우리가 확률을 예측할 때, 우리는 무엇을 예측하고 있을까요?
저자:발명가들의 수량화 - 작은 꿈, 창작: 2017-02-25 00:22:28, 업데이트:우리가 확률을 예측할 때, 우리는 무엇을 예측하고 있을까요?
제가 오래 전에 인터뷰를 한 적이 있는데, 그 인터뷰의 주제에 대해 기억이 나네요. 그 당시의 인터뷰 과정은 크게 다음과 같습니다.
인터뷰어: 로지스틱이 돌아왔다는 것을 알고 계셨나요? 저는: 물론, 자주 사용되죠. 인터뷰어: 그렇다면 로지스틱의 회귀 예측의 확률을 어떻게 설명해야 할까요? 나는: 물론 그렇지 않습니다. 단 한 번의 관찰만 있으면 개인 확률은 추정할 수 없습니다. 같은 특징을 가진 N 개 개 개에게 주어진 성공률은 추정된 확률과 같다고 설명해야합니다.
아, 그 당시 면접관들은 저를 거절했고, 물론 마지막 면접에서는 제가 면접을 받았다는 결과를 얻었습니다. (아마도 통계학, 컴퓨터의 배경이 아닌 경제학 때문일 수 있습니다.)
제가 말씀드렸던 것은 약간 모순적이거나 이해하기 어렵다고 생각하실 수도 있습니다.
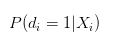
이 모든 것은 개인 성공 확률로 설명되어야 할 것이 아니겠습니까?
- ##########################################
우리가 단 한 사람의 성공 확률이라고 말할 때, 동일한 사람이 동일한 조건에서 100번 반복하여 평균적으로 몇 번 성공했는지에 대한 확률이어야 합니다. 만약 t가 한 사람이 시도한 수를 기억한다면, 우리의 이상적인 모델 (데이터 생성 과정) 은 다음과 같습니다.
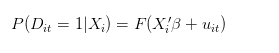
그러나 대안적으로, 실제 데이터 생성 과정은 다음과 같습니다.
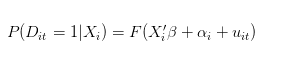

더 많은 내용
- HttpQuery는 파이썬에서 사용할 수 없습니다.
- 이 모든 것은 우리가 할 수 있는 일이 아닙니다.
- 승패율에 대한 이야기
- 이 모든 것은 투자에 대한 가장 큰 거짓말일지도 모릅니다.
- 무작위성이 넘치는 세상에서 살아남는 방법
- 트렌드를 발견하고 트렌드를 따라가세요.
- 빅데이터 펀드 공개
- 왜 소매 투자자들은 불투명 (Contrarian) 이냐?
- 이 모든 것은 우리가 이겨내기 위해 해야 할 일입니다.
- 기계 학습 알고리즘의 여행
- 프로그램화 거래 프로세스 맵 (예: 프로그램에서 아이디어)
- _C() 재시험 함수
- _N() 함수 소수점 소수점 정밀 제어
- 자율적인 초보 학습
- 실제적이고 형식적인 거래 시스템
- 부동산, 주식, 통화에 대한 세 가지 이야기
- 퀀트의 6개 지점을 공개합니다
- 동적 시간 정리에 기반한 형상 인식 전략
- 모형 거래소에 대한 생각
- 8개의 유명한 암호화폐 헤지핑 EA의 전략 평가
안녕하세요886lgistic 자체는 확률과 관련이 없습니다. 단지 거리를 0 - 1로 매핑하기 위해서입니다.
젠장흥미롭습니다.
발명가들의 수량화 - 작은 꿈이 부분의 본문은 "이번 포럼에 대해 토론하는 것은 매력적이어야 합니다".