Переоборудование сборщиков данных - поддержка импорта файлов в формате CSV для предоставления персонализированных источников данных
Автор:Изобретатели количественного измерения - мечты, Создано: 2020-05-23 15:44:47, Обновлено: 2024-12-10 20:19:56
Обновление файлообменника с поддержкой CSV для импорта файлов и предоставления персонализированных источников данных
Последние пользователи нуждаются в том, чтобы их собственные файлы в формате CSV были источником данных, чтобы позволить изобретателям использовать систему обратной связи для количественной торговой платформы. Система обратной связи для количественной торговой платформы обладает множественными функциями, использует простоту и эффективность, чтобы можно было проводить обратную связь, если у вас есть данные, и больше не ограничиваться биржами, поддерживаемыми платформой.
Идеи дизайна
Идея дизайна очень проста, мы просто немного изменили на базе предыдущего сборщика рынков, мы добавили параметр сборщику рынков.isOnlySupportCSVДобавить один параметр для управления тем, что только CSV-файлы используются в качестве источника данных для рецензированияfilePathForCSV, используется для настройки пути размещения файлов CSV на серверах, управляемых роботами-собирателями.isOnlySupportCSVПараметры настроены наTrueДля того, чтобы принять решение о использовании этого источника данных (данные, собранные самим, данные из CSV-файлов), это изменение было сделано в основном с учетом того, что данные, собранные самим пользователем, могут быть использованы в качестве источника данных.ProviderКатегорииdo_GETФункция в.
Что такое CSV-файл?
Комматно-сепаративные значения (CSV, иногда называемые также символами-сепаративными значениями, поскольку отдельные символы могут быть и некоматами) - это файлы, хранящие табличные данные в текстовом виде (числа и текст). Чистый текст означает, что файл представляет собой последовательность символов, не содержащая данных, которые должны быть расшифрованы, как бинарные числа. CSV-файлы состоят из любых записей, помещенных каким-то символом перемены; каждый запись состоит из полей, разделяемых другими символами или строками, наиболее распространенными из которых являются кометы или табличные символы.
Общих стандартов формата CSV не существует, однако существует некоторая закономерность, которая обычно определяется как заголовок первого действия в одной строке записи; данные в каждой строке интервалируются запятой.
Например, CSV-файл, который мы использовали для тестирования, был открыт с помощью дневника: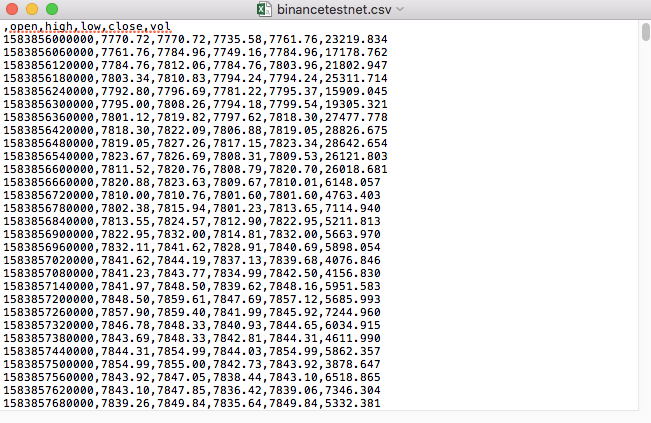
Заметьте, что первая строка в CSV-файле - это заголовок таблицы.
,open,high,low,close,vol
Мы собираем такие данные и создаем формат, который позволяет системе отслеживания настроить запросы на источник данных, которые были рассмотрены в нашем коде в предыдущей статье, но с небольшими изменениями.
Измененный код
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Запуск теста
Сначала мы запускаем рыночный сборник-робот, мы добавляем к нему биржу и запускаем его.
Конфигурация параметров:
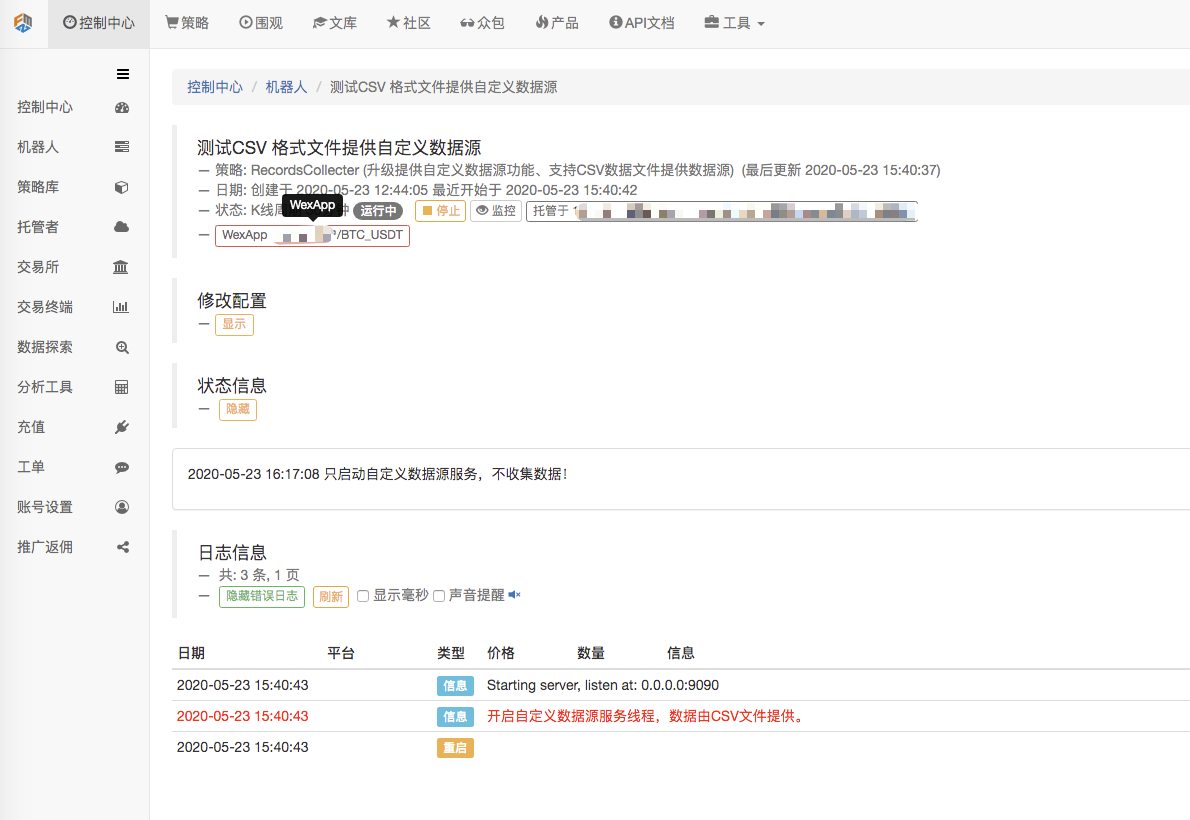
Мы создали тест-стратегию:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
Схема очень проста: просто получите и напечатайте три K-линии данных.
На странице рецензирования источник данных системы рецензирования настраивается как настраиваемый источник данных, а адрес заполняет адрес сервера, управляемого роботом-сборщиком. Так как данные в нашем CSV-файле K-линии в 1 минуту, мы устанавливаем цикл K-линий в 1 минуту при рецензировании.
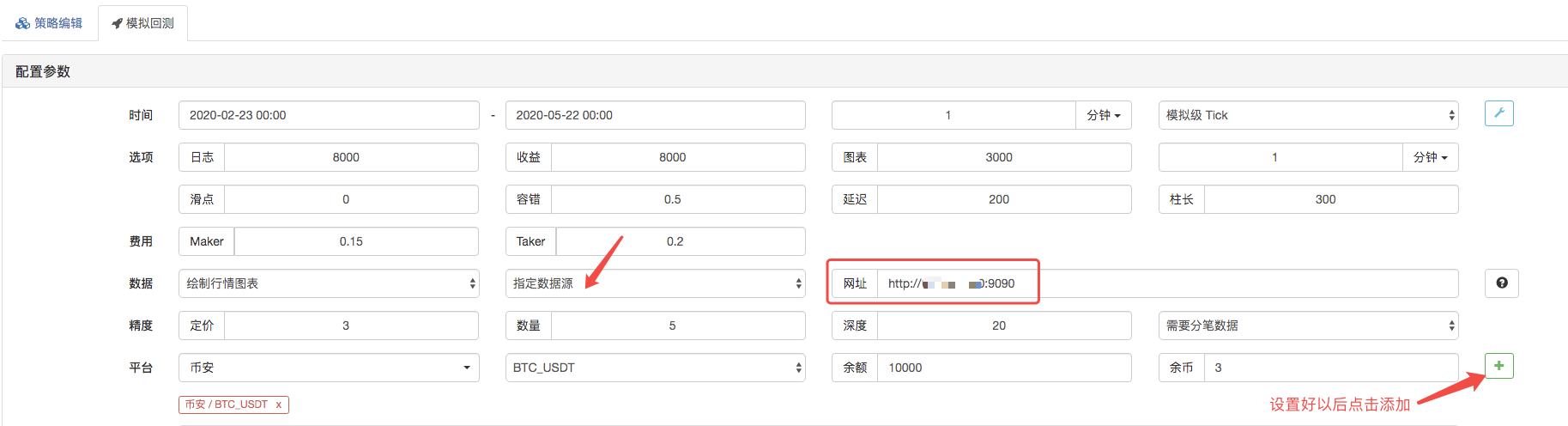
Нажав на кнопку, робот-сборщик получает запрос:
После того, как политика выполнения реквизитной системы будет выполнена, будет сгенерирован K-линейный график, основанный на K-линейных данных из источника данных.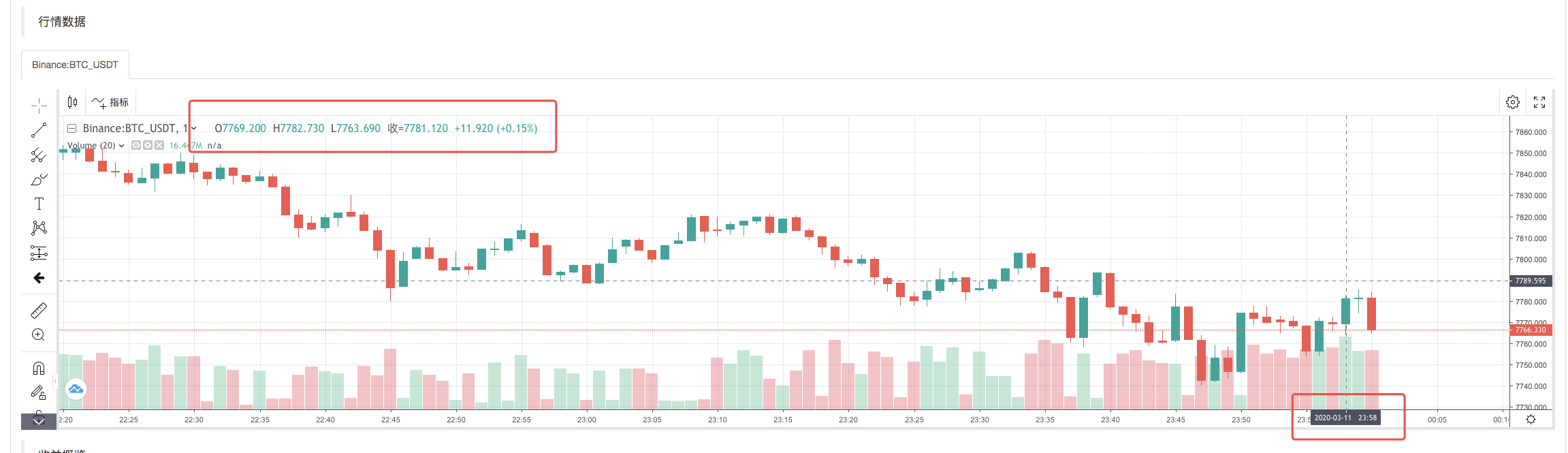
Сравните данные в документах:

Посмотрите на это видео.
- Введение в арбитраж с задержкой свинца в криптовалюте (2)
- Презентация о своде Lead-Lag в цифровой валюте (2)
- Обсуждение по внешнему приему сигналов платформы FMZ: полное решение для приема сигналов с встроенным сервисом Http в стратегии
- Обзор приема внешних сигналов на платформе FMZ: стратегию полного решения приема сигналов встроенного сервиса HTTP
- Введение в арбитраж с задержкой свинца в криптовалюте (1)
- Введение Lead-Lag в цифровой валюте (1)
- Дискуссия по внешнему приему сигнала платформы FMZ: расширенный API VS стратегия встроенного HTTP-сервиса
- Обзор FMZ-платформы для получения внешних сигналов: расширение API против стратегии встроенного HTTP-сервиса
- Обсуждение метода тестирования стратегии на основе генератора случайных тикеров
- Исследование методов тестирования стратегии на основе генератора случайных рынков
- Новая функция FMZ Quant: Используйте функцию _Serve для простого создания HTTP-сервисов
- Усовершенствованный инструмент анализа на основе развития грамматики Alpha101
- Научить вас обновлять рынок коллектор backtest пользовательский источник данных
- Недостатки системы высокочастотного повторения, основанной на транзакциях по буквам, и K-линейного повторения
- Объяснение механизма обратного тестирования на уровне моделирования FMZ
- Лучший способ установить и обновить FMZ docker на Linux VPS
- Фьючерсы на сырьевые товары Стратегия R-Breaker
- Мысли о логике торговли фьючерсами цифровых валют
- Научить вас внедрять рыночные котировки коллектор
- Python версия Фьючерсы на сырьевые товары Стратегия скользящей средней
- Рыночные котировки коллектор обновление снова
- Стратегия торговли высокочастотными фьючерсами на сырьевые товары, написанная на C++
- Ларри Коннорс RSI2 Средняя стратегия обратного движения
- Окс руководит и учит вас использовать JS пары для расширения FMZ API
- На основе использования нового индекса относительной прочности в внутридневных стратегиях
- Исследования фьючерсной стратегии хеджирования в нескольких валютах Binance Часть 4
- Ларри Коннорс Ларри Коннорс RSI2 Стратегия регрессии среднего значения
- Исследования фьючерсной стратегии хеджирования в нескольких валютах Binance Часть 3
- Исследование стратегии хеджирования в нескольких валютах Binance Futures Часть 2
- Исследования фьючерсной стратегии хеджирования в нескольких валютах Binance Часть 1
- Руководство показывает вам, как обновить и перепроверять настройки источников данных.
БрюссельНужно ли установить Python на сервере администратора?
Спарта играет в количественном режимеДэнни, теперь этот настраиваемый источник данных снова просматривается в браузере, и есть проблемы с точностью данных, вы можете попробовать.
ЭйКПМ.../upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png /upload/asset/19c100ceb1eb25a38a970.png Я подключил бота, как я должен был заполнить там адрес, я заполнил адрес сервера, порт пароль 9090, и коллектор не отвечает.
WeixxПожалуйста, объясните, почему я настроил на хост-сервере настройки на пользовательский источник данных CSV, с помощью которого при запросе страницы возвращаются данные, а затем при обратном поиске возвращаются никакие данные, когда данные напрямую назначаются только на два данные.
WeixxПожалуйста, объясните, почему я настроил на хост сервере настраиваемый источник данных CSV, который возвращает данные с запросом страницы, а затем не возвращает данные в обратном отслеживании, и не отправляет запрос на сервер https://upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28658795b3e.png /upload/asset/169e8ddbf9c0c544png
qq89520Спросите, как параметры настроены?
проповедьЕсли вы хотите, чтобы ваши акции были высококлассными, то вы можете измерить любую монету, возможно, даже акции.
Дзаидаси 666
Изобретатели количественного измерения - мечтыЯ хочу, чтобы у меня был питон.
Спарта играет в количественном режимеЭто была ошибка в системе, которая была исправлена.
Изобретатели количественного измерения - мечтыПосмотрите, как вы можете попробовать это.
Изобретатели количественного измерения - мечтыДля этого нужно понять статью, код. Здесь речь идет о том, как использовать CSV-файлы в качестве источника данных, чтобы предоставить данные системе обратной связи.
Изобретатели количественного измерения - мечтыСмотрите описание в документации API.
WeixxИспользуя методы exchange.GetData (), можно ли превратить K-строки в пользовательские данные?
Изобретатели количественного измерения - мечтыУслуга, предоставляющая персонализированный источник данных, должна быть размещена на сервере, должен быть общедоступный IP-адрес.
WeixxПожалуйста, как можно настроить локальный ретро в HTTP-сервисе, не поддерживает ли локальный ретро ретро пользовательские источники данных? Я добавил в локальный ретро exchanges: [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"}] этот параметр, а также преобразование в IP робота также не требуется на сервер
Изобретатели количественного измерения - мечтыСлишком большое количество данных. Веб-страница не может быть загружена, кроме того, DEMO, вы изучали, должно быть, все в порядке, полагаю, что вы неправильно настроили.
WeixxЯ - данные csv в одну минуту, K-линия - данные других валют, а затем, поскольку в момент обратного отсчета не может быть выбран случайный торговый пакет, робот и выбранный обменный пакет для обратного отсчета настроены на huobi, торговый пакет на BTC-USDT, данные запроса. Я иногда получаю запросы со стороны робота, но не получаю данные со стороны обратного отсчета, и я меняю временные рамки csv с секунды на миллисекунды, которые также не могут получить данные.
Изобретатели количественного измерения - мечтыЕсли вы обращаетесь в BTC_USDT, то к какому конкретно вы имеете в виду? Есть ли какие-либо требования к данным, которые определяются этим определением?
Изобретатели количественного измерения - мечтыЯ проверил, что большие объемы данных тоже могут быть полезны.
WeixxНебольшие объемы данных могут быть получены, но когда я указываю CSV-файл более чем на минуту данных в течение года, это не может быть получено, а может ли слишком большое количество данных иметь значение?
WeixxВ данный момент я конфигурирую на роботе биржу HUOBI, затем пара BTC-USDT, которая также настраивается, также конфигурируется при повторном измерении, а затем код повторного измерения использует функцию exchange.GetRecords ((), есть ли какие-либо требования к данным, которые определяются таким образом?
Изобретатели количественного измерения - мечтыВы можете быть в браузерной части, потому что вы указали параметры запроса, система ответа не может запустить ответ робота, что робот не принял запрос, объясняя, что место было неправильно настроено при ответе, чтобы найти проблему при проверке, дешифровке.
Изобретатели количественного измерения - мечтыЕсли вы хотите прочитать свой собственный CSV-файл, вы можете настроить его так, как это показано в этой статье.