算区间的概率。比如将F1分解成[0, 0.05]、(0.05, 0.2)、[0.2, +∞]三个区间,然后计算每个区间的概率。在我们这个例子中,F1等于0.1,落在第二个区间,所以计算的时候,就使用第二个区间的发生概率。
根据统计资料,可得:
P(F1|C0) = 0.5, P(F1|C1) = 0.1
P(F2|C0) = 0.7, P(F2|C1) = 0.2
P(F3|C0) = 0.2, P(F3|C1) = 0.9
因此
P(F1|C0) P(F2|C0) P(F3|C0) P(C0)
= 0.5 x 0.7 x 0.2 x 0.89
= 0.0623
P(F1|C1) P(F2|C1) P(F3|C1) P(C1)
= 0.1 x 0.2 x 0.9 x 0.11
= 0.00198
可以看到,虽然这个用户没有使用真实头像,但是他是真实账号的概率,比虚假账号高出30多倍,因此判断这个账号为真。
- 04 性别分类
下面是一组人类身体特征的统计资料。
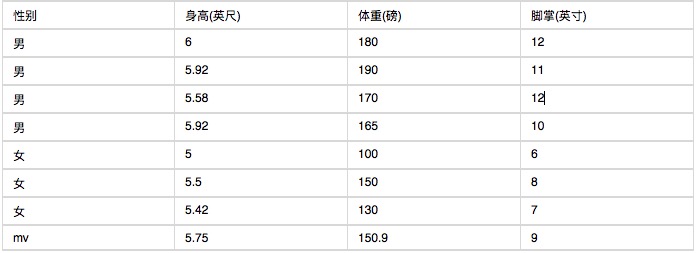
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?根据朴素贝叶斯分类器,计算下面这个式子的值。
P(身高|性别) x P(体重|性别) x P(脚掌|性别) x P(性别)
这里的困难在于,由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办?这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值。比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的值,只用来反映各个值的相对可能性)。
有了这些数据以后,就可以计算性别的分类了。
P(身高=6|男) x P(体重=130|男) x P(脚掌=8|男) x P(男)
= 6.1984 x e-9
P(身高=6|女) x P(体重=130|女) x P(脚掌=8|女) x P(女)
= 5.3778 x e-4
可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
#### 转载自 阮一峰 的微信公众号- テンプレート3.2:デジタル通貨取引のクラスタデータベース (統合 現金,フューチャーサポート OKCoinフューチャー/BitVC)
- リスクの小物語 (6) 申し訳ありませんが,ゴースは小さな仕事をしました.
- 危険小説 (4) ワームモーバーと神の曲線
- リスクの短編 (第5回) バイエス,教材だけで生きる男
- ストップダウンの代替案の素晴らしい説明
- OkCoin中国站APIの誤ったコード検索
- 2.12 _D ((()) 関数と時間軸
- Python: この場所には注意してください.
- 統合された直感認識
- マルコフ模型
- 2.11 API: Chart 関数の使い方 (図図関数) の簡単な例
- 詳細な通貨対
- 線形思考の罠に
- 読み書きのやり方によって,多くの富が生まれると聞きました.
- ギャンブルと投資で逃亡した
と生き延びた の物語 - 30行のコードがあなたを量的な投資の世界に連れて行く (Python版)
- ギャンブルは,高級なビジネスの一種です
- 価格と量関係は重要な指標です!
- プラットフォームに"Do"の復旧機能を追加するよう強く要求
- 金融の3つの表について,予想外で面白く読むにはどうすればいいですか?