Reaproveitamento do coletor de transações - suporte à importação de arquivos no formato CSV para fornecer fontes de dados personalizadas
Autora:Inventor quantificado - sonho pequeno, Criado: 2020-05-23 15:44:47, Atualizado: 2024-12-10 20:19:56
Repositório de transações de requalificação do plugin para importar arquivos no formato CSV para fornecer fontes de dados personalizadas
O usuário mais recente precisa ter seu próprio arquivo em formato CSV como fonte de dados, para que os inventores possam usar o sistema de retrospecção da plataforma de negociação quantitativa.
Ideias de Design
A ideia do projeto é muito simples, só precisamos de fazer uma pequena modificação na base do coletor de mercado anterior e adicionar um parâmetro ao coletor de mercado.isOnlySupportCSVPara controlar se apenas os arquivos CSV são usados como fonte de dados para o sistema de retrospecção, adicionar um parâmetrofilePathForCSV, para configurar o caminho para colocar o arquivo de dados CSV em um servidor operado por um robô coletor de transações.isOnlySupportCSVSe os parâmetros estão definidos comoTrueA mudança foi feita principalmente para que os usuários possam usar a fonte de dados (data coletada por eles mesmos, dados em arquivos CSV) e para que os usuários possam usar a fonte de dados (data coletada por eles mesmos, dados em arquivos CSV).ProviderClassedo_GETNa função.
O que é um CSV?
Comma-Separated Values (CSV, às vezes também chamado de valores separados por vírgulas, pois os caracteres separados também podem não ser vírgulas) são documentos que armazenam dados de tabelas em formato de texto puro (números e texto). O texto puro significa que o documento é uma sequência de caracteres, não contendo dados que precisam ser interpretados como números binários. O CSV é composto por registros de propósito arbitrário, com intervalos de uma espécie de barras de segmentação; cada registro é composto por campos, os intervalos de segmentação são outros caracteres ou strings, o mais comum é um vírgulo.
Não existe um padrão geral para o formato de arquivo CSV, mas há uma regra, geralmente para uma linha de registro, com o primeiro ato de cabeçalho; os dados em cada linha são espaçados por vírgulas.
Por exemplo, o arquivo CSV que usamos para testar se abre com um diário é assim: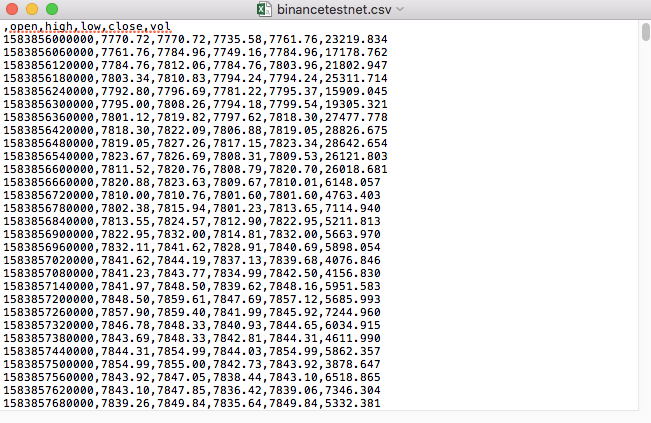
Observe que a primeira linha do CSV é o cabeçalho do formulário.
,open,high,low,close,vol
O que queremos fazer é analisar esses dados e construí-los em um formato que permita que o sistema de pesquisa personalize os requisitos de fontes de dados, que já foram tratados no código de um artigo anterior, com apenas algumas modificações.
Código modificado
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Testes de execução
Primeiro, nós iniciamos o robô coletor de mercado, nós adicionamos uma troca ao robô e o robô está funcionando.
Configuração de parâmetros:
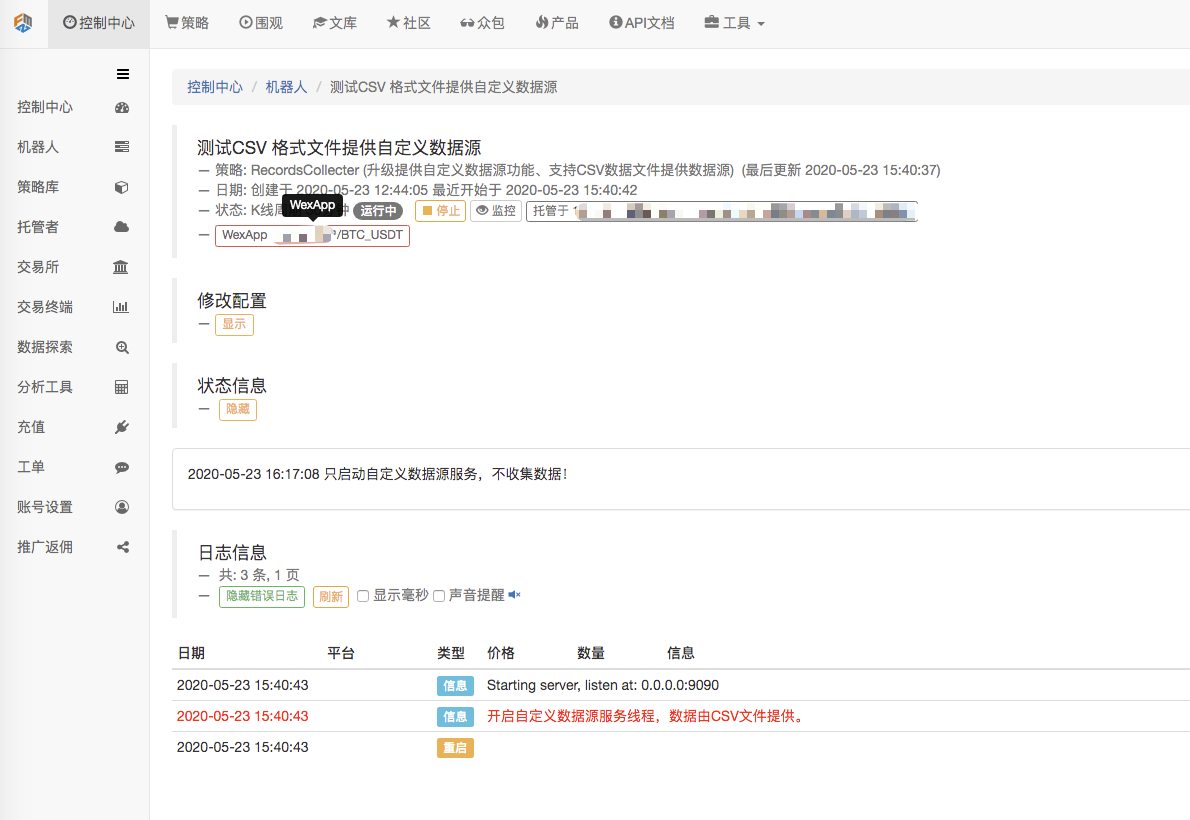
E então criamos uma estratégia de teste:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
A estratégia é simples: basta obter e imprimir três linhas K de dados.
A página de retorno, a fonte de dados do sistema de retorno é configurada como fonte de dados personalizada, e o endereço preenche o endereço do servidor executado pelo robô do coletor de transações. Como os dados em nossos arquivos CSV são linhas K de 1 minuto.
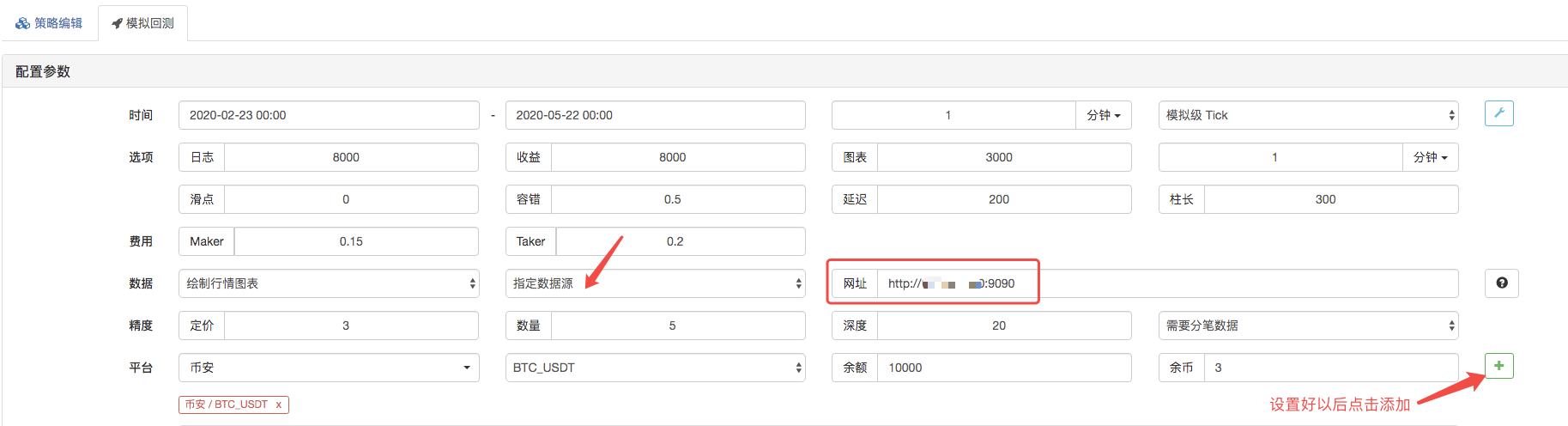
O bot de coleta de dados recebe um pedido de dados quando você clica no bot de coleta de dados:
Quando a política de execução do sistema de retrospecção é concluída, um gráfico de linhas K é gerado com base nos dados de linhas K da fonte de dados.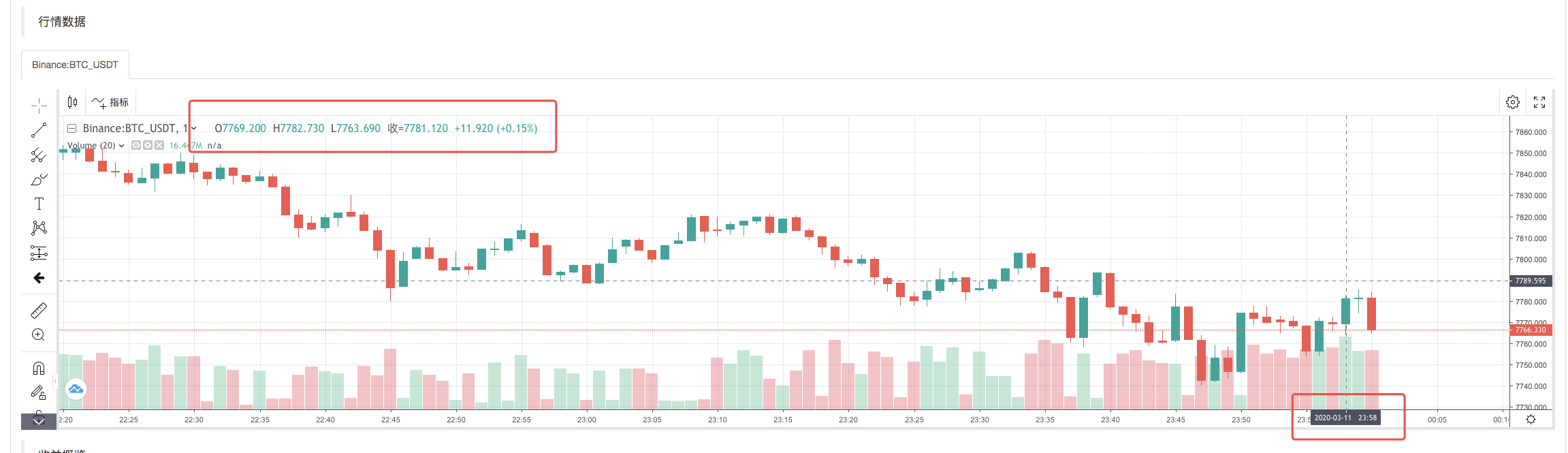
Comparar dados em documentos:

A partir de agora, o blogueiro também pode se inscrever no site do projeto.
- Introdução à arbitragem de lead-lag em criptomoedas (2)
- Introdução ao suporte de Lead-Lag na moeda digital (2)
- Discussão sobre a recepção de sinais externos da plataforma FMZ: uma solução completa para receber sinais com serviço HTTP em estratégia
- Discussão da recepção de sinais externos da plataforma FMZ: estratégias para o sistema completo de recepção de sinais do serviço HTTP embutido
- Introdução à arbitragem de lead-lag em criptomoedas (1)
- Introdução ao suporte de Lead-Lag na moeda digital
- Discussão sobre a recepção de sinais externos da plataforma FMZ: API estendida VS estratégia Serviço HTTP integrado
- Exploração da recepção de sinais externos da plataforma FMZ: API de extensão vs estratégia de serviços HTTP embutidos
- Discussão sobre o método de teste de estratégia baseado no gerador de tickers aleatórios
- Métodos de teste de estratégias baseados em geradores de mercado aleatórios
- Novo recurso do FMZ Quant: Use a função _Serve para criar serviços HTTP facilmente
- Ferramenta de análise avançada baseada no desenvolvimento da gramática Alpha101
- Ensinar-lhe a atualizar o coletor de mercado backtest a fonte de dados personalizados
- Deficiência do sistema de retorno de alta frequência baseado em transações por papel e retorno de linha K
- Explicação do mecanismo de backtest do nível de simulação FMZ
- A melhor maneira de instalar e atualizar FMZ docker no Linux VPS
- Estratégia R-Breaker de Futuros de Commodities
- Uma reflexão sobre a lógica de negociação de futuros em moeda digital
- Ensinar-lhe a implementar um coletor de cotações de mercado
- Versão Python Commodity Futures Moving Average Estratégia
- Cotações de mercado coletor atualizar novamente
- Commodity Futures High Frequency Trading Strategy escrito em C++
- Larry Connors RSI2 Estratégia de Reversão Mean
- A mão de Oak ensinou-lhe a usar o JS para pautar a API de extensão FMZ
- Baseado na utilização de um novo índice de força relativa nas estratégias intradiárias
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 4
- Larry Connors Larry Connors RSI2 estratégia de retorno da média
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 3
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 2
- Pesquisa sobre Binance Futures Multi-currency Hedging Strategy Parte 1
- Manual para ensinar você a atualizar o catador de transações para a recuperação de recursos de fontes de dados personalizadas
O meu irmão.O servidor do administrador precisa instalar o Python?
Esparda joga quantidadeAgora, essa fonte de dados personalizada é testada no navegador e há um problema de precisão de dados.
AiKPM.../upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png Eu coloquei o bot, como é que o endereço deve ser preenchido, eu preenchi o endereço do servidor, o portão 9090 e o coletor não respondeu.
WeixxPor favor, pergunte-me por que eu configurei um recurso de dados CSV personalizado no servidor hospedado para retornar dados com pedidos de páginas e não retornar dados no retorno, quando os dados são diretamente configurados para apenas dois dados, o servidor http pode receber pedidos em /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d286587b3e.ng /upload/asset/169e8dcdbf9c0c544pbac8.png
WeixxPor favor, pergunte-me por que eu configurei um recurso de dados CSV personalizado no servidor hospedado para retornar dados com pedidos de página e não retornar dados no retorno e não fazer pedidos para o servidor do servidor https://upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28d658795b3e.png /upload/asset/169e8ddbf9c0c544png
QQ89520Como é que os parâmetros são definidos?
homilhaA partir daí, a moeda pode ser avaliada em qualquer moeda, e talvez também em ações.
Dsaidasi 666
Inventor quantificado - sonho pequenoO Python é necessário.
Esparda joga quantidadeFoi um bug do sistema de retest, e foi corrigido.
Inventor quantificado - sonho pequenoA descrição da precisão na documentação da API pode ser vista abaixo e experimentada.
Inventor quantificado - sonho pequenoÉ necessário entender o artigo, o código. Aqui é sobre o uso de um arquivo CSV como fonte de dados para fornecer dados ao sistema de rastreamento.
Inventor quantificado - sonho pequenoVeja a descrição na documentação da API.
WeixxOs dados personalizados são usados no modo exchange.GetData (), para fazer a retrospecção e transformar as linhas K em dados personalizados.
Inventor quantificado - sonho pequenoO serviço que fornece fontes de dados personalizadas deve estar no servidor e deve ser um IP público. O sistema de retrospecção local do serviço não pode ser acessado.
WeixxPor favor, pergunte como fazer um retorno local de dados em um servidor http local, o retorno local não suporta retorno de fontes de dados personalizadas? Eu adicionei exchanges no retorno local: [{ "eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"} Este parâmetro, assim como o IP do robô, também não é solicitado ao servidor.
Inventor quantificado - sonho pequenoO volume de dados é muito grande. A página web não pode carregar, além disso, o DEMO que você pesquisou, deve ser bom, acho que você configurou errado.
WeixxEu sou os dados do csv é um minuto K linha são dados de outras moedas, e então, como no momento da retrospecção, o par de negociação não pode ser escolhido aleatoriamente, o robô e o exchange da retrospecção selecionada são configurados para o huobi, o par de negociação para o BTC-USDT, o pedido de dados que eu às vezes no lado do robô pode receber os pedidos, mas no lado da retrospecção não pode obter os dados, e eu mudei o cronômetro do csv de segundos para milissegundos também não pode obter os dados.
Inventor quantificado - sonho pequenoO que você está referindo especificamente? Há algum requisito para dados definidos? Por exemplo, a parte do tempo pode ser visualizada em milissegundos e segundos?
Inventor quantificado - sonho pequenoA grande quantidade de dados também é boa, eu fiz isso quando testei.
WeixxUma pequena quantidade de dados pode ser obtida, mas quando eu especifiquei um arquivo CSV com mais de um minuto de dados por ano e descobri que não poderia ser obtida, será que a quantidade de dados é muito grande?
WeixxO que eu estou configurando no robô agora é a troca HUOBI, e então o par de negociação também é o BTC-USDT, que também é configurado para o retraso, e então o código para o retraso é o uso de uma função exchange.GetRecords ((), há algum requisito para essa definição de dados?
Inventor quantificado - sonho pequenoVocê pode estar no lado do navegador porque você especificou o parâmetro de consulta, o sistema de resposta não pode desencadear o bot responde, dizendo que o robô não aceitou o pedido, dizendo que o local foi configurado erroneamente durante a resposta, verificando e debugando para encontrar o problema.
Inventor quantificado - sonho pequenoSe você quiser ler o seu próprio arquivo CSV, você pode configurar o caminho do arquivo, conforme mostrado neste exemplo.