ビッグデータファンドの暴露
作者: リン・ハーン発明者 量化 - 微かな夢, 作成日: 2017-02-27 13:01:49, 更新日: 2017-02-27 23:43:03ビッグデータファンドの暴露
本日の科学投資記事では,ビッグデータファンドの仕組みや,淘宝,百度,シナワンのインターネットデータがファンドマネジャーの株価選択に役立つ方法について説明します.
- #### 大データファンドを公開する前に,典型的な株式型ファンドの選択手順を見てみましょう.
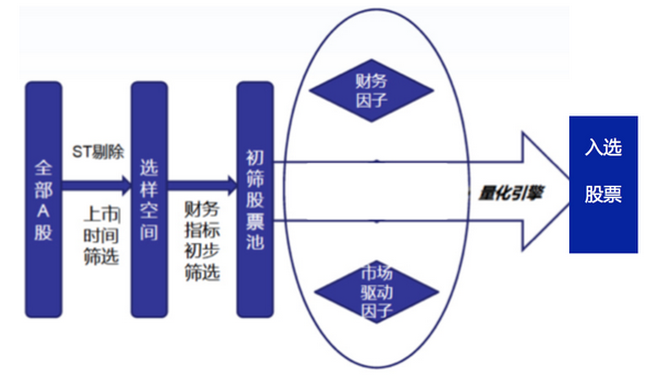
すべてのA株から初期抽選スペースを抽出し,初期抽選基準は一般的に上場時間,市場価値などの基本的な指標を使用する. サンプリングスペースから初回株池を選択し,通常,業界データ,財務指標,収益性などのシフト条件が適用される.初回株池は多因子株選定モデルのサンプルとなる. 多因子株価モデルを用いて株価を定量化する.従来の多因子モデルでは,金融要因 (株価率,株価率,株価率,株価比率,株価比率,主体事業収入成長率,株価成長率,EPS成長率,総資産成長率など) と市場駆動要因 (株価短期回報率,長期回報率,特定の波動率,取引流通の変化,自由市場価値など) が主に採用される.上記のすべての要因の長期的歴史的回報と安定性による進行的加重計算により,株価の総合スコアが得られる. 量化エンジンによる学習により,基金の構成株と相応の重さを計算する.
では,ビッグデータファンドと従来のファンドの違いは何でしょうか?
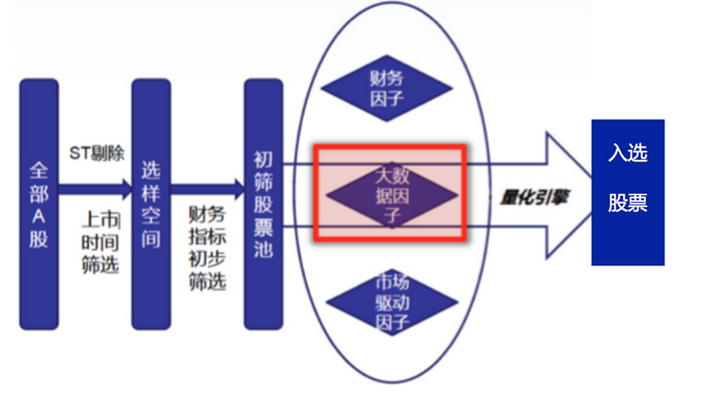
以前は,多因子株の選択モデルを確立したとき,採用する要因は全て市場内部からのもので,我々は株そのものの属性だけに焦点を当てていたが,ビッグデータ要因の導入は,新しい情報をもたらした.我々は百度検索量の変化が株の変化と関連性があるかどうか,我々は淘宝の特定の業界の販売が業界内の企業の株価格に影響するか,我々はまた新浪金融部門の特定の株式ニュースに関連する読者数のコメントが株価の変動に影響するか,我々は注目する.
リアルなビッグデータファンドの例を挙げると,ビッグデータについて理解が深まるでしょう.
この例は,博時基金と
サンプリングスペースを構成する際,淘金ビッグデータ100は,以下のカテゴリーを含む,オンライン電子商取引商品カテゴリに関連する中銀三級産業の関連株をサンプリングスペースとして選択した.
家庭用耐用品
休憩用品
繊維と衣類
ホテル・レストラン・レジャー
食品と主要品の小売業
食品・飲料
家庭用品
個人用品
-
これらの業界と淘宝自社の商品分類は,淘宝のデータ生成のビッグデータ因子により,これらの業界でより多くの情報を提供できるので,非常に似ていることがわかります.
淘宝関連業界のサンプルスペースに基づいて,博時基金と金服は,多因子量化モデルに使用される
最後に,量化選用株モデルは,ビッグデータ要因,金融要因,市場駆動要因を活用して,ビッグデータファンドの構成株と重さを決定する株の分割ランキングを行う.
淘金100指数に加えて,各ビッグデータファンドは,百度,スノーボール,シナワ,銀銀など多くのビッグデータソースを利用し,中証指数株式会社を通じて公開された資料を通じて,各ビッグデータファンドが利用する要因は以下のとおりである.
百貨百貨100指数
サンプルスペースの株に対して,最近の一ヶ月間の検索総量と検索増量分別計算し,それぞれ総量因数と増量因数として記録する.検索総量因数と増量因数について,因数分析モデルを構築し,各期間の株の総合スコアを計算し,検索因数として記録する.
雪球の熱因子100トン
まず,第2ステップで得られたスノーボール智選組合せに基づいて,選定対象のサンプルの智選組合せカバーを計算し,次に,各株の智選組合せカバーに基づいて,株に相応な評価を与え,各株のスノーボール熱因子スコアとして記録する.
南シナバのビッグデータ
新浪経済チャンネルの下のページクリック量,微博の否定的な記事報道,報道の影響.
銀のビッグデータ指数 銀の業界におけるビッグデータ要因
銀の消費カテゴリ統計型傾向特性のデータに基づいて,産業投資研究指標が処理され,次に,所得された産業投資研究指標に基づいて,包括的な調査産業の景気度,包括:消費金額,取引回数など,産業経済度ランキングが与えられ,最後に,景気度に応じて,業界内の株式に相応の評価を与えられ,業界ビッグデータファクタースコアが与えられます.
多くの知人が,ビッグデータファンドのパフォーマンスが実際は不気味だと考えている.実際,これまでいくつかのビッグデータファンドのパフォーマンスも当初予想通りにはなっていないが,これはビッグデータファンドが間違った方向に進んでいるという結論に達させるわけではない.現在,ビッグデータへの応用は保守的で実験的であり,従来の多因子モデルに基づいたビッグデータファンドを追加しただけで,モデル自体においてさらなる破壊的な革新を施していない.しかし,ビッグデータファンドの処理は,文法分析,感情分析,話題モデルなどの自然言語処理や機械学習の分野を含む.
実際,ビッグデータの応用は,私たちの生活のあらゆる側面に触れてきました. 投資価値の宝物が無意識に蓄積されています. 既存のビッグデータファンドの業績は,これらの価値を効果的に掘り出す能力を示していないが,ビッグデータの宝物は,そこにあり,おそらく,知られていない高者によって利用されています.
科学への投資 検証された投資
- 確率,負荷,長期取引のポジティブな期待値
- 未来の関数についての疑問は,神様に教えてもらいたい!
- 通貨銀行システムにおける資金と信用
- ギャンブルの取引戦略
- HttpQuery は Python で使えません
- 放棄された
の機会の均衡は,何を意味するのか? - 勝利率と損失率について
- 投資の最大のウソはおそらくこれだ!
- ランダムな世界での生き残り
- トレンドを見つけ トレンドに従う
- なぜ小売投資家は急落するのでしょうか?
- 勝てばコインを投げても取引で儲かるのか?
- 機械学習アルゴリズムの旅
- 確率を予測するとき,私たちは何を予測しているのでしょうか?
- プログラム化取引流程図 (プログラムへのアイデア)
- _C() 試行錯誤関数
- _N() 関数 小数点位 精度制御
- 適性的な平均線での初期学習
- リアルでフォーマルな取引システム
- 3つの物語:不動産,株式市場,通貨を理解する