Когда мы предсказываем вероятность, что мы предсказываем?
Автор:Изобретатели количественного измерения - мечты, Создано: 2017-02-25 00:22:28, Обновлено:Когда мы предсказываем вероятность, что мы предсказываем?
Я был на одном из интервью очень давно, и тема заставила меня задуматься.
Интервьюер: Вы знаете, что Logistic возвращается? Я: Конечно, я знаю, это часто бывает. Интервьюер: Как вы думаете, как объяснить вероятность того, что логистический прогноз возвращения - это вероятность успеха одного человека? Я: Конечно, нет. Если только одно наблюдение, то индивидуальная вероятность не может быть оценена. Это должно быть объяснено тем, что, при условии, что N человек имеют одинаковые характеристики, процент успеха равен оцененной вероятности.
Ну, тогда собеседники не могли, и конечно, в итоге меня вычеркнули (возможно, из-за моего экономического, а не статистического, компьютерного опыта).
Возможно, вы думаете, что это немного противоречиво или трудно понять, но когда мы оценивали возвращение Logistic, мы оценили:
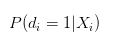
Не следует ли объяснять это вероятностью успеха человека?
- #### Я думаю, что это довольно проблематично.
Когда мы говорим о вероятности успеха отдельного человека, то это должно быть среднее число успешных попыток одного и того же человека 100 раз при одинаковых условиях. Если учесть t как количество попыток одного и того же человека, то наша идеальная модель (процесс генерации данных) должна выглядеть так:
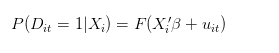
Однако, как альтернатива, реальный процесс создания данных может выглядеть так:
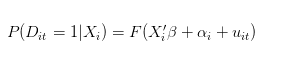

- HttpQuery не работает в Python
- Что это значит, что у нас есть шанс выиграть, а у нас нет шансов выиграть?
- Мы говорим о шансах на победу и проигрыш.
- Это, пожалуй, самая большая ложь в инвестировании!
- Как выжить в мире, полном случайностей
- Изучайте тенденции и следуйте за ними
- Раскрытие фонда больших данных
- Почему розничные инвесторы покупают и покупают (Контрариан)?
- Если вы не сможете выиграть, бросайте монету и делайте сделку, чтобы заработать?
- Путешествие алгоритмов машинного обучения
- Программированная транзакционная схема (Idea to Program)
- _C() Функция перепробования
- _N() Функция Маленькие цифры с точки
- Первоначальное обучение адаптации
- Настоящая и формальная система торговли
- Три коротких рассказа о понимании недвижимости, фондовых рынков и валюты
- Шесть ветвей Quant раскрыты
- Стратегия распознавания форм на основе динамической закономерности времени
- Мысли об аналогичных биржах
- Стратегические отзывы о восьми известных крипто-хеджирующих EA
Здравствуйте886lgistic сам по себе не имеет ничего общего с вероятностью, просто для того, чтобы отобразить расстояние до 0−1.
- Я не знаю.Интересно
Изобретатели количественного измерения - мечтыУ вас есть время, чтобы выступить, и дискуссия на этом форуме должна быть очень привлекательной.