عمل جمع کرنے والے کو دوبارہ اپ گریڈ کریں - CSV فارمیٹ فائلوں کی درآمد کی حمایت کرتے ہوئے اپنی مرضی کے مطابق ڈیٹا ماخذ فراہم کریں
مصنف:ایجاد کاروں کی مقدار - خواب, تخلیق: 2020-05-23 15:44:47, تازہ کاری: 2024-12-10 20:19:56
عمل جمع کرنے والے کو دوبارہ اپ گریڈ کرنے کے لئے ٹیبلٹ CSV فارمیٹ فائلوں کی درآمد کی حمایت کرتا ہے جس میں اپنی مرضی کے مطابق ڈیٹا ماخذ فراہم کرتا ہے
تازہ ترین صارف کو اپنے CSV فارمیٹ فائلوں کو ڈیٹا ماخذ کے طور پر استعمال کرنے کی ضرورت ہے تاکہ موجد کو کوانٹائزڈ ٹریڈنگ پلیٹ فارم کے ریٹیسٹنگ سسٹم کا استعمال کریں۔ موجد کوانٹائزڈ ٹریڈنگ پلیٹ فارم کے ریٹیسٹنگ سسٹم میں بہت ساری خصوصیات ہیں ، اور اس کا استعمال جامع اور موثر ہے ، لہذا جب تک آپ کے پاس ڈیٹا موجود ہے ، آپ کو ریٹیسٹنگ کی جاسکتی ہے ، اس وقت تک کہ پلیٹ فارم کے ڈیٹا سینٹر کی حمایت کرنے والے تبادلے ، اقسام تک محدود نہ ہو۔
ڈیزائن کے خیالات
ڈیزائن کا خیال بہت آسان ہے، ہم صرف اس میں تھوڑا سا تبدیلی کرتے ہیں، اور ہم اس میں ایک پیرامیٹر شامل کرتے ہیںisOnlySupportCSVکنٹرول کرنے کے لئے کہ آیا صرف CSV فائل کو ڈیٹا کا ذریعہ کے طور پر پیش کیا جاتا ہے یا نہیںfilePathForCSV، جس میں سیٹ اپ کرنے کے لئے استعمال کیا جاتا ہے مارکیٹنگ جمع کرنے والے روبوٹ کے ذریعہ چلنے والے سرور پر CSV ڈیٹا فائلوں کو رکھنے کا راستہ۔ آخر میں ،isOnlySupportCSVکیا آپ کے پیرامیٹرز کے لئے مقرر کیا گیا ہےTrueیہ تبدیلی بنیادی طور پر اس بات کی نشاندہی کرتی ہے کہ کس طرح صارفین کو ان کے ڈیٹا کے ذریعہ استعمال کرنے کا فیصلہ کرنے کی اجازت دی جاتی ہے (خود سے جمع کردہ ، 2 ، CSV فائلوں میں ڈیٹا) ۔Providerزمرہdo_GETآپ کے لئے یہ بہت اچھا ہے.
CSV فائل کیا ہے؟
کوما الگ شدہ اقدار (CSV، جسے بعض اوقات کوما الگ شدہ اقدار بھی کہا جاتا ہے کیونکہ کوما الگ الگ کرنے والے حروف بھی کوما نہیں ہوسکتے ہیں) ، ان کے دستاویزات میں صرف متن کی شکل میں ٹیبل ڈیٹا (نمبرز اور متن) محفوظ کیا جاتا ہے۔ خالص متن کا مطلب یہ ہے کہ یہ فائل ایک حروف سیریز ہے جس میں اعداد و شمار کی طرح پڑھنے کے لئے ضروری نہیں ہے۔ CSV فائل کسی بھی مقصد کے ریکارڈ پر مشتمل ہے جس میں ریکارڈ کے وقفے کو کسی قسم کی تبدیلی کی علامت کے طور پر الگ کیا جاتا ہے۔ ہر ریکارڈ فیلڈز پر مشتمل ہوتا ہے ، جس میں وقفے کو دوسرے حروف یا سٹرنگز سے الگ کیا جاتا ہے ، جو سب سے زیادہ عام طور پر کوما یا ٹیبلٹ حروف ہوتے ہیں۔ عام طور پر ، تمام ریکارڈوں میں بالکل ایک جیسے پیراگراف ترتیب ہوتے ہیں۔ یہ عام طور پر خالص متن کے دستاویزات ہوتے ہیں۔ یہ تجویز کیا جاتا ہے کہ WordADDP استعمال کریں یا اسے دوبارہ کھولیں ، اگر کوئی دوسرا آرکائیو نئے EXCEL کا استعمال کرتے ہوئے پہلے سے کھولا جائے تو ، یہ بھی ایک طریقہ ہے۔
سی ایس وی فائل فارمیٹ کے لیے کوئی عام معیار موجود نہیں ہے، لیکن ایک قاعدہ موجود ہے، عام طور پر ایک ریکارڈ کی ایک سطر کے لیے، پہلی حرکت کا سرخی۔ ہر سطر میں ڈیٹا کو کوما کے وقفے سے استعمال کیا جاتا ہے۔
مثال کے طور پر، ہم نے ایک CSV فائل کو ٹیسٹ کرنے کے لئے استعمال کیا ہے جو نوشتہ میں کھلتا ہے: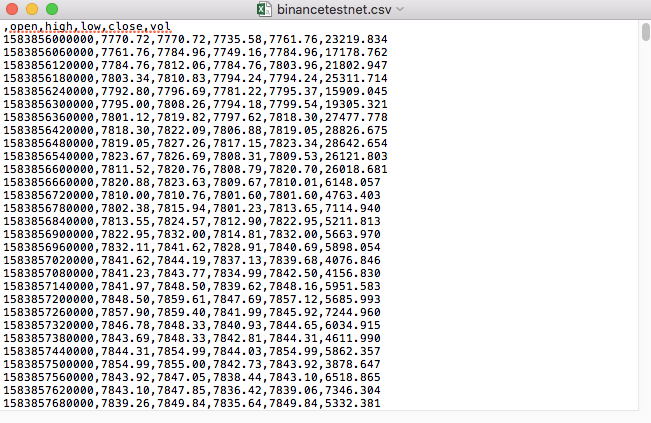
نوٹ کریں کہ CSV فائل کی پہلی سطر ٹیبل ہیڈر ہے۔
,open,high,low,close,vol
ہم اس طرح کے اعداد و شمار کو تجزیہ کرنے کے لئے ترتیب دیتے ہیں اور پھر اس فارمیٹ کو تشکیل دیتے ہیں جس میں ریویو سسٹم اپنی مرضی کے مطابق ڈیٹا ماخذ کی درخواست کرتا ہے، جو ہمارے پچھلے مضمون میں کوڈ میں نمٹا گیا ہے، صرف تھوڑا سا ترمیم کے ساتھ.
ترمیم شدہ کوڈ
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
ٹیسٹ چلائیں
اس کے بعد ہم نے ایک روبوٹ کو شروع کیا جس نے مارکیٹ کو جمع کیا اور ہم نے روبوٹ کو ایک ایکسچینج شامل کیا اور روبوٹ کو چلایا۔
پیرامیٹرز کی ترتیب:
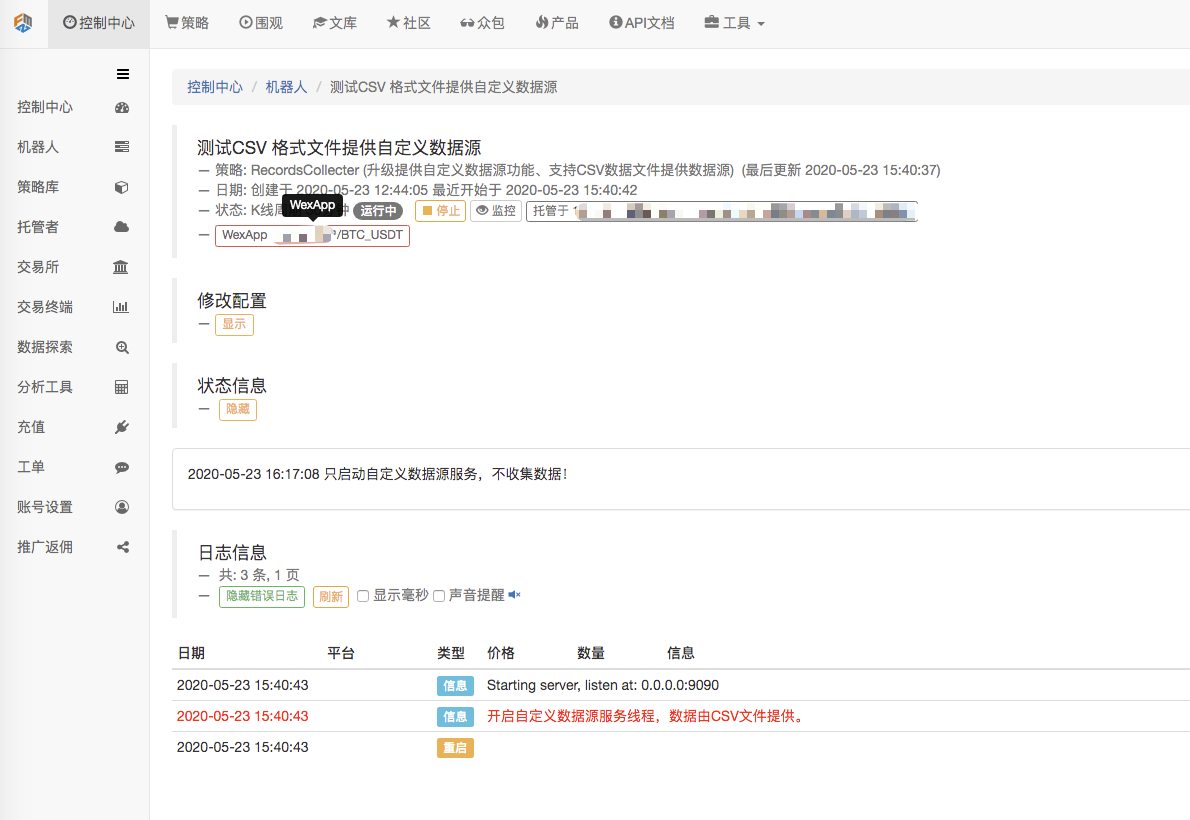
اس کے بعد ہم نے ایک ٹیسٹنگ حکمت عملی بنائی:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
اس کی حکمت عملی بہت آسان ہے، صرف تین K لائن ڈیٹا حاصل کریں اور ان پرنٹ کریں۔
ریٹرننگ پیج ، ریٹرننگ سسٹم کے ڈیٹا ماخذ کو اپنی مرضی کے مطابق ڈیٹا ماخذ کے طور پر ترتیب دیا گیا ہے ، اور ایڈریس کو سرور ایڈریس پر پُر کیا گیا ہے جو مارکیٹنگ کلکٹر روبوٹ چلاتا ہے۔ چونکہ ہمارے CSV فائل میں ڈیٹا 1 منٹ کی لائن ہے۔ لہذا ریٹرننگ کے وقت ، ہم نے 1 منٹ کی لائن کا دورانیہ ترتیب دیا ہے۔
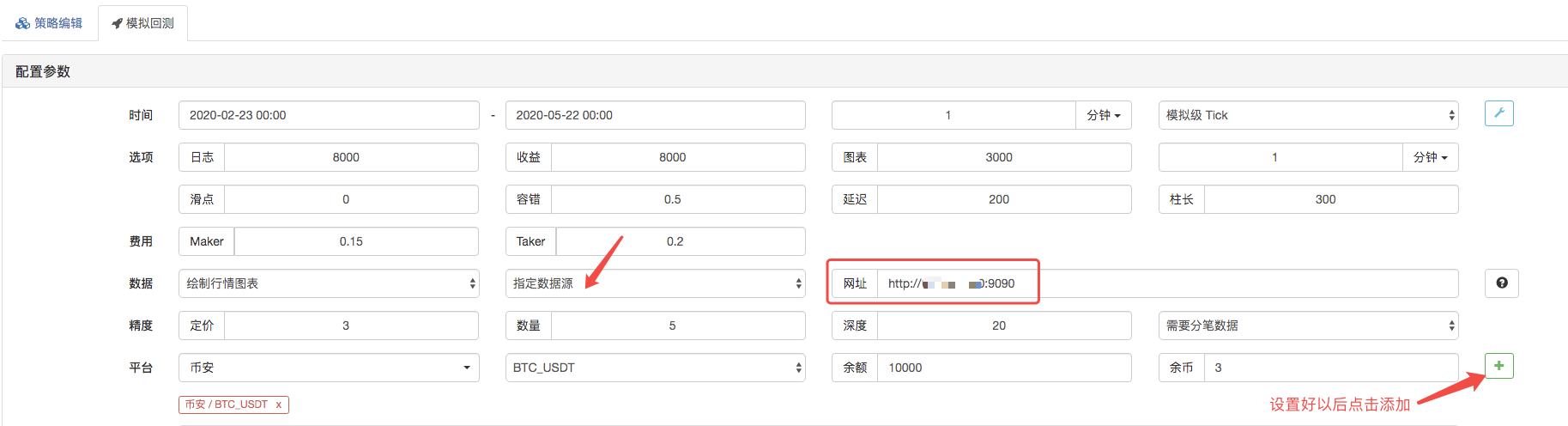
ایک بار جب آپ نے اس پر کلک کیا تو ، مارکیٹنگ جمع کرنے والے روبوٹ کو ڈیٹا کی درخواست موصول ہوئی:
ایک بار جب ریویو سسٹم کی حکمت عملی مکمل ہوجاتی ہے تو ، ڈیٹا ماخذ میں K لائن ڈیٹا کے مطابق K لائن چارٹ تیار کیا جاتا ہے۔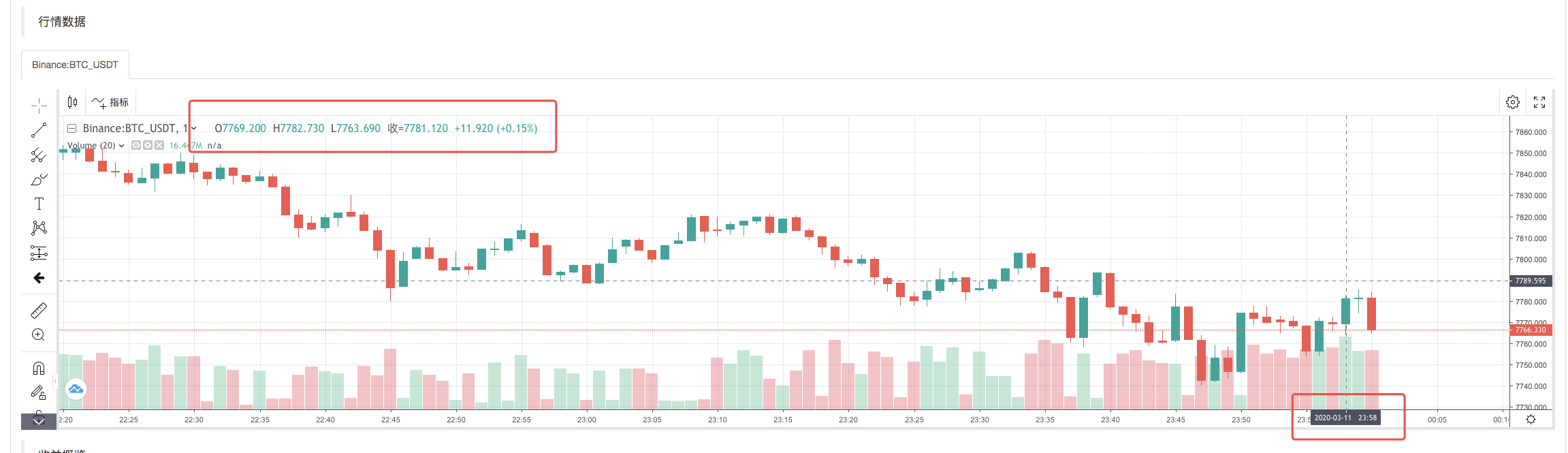
اس کے علاوہ، آپ کو یہ بھی معلوم ہونا چاہئے کہ آپ کو کیا کرنا چاہئے:

آپ کو خوش آمدید۔
- کریپٹوکرنسی میں لیڈ لیگ اربیٹریج کا تعارف (2)
- ڈیجیٹل کرنسیوں میں لیڈ لیگ سوٹ کا تعارف ((2)
- ایف ایم زیڈ پلیٹ فارم کی بیرونی سگنل وصولی پر بحث: حکمت عملی میں بلٹ ان ایچ ٹی پی سروس کے ساتھ سگنل وصول کرنے کے لئے ایک مکمل حل
- ایف ایم زیڈ پلیٹ فارم کے بیرونی سگنل وصول کرنے کا جائزہ: حکمت عملی بلٹ میں HTTP سروس سگنل وصول کرنے کا مکمل نظام
- کریپٹوکرنسی میں لیڈ لیگ اربیٹریج کا تعارف (1)
- ڈیجیٹل کرنسی میں لیڈ لیگ سوٹ کا تعارف ((1)
- ایف ایم زیڈ پلیٹ فارم کی بیرونی سگنل وصولی پر تبادلہ خیال: توسیع شدہ اے پی آئی بمقابلہ حکمت عملی بلٹ ان HTTP سروس
- ایف ایم زیڈ پلیٹ فارم کے لئے بیرونی سگنل وصول کرنے کا جائزہ: توسیع API بمقابلہ حکمت عملی بلٹ ان HTTP سروس
- رینڈم ٹکر جنریٹر پر مبنی حکمت عملی ٹیسٹنگ کے طریقہ کار پر بحث
- بے ترتیب مارکیٹ جنریٹر پر مبنی حکمت عملی ٹیسٹنگ کے طریقوں کا جائزہ
- ایف ایم زیڈ کوانٹ کی نئی خصوصیت: آسانی سے ایچ ٹی ٹی پی سروسز بنانے کے لئے _Serve فنکشن کا استعمال کریں
- الفا 101 گرائمر کی ترقی پر مبنی تجزیہ کا بہتر آلہ
- آپ کو اپ گریڈ کرنے کے لئے سکھانے کے لئے مارکیٹ جمع کرنے والے backtest اپنی مرضی کے مطابق ڈیٹا ماخذ
- کالم پر مبنی ہائی فریکوئینسی ریورس سسٹم اور کیو لائن ریورس کے نقائص
- FMZ سیمولیشن سطح بیک ٹسٹ میکانیزم کی وضاحت
- لینکس VPS پر FMZ ڈوکر انسٹال اور اپ گریڈ کرنے کا بہترین طریقہ
- روڈ فیوچرز آر بریکر حکمت عملی
- ڈیجیٹل کرنسی کے فیوچر ٹریڈنگ کی منطق کے بارے میں سوچنا
- آپ کو ایک مارکیٹ کی قیمتوں کا تعین جمع کرنے کے لئے لاگو کرنے کے لئے سکھانے کے
- پیتھون ورژن کموڈٹی فیوچر حرکت پذیر اوسط حکمت عملی
- مارکیٹ کی قیمتوں کا تعین جمع کرنے والا ایک بار پھر اپ گریڈ
- سی ++ میں لکھی گئی کموڈٹی فیوچر ہائی فریکوئنسی ٹریڈنگ حکمت عملی
- لیری کونرز RSI2 اوسط ریورسشن کی حکمت عملی
- اوک ہاتھ آپ کو سکھاتا ہے کہ کس طرح JS کے ساتھ FMZ توسیع API کو جوڑنا ہے
- اندرونی دن کی حکمت عملیوں میں ایک نئی رشتہ دار طاقت انڈیکس کے استعمال کی بنیاد پر
- بائننس فیوچر ملٹی کرنسی ہیجنگ حکمت عملی حصہ 4 پر تحقیق
- لیری کونرس لیری کونرس RSI2 اوسط واپسی کی حکمت عملی
- بائننس فیوچر ملٹی کرنسی ہیجنگ حکمت عملی حصہ 3 پر تحقیق
- بائننس فیوچر ملٹی کرنسی ہیجنگ حکمت عملی پر تحقیق حصہ 2
- بائننس فیوچر ملٹی کرنسی ہیجنگ حکمت عملی پر تحقیق حصہ 1
- ہاتھ سے آپ کو کسٹم ڈیٹا ماخذ کی کارکردگی کی جانچ پڑتال کرنے کے لئے مارکیٹنگ کلکٹر کو اپ گریڈ کرنے کے لئے سکھاتا ہے
بھائی بھائی!کیا ایڈمنسٹریٹر سرورز پر پِیٹون نصب کرنا ضروری ہے؟
اسپارٹا کھیلنے کی مقدارڈینم، اب یہ اپنی مرضی کے مطابق ڈیٹا بیس براؤزر کی طرف سے دوبارہ جانچ پڑتال کی ہے، اعداد و شمار کی درستگی کے ساتھ مسائل ہیں، آپ کو یہ کرنے کی کوشش کریں.
اے آئی کے پی ایم-/upload/asset/19cfcf5244f5e2cd73173.png /upload/asset/19c100ceb1eb25a38a970.png روبوٹ بند کر دیا گیا ہے، میں نے سرور ایڈریس پورٹ پاس ورڈ 9090 میں بھرنے کے لئے کس طرح کی ضرورت ہے، اور کلکٹر میں کوئی ردعمل نہیں ہے.
ویکسبراہ کرم پوچھیں کہ میں نے کسٹم سی ایس وی ڈیٹا سورس کو اپنے میزبان سرور پر کیوں ترتیب دیا ہے ، صفحہ کی درخواست میں ڈیٹا کی واپسی ہوتی ہے ، پھر دوبارہ جانچ میں کوئی ڈیٹا نہیں ملتا ہے ، جب ڈیٹا کو براہ راست صرف دو اعداد و شمار پر ترتیب دیا جاتا ہے تو ، httpsserver ٹرمینل درخواست میں /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d286587b3e.ng /upload/asset/169e8dcdbf9c0c544pngbac
ویکسبراہ کرم پوچھیں کہ میں نے اپنے میزبان سرور پر کسٹم CSV ڈیٹا سورس کو کیوں ترتیب دیا ہے ، صفحہ کی درخواست کے ساتھ ڈیٹا کی واپسی ، پھر دوبارہ جانچ میں کوئی ڈیٹا کی واپسی نہیں ہوئی ، اور نہ ہی کسی درخواست کو httpsserver ٹرمینل میں /upload/asset/1691b2d9549fcec81c12a.png /upload/asset/168f8050b3db4a84d7e2f.png /upload/asset/16a67eaa598e95b11edb9.png /upload/asset/169c6c4c3d28658795b3e.png /upload/asset/169e8dcdbf9c0c544png
qq89520براہ مہربانی مجھے بتائیں کہ آپ کے پیرامیٹرز کیسے ہیں؟
خطبہاگر آپ کے پاس ایک اعلی درجے کی کرنسی ہے ، تو آپ کسی بھی کرنسی کا اندازہ لگا سکتے ہیں ، اور شاید اسٹاک بھی۔
ڈسائیڈسی 666
ایجاد کاروں کی مقدار - خوابآپ کو پائیتھون کی ضرورت ہے۔
اسپارٹا کھیلنے کی مقداریہ نظام کی خرابی کا پتہ لگانے کے لئے تھا، اور اسے ٹھیک کر دیا گیا ہے
ایجاد کاروں کی مقدار - خوابAPI دستاویزات میں درستگی کے بارے میں وضاحت کے لئے، آپ کو یہ دیکھنے کی کوشش کر سکتے ہیں.
ایجاد کاروں کی مقدار - خواباس کے علاوہ ، آپ کو اس مضمون کو سمجھنے کی ضرورت ہے ، کوڈ۔ یہ CSV فائلوں کے ذریعہ ڈیٹا کا ذریعہ ہے ، جس سے ڈیٹا کو ریٹرن سسٹم میں فراہم کیا جاتا ہے۔
ایجاد کاروں کی مقدار - خواباس کے بارے میں تفصیلات اے پی آئی دستاویزات میں ملاحظہ کریں۔
ویکسکسٹم ڈیٹا کو کسٹم ڈیٹا میں تبدیل کرنے کے لئے کسٹم ڈیٹا کو کسٹم ڈیٹا میں تبدیل کرنے کے لئے کسٹم ڈیٹا کو کسٹم ڈیٹا میں تبدیل کیا جاسکتا ہے؟
ایجاد کاروں کی مقدار - خوابیہ سروس جو اپنی مرضی کے مطابق ڈیٹا ماخذ فراہم کرتی ہے اسے سرور پر رکھنا ضروری ہے ، یہ عوامی IP ہونا ضروری ہے۔ مقامی سروس ریٹرننگ سسٹم تک رسائی حاصل نہیں ہے۔
ویکسبراہ کرم پوچھیں کہ مقامی طور پر HTTP سرور پر مقامی طور پر ڈیٹا کو کیسے دوبارہ ترتیب دیا جائے۔ کیا مقامی طور پر دوبارہ ترتیب دینے سے اپنی مرضی کے مطابق ڈیٹا ماخذ کو دوبارہ ترتیب دینے میں مدد نہیں ملتی؟ میں نے مقامی طور پر دوبارہ ترتیب دینے میں شامل کیا exchanges: [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"} یہ پیرامیٹر ، اور روبوٹ میں تبدیل شدہ آئی پی بھی سرور سے کوئی درخواست نہیں کرتے ہیں۔
ایجاد کاروں کی مقدار - خواببہت زیادہ اعداد و شمار۔ ویب پیج کو لوڈ نہیں کیا جاسکتا ، اس کے علاوہ ڈیمو۔ آپ کی تحقیق میں ، یہ ٹھیک ہونا چاہئے ، میرا اندازہ ہے کہ آپ نے اسے غلط ترتیب دیا ہے۔
ویکسمیں csv ڈیٹا ایک منٹ K لائن دیگر کرنسیوں کے اعداد و شمار ہیں، اور پھر چونکہ دوبارہ جانچ پڑتال کے وقت ٹریڈنگ کے جوڑے کو کسی بھی وقت منتخب نہیں کیا جاسکتا ہے، روبوٹ اور دوبارہ جانچ پڑتال کے منتخب کردہ تبادلے دونوں کو huobi کے طور پر مقرر کیا جاتا ہے، ٹریڈنگ کا جوڑا BTC-USDT ہے، یہ درخواست کا ڈیٹا میں کبھی کبھی روبوٹ کی طرف سے درخواست حاصل کرسکتا ہوں، لیکن دوبارہ جانچ پڑتال کی طرف سے ڈیٹا حاصل نہیں کیا جاسکتا ہے، اور میں نے csv کے ٹائم لائن کو سیکنڈ سے تبدیل کر دیا ہے.
ایجاد کاروں کی مقدار - خوابکیا آپ کا مطلب ہے؟ کیا اس کی تعریف کے اعداد و شمار کی کوئی ضرورت ہے؟ مثال کے طور پر وقت کے حصے میں ملی سیکنڈ اور سیکنڈ دونوں کو دیکھا جاسکتا ہے؟
ایجاد کاروں کی مقدار - خوابیہ بہت اچھا ہے کہ اعداد و شمار بہت زیادہ ہیں، میں نے ٹیسٹ کے دوران یہ کیا تھا۔
ویکسبہت کم ڈیٹا حاصل کیا جا سکتا ہے، لیکن جب میں نے ایک CSV فائل کو ایک سال سے زیادہ کے لئے ایک منٹ کے اعداد و شمار کی وضاحت کی تو یہ پتہ چلا کہ یہ نہیں مل سکا، کیا ڈیٹا کی مقدار بہت زیادہ ہے؟ پھر کیا یہ مقامی طور پر اپنی مرضی کے مطابق ڈیٹا ماخذ کھولنے اور مقامی طور پر دوبارہ جانچ پڑتال کر سکتا ہے؟
ویکسمیرے روبوٹ پر فی الحال HUOBI ایکسچینج کی تشکیل کی گئی ہے ، پھر ٹریڈنگ جوڑی بھی سیٹ ہے ، BTC-USDT ، اور دوبارہ جانچ پڑتال کے وقت بھی اس طرح کی تشکیل کی گئی ہے ، اور پھر دوبارہ جانچ پڑتال کا کوڈ بھی ایک exchange.GetRecords () فنکشن کا استعمال کرتا ہے ، کیا اس کی تعریف کردہ ڈیٹا کی کوئی ضرورت ہے؟ مثال کے طور پر وقت کا حصہ ملی سیکنڈ اور سیکنڈ دونوں کو دیکھا جاسکتا ہے؟
ایجاد کاروں کی مقدار - خوابآپ براؤزر کے اختتام پر ہوسکتے ہیں کیونکہ آپ نے اپنے مخصوص استفسار کے پیرامیٹرز لکھے ہیں ، جواب دینے والا نظام روبوٹ کا جواب نہیں دے سکتا ، یہ بتاتا ہے کہ روبوٹ نے درخواست قبول نہیں کی ، جواب دینے کے دوران اس جگہ کی تشکیل غلط ہے ، جانچ پڑتال ، ڈیبگنگ کے دوران مسئلہ مل سکتا ہے۔
ایجاد کاروں کی مقدار - خواباگر آپ اپنے CSV فائل کو پڑھنا چاہتے ہیں تو ، آپ اس فائل کا راستہ ترتیب دے سکتے ہیں ، جیسا کہ اس ٹیکسٹ میں دکھایا گیا ہے۔